Cette architecture de référence montre comment appliquer un transfert de style neuronal à une vidéo avec Azure Machine Learning. Le transfert de style est une technique d’apprentissage profond (« deep learning ») qui compose une image existante dans le style d’une autre image. Vous pouvez généraliser cette architecture à un scénario qui utilise le scoring par lots avec le Deep Learning.
Architecture
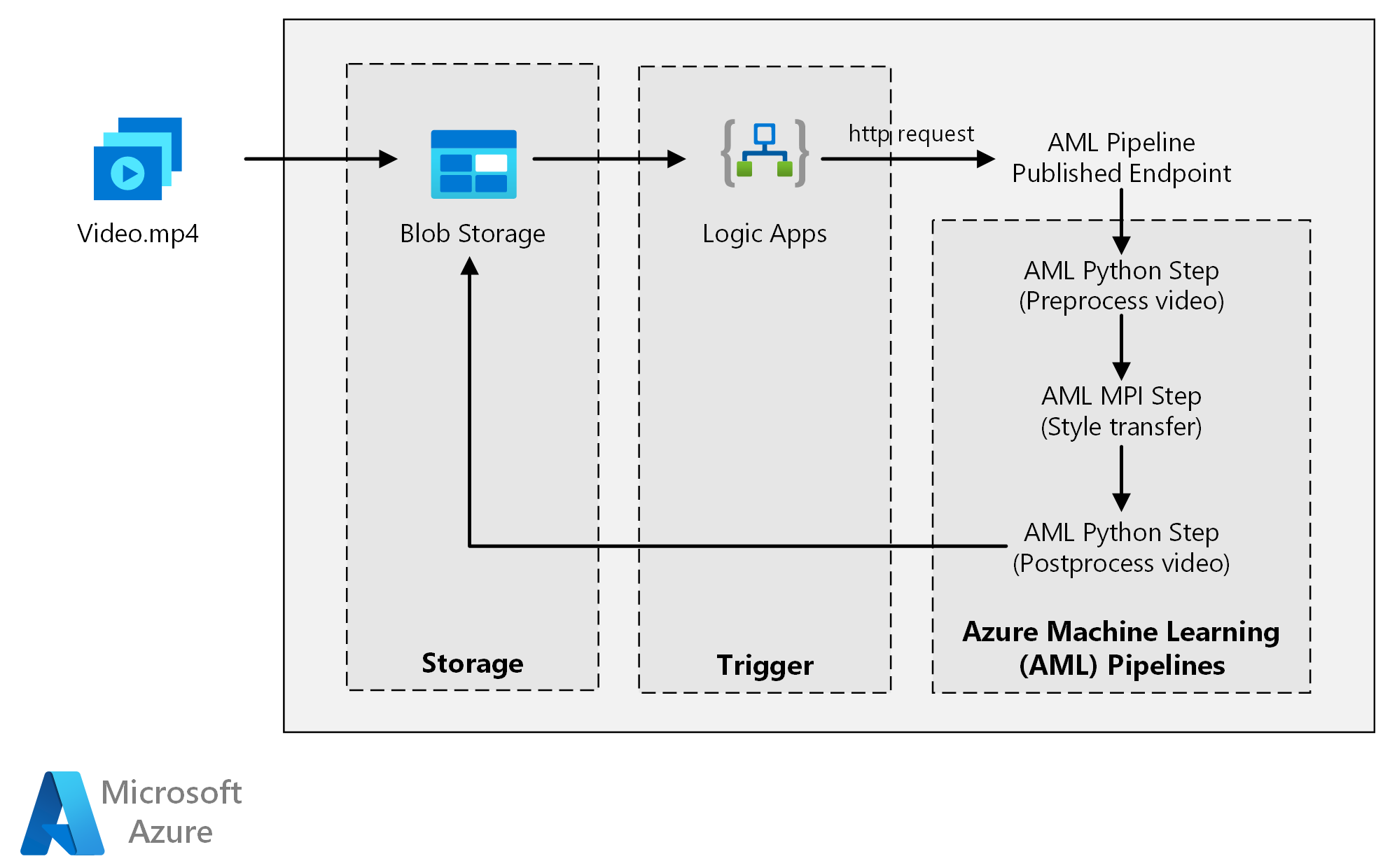
Téléchargez un fichier Visio de cette architecture.
Workflow
Cette architecture est constituée des composants suivants.
Calcul
Azure Machine Learning utilise des pipelines pour créer des séquences de calcul reproductibles et faciles à gérer. Il offre également une cible de calcul managée (sur laquelle un calcul de pipeline peut s’exécuter) appelée Capacité de calcul Azure Machine Learning pour l’entraînement, le déploiement et le scoring des modèles Machine Learning.
Stockage
Stockage Blob Azure stocke toutes les images (images d’entrée, images de style et images de sortie). La solution Azure Machine Learning s’intégrant avec le service Stockage Blob Azure, les utilisateurs ne doivent pas déplacer manuellement les données entre les plateformes de calcul et les stockages d’objets blob. Le service Stockage Blob Azure s’avère aussi très économique par rapport aux performances qu’exige cette charge de travail.
Déclencheur
Azure Logic Apps déclenche le workflow. Quand l’application logique détecte qu’un objet blob a été ajouté au conteneur, elle déclenche le pipeline Azure Machine Learning. Logic Apps est parfaitement adapté à cette architecture de référence, car il permet de détecter facilement les modifications apportées au stockage Blob, avec un processus simple pour modifier le déclencheur.
Prétraiter et post-traiter les données
Cette architecture de référence utilise la séquence vidéo d’un orang-outan dans un arbre.
- Utilisez FFmpeg pour extraire le fichier audio de la séquence vidéo, de façon à pouvoir le réincorporer par la suite dans la vidéo en sortie.
- Utilisez FFmpeg pour découper la vidéo en images individuelles. Les images sont traitées indépendamment, en parallèle.
- À ce stade, vous pouvez appliquer le transfert de style neuronal en parallèle à chaque image individuelle.
- Lorsque chaque image a été traitée, utilisez FFmpeg pour les réassembler.
- Enfin, réattachez le fichier audio à la séquence vidéo réassemblée.
Components
Détails de la solution
Cette architecture de référence a été conçue pour les charges de travail qui sont déclenchées par la présence de nouveaux contenus multimédias dans Azure Storage.
Le traitement est constitué des étapes suivantes :
- Téléchargez le fichier vidéo dans Stockage Blob Azure.
- Le fichier vidéo déclenche l’envoi par Azure Logic Apps d’une demande au point de terminaison publié du pipeline Azure Machine Learning.
- Le pipeline traite la vidéo, applique le transfert de style avec MPI et effectue le post-traitement de la vidéo.
- La sortie est réenregistrée dans le stockage blob une fois le pipeline terminé.
Cas d’usage potentiels
une société de multimédia souhaite changer le style d’une vidéo pour qu’elle ressemble à une peinture spécifique. L’organisation veut appliquer ce style à toutes les images de la vidéo en temps voulu et de façon automatisée. Pour plus d’informations sur les algorithmes de transfert de style neuronal, consultez le document Image Style Transfer Using Convolutional Neural Networks (PDF).
Considérations
Ces considérations implémentent les piliers d’Azure Well-Architected Framework qui est un ensemble de principes directeurs qui permettent d’améliorer la qualité d’une charge de travail. Pour plus d'informations, consultez Microsoft Azure Well-Architected Framework.
Efficacité des performances
L’efficacité des performances est la capacité de votre charge de travail à s’adapter à la demande des utilisateurs de façon efficace. Pour plus d’informations, consultez Vue d’ensemble du pilier d’efficacité des performances.
GPU et UC
Pour les charges de travail de Deep Learning, les GPU (processeurs graphiques) sont généralement beaucoup plus performants que les CPU (processeurs centraux), dans la mesure où il faut généralement un cluster de CPU important pour obtenir des performances comparables. Bien qu’il soit possible d’utiliser uniquement des CPU dans cette architecture, les GPU offrent un bien meilleur rapport coût/performances. Nous vous recommandons d’utiliser la dernière série NCv3 de GPU optimisés.
Les GPU ne sont pas compatibles par défaut dans toutes les régions. Veillez à sélectionner une région compatible avec les GPU. Par ailleurs, les abonnements ont un quota par défaut de zéro cœur pour les machines virtuelles optimisées pour les GPU. Vous pouvez augmenter ce quota en formulant une demande de support. Vérifiez que votre abonnement dispose d’un quota suffisant pour exécuter votre charge de travail.
Paralléliser dans les machines virtuelles et les cœurs
Quand vous exécutez un processus de transfert de style en tant que traitement par lots, les tâches qui s’exécutent principalement sur les GPU doivent être parallélisées dans toutes les machines virtuelles. Deux approches sont possibles : vous pouvez soit créer un cluster plus grand contenant des machines virtuelles avec un seul GPU, soit créer un cluster plus petit contenant des machines virtuelles avec un grand nombre de GPU.
Pour cette charge de travail, ces deux options offrent des performances comparables. Le fait d’utiliser moins de machines virtuelles avec plus de GPU par machine virtuelle peut contribuer à réduire le déplacement de données. Cependant, le volume de données par tâche pour cette charge de travail n’étant pas très important, la limitation imposée par le stockage Blob n’est pas significative.
Étape MPI
Lors de la création du pipeline Azure Machine Learning, une des étapes utilisées pour effectuer le calcul parallèle est celle de la MPI (interface de traitement de message). L’étape MPI aide à fractionner les données uniformément entre les nœuds disponibles. L’étape MPI n’est pas exécutée tant que tous les nœuds demandés ne sont pas prêts. Si un nœud échoue ou est préempté (s’il s’agit d’une machine virtuelle de faible priorité), l’étape MPI doit être réexécutée.
Sécurité
La sécurité fournit des garanties contre les attaques délibérées, et contre l’utilisation abusive de vos données et systèmes importants. Pour plus d’informations, consultez Vue d’ensemble du pilier Sécurité. Cette section contient des considérations relatives à l'élaboration de solutions sécurisées.
Restreindre l’accès au stockage Blob Azure
Dans cette architecture de référence, Stockage Blob Azure est le composant de stockage principal qui doit être protégé. Le déploiement de référence présenté dans le dépôt GitHub utilise des clés de compte de stockage pour accéder à Stockage Blob. Pour une protection et un contrôle accrus, envisagez d’utiliser une signature d’accès partagé (SAP). Elle octroie un accès limité aux objets contenus dans le stockage, sans qu’il soit nécessaire de coder en dur les clés de compte ou de les enregistrer en texte clair. Cette approche est particulièrement utile, car les clés de compte sont visibles en texte clair à l’intérieur de l’interface du concepteur de l’application logique. L’utilisation d’une signature SAP permet aussi de s’assurer que le compte de stockage obéit à une gouvernance appropriée et que l’accès est octroyé uniquement aux personnes censées en bénéficier.
Dans les scénarios faisant intervenir des données plus sensibles, veillez à ce que toutes vos clés de stockage soient protégées, car elles octroient un accès complet à toutes les données d’entrée et de sortie de la charge de travail.
Chiffrement des données et déplacement des données
Cette architecture de référence utilise le transfert de style comme exemple de processus de scoring par lots. Pour les scénarios avec des données plus sensibles, les données contenues dans le stockage doivent être chiffrées au repos. Chaque fois que des données se déplacent d’un emplacement à l’autre, utilisez le protocole TLS (Transport Layer Security) pour sécuriser le transfert des données. Pour plus d’informations, consultez le guide de sécurité Stockage Azure.
Sécuriser votre calcul dans un réseau virtuel
Lors du déploiement de votre cluster de capacité de calcul Machine Learning, vous pouvez le configurer pour qu’il soit provisionné à l’intérieur du sous-réseau d’un réseau virtuel. Ce sous-réseau permet aux nœuds de calcul du cluster de communiquer de façon sécurisée avec d’autres machines virtuelles.
Protéger contre les activités malveillantes
Dans les scénarios à plusieurs utilisateurs, veillez à ce que les données sensibles soient protégées contre les activités malveillantes. Si l’accès à ce déploiement est octroyé à d’autres utilisateurs pour leur permettre de personnaliser les données d’entrée, prenez note des précautions et des considérations suivantes :
- Utilisez un contrôle d’accès en fonction du rôle Azure (RBAC) pour limiter l’accès des utilisateurs aux seules ressources dont ils ont besoin.
- Provisionnez deux comptes de stockage distincts. Stockez les données d’entrée et de sortie dans le premier compte. L’accès à ce compte peut être octroyé à des utilisateurs externes. Stockez les scripts exécutables et les fichiers journaux de sortie dans l’autre compte. Les utilisateurs externes ne doivent pas avoir accès à ce compte. Cette séparation garantit que des utilisateurs externes ne puissent pas modifier les fichiers exécutables (pour injecter du code malveillant) ni accéder aux fichiers journaux, qui peuvent contenir des informations sensibles.
- Des utilisateurs malveillants peuvent lancer une attaque DDoS contre de la file d’attente des travaux ou injecter dans celle-ci des messages incohérents mal formés, entraînant ainsi le blocage du système ou des erreurs de retrait de la file d’attente.
Optimisation des coûts
L’optimisation des coûts consiste à examiner les moyens de réduire les dépenses inutiles et d’améliorer l’efficacité opérationnelle. Pour plus d’informations, consultez Vue d’ensemble du pilier d’optimisation des coûts.
Par rapport aux composants de stockage et de planification, les ressources de calcul utilisées dans cette architecture de référence s’avèrent nettement plus coûteuses. L’une des principales difficultés est de paralléliser efficacement les tâches dans un cluster de machines compatibles avec les GPU.
La taille du cluster de capacité de calcul Azure Machine Learning peut faire l’objet d’un scale-up ou d’un scale-down automatique, en fonction des travaux présents dans la file d’attente. Vous pouvez activer la mise à l’échelle automatique par programmation en définissant le nombre minimal et le nombre maximal de nœuds.
Pour les tâches qui ne nécessitent pas un traitement immédiat, configurez la mise à l’échelle automatique, de sorte que l’état par défaut (minimal) soit un cluster sans nœud. Avec cette configuration, le cluster démarre sans nœud et ne monte en puissance que s’il détecte des tâches dans la file d’attente. Si le processus de scoring par lots ne s’enclenche que quelques fois par jour, ce paramètre permet de réaliser des économies conséquentes.
La mise à l’échelle pourrait ne pas convenir pour les tâches Batch trop rapprochées les unes des autres. Le temps nécessaire au lancement et à l’arrêt d’un cluster a aussi un coût. De ce fait, si une charge de travail Batch commence seulement quelques minutes après la fin de la tâche précédente, il peut être plus rentable de laisser le cluster s’exécuter entre les tâches.
La Capacité de calcul Machine Learning Azure prenant également en charge les machines virtuelles de faible priorité, il vous permet d’exécuter vos calculs sur des machines virtuelles à prix réduit, l’inconvénient étant que celles-ci pourraient être préemptées à tout moment. Les machines virtuelles de faible priorité sont idéales pour les charges de travail de scoring par lots qui ne sont pas critiques.
Surveiller les travaux de traitement par lots
Pendant que vous exécutez votre tâche, il est important de surveiller la progression et de vérifier que tout fonctionne comme prévu. Cependant, superviser un cluster de nœuds actifs peut s’avérer ardu.
Pour vérifier l’état global du cluster, accédez au service Machine Learning sur le portail Azure pour inspecter l’état des nœuds du cluster. Si un nœud est inactif ou si un travail a échoué, vous pouvez consulter les journaux d’activité d’erreurs enregistrés dans Stockage Blob. Ils sont également accessibles dans le Portail Azure.
La supervision peut encore être approfondie en connectant les journaux d’activité à Application Insights, ou en exécutant des processus distincts pour interroger l’état du cluster et de ses travaux.
Se connecter avec Azure Machine Learning
Azure Machine Learning journalise automatiquement tous les stdout/stderr dans le compte de stockage Blob associé. Sauf indication contraire, votre espace de travail Azure Machine Learning provisionne automatiquement un compte de stockage et y enregistre vos journaux d’activité. Vous pouvez également utiliser un outil de navigation de stockage comme l’Explorateur Stockage Azure, qui est un moyen plus simple de parcourir les fichiers journaux.
Déployer ce scénario
Pour déployer cette architecture de référence, suivez les étapes décrites dans le dépôt GitHub.
Vous pouvez également déployer une architecture de scoring par lots pour les modèles d’apprentissage profond avec Azure Kubernetes Service. Suivez les étapes décrites dans ce référentiel GitHub.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Jian Tang | Gestionnaire de programmes II
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
- Scoring par lots de modèles Spark sur Azure Databricks
- Scoring par lots des modèles Python sur Azure
- Scoring par lot avec les modèles R pour prévoir les ventes