Copier et transformer des données dans Amazon Simple Storage Service avec Azure Data Factory ou Azure Synapse Analytics
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article explique comment utiliser l’activité Copy pour copier des données à partir d’Amazon Simple Storage Service (Amazon S3) et comment utiliser Data Flow pour transformer les données dans Amazon S3. Pour plus d'informations, consultez les articles de présentation d'Azure Data Factory et de Synapse Analytics.
Conseil
Pour en savoir plus sur le scénario de migration de données d'Amazon S3 vers le service Stockage Azure, consultez Migrer des données d'Amazon S3 vers le service Stockage Azure.
Fonctionnalités prises en charge
Ce connecteur Amazon S3 est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité de copie (source/-) | |
| Mappage de flux de données (source/récepteur) | 0 |
| Activité de recherche | |
| Activité GetMetadata | |
| Supprimer l’activité |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Plus spécifiquement, ce connecteur Amazon S3 prend en charge la copie de fichiers en l’état ou l’analyse de fichiers avec les formats de fichier et codecs de compression pris en charge. Vous pouvez également choisir de conserver les métadonnées de fichier lors de la copie. Le connecteur utilise AWS Signature version 4 pour authentifier les demandes auprès d’Amazon S3.
Conseil
Si vous souhaitez copier des données à partir de n’importe quel fournisseur de stockage compatible S3, consultez Stockage compatible Amazon S3.
Autorisations requises
Pour copier des données à partir d’Amazon S3, veillez à disposer des autorisations s3:GetObject et s3:GetObjectVersion pour les opérations d’objet Amazon S3.
Si vous utilisez l’interface utilisateur de Data Factory pour créer, sachez que des autorisations s3:ListAllMyBuckets et s3:ListBucket/s3:GetBucketLocation supplémentaires sont nécessaires pour les opérations telles que le test de connexion au service lié et la navigation à partir de la racine. Si vous ne souhaitez pas accorder ces autorisations, vous pouvez choisir les options « Test connection to file path » (« Tester la connexion au chemin du fichier ») ou « Browse from specified path » («Parcourir à partir du chemin spécifié ») dans interface utilisateur.
Pour obtenir la liste complète des autorisations Amazon S3, consultez l’article Spécification des autorisations d’une stratégie sur le site AWS.
Prise en main
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
Créer un service lié Amazon Simple Stockage Service (S3) à l’aide de l’interface utilisateur
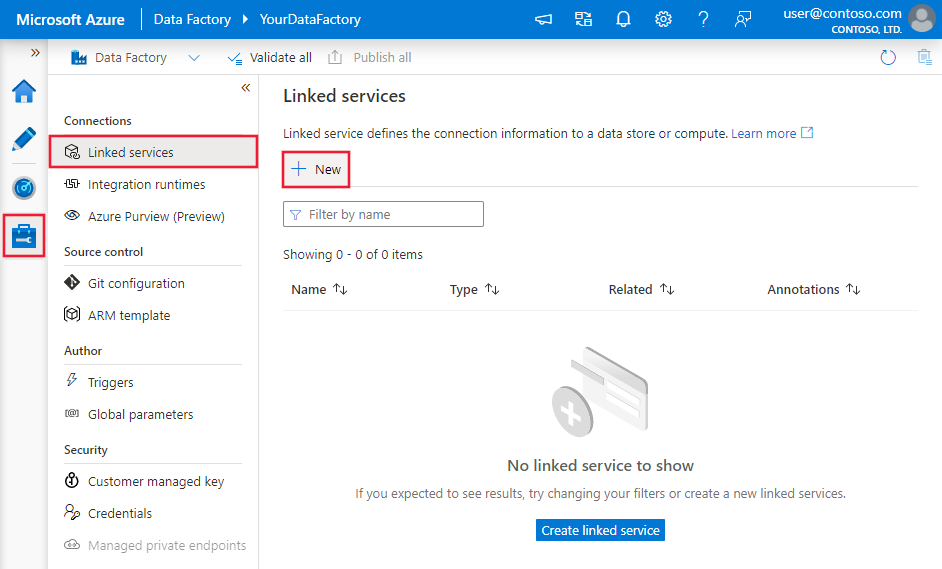
Utilisez les étapes suivantes pour créer un service lié Amazon S3 dans l’interface utilisateur du portail Azure.
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse, sélectionnez Services liés, puis cliquez sur Nouveau :
Recherchez Amazon et sélectionnez le connecteur Amazon S3.
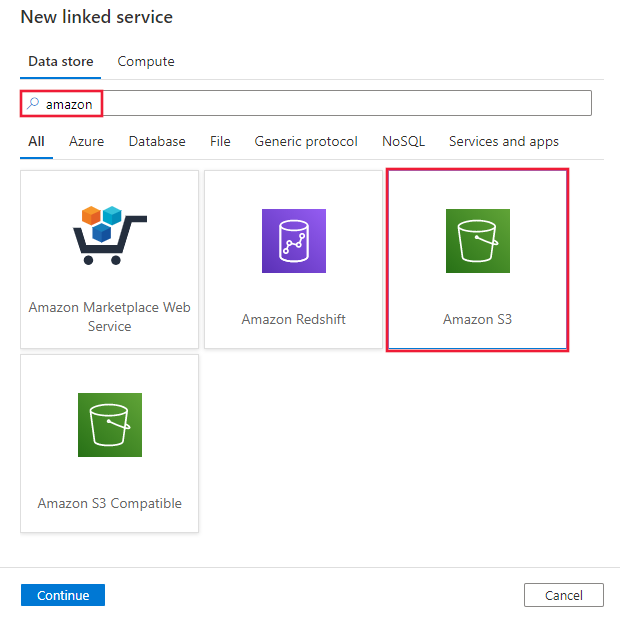
Configurez les informations du service, testez la connexion et créez le nouveau service lié.
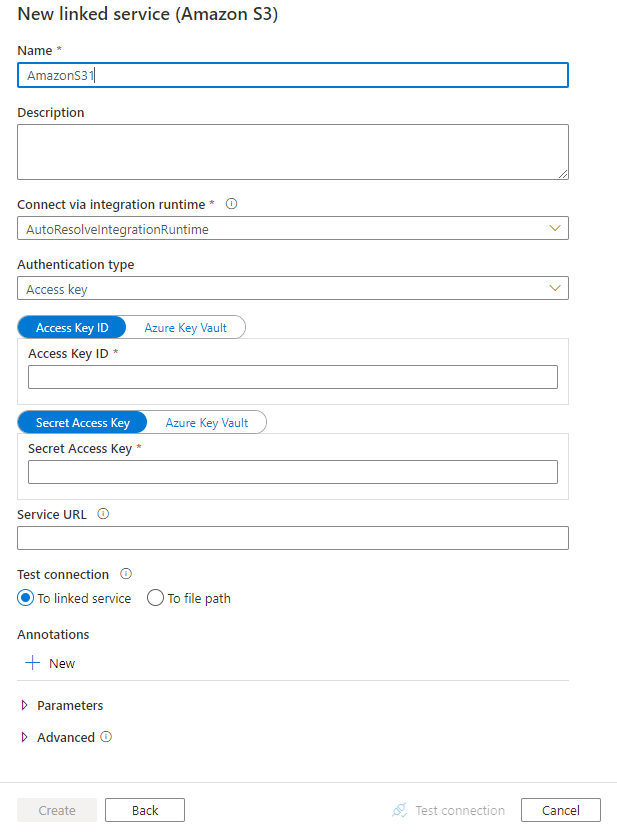
Informations de configuration du connecteur
Les sections suivantes fournissent des informations sur les propriétés utilisées pour définir les entités Data Factory spécifiques d’Amazon S3.
Propriétés du service lié
Les propriétés prises en charge pour un service lié Amazon S3 prises en charge sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur AmazonS3. | Oui |
| authenticationType | Spécifiez le type d’authentification utilisé pour se connecter à Amazon S3. Vous pouvez choisir d’utiliser des clés d’accès pour un compte de gestion des identités et des accès (IAM) AWS, ou des informations d’identification de sécurité temporaires. Les valeurs autorisées sont AccessKey (par défaut) et TemporarySecurityCredentials. |
Non |
| accessKeyId | ID de la clé d’accès secrète. | Oui |
| secretAccessKey | La clé d’accès secrète elle-même. Marquez ce champ en tant que SecureString afin de le stocker en toute sécurité, ou référencez un secret stocké dans Azure Key Vault. | Oui |
| sessionToken | S’applique lors de l’utilisation de l’authentification par informations d’identification de sécurité temporaires. Découvrez comment demander des informations d’identification de sécurité temporaires auprès de AWS. Notez que les informations d’identification temporaires AWS expirent entre 15 minutes et 36 heures en fonction des paramètres. Assurez-vous que vos informations d’identification sont valides lorsque l’activité s’exécute, en particulier pour les charges de travail mises en œuvre ; vous pouvez par exemple les actualiser régulièrement et les stocker dans Azure Key Vault. Marquez ce champ en tant que SecureString afin de le stocker en toute sécurité, ou référencez un secret stocké dans Azure Key Vault. |
Non |
| serviceUrl | Spécifiez le point de terminaison S3 personnalisé https://<service url>.Modifiez-le uniquement si vous souhaitez essayer un autre point de terminaison de service ou si vous souhaitez basculer entre https et http. |
Non |
| connectVia | Le runtime d’intégration à utiliser pour se connecter à la banque de données. Vous pouvez utiliser le runtime d’intégration Azure ou un runtime d’intégration auto-hébergé (si votre banque de données se trouve sur un réseau privé). Si cette propriété n’est pas spécifiée, le service utilise le runtime d’intégration Azure par défaut. | Non |
Exemple : Utilisation de l’authentification par clé d’accès
{
"name": "AmazonS3LinkedService",
"properties": {
"type": "AmazonS3",
"typeProperties": {
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemple : Utilisation de l’authentification par informations d’identification de sécurité temporaires
{
"name": "AmazonS3LinkedService",
"properties": {
"type": "AmazonS3",
"typeProperties": {
"authenticationType": "TemporarySecurityCredentials",
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
},
"sessionToken": {
"type": "SecureString",
"value": "<session token>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article Jeux de données.
Azure Data Factory prend en charge les formats de fichier suivants. Reportez-vous à chaque article pour les paramètres basés sur le format.
- Format Avro
- Format binaire
- Format de texte délimité
- Format Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Les propriétés suivantes sont prises en charge pour les objets Amazon S3 sous les paramètres location dans un jeu de données basé sur le format :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type sous location dans le jeu de données doit être définie sur AmazonS3Location. |
Oui |
| bucketName | Le nom de compartiment S3. | Oui |
| folderPath | Chemin d’accès au dossier sous le compartiment donné. Si vous souhaitez utiliser un caractère générique pour filtrer le dossier, ignorez ce paramètre et spécifiez-le dans les paramètres de la source de l’activité. | Non |
| fileName | Nom de fichier sous le compartiment et le chemin d’accès du dossier donnés. Si vous souhaitez utiliser un caractère générique pour filtrer des dossiers, ignorez ce paramètre et spécifiez-le dans les paramètres de la source de l’activité. | Non |
| version | La version de l’objet S3 si le contrôle de version S3 est activé. À défaut de spécification, la version la plus récente est extraite. | Non |
Exemple :
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Amazon S3 linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AmazonS3Location",
"bucketName": "bucketname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Propriétés de l’activité de copie
Pour obtenir la liste complète des sections et des propriétés disponibles pour la définition des activités, consultez l’article Pipelines. Cette section fournit la liste des propriétés prises en charge par la source Amazon S3.
Amazon S3 comme type de source
Azure Data Factory prend en charge les formats de fichier suivants. Reportez-vous à chaque article pour les paramètres basés sur le format.
- Format Avro
- Format binaire
- Format de texte délimité
- Format Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Les propriétés suivantes sont prises en charge pour les objets Amazon S3 sous les paramètres storeSettings dans une source de copie basée sur le format :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type sous storeSettings doit être définie sur AmazonS3ReadSettings. |
Oui |
| Recherchez les fichiers à copier : | ||
| OPTION 1 : chemin d’accès statique |
Copie à partir du compartiment donné ou du chemin d’accès au dossier/fichier spécifié dans le jeu de données. Si vous souhaitez copier tous les fichiers d’un compartiment ou dossier, spécifiez en plus wildcardFileName comme *. |
|
| OPTION 2 : Préfixe S3 - prefix |
Préfixe pour le nom de la clé S3 sous le compartiment donné configuré dans un jeu de données pour filtrer les fichiers S3 sources. Les clé S3 dont le nom commence par bucket_in_dataset/this_prefix sont sélectionnées. Elles utilisent le filtre côté service de S3, qui offre de meilleures performances qu’un filtre de caractères génériques.Quand vous utilisez le préfixe et que vous choisissez de copier le récepteur basé sur un fichier avec conservation de la hiérarchie, notez que le sous-chemin après le dernier signe « / » dans le préfixe est conservé. Par exemple, si vous avez la source bucket/folder/subfolder/file.txt et que vous configurez le préfixe sous la forme folder/sub, le chemin du fichier conservé est subfolder/file.txt. |
Non |
| OPTION 3 : caractère générique - wildcardFolderPath |
Chemin d’accès du dossier avec des caractères génériques sous le compartiment donné configuré dans le jeu de données pour filtrer les dossiers sources. Les caractères génériques autorisés sont les suivants : * (correspond à zéro caractère ou plusieurs) et ? (correspond à zéro ou un caractère). Utilisez ^ comme caractère d’échappement si le nom de votre dossier contient un caractère générique ou ce caractère d’échappement. Consultez d’autres exemples dans les exemples de filtre de dossier et de fichier. |
Non |
| OPTION 3 : caractère générique - wildcardFileName |
Nom de fichier avec caractères génériques sous le compartiment et le chemin d’accès du dossier donnés (ou chemin d’accès du dossier en caractères génériques) pour filtrer les fichiers sources. Les caractères génériques autorisés sont les suivants : * (correspond à zéro caractère ou plusieurs) et ? (correspond à zéro ou un caractère). Utilisez ^ comme caractère d’échappement si le nom de votre fichier contient un caractère générique ou ce caractère d’échappement. Consultez d’autres exemples dans les exemples de filtre de dossier et de fichier. |
Oui |
| OPTION 4 : liste de fichiers - fileListPath |
Indique de copier un ensemble de fichiers donné. Pointez vers un fichier texte contenant la liste des fichiers que vous voulez copier, un fichier par ligne indiquant le chemin d’accès relatif configuré dans le jeu de données. Lorsque vous utilisez cette option, ne spécifiez pas de nom de fichier dans le jeu de données. Pour plus d’exemples, consultez Exemples de listes de fichiers. |
Non |
| Paramètres supplémentaires : | ||
| recursive | Indique si les données sont lues de manière récursive à partir des sous-dossiers ou uniquement du dossier spécifié. Notez que lorsque l’option recursive est définie sur true et que le récepteur est un magasin basé sur un fichier, un dossier ou un sous-dossier vide n’est pas copié ou créé sur le récepteur. Les valeurs autorisées sont true (par défaut) et false. Cette propriété ne s’applique pas lorsque vous configurez fileListPath. |
Non |
| deleteFilesAfterCompletion | Indique si les fichiers binaires seront supprimés du magasin source après leur déplacement vers le magasin de destination. La suppression se faisant par fichier, lorsque l’activité de copie échoue, vous pouvez constater que certains fichiers ont déjà été copiés vers la destination et supprimés de la source, tandis que d’autres restent dans le magasin source. Cette propriété est valide uniquement dans un scénario de copie de fichiers binaires. La valeur par défaut est false. |
Non |
| modifiedDatetimeStart | Les fichiers sont filtrés en fonction de l’attribut de dernière modification. Les fichiers sont sélectionnés si l’heure de leur dernière modification est postérieure ou égale à modifiedDatetimeStart et antérieure à modifiedDatetimeEnd. L’heure est appliquée à un fuseau horaire UTC au format « 2018-12-01T05:00:00Z ». Les propriétés peuvent avoir la valeur NULL, ce qui a pour effet qu’aucun filtre d’attribut de fichier n’est appliqué au jeu de données. Quand modifiedDatetimeStart a une valeur de DateHeure, mais que la valeur de modifiedDatetimeEnd est NULL, les fichiers dont l’attribut de dernière modification a une valeur supérieure ou égale à la valeur de DateHeure sont sélectionnés. Quand modifiedDatetimeEnd a une valeur de DateHeure, mais que la valeur de modifiedDatetimeStart est NULL, les fichiers dont l’attribut de dernière modification a une valeur inférieure à la valeur de DateHeure sont sélectionnés.Cette propriété ne s’applique pas lorsque vous configurez fileListPath. |
Non |
| modifiedDatetimeEnd | Identique à ce qui précède. | Non |
| enablePartitionDiscovery | Pour les fichiers partitionnés, spécifiez s’il faut analyser les partitions à partir du chemin d’accès au fichier et les ajouter en tant que colonnes sources supplémentaires. Les valeurs autorisées sont false (par défaut) et true. |
Non |
| partitionRootPath | Lorsque la découverte de partition est activée, spécifiez le chemin d’accès racine absolu pour pouvoir lire les dossiers partitionnés en tant que colonnes de données. S’il n’est pas spécifié, par défaut : – Quand vous utilisez le chemin d’accès du fichier dans le jeu de données ou la liste des fichiers sur la source, le chemin racine de la partition est le chemin d’accès configuré dans le jeu de données. – Quand vous utilisez le filtre de dossiers de caractères génériques, le chemin d’accès racine de la partition est le sous-chemin d’accès avant le premier caractère générique. – Quand vous utilisez le préfixe, le chemin d’accès racine de la partition est le sous-chemin d’accès avant le dernier « / ». Par exemple, en supposant que vous configurez le chemin d’accès dans le jeu de données en tant que « root/folder/year=2020/month=08/day=27 » : – Si vous spécifiez le chemin d’accès racine de la partition en tant que « root/folder/year=2020 », l’activité de copie génère deux colonnes supplémentaires, month et day, ayant respectivement la valeur « 08 » et « 27 », en plus des colonnes contenues dans les fichiers.– Si le chemin d’accès racine de la partition n’est pas spécifié, aucune colonne supplémentaire n’est générée. |
Non |
| maxConcurrentConnections | La limite supérieure de connexions simultanées établies au magasin de données pendant l’exécution de l’activité. Spécifiez une valeur uniquement lorsque vous souhaitez limiter les connexions simultanées. | Non |
Exemple :
"activities":[
{
"name": "CopyFromAmazonS3",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AmazonS3ReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Exemples de filtres de dossier et de fichier
Cette section décrit le comportement résultant de l’utilisation de filtres de caractères génériques dans les noms de fichier et les chemins de dossier.
| Compartiment | key | recursive | Structure du dossier source et résultat du filtrage (les fichiers en gras sont récupérés) |
|---|---|---|---|
| Compartiment | Folder*/* |
false | Compartiment DossierA Fichier1.csv File2.json Sousdossier1 File3.csv File4.json File5.csv AutreDossierB Fichier6.csv |
| Compartiment | Folder*/* |
true | Compartiment DossierA Fichier1.csv File2.json Sousdossier1 File3.csv File4.json File5.csv AutreDossierB Fichier6.csv |
| Compartiment | Folder*/*.csv |
false | Compartiment DossierA Fichier1.csv Fichier2.json Sousdossier1 File3.csv File4.json File5.csv AutreDossierB Fichier6.csv |
| Compartiment | Folder*/*.csv |
true | Compartiment DossierA Fichier1.csv Fichier2.json Sousdossier1 File3.csv File4.json File5.csv AutreDossierB Fichier6.csv |
Exemples de liste de fichiers
Cette section décrit le comportement résultant de l’utilisation d’un chemin d’accès de liste de fichiers dans la source de l’activité Copy.
Supposons que vous disposez de la structure de dossiers sources suivante et que vous souhaitez copier les fichiers en gras :
| Exemple de structure source | Contenu de FileListToCopy.txt | Configuration |
|---|---|---|
| Compartiment DossierA Fichier1.csv Fichier2.json Sousdossier1 File3.csv File4.json File5.csv Métadonnées FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
Dans le jeu de données : - compartiment : bucket- chemin d’accès du dossier : FolderADans la source de l’activité Copy : - chemin d’accès à la liste de fichiers : bucket/Metadata/FileListToCopy.txt Le chemin d’accès de la liste de fichiers pointe vers un fichier texte dans le même magasin de données, qui contient la liste de fichiers que vous voulez copier, un fichier par ligne indiquant le chemin d’accès relatif configuré dans le jeu de données. |
Conserver les métadonnées lors de la copie
Lorsque vous copiez des fichiers depuis Amazon S3 vers Azure Data Lake Storage Gen2 ou Stockage Blob Azure, vous pouvez choisir de conserver les métadonnées des fichiers avec les données. Pour plus d’informations, consultez Conserver les métadonnées.
Propriétés du mappage de flux de données
Lorsque vous transformez des données en flux de données de mappage, vous pouvez lire les fichiers d’Amazon S3 dans les formats suivants :
Les paramètres spécifiques du format se trouvent dans la documentation de ce format. Pour plus d’informations, consultez Transformation de la source dans un flux de données de mappage.
Transformation de la source
Dans une transformation de source, vous pouvez lire à partir d’un conteneur, d’un dossier ou d’un fichier individuel dans Amazon S3. Utilisez l’onglet Options de la source pour gérer la façon dont les fichiers sont lus.
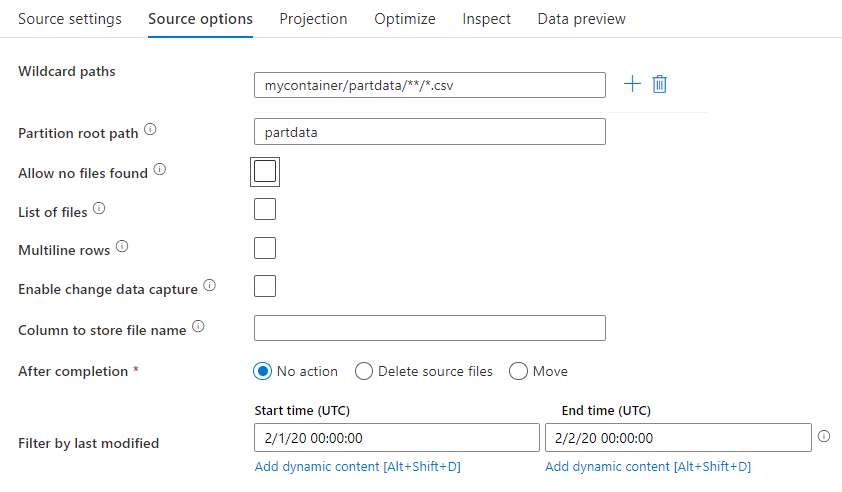
Chemin d’accès à caractères génériques : L’utilisation d’un modèle à caractères génériques donne pour instruction au service de parcourir en boucle chaque dossier et fichier correspondant dans une même transformation de la source. Il s’agit d’un moyen efficace de traiter plusieurs fichiers dans un seul et même flux. Ajoutez plusieurs modèles de correspondance à caractères génériques avec le signe plus qui apparaît quand vous pointez sur votre modèle à caractères génériques existant.
Dans le conteneur source, choisissez une série de fichiers qui correspondent à un modèle. Seul un conteneur peut être spécifié dans le jeu de données. Votre chemin contenant des caractères génériques doit donc également inclure le chemin de votre dossier à partir du dossier racine.
Exemples de caractères génériques :
*Représente un jeu de caractères quelconque.**Représente une imbrication de répertoires récursifs.?Remplace un caractère.[]Cherche une correspondance avec le ou les caractères entre crochets./data/sales/**/*.csvObtient tous les fichiers .csv se trouvant sous /data/sales./data/sales/20??/**/Obtient tous les fichiers datés du XXe siècle./data/sales/*/*/*.csvObtient les fichiers .csv à deux niveaux sous /data/sales./data/sales/2004/*/12/[XY]1?.csvObtient tous les fichiers .csv datés de décembre 2004, commençant par X ou Y et ayant comme préfixe un nombre à deux chiffres.
Chemin racine de la partition : si vous avez partitionné des dossiers dans votre source de fichier avec un format key=value (par exemple, year=2019), vous pouvez attribuer le niveau supérieur de cette arborescence de dossiers de partitions à un nom de colonne dans votre flux de données.
Tout d’abord, définissez un caractère générique pour inclure tous les chemins d’accès des dossiers partitionnés, ainsi que des fichiers de nœud terminal que vous souhaitez lire.
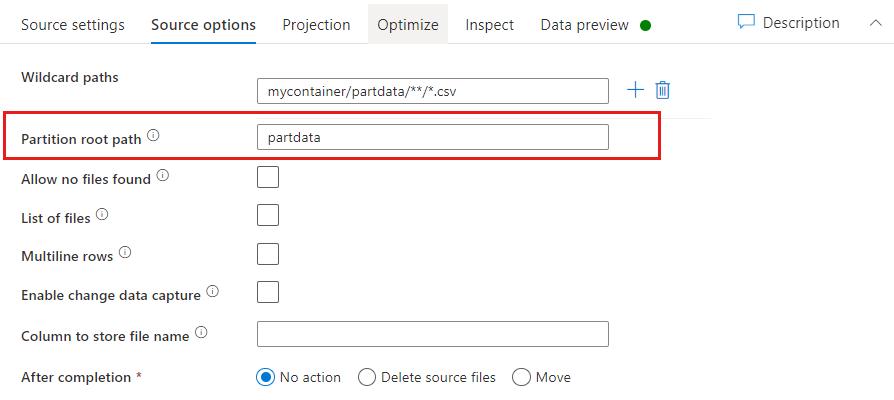
Utilisez le paramètre Chemin racine de la partition pour définir le niveau supérieur de la structure de dossiers. Quand vous affichez le contenu de vos données à l’aide d’un aperçu des données, vous voyez que le service ajoute les partitions résolues trouvées dans chacun de vos niveaux de dossiers.
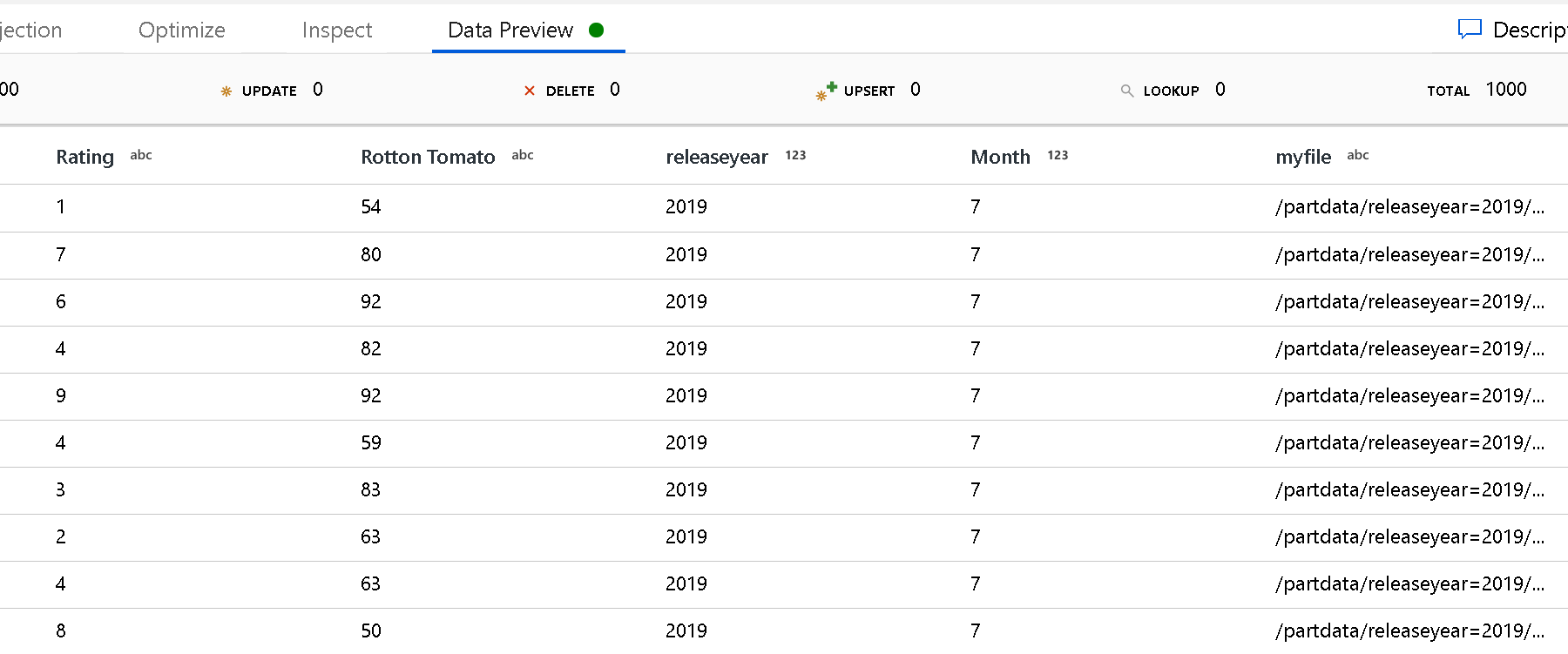
Liste de fichiers : Il s’agit d’un ensemble de fichiers. Créez un fichier texte qui inclut une liste de fichiers avec chemin relatif à traiter. Pointez sur ce fichier texte.
Colonne où stocker le nom du fichier : Stockez le nom du fichier source dans une colonne de vos données. Entrez un nouveau nom de colonne pour stocker la chaîne de nom de fichier.
Après l’exécution : après l’exécution du flux de données, choisissez de ne rien faire avec le fichier source, de le supprimer ou de le déplacer. Pour le déplacement, les chemins sont des chemins relatifs.
Pour déplacer les fichiers sources vers un autre emplacement de post-traitement, sélectionnez tout d’abord « Déplacer » comme opération de fichier. Définissez ensuite le répertoire de provenance (« from »). Si vous n’utilisez pas de caractères génériques pour votre chemin, le paramètre « from » sera le même dossier que votre dossier source.
Si vous avez un chemin d’accès source contenant un caractère générique, votre syntaxe se présente comme suit :
/data/sales/20??/**/*.csv
Vous pouvez spécifier « from » comme suit :
/data/sales
Et vous pouvez spécifier « to » comme suit :
/backup/priorSales
Dans le cas présent, tous les fichiers qui provenaient de /data/sales sont déplacés dans /backup/priorSales.
Notes
Les opérations de fichier s’exécutent uniquement quand vous démarrez le flux de données à partir d’une exécution de pipeline (débogage ou exécution) qui utilise l’activité Exécuter le flux de données dans un pipeline. Les opérations de fichiers ne s’exécutent pas en mode de débogage de flux de données.
Filtrer par date de dernière modification : Vous pouvez filtrer les fichiers traités en spécifiant une plage de dates sur laquelle les fichiers ont été modifiés pour la dernière fois. Toutes les valeurs de DateHeure sont exprimées en temps universel coordonné (UTC).
Propriétés de l’activité Lookup
Pour en savoir plus sur les propriétés, consultez Activité Lookup.
Propriétés de l’activité GetMetadata
Pour en savoir plus sur les propriétés, consultez Activité GetMetadata.
Propriétés de l’activité Delete
Pour en savoir plus sur les propriétés, consultez Activité Delete.
Modèles hérités
Notes
Les modèles suivants sont toujours pris en charge tels quels à des fins de compatibilité descendante. Nous vous suggérons d’utiliser le nouveau modèle mentionné précédemment. L’interface utilisateur de création a basculé vers la génération du nouveau modèle.
Modèle de jeu de données hérité
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur AmazonS3Object. | Oui |
| bucketName | Le nom de compartiment S3. Le filtre de caractères génériques n’est pas pris en charge. | Oui pour l’activité Copy ou Lookup, non pour l’activité GetMetadata |
| key | Filtre de nom ou de caractères génériques de la clé d’objet S3 sous le compartiment spécifié. S’applique uniquement lorsque la propriété prefix n’est pas spécifiée. Le filtre de caractères génériques est pris en charge pour la partie dossier et la partie nom de fichier. Les caractères génériques autorisés sont les suivants : * (correspond à zéro caractère ou plusieurs) et ? (correspond à zéro ou un caractère).- Exemple 1 : "key": "rootfolder/subfolder/*.csv"- Exemple 2 : "key": "rootfolder/subfolder/???20180427.txt"Consultez d’autres exemples dans les exemples de filtre de dossier et de fichier. Utilisez ^ comme caractère d’échappement si le nom réel de votre dossier ou fichier contient un caractère générique ou ce caractère d’échappement. |
Non |
| prefix | Préfixe de la clé d’objet S3. Les objets dont les clés commencent par ce préfixe sont sélectionnés. S’applique uniquement lorsque la propriété key n’est pas spécifiée. | Non |
| version | La version de l’objet S3 si le contrôle de version S3 est activé. À défaut de spécification, la version la plus récente sera extraite. | Non |
| modifiedDatetimeStart | Les fichiers sont filtrés en fonction de l’attribut de dernière modification. Les fichiers seront sélectionnés si l’heure de leur dernière modification est supérieure ou égale à modifiedDatetimeStart et inférieure à modifiedDatetimeEnd. L’heure est appliquée au fuseau horaire UTC au format « 2018-12-01T05:00:00Z ». N’oubliez pas que l’activation de ce paramètre affecte les performances globales du déplacement de données lorsque vous souhaitez filtrer d’énormes quantités de fichiers. Les propriétés peuvent avoir la valeur NULL, ce qui a pour effet qu’aucun filtre d’attribut de fichier n’est appliqué au jeu de données. Quand modifiedDatetimeStart a une valeur de DateHeure, mais que la valeur de modifiedDatetimeEnd est NULL, les fichiers dont l’attribut de dernière modification a une valeur supérieure ou égale à la valeur de DateHeure sont sélectionnés. Quand modifiedDatetimeEnd a une valeur de DateHeure, mais que la valeur de modifiedDatetimeStart est NULL, les fichiers dont l’attribut de dernière modification a une valeur inférieure à la valeur de DateHeure sont sélectionnés. |
Non |
| modifiedDatetimeEnd | Les fichiers sont filtrés en fonction de l’attribut de dernière modification. Les fichiers seront sélectionnés si l’heure de leur dernière modification est supérieure ou égale à modifiedDatetimeStart et inférieure à modifiedDatetimeEnd. L’heure est appliquée au fuseau horaire UTC au format « 2018-12-01T05:00:00Z ». N’oubliez pas que l’activation de ce paramètre affecte les performances globales du déplacement de données lorsque vous souhaitez filtrer d’énormes quantités de fichiers. Les propriétés peuvent avoir la valeur NULL, ce qui a pour effet qu’aucun filtre d’attribut de fichier n’est appliqué au jeu de données. Quand modifiedDatetimeStart a une valeur de DateHeure, mais que la valeur de modifiedDatetimeEnd est NULL, les fichiers dont l’attribut de dernière modification a une valeur supérieure ou égale à la valeur de DateHeure sont sélectionnés. Quand modifiedDatetimeEnd a une valeur de DateHeure, mais que la valeur de modifiedDatetimeStart est NULL, les fichiers dont l’attribut de dernière modification a une valeur inférieure à la valeur de DateHeure sont sélectionnés. |
Non |
| format | Si vous souhaitez copier des fichiers en l’état entre des magasins de fichiers (copie binaire), ignorez la section Format dans les deux définitions de jeu de données d’entrée et de sortie. Si vous souhaitez analyser ou générer des fichiers dans un format spécifique, les types de format de fichier suivants sont pris en charge : TextFormat, JsonFormat, AvroFormat, OrcFormat et ParquetFormat. Définissez la propriété type située sous Format sur l’une de ces valeurs. Pour en savoir plus, voir les sections Format Text, Format JSON, Format Avro, Format Orc et Format Parquet. |
Non (uniquement pour un scénario de copie binaire) |
| compression | Spécifiez le type et le niveau de compression pour les données. Pour plus d’informations, voir Formats de fichier et de codecs de compression pris en charge. Les types pris en charge sont : GZip, Deflate, BZip2 et ZipDeflate. Les niveaux pris en charge sont Optimal et Fastest. |
Non |
Conseil
Pour copier tous les fichiers d’un dossier, spécifiez bucketName pour le compartiment, et prefix pour la partie dossier.
Pour copier un seul fichier avec un nom donné, spécifiez bucketName pour le compartiment, et key pour la partie dossier plus le nom de fichier.
Pour copier un sous-ensemble de fichiers d’un dossier, spécifiez bucketName pour le compartiment et key pour la partie dossier plus le filtre de caractères génériques.
Exemple : utilisation de préfixe
{
"name": "AmazonS3Dataset",
"properties": {
"type": "AmazonS3Object",
"linkedServiceName": {
"referenceName": "<Amazon S3 linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"bucketName": "testbucket",
"prefix": "testFolder/test",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Exemple : utilisation de clé et version (facultative)
{
"name": "AmazonS3Dataset",
"properties": {
"type": "AmazonS3",
"linkedServiceName": {
"referenceName": "<Amazon S3 linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"bucketName": "testbucket",
"key": "testFolder/testfile.csv.gz",
"version": "XXXXXXXXXczm0CJajYkHf0_k6LhBmkcL",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Modèle source hérité pour l’activité Copy
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source d’activité Copy doit être définie sur FileSystemSource. | Oui |
| recursive | Indique si les données sont lues de manière récursive à partir des sous-dossiers ou uniquement du dossier spécifié. Notez que, lorsque l’option recursive est définie sur true et que le récepteur est un magasin basé sur un fichier, un dossier vide ou un sous-dossier n’est pas copié ou créé sur le récepteur. Les valeurs autorisées sont true (par défaut) et false. |
Non |
| maxConcurrentConnections | La limite supérieure de connexions simultanées établies au magasin de données pendant l’exécution de l’activité. Spécifiez une valeur uniquement lorsque vous souhaitez limiter les connexions simultanées. | Non |
Exemple :
"activities":[
{
"name": "CopyFromAmazonS3",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon S3 input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "FileSystemSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Contenu connexe
Pour obtenir la liste des magasins de données pris en charge par l'activité Copy en tant que sources et récepteurs, consultez Magasins de données pris en charge.