Il est essentiel qu’une architecture de microservices intègre des API efficaces, car tous les échanges de données entre les services s’effectuent par le biais de messages ou d’appels d’API. Des API efficaces évitent la création d’E/S bavardes. Les services étant conçus par des équipes qui travaillent indépendamment les unes des autres, les API doivent comporter des schémas de sémantique et de contrôle de version bien définis afin que les mises à jour n’interrompent pas d’autres services.
Il est important d’établir une distinction entre deux types d’API :
- API publiques appelées par les applications clientes ;
- API principales utilisées pour la communication interservice.
Ces deux cas d’usage présentent des exigences quelque peu différentes. Une API publique doit être compatible avec les applications clientes, qui correspondent généralement à des applications de navigateur ou à des applications mobiles natives. La plupart du temps, cela signifie que l’API publique utilisera REST sur HTTP. En revanche, dans le cas des API principales, vous devez prendre en compte les performances réseau. Selon la granularité de vos services, la communication interservice peut entraîner un trafic réseau très dense. Les services sont susceptibles de devenir rapidement liés aux E/S. Il est alors indispensable de prendre en compte d’autres facteurs, tels que la vitesse de sérialisation et la taille de charge utile. Il existe certaines alternatives courantes à l’utilisation de REST sur HTTP, telles que gRPC, Apache Avro et Apache Thrift. Ces protocoles prennent en charge la sérialisation binaire et se révèlent généralement plus efficaces que HTTP.
Considérations
Voici quelques points à prendre en compte lors du choix du mode d’implémentation d’une API.
REST et RPC. Comparez les compromis induits par l’utilisation d’une interface de style REST et par l’emploi d’une interface de style RPC.
Le style REST modélise les ressources et peut ainsi vous permettre d’exprimer votre modèle de domaine de façon naturelle. Il définit une interface uniforme reposant sur les verbes HTTP, ce qui favorise l’évolutivité. REST comporte une sémantique bien définie en termes d’idempotence, d’effets secondaires et de codes de réponse. En outre, il applique une communication sans état, ce qui améliore l’extensibilité.
RPC est davantage axé sur les opérations ou sur les commandes. Étant donné que les interfaces RPC sont comparables à des appels de méthode locaux, elles peuvent vous amener à concevoir des API excessivement bavardes. Toutefois, cela n’implique pas que le mécanisme RPC soit lui-même bavard. Cela signifie simplement que vous devez accorder un soin tout particulier à la conception de l’interface.
Dans le cas d’une interface RESTful, le choix le plus courant consiste à utiliser REST sur HTTP à l’aide de JSON. Pour une interface de style RPC, il existe plusieurs frameworks courants, notamment gRPC, Apache Avro et Apache Thrift.
Efficacité. Considérez l’efficacité en termes de taille, de mémoire et de taille de charge utile. Une interface basée sur gRPC se révèle généralement plus rapide que REST sur HTTP.
Interface Definition Language (IDL) . Un langage IDL est utilisé pour définir les méthodes, les paramètres et les valeurs renvoyées d’une API. Il est possible d’utiliser un IDL pour générer le code client, le code de sérialisation et la documentation sur les API. Les IDL peuvent également être consommés par des outils de test d’API tels que Postman. Les infrastructures comme gRPC, Avro et Thrift définissent leurs propres spécifications IDL. REST sur HTTP ne présente pas un format IDL standard, mais un choix courant consiste à utiliser OpenAPI (anciennement Swagger). Vous pouvez également créer une API REST HTTP sans utiliser de langage de définition formel, mais vous perdrez alors les avantages des fonctions de génération et de test du code.
Sérialisation. De quelle manière les objets sont-ils sérialisés sur le réseau ? Les options possibles comprennent les formats reposant sur du texte (principalement JSON) et les formats binaires tels que la mémoire tampon de protocole. Les formats binaires sont généralement plus rapides que les formats texte. Toutefois, JSON présente des avantages en termes d’interopérabilité, car la plupart des langages et des infrastructures prennent en charge la sérialisation JSON. Certains formats de sérialisation nécessitent un schéma fixe, tandis que d’autres requièrent la compilation d’un fichier de définition de schéma. Dans ce cas, vous devrez intégrer cette étape dans votre processus de génération.
Infrastructures et langages pris en charge. Le protocole HTTP est pris en charge dans la quasi-totalité des infrastructures et des langages. Les infrastructures gRPC, Avro et Thrift comportent toutes des bibliothèques pour C++, C#, Java et Python. Thrift et gRPC prennent également en charge Go.
Compatibilité et interopérabilité. Si vous choisissez un protocole tel que gRPC, vous pouvez avoir besoin d’une couche de traduction de protocole entre l’API publique et le back end. Une passerelle peut assurer cette fonction. Si vous utilisez une maille de services, considérez les protocoles qui sont compatibles avec cette dernière. Par exemple, Linkerd intègre une prise en charge de HTTP, de Thrift et de gRPC.
Nous vous recommandons de choisir REST sur HTTP, sauf si vous souhaitez bénéficier des avantages en termes de performances offerts par un protocole binaire. REST sur HTTP ne requiert aucune bibliothèque spéciale. Il crée un couplage minimal, car les appelants n’ont pas besoin d’un stub client pour communiquer avec le service. Des écosystèmes d’outils élaborés prennent en charge les définitions de schéma, ainsi que les fonctions de test et de surveillance des points de terminaison HTTP RESTful. Enfin, HTTP est compatible avec les clients de navigateur, éliminant ainsi la nécessité de disposer d’une couche de traduction de protocole entre le client et le serveur principal.
Toutefois, si vous choisissez REST sur HTTP, vous devez procéder à des tests de performances et de charge au début du processus de développement afin de vérifier que cette méthode fournit des résultats satisfaisants pour votre scénario.
Conception d’API RESTful
Vous disposez de nombreuses ressources pour concevoir des API RESTful. Vous trouverez ci-après quelques ressources qui pourront vous être utiles :
Voici quelques considérations spécifiques à prendre en compte.
Prenez garde aux API qui communiquent des détails de l’implémentation interne ou qui reflètent simplement un schéma de base de données interne. L’API doit modéliser le domaine. Elle constitue un contrat entre les services, et dans l’idéal, ne doit changer qu’en cas d’ajout de nouvelles fonctionnalités, et non pour la simple raison que vous avez refactorisé du code ou normalisé une table de base de données.
Les tailles de charge utile ou les modèles d’interaction requis peuvent varier selon les types de clients (interface d’applications mobiles, navigateur web de bureau, etc.). Envisagez d’utiliser le modèle Back-ends pour front-ends afin de créer des back-ends pour chaque client, qui exposent une interface optimale pour le client concerné.
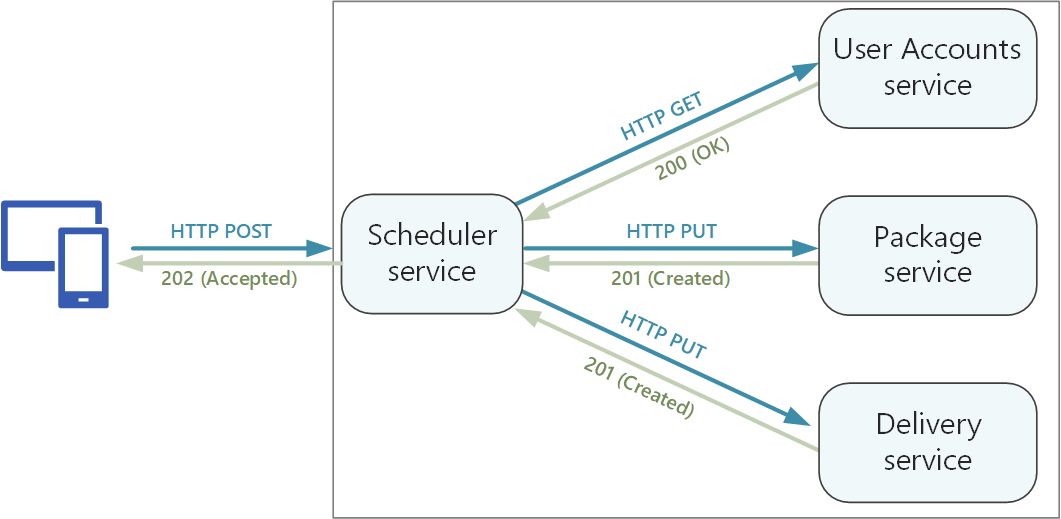
Dans le cas des opérations présentant des effets secondaires, faites en sorte de les rendre idempotentes et de les implémenter en tant que méthodes PUT. Cette approche autorise les nouvelles tentatives sécurisées et peut contribuer à améliorer la résilience. L'article Communication entre les services traite de cette question plus en détail.
Les méthodes HTTP peuvent présenter une sémantique asynchrone, dans le cadre de laquelle la méthode renvoie une réponse immédiatement, alors que le service exécute l’opération de façon asynchrone. Dans ce cas, la méthode doit renvoyer un code de réponse HTTP 202, qui indique que la requête a été acceptée pour traitement, mais que le traitement n’a pas encore été effectué. Pour plus d'informations, consultez Modèle de demande-réponse asynchrone.
Mappage des modèles REST sur les modèles de conception pilotée par le domaine
Les modèles tels que les objets d’entité, d’agrégat et de valeur sont conçus pour placer certaines contraintes sur les objets de votre modèle de domaine. Dans de nombreuses descriptions de l’approche de conception pilotée par le domaine, les modèles sont modélisés à l’aide de concepts de langage orienté objet tels que les constructeurs ou les méthodes getter et setter de propriété. Par exemple, les objets de valeur sont censés être immuables. Dans un langage de programmation orienté objet, vous appliquez cette règle en attribuant les valeurs dans le constructeur et en définissant les propriétés en lecture seule :
export class Location {
readonly latitude: number;
readonly longitude: number;
constructor(latitude: number, longitude: number) {
if (latitude < -90 || latitude > 90) {
throw new RangeError('latitude must be between -90 and 90');
}
if (longitude < -180 || longitude > 180) {
throw new RangeError('longitude must be between -180 and 180');
}
this.latitude = latitude;
this.longitude = longitude;
}
}
Ces types de pratiques de codage sont particulièrement importantes lorsque vous créez une application monolithique traditionnelle. Dans le cas d’une base de code volumineuse, de nombreux sous-systèmes sont susceptibles d’utiliser l’objet Location ; il est donc essentiel que l’objet applique le comportement adéquat.
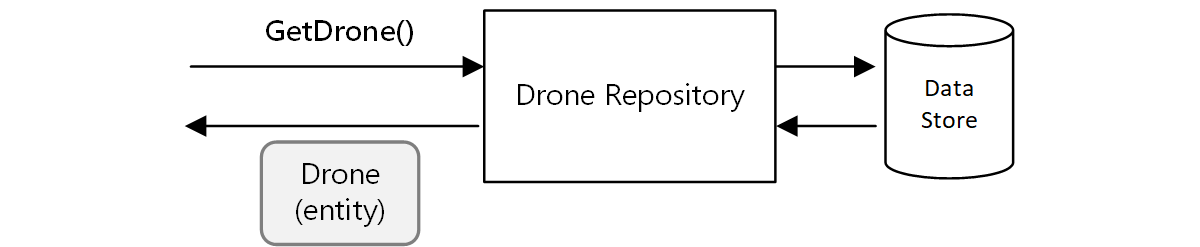
Un autre exemple concerne le modèle de référentiel, qui offre l’assurance que les autres parties de l’application n’effectuent pas de lectures ou d’écritures directes dans le magasin de données :
Toutefois, dans une architecture de microservices, les services ne partagent pas la même base de code, ni de magasins de données. A la place, ils communiquent par le biais d’API. Considérons le cas où le service Scheduler demande des informations concernant un drone du service Drone. Le service Drone comporte des modèles de drone internes, exprimés par l’intermédiaire d’un code. Toutefois, le service Scheduler ne voit pas ces modèles. A la place, il récupère une représentation de l’entité de drone, correspondant peut-être à un objet JSON dans une réponse HTTP.
Cet exemple est idéal pour les secteurs de l’aéronautique et de l’aérospatiale.
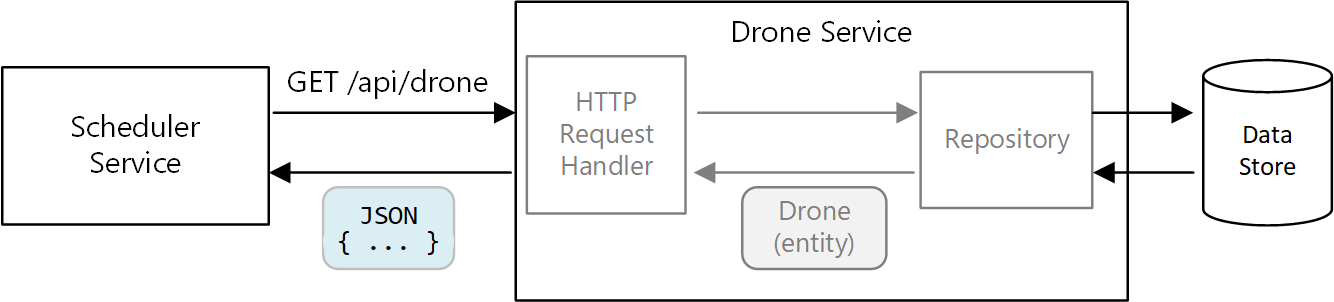
Le service Scheduler ne peut pas modifier les modèles internes du service Drone, ni écrire dans le magasin de données de ce service. Cela signifie que le code qui implémente le service Drone présente une surface d’exposition plus modeste que le code d’une application monolithique traditionnelle. Si le service Drone définit une classe Location, l’étendue de cette classe est limitée, et aucun autre service ne consommera directement la classe.
C’est la raison pour laquelle ce guide ne se concentre pas sur les pratiques de codage, car ces dernières sont liées aux modèles tactiques de conception pilotée par le domaine. Mais il s’avère que vous pouvez également modéliser de nombreux modèles de conception pilotée par le domaine par le biais des API REST.
Par exemple :
Les agrégats sont naturellement mappés sur des ressources dans REST. Par exemple, l’agrégat Delivery est exposé en tant que ressource par l’API Delivery.
Les agrégats sont des limites de cohérence. Les opérations sur les agrégats ne doivent jamais laisser un agrégat dans un état incohérent. Par conséquent, évitez de créer des API qui permettent à un client de manipuler l’état interne d’un agrégat. À la place, favorisez les API de granularité grossière qui exposent les agrégats sous forme de ressources.
Les entités sont dotées d’identités uniques. Dans REST, les ressources comportent des identificateurs uniques qui prennent la forme d’URL. Créez des URL de ressource qui correspondent à l’identité de domaine d’une entité. Le mappage d’une URL sur l’identité de domaine peut être opaque pour le client.
Il est possible d’atteindre les entités enfants d’un agrégat en naviguant à partir de l’entité racine. Si vous suivez les principes HATEOAS, les entités enfants sont accessibles par le biais de liens dans la représentation de l’entité parente.
Étant donné que les objets de valeur sont immuables, les mises à jour s’effectuent en remplaçant la totalité de l’objet de valeur. Dans REST, implémentez les mises à jour par l’intermédiaire de requêtes PUT ou PATCH.
Un référentiel permet aux clients de rechercher, ajouter ou supprimer des objets dans une collection, en extrayant les détails du magasin de données sous-jacent. Dans REST, une collection peut constituer une ressource distincte, avec des méthodes d’interrogation de la collection ou d’ajout de nouvelles entités à la collection.
Lorsque vous concevez vos API, pensez à la façon dont elles expriment le modèle de domaine ; ne considérez pas uniquement les données à l’intérieur du modèle, mais également les opérations d’entreprise et les contraintes sur les données.
| Concept de conception pilotée par le domaine | Équivalent REST | Exemple |
|---|---|---|
| Agrégat | Ressource | { "1":1234, "status":"pending"... } |
| Identité | URL | https://delivery-service/deliveries/1 |
| Entités enfants | Liens | { "href": "/deliveries/1/confirmation" } |
| Mise à jour des objets de valeur | PUT ou PATCH | PUT https://delivery-service/deliveries/1/dropoff |
| Référentiel | Collection | https://delivery-service/deliveries?status=pending |
Contrôle de version d’API
Une API est un contrat entre un service et des clients ou des consommateurs de ce service. Si une API change, il existe un risque d’arrêt des clients qui dépendent de cette API, qu’il s’agisse de clients externes ou d’autres microservices. Par conséquent, n’apportez qu’un nombre de modifications minimal à vos API. La plupart du temps, les changements apportés à l’implémentation sous-jacente ne nécessitent aucune modification de l’API. Toutefois, dans la pratique, il arrivera un moment où vous souhaiterez ajouter de nouvelles fonctionnalités ou capacités nécessitant la modification d’une API existante.
Chaque fois que possible, faites en sorte que ces modifications d’API soient à compatibilité descendante. Par exemple, évitez de supprimer un champ d’un modèle, car cette opération risque d’arrêter les clients qui s’attendent à trouver ce champ à cet emplacement. L’ajout d’un champ n’interrompt pas la compatibilité, car les clients doivent ignorer tous les champs qu’ils ne comprennent pas dans une réponse. Toutefois, le service doit gérer les cas où un client plus ancien omet le nouveau champ dans une requête.
Prenez en charge le contrôle de version dans votre contrat d’API. Si vous introduisez une modification d’API entraînant un arrêt, proposez une nouvelle version de l’API. Continuez à prendre en charge la version précédente et offrez aux clients la possibilité de sélectionner la version à appeler. Vous pouvez procéder de deux manières. La première méthode consiste à exposer simplement les deux versions dans le même service. La seconde méthode consiste à exécuter deux versions du service côte à côte et à acheminer les requêtes vers l’une ou l’autre version en fonction des règles d’acheminement HTTP.
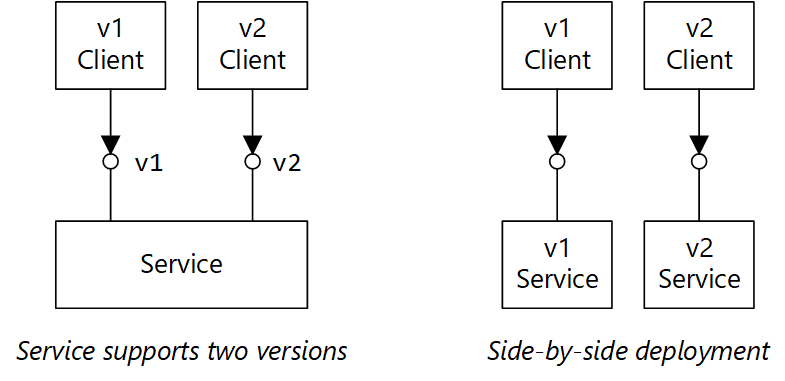
Le diagramme comporte deux parties. « Le service prend en charge deux versions » indique que le client v1 et le client v2 pointent tous deux vers un même service. « Déploiement côte à côte » montre le client v1 pointant vers un service v1 et le client v2 pointant vers un service v2.
La prise en charge de plusieurs versions implique différents coûts en termes de temps de développement, de test et de fonctionnement. Il est donc judicieux de déconseiller l’utilisation des anciennes versions le plus rapidement possible. Dans le cas des API internes, l’équipe propriétaire de l’API peut collaborer avec d’autres équipes pour aider ces dernières à effectuer la migration vers la nouvelle version. Dans ce contexte, un processus de gouvernance entre les différentes équipes se révèle particulièrement utile. Dans le cas des API externes (publiques), il peut être plus difficile de déconseiller une version d’API, en particulier si l’API est consommée par des tiers ou par des applications clientes natives.
Lorsqu’une implémentation de service change, il est utile d’identifier cette modification par une version. La version fournit des informations importantes lors de la résolution des erreurs. Dans le cadre de l’analyse de la cause racine, il peut se révéler très utile de connaître précisément la version du service qui a été appelée. Envisagez d’utiliser la gestion sémantique de version pour les versions de service. La gestion sémantique de version utilise un format MAJOR.MINOR.PATCH. Toutefois, les clients doivent uniquement sélectionner une API par son numéro de version principale, ou éventuellement par son numéro de version mineure si les modifications qui existent entre les différentes versions mineures sont importantes, mais n’entraînent pas d’arrêt. En d’autres termes, il est raisonnable de permettre aux clients de choisir entre les versions 1 et 2 d’une API, mais non de les laisser sélectionner la version 2.1.3. Si vous autorisez un tel niveau de granularité, vous serez probablement contraint de prendre en charge une multitude de versions.
Pour plus d’informations sur le contrôle de version d’API, consultez la section Contrôle de version d’une API web RESTful.
Opérations idempotentes
Une opération est idempotente si elle peut être appelée plusieurs fois sans produire d'effets secondaires supplémentaires après le premier appel. L'idempotence peut être une stratégie de résilience utile car elle permet à un service situé en amont d'appeler plusieurs fois une opération en toute sécurité. Pour plus d'informations sur ce point, consultez Transactions distribuées.
La spécification HTTP stipule que les méthodes GET, PUT et DELETE doivent être idempotentes. Le caractère idempotent des méthodes POST n’est pas garanti. Si une méthode POST crée une ressource, il n’existe généralement aucune garantie que cette opération soit idempotente. La spécification définit le terme « idempotent » de cette façon :
Une méthode de demande est dite « idempotente » si l’exécution de plusieurs requêtes identiques à l’aide de cette méthode est censée produire le même effet sur le serveur que l’exécution d’une seule de ces requêtes. (RFC 7231)
Il est important de bien comprendre la différence entre les sémantiques PUT et POST lors de la création d’une entité. Dans les deux cas, le client envoie une représentation d’une entité dans le corps de la requête. Toutefois, la signification de l’URI diffère.
Dans le cas d’une méthode POST, l’URI représente une ressource parente de la nouvelle entité, telle qu’une collection. Par exemple, l’URI utilisé pour la création d’une livraison pourrait être
/api/deliveries. Le serveur crée l’entité et lui attribue un nouvel URI, tel que/api/deliveries/39660. Cet URI est renvoyé dans l’en-tête Location de la réponse. Chaque fois que le client envoie une requête, le serveur crée une entité avec un nouvel URI.Dans le cas d’une méthode PUT, l’URI identifie l’entité. Si une entité présente déjà cet URI, le serveur remplace l’entité existante par la version dans la requête. Si aucune entité ne présente cet URI, le serveur en crée une. Par exemple, supposons que le client envoie une requête PUT à
api/deliveries/39660. Si aucune livraison ne présente cet URI, le serveur en crée une. Si le client envoie de nouveau la même requête par la suite, le serveur remplacera l’entité existante.
Voici l’implémentation de la méthode PUT dans le service Delivery.
[HttpPut("{id}")]
[ProducesResponseType(typeof(Delivery), 201)]
[ProducesResponseType(typeof(void), 204)]
public async Task<IActionResult> Put([FromBody]Delivery delivery, string id)
{
logger.LogInformation("In Put action with delivery {Id}: {@DeliveryInfo}", id, delivery.ToLogInfo());
try
{
var internalDelivery = delivery.ToInternal();
// Create the new delivery entity.
await deliveryRepository.CreateAsync(internalDelivery);
// Create a delivery status event.
var deliveryStatusEvent = new DeliveryStatusEvent { DeliveryId = delivery.Id, Stage = DeliveryEventType.Created };
await deliveryStatusEventRepository.AddAsync(deliveryStatusEvent);
// Return HTTP 201 (Created)
return CreatedAtRoute("GetDelivery", new { id= delivery.Id }, delivery);
}
catch (DuplicateResourceException)
{
// This method is mainly used to create deliveries. If the delivery already exists then update it.
logger.LogInformation("Updating resource with delivery id: {DeliveryId}", id);
var internalDelivery = delivery.ToInternal();
await deliveryRepository.UpdateAsync(id, internalDelivery);
// Return HTTP 204 (No Content)
return NoContent();
}
}
En principe, la plupart des requêtes créeront une entité ; par conséquent, la méthode anticipe les choses en appelant CreateAsync sur l’objet de référentiel, puis traite toutes les exceptions de ressources en double en mettant à jour la ressource à la place.
Étapes suivantes
Apprenez à utiliser une passerelle API à la frontière entre les applications clientes et les microservices.