Cette architecture de référence montre comment effectuer l’apprentissage d’un modèle de recommandation à l’aide d’Azure Databricks, puis déployer le modèle en tant qu’API en utilisant Azure Cosmos DB, Azure Machine Learning et Azure Kubernetes Service (AKS). Pour obtenir une implémentation de référence de cette architecture, consultez Création d’une API de recommandation en temps réel sur GitHub.
Architecture
Téléchargez un fichier Visio de cette architecture.
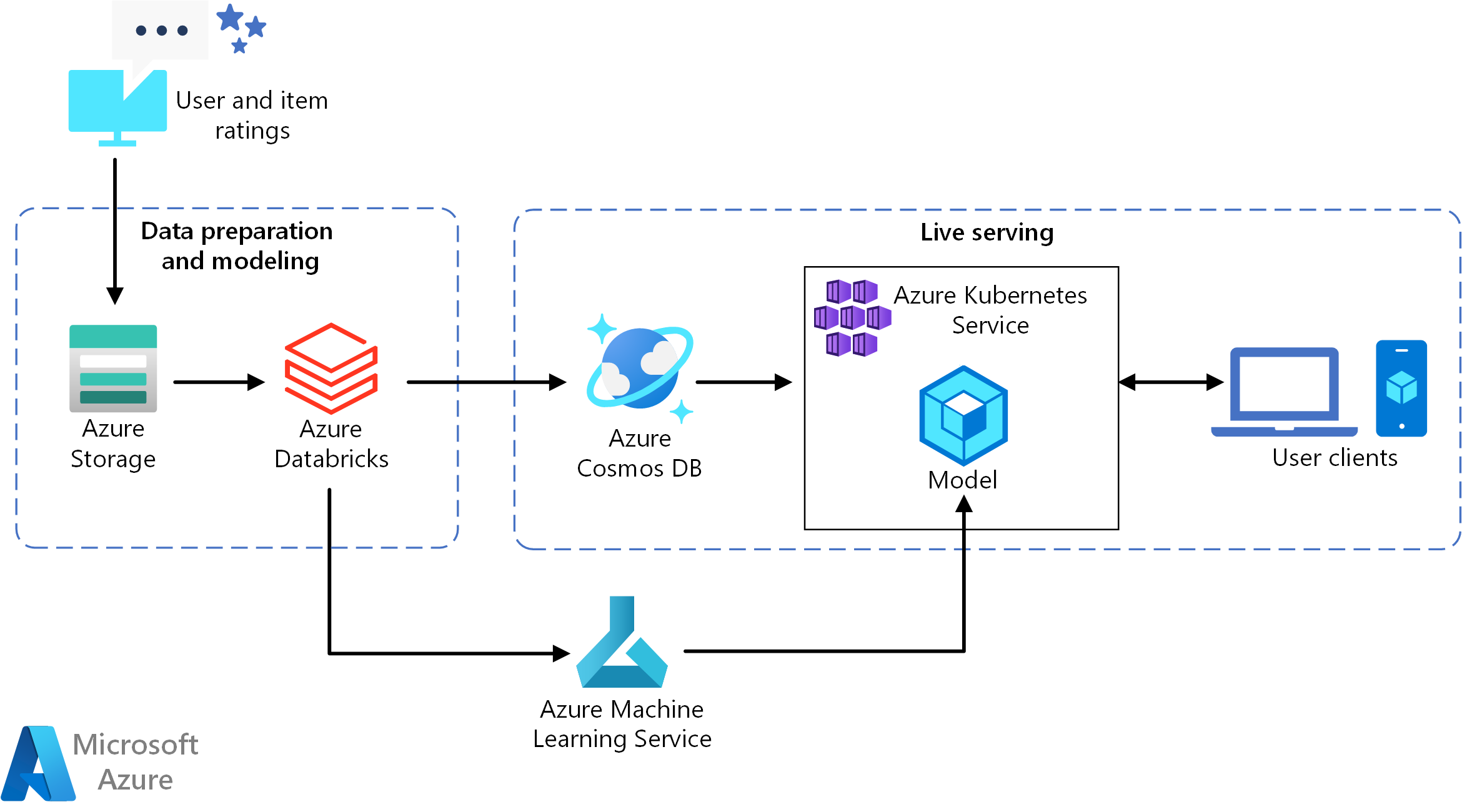
Cette architecture de référence concerne l’entraînement et le déploiement d’une API de service de recommandation en temps réel qui peut fournir les 10 meilleures recommandations de films pour un utilisateur.
Dataflow
- Suivre les comportements des utilisateurs. Par exemple, un service back-end peut enregistrer quand un utilisateur évalue un film, ou clique sur un produit ou un article de presse.
- Charger les données dans Azure Databricks à partir d’une source de données disponible.
- Préparer les données et les diviser en jeux d’entraînement et de test pour entraîner le modèle. (Ce guide décrit les options de division des données.)
- Adapter le modèle Spark Collaborative Filtering aux données.
- Évaluer la qualité du modèle à l’aide de métriques d’évaluation et de classement. (Ce guide fournit des détails sur les métriques que vous pouvez utiliser pour évaluer votre recommandation.)
- Précalculer les 10 meilleures recommandations par utilisateur et les stocker en tant que cache dans Azure Cosmos DB.
- Déployer un service API sur AKS à l’aide des Azure Machine Learning pour conteneuriser et déployer l’API.
- Lorsque le service back-end reçoit une demande d’un utilisateur, appeler l’API de recommandation hébergée dans AKS pour obtenir les 10 meilleures recommandations et les afficher à l’intention de l’utilisateur.
Composants
- Azure Databricks. Databricks est un environnement de développement utilisé pour préparer des données d’entrée et entraîner le modèle de recommandation sur un cluster Spark. Azure Databricks offre également un espace de travail interactif afin d’exécuter des notebooks et de collaborer sur ceux-ci pour toute tâche de traitement de données ou de machine learning.
- Azure Kubernetes Service (AKS). AKS est utilisé pour déployer et rendre opérationnelle une API de service de modèle Machine Learning sur un cluster Kubernetes. AKS héberge le modèle conteneurisé, en offrant une scalabilité qui répond à vos besoins en débit, la gestion des identités et des accès ainsi que la journalisation et la supervision de l’intégrité.
- Azure Cosmos DB. Azure Cosmos DB est un service de base de données mondialement distribué qui permet de stocker les 10 premiers films recommandés pour chaque utilisateur. Azure Cosmos DB convient bien pour ce scénario, car il fournit une faible latence (10 ms au 99e centile) pour lire les premiers articles recommandés pour un utilisateur donné.
- Machine Learning. Ce service est utilisé pour suivre et gérer des modèles Machine Learning, puis empaqueter et déployer ces modèles sur un environnement AKS scalable.
- Microsoft Recommenders. Ce dépôt open source contient le code des utilitaires et des exemples permettant aux utilisateurs de prendre en main la génération, l’évaluation et la mise en place d’un système de recommandation.
Détails du scénario
Cette architecture peut être étendue à la plupart des scénarios de moteur de recommandation, notamment des recommandations pour des produits, films et actualités.
Cas d’usage potentiels
Scénario : Une société de multimédia souhaite fournir des recommandations sur des vidéos ou des films à ses utilisateurs. En proposant des recommandations personnalisées, l’organisation répond à plusieurs objectifs de l’entreprise, dont des taux de clic plus élevés, un niveau d’engagement accru sur son site web et une plus grande satisfaction des utilisateurs.
Cette solution est optimisée pour le secteur de la vente au détail et pour les secteurs des médias et du divertissement.
Considérations
Ces considérations implémentent les piliers d’Azure Well-Architected Framework qui est un ensemble de principes directeurs qui permettent d’améliorer la qualité d’une charge de travail. Pour plus d’informations, consultez Microsoft Azure Well-Architected Framework.
Le scoring par lots des modèles Spark sur Azure Databricks décrit une architecture de référence qui utilise Spark et Azure Databricks pour exécuter des processus de scoring par lots planifiés. Nous recommandons cette approche pour générer de nouvelles recommandations.
Efficacité des performances
L’efficacité des performances est la capacité de votre charge de travail à s’adapter à la demande des utilisateurs de façon efficace. Pour plus d’informations, consultez Vue d’ensemble du pilier d’efficacité des performances.
Les performances représentent un aspect primordial pour les recommandations en temps réel, car celles-ci se situent généralement sur le chemin critique de la demande d’un utilisateur sur votre site web.
L’association d’AKS et d’Azure Cosmos DB permet à cette architecture de fournir un bon point de départ pour proposer des recommandations destinées à une charge de travail de taille moyenne avec une surcharge minimale. Sous un test de charge avec 200 utilisateurs simultanés, cette architecture fournit des recommandations à une latence moyenne d’environ 60 ms et fonctionne à un débit de 180 demandes par seconde. Le test de charge a été exécuté sur la configuration de déploiement par défaut (un cluster AKS 3x D3 v2 avec 12 processeurs virtuels, 42 Go de mémoire et 11 000 unités de requête par seconde provisionnées pour Azure Cosmos DB).
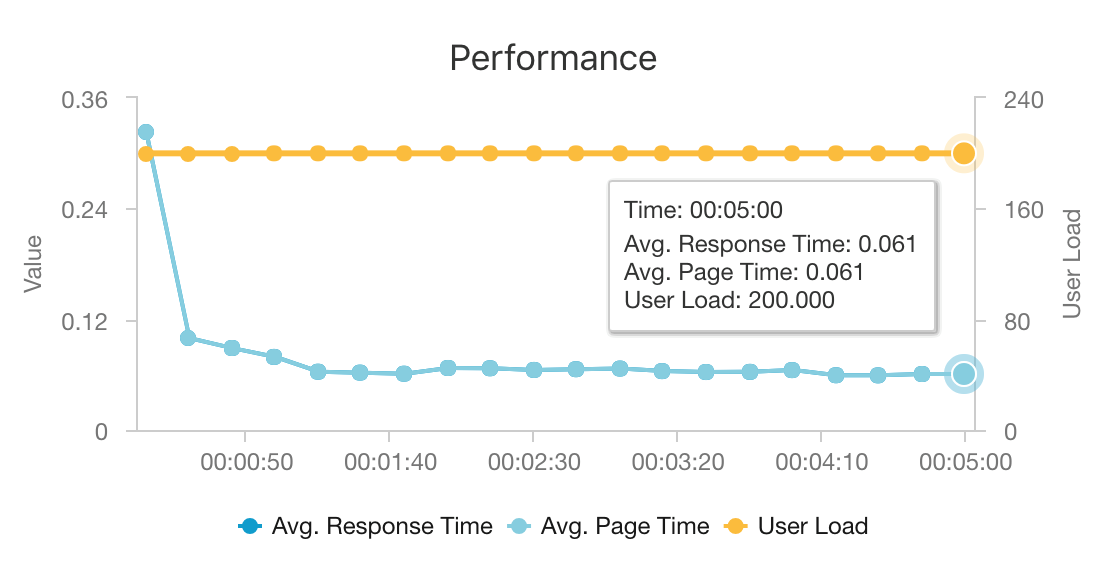
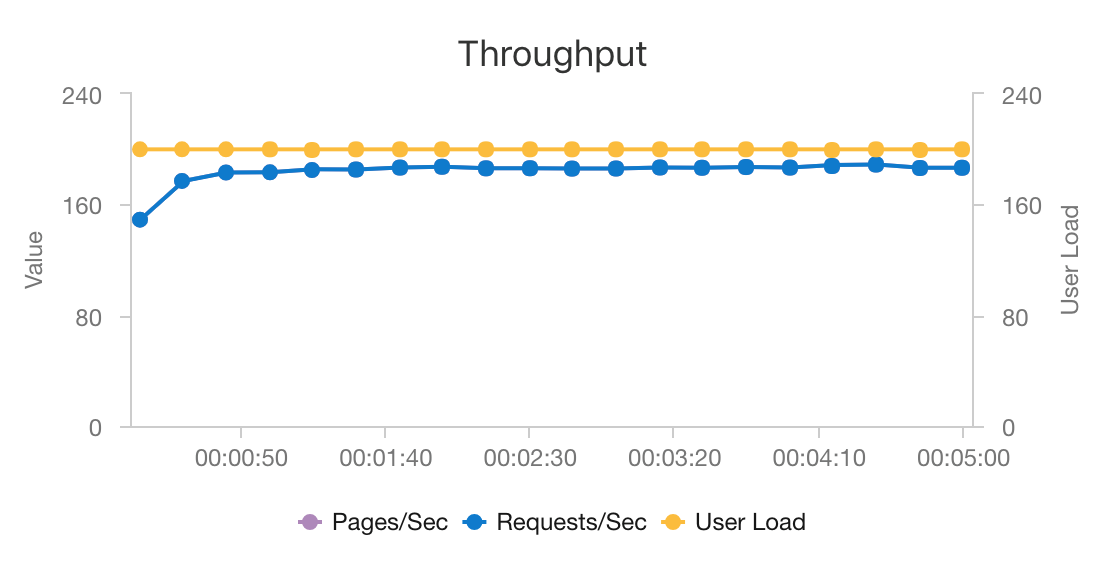
Azure Cosmos DB est recommandé pour sa distribution mondiale clés en main et son utilité pour répondre à toutes les exigences en matière de base de données de votre application. Pour légèrement réduire la latence, envisagez d’utiliser Azure Cache pour Redis au lieu d’Azure Cosmos DB pour servir les recherches. Azure Cache pour Redis peut améliorer les performances des systèmes qui reposent grandement sur les données dans les magasins back-end.
Extensibilité
Si vous n’envisagez pas d’utiliser Spark ou si vous avez une charge de travail plus petite qui ne doit pas être distribuée, pensez à utiliser Data Science Virtual Machine (DSVM) au lieu d’Azure Databricks. Une DSVM est une machine virtuelle Azure avec des outils et infrastructures de Deep Learning pour le Machine Learning et la science des données. Comme avec Azure Databricks, n’importe quel modèle que vous créez dans une machine virtuelle DSVM peut être rendu opérationnel en tant que service sur AKS via Machine Learning.
Pendant l’entraînement, approvisionnez un cluster Spark de taille fixe plus grand dans Azure Databricks ou configurez la mise à l’échelle automatique. Lorsque la mise à l’échelle automatique est activée, Databricks supervise la charge sur votre cluster et effectue un scale-up et un scale-down selon les besoins. Provisionnez un cluster plus grand ou effectuez un scale-out de celui-ci si vous avez une taille de données importante et que vous souhaitez réduire la quantité de temps nécessaire pour la préparation des données ou les tâches de modélisation.
Mettez le cluster AKS à l’échelle pour répondre à vos besoins en termes de performances et de débit. Prenez soin d’effectuer un scale-up du nombre de pods pour utiliser pleinement le cluster et de mettre à l’échelle les nœuds du cluster pour répondre à la demande de votre service. Vous pouvez également définir la mise à l’échelle automatique sur un cluster AKS. Pour plus d’informations, consultez Déployer un modèle sur un cluster Azure Kubernetes Service.
Pour gérer les performances Azure Cosmos DB, estimez le nombre de lectures nécessaires par seconde et provisionnez le nombre d’unités de requête par seconde (débit) nécessaire. Utilisez les bonnes pratiques pour le partitionnement et la mise à l’échelle horizontale.
Optimisation des coûts
L’optimisation des coûts consiste à examiner les moyens de réduire les dépenses inutiles et d’améliorer l’efficacité opérationnelle. Pour plus d’informations, consultez Vue d’ensemble du pilier d’optimisation des coûts.
Les principaux facteurs de coût dans ce scénario sont :
- Taille du cluster Azure Databricks nécessaire pour l’entraînement.
- Taille du cluster AKS nécessaire pour répondre à vos besoins de performance.
- Unités de requête Azure Cosmos DB provisionnées pour répondre à vos besoins de performance.
Gérez les coûts Azure Databricks en réentraînant moins fréquemment et en désactivant le cluster Spark quand il n’est pas utilisé. Les coûts AKS et Azure Cosmos DB sont liés aux performances et au débit requis par votre site, et augmentent et baissent selon le volume de trafic sur votre site.
Déployer ce scénario
Pour déployer cette architecture, suivez les instructions d’Azure Databricks dans le document de configuration. En bref, ces instructions vous demandent de réaliser les opérations suivantes :
- Créez un espace de travail Azure Databricks.
- Créez un cluster avec la configuration suivante dans Azure Databricks :
- Mode de cluster : Standard
- Version de Databricks Runtime : 4.3 (inclut Apache Spark 2.3.1, Scala 2.11)
- Version de Python : 3
- Type de pilote : Standard_DS3_v2
- Type de Worker : Standard_DS3_v2 (min. et max. en fonction des besoins)
- Arrêt automatique : (en fonction des besoins)
- Configuration de Spark : (en fonction des besoins)
- Variables d’environnement : (en fonction des besoins)
- Créez un jeton d’accès personnel dans l’espace de travail Azure Databricks. Pour plus d’informations, consultez la documentation sur l’authentification Azure Databricks.
- Clonez le dépôt Microsoft Recommenders dans un environnement où vous pouvez exécuter des scripts (par exemple, votre ordinateur local).
- Suivez les instructions d’installation rapide pour installer les bibliothèques appropriées sur Azure Databricks.
- Suivez les instructions d’installation rapide pour préparer Azure Databricks pour l’opérationnalisation.
- Importez le notebook ALS Movie Operationalization dans votre espace de travail. Une fois connecté à votre espace de travail Azure Databricks, procédez comme suit :
- Cliquez sur Accueil sur le côté gauche de l’espace de travail.
- Cliquez avec le bouton droit sur un espace blanc dans votre répertoire de base. Sélectionnez Importer.
- Sélectionnez URL et collez l’URL suivante dans la zone de texte :
https://github.com/Microsoft/Recommenders/blob/main/examples/05_operationalize/als_movie_o16n.ipynb - Cliquez sur Importer.
- Ouvrez le notebook dans Azure Databricks et attachez le cluster configuré.
- Exécutez le notebook pour créer les ressources Azure requises afin de créer une API de recommandation qui fournit les 10 meilleures recommandations de films pour un utilisateur donné.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteurs principaux :
- Miguel Fierro | Responsable en chef des scientifiques des données
- Nikhil Joglekar | Chef de produit, algorithmes Azure et science des données
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
- Génération d’une API de recommandation en temps réel
- Présentation d’Azure Databricks
- Azure Kubernetes Service
- Bienvenue dans Azure Cosmos DB
- Qu'est-ce que Microsoft Azure Machine Learning ?