Copier et transformer des données dans Azure SQL Managed Instance en utilisant Azure Data Factory ou Synapse Analytics
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article indique comment utiliser l’activité de copie pour copier des données depuis et vers Azure SQL Managed Instance et utiliser Data Flow pour transformer les données dans Azure SQL Managed Instance. Pour plus d’informations, consultez les articles de présentation pour Azure Data Factory et Synapse Analytics.
Fonctionnalités prises en charge
Ce connecteur Azure SQL Database Managed Instance est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR | Point de terminaison privé managé |
|---|---|---|
| Activité de copie (source/récepteur) | ① ② | ✓ Préversion publique |
| Mappage de flux de données (source/récepteur) | ① | ✓ Préversion publique |
| Activité de recherche | ① ② | ✓ Préversion publique |
| Activité GetMetadata | ① ② | ✓ Préversion publique |
| Activité de script | ① ② | ✓ Préversion publique |
| Activité de procédure stockée | ① ② | ✓ Préversion publique |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Pour l’activité de copie, ce connecteur Azure SQL Database prend en charge les fonctions suivantes :
- Copie de données à l’aide de l’authentification SQL et de l’authentification du jeton de l’application Microsoft Entra avec un principal de service ou les identités managées pour les ressources Azure.
- En tant que source, la récupération de données à l’aide d’une requête SQL ou d’une procédure stockée. Vous pouvez également choisir de copier en parallèle à partir de la source SQL MI. Pour plus d’informations, consultez la section Copier en parallèle à partir de SQL MI.
- En tant que récepteur, la création automatique de la table de destination si elle n’existe pas, en fonction du schéma source, l’ajout de données à une table ou l’appel d’une procédure stockée avec une logique personnalisée pendant la copie.
Prérequis
Pour accéder au point de terminaison public SQL Managed Instance, vous pouvez utiliser un runtime d’intégration Azure managé. Assurez-vous que vous activez le terminal public et que vous autorisez également le trafic du terminal public sur le groupe de sécurité réseau afin que le service puisse se connecter à votre base de données. Pour plus d’informations, consultez cet article.
Pour accéder au point de terminaison privé SQL Managed Instance, configurez un runtime d’intégration auto-hébergé pouvant accéder à la base de données. Si vous configurez le runtime d'intégration auto-hébergé dans le même réseau virtuel que votre instance managée, assurez-vous que la machine qui exécute le runtime d'intégration ne se trouve pas dans le même sous-réseau que votre instance managée. Si vous configurez votre runtime d’intégration auto-hébergé dans un réseau virtuel différent de celui de votre instance managée, vous pouvez utiliser un peering de réseau virtuel ou une connexion de réseau virtuel à réseau virtuel. Pour plus d’informations, consultez Connecter votre application à SQL Managed Instance.
Bien démarrer
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
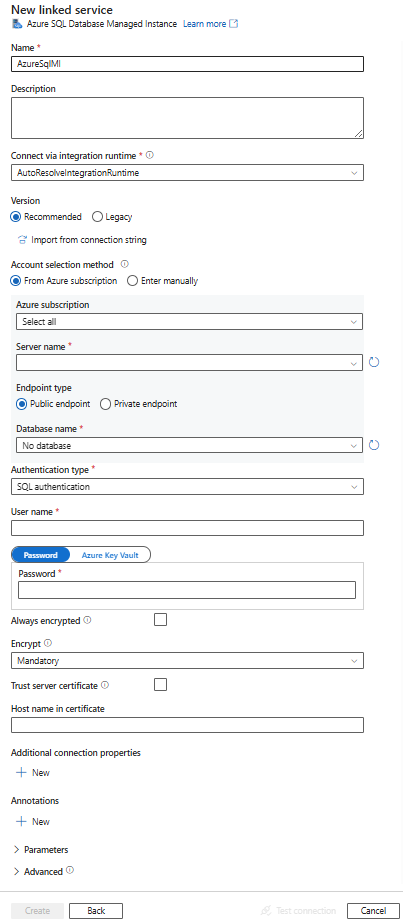
Créer un service lié à une instance Azure SQL Managed en utilisant l'interface utilisateur.
Suivez les étapes suivantes pour créer un service lié à une instance de SQL Managed dans l'interface utilisateur du portail Azure.
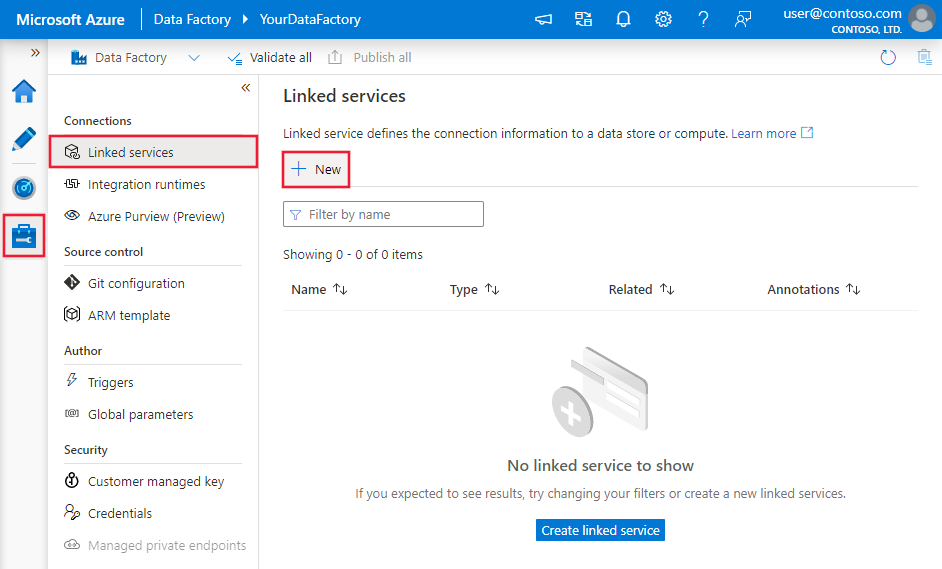
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse et sélectionnez Services liés, puis cliquez sur Nouveau :
Recherchez SQL et sélectionnez le connecteur Managed Instance Azure SQL Server.

Configurez les informations du service, testez la connexion et créez le nouveau service lié.
Informations de configuration des connecteurs
Les sections suivantes fournissent des informations détaillées sur les propriétés utilisées pour définir des entités Azure Data Factory spécifiques au connecteur SQL Managed Instance.
Propriétés du service lié
La version Recommandée du connecteur Azure SQL Managed Instance prend en charge TLS 1.3. Consultez cette section pour mettre à niveau votre version de connecteur Azure SQL Managed Instance à partir de la version héritée. Pour obtenir des détails sur les propriétés, consultez les sections correspondantes.
Version recommandée
Les propriétés génériques suivantes sont prises en charge pour un service lié à Azure SQL Managed Instance quand vous appliquez la version Recommandée :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur AzureSqlMI. | Oui |
| server | Nom ou adresse réseau de l’instance de SQL Server à laquelle vous souhaitez vous connecter. | Oui |
| database | Nom de la base de données. | Oui |
| authenticationType | Type utilisé pour l’authentification. Les valeurs autorisées sont SQL (par défaut), ServicePrincipal, SystemAssignedManagedIdentity et UserAssignedManagedIdentity. Accédez à la section d’authentification appropriée relative aux propriétés et aux prérequis spécifiques. | Oui |
| alwaysEncryptedSettings | Spécifiez les informations alwaysencryptedsettings nécessaires pour permettre à Always Encrypted de protéger les données sensibles stockées dans SQL Server à l’aide d’une identité managée ou d’un principal de service. Pour plus d’informations, consultez l’exemple JSON figurant après le tableau et la section Utilisation d’Always Encrypted. S’il n’est pas spécifié, le paramètre par défaut Always Encrypted est désactivé. | Non |
| encrypt | Indiquez si le chiffrement TLS est obligatoire pour toutes les données envoyées entre le client et le serveur. Options : obligatoire (pour true, valeur par défaut)/facultatif (pour false)/strict. | Non |
| trustServerCertificate | Indiquez si le canal est chiffré tout en contournant la chaîne de certificats pour valider l’approbation. | Non |
| hostNameInCertificate | Nom d’hôte à utiliser au moment de la validation du certificat de serveur pour la connexion. Quand il n’est pas spécifié, le nom du serveur est utilisé pour la validation de certificat. | Non |
| connectVia | Ce runtime d'intégration permet de se connecter au magasin de données. Vous pouvez utiliser un runtime d'intégration auto-hébergé ou un runtime d'intégration Azure si votre instance gérée possède un terminal public et autorise le service à y accéder. À défaut de spécification, l’Azure Integration Runtime par défaut est utilisé. | Oui |
Pour connaître des propriétés de connexion supplémentaires, consultez le tableau ci-dessous :
| Propriété | Description | Obligatoire |
|---|---|---|
| applicationIntent | Type de charge de travail de l’application au moment de la connexion à un serveur. Les valeurs autorisées sont ReadOnly et ReadWrite. |
Non |
| connectTimeout | Durée d’attente (en secondes) d’une connexion au serveur avant l’arrêt de la tentative, et la génération d’une erreur. | Non |
| connectRetryCount | Nombre de tentatives de reconnexions après l’identification d’une défaillance due à une connexion inactive. La valeur doit être un entier compris entre 0 et 255. | Non |
| connectRetryInterval | Durée (en secondes) entre chaque tentative de reconnexion après l’identification d’une défaillance due à une connexion inactive. La valeur doit être un entier compris entre 1 et 60. | Non |
| loadBalanceTimeout | Durée minimale (en secondes) pendant laquelle la connexion doit rester dans le pool de connexions avant d’être détruite. | Non |
| commandTimeout | Délai d’attente par défaut (en secondes) avant l’arrêt de la tentative d’exécution d’une commande, et la génération d’une erreur. | Non |
| integratedSecurity | Les valeurs autorisées sont true ou false. Quand vous spécifiez false, indique si userName et password sont spécifiés dans la connexion. Quand vous spécifiez true, indique si les informations d’identification du compte Windows actuel sont utilisées pour l’authentification. |
Non |
| failoverPartner | Nom ou adresse du serveur partenaire auquel se connecter si le serveur principal est en panne. | Non |
| maxPoolSize | Nombre maximal de connexions autorisées dans le pool de connexions pour la connexion spécifique. | Non |
| minPoolSize | Nombre minimal de connexions autorisées dans le pool de connexions pour la connexion spécifique. | Non |
| multipleActiveResultSets | Les valeurs autorisées sont true ou false. Quand vous spécifiez true, une application peut gérer plusieurs jeux de résultats MARS (Multiple Active Result Set). Quand vous spécifiez false, une application doit traiter ou annuler tous les jeux de résultats d’un lot pour pouvoir exécuter d’autres lots sur cette connexion. |
Non |
| multiSubnetFailover | Les valeurs autorisées sont true ou false. Si votre application se connecte à un groupe de disponibilité AlwaysOn sur différents sous-réseaux, l’affectation de la valeur true à cette propriété accélère la détection du serveur actif et la connexion à celui-ci. |
Non |
| packetSize | Taille en octets des paquets réseau utilisés pour communiquer avec une instance de serveur. | Non |
| pooling | Les valeurs autorisées sont true ou false. Quand vous spécifiez true, la connexion est groupée. Quand vous spécifiez false, la connexion est explicitement ouverte chaque fois qu’elle est demandée. |
Non |
Authentification SQL
Pour utiliser l’authentification SQL, en plus des propriétés génériques décrites dans la section précédente, spécifiez les propriétés suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| userName | Nom d’utilisateur utilisé pour se connecter au serveur. | Oui |
| mot de passe | Mot de passe du nom d’utilisateur. Marquez ce champ comme SecureString pour le stocker en toute sécurité. Vous pouvez également référencer un secret stocké dans Azure Key Vault. | Oui |
Exemple 1 : utilisez l’authentification SQL
{
"name": "AzureSqlMILinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemple 2 : utilisez l’authentification SQL avec un mot de passe dans Azure Key Vault
{
"name": "AzureSqlMILinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemple 3 : utilisez l’authentification SQL avec Always Encrypted
{
"name": "AzureSqlMILinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Authentification d’un principal du service
Pour utiliser l’authentification de principal de service, outre les propriétés génériques décrites dans la section précédente, spécifiez les propriétés suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| servicePrincipalId | Spécifiez l’ID client de l’application. | Oui |
| servicePrincipalCredential | Informations d’identification du principal du service. Spécifiez la clé de l’application. Marquez ce champ en tant que SecureString afin de le stocker en toute sécurité, ou référencez un secret stocké dans Azure Key Vault. | Oui |
| tenant | Spécifiez les informations de locataire, comme le nom de domaine ou l’ID de locataire, dans lequel votre application se trouve. Récupérez-les en pointant la souris dans le coin supérieur droit du Portail Azure. | Oui |
| azureCloudType | Pour l’authentification du principal de service, spécifiez le type d’environnement cloud Azure auquel votre application Microsoft Entra est inscrite. Les valeurs autorisées sont AzurePublic, AzureChina, AzureUsGovernment et AzureGermany. Par défaut, l’environnement cloud du service est utilisé. |
Non |
Vous devez également effectuer les étapes suivantes :
Suivez les étapes décrites dans Approvisionner un administrateur de Microsoft Entra pour votre instance gérée.
Créez une application Microsoft Entra à partir du portail Microsoft Azure. Prenez note du nom de l’application et des valeurs suivantes qui définissent le service lié :
- ID de l'application
- Clé de l'application
- ID client
Créez des identifiants pour le principal du service. Dans SSMS (SQL Server Management Studio), connectez-vous à votre instance managée à l’aide d’un compte SQL Server administrateur système. Dans la base de données de référence, exécutez le code T-SQL suivant :
CREATE LOGIN [your application name] FROM EXTERNAL PROVIDERCréez des utilisateurs de base de données autonome pour le principal de service. Connectez-vous à la base de données à partir de laquelle ou vers laquelle vous souhaitez copier des données, puis exécutez la commande T-SQL suivante :
CREATE USER [your application name] FROM EXTERNAL PROVIDERAccordez au principal de service les autorisations requises comme vous le faites d’habitude pour les utilisateurs SQL et autres. Exécutez le code suivant. Pour plus d’options, consultez ce document.
ALTER ROLE [role name e.g. db_owner] ADD MEMBER [your application name]Configurez un service lié SQL Managed Instance.
Exemple : utilisez l’authentification du principal de service
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"hostNameInCertificate": "<host name>",
"authenticationType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<application key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Authentification d’identité managée affectée par le système
Une fabrique de données ou un espace de travail Synapse peut être associé à une identité managée affectée par le système pour les ressources Azure, laquelle représente le service lors de l’authentification auprès d’autres services Azure. Vous pouvez utiliser cette identité managée pour l’authentification SQL Managed Instance. Le service en question peut accéder à votre base de données et copier des données depuis ou vers celle-ci à l’aide de cette identité.
Pour utiliser l’authentification d’identité managée affectée par le système, spécifiez les propriétés génériques décrites dans la section précédente et effectuez ces étapes.
Suivez les étapes décrites dans Approvisionner un administrateur de Microsoft Entra pour votre instance gérée.
Créez des identifiants pour l’identité managée affectée par le système. Dans SSMS (SQL Server Management Studio), connectez-vous à votre instance managée à l’aide d’un compte SQL Server administrateur système. Dans la base de données de référence, exécutez le code T-SQL suivant :
CREATE LOGIN [your_factory_or_workspace_ name] FROM EXTERNAL PROVIDERCréez des utilisateurs de base de données autonome pour l’identité managée affectée par le système. Connectez-vous à la base de données à partir de laquelle ou vers laquelle vous souhaitez copier des données, puis exécutez la commande T-SQL suivante :
CREATE USER [your_factory_or_workspace_name] FROM EXTERNAL PROVIDEROctroyez à l’identité managée affectée par le système les autorisations nécessaires, comme vous le faites normalement pour les utilisateurs SQL et les autres utilisateurs. Exécutez le code suivant. Pour plus d’options, consultez ce document.
ALTER ROLE [role name e.g. db_owner] ADD MEMBER [your_factory_or_workspace_name]Configurez un service lié SQL Managed Instance.
Exemple : utilisation de l’authentification via une identité managée affectée par le système
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SystemAssignedManagedIdentity"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Authentification d’identité managée affectée par l’utilisateur
Une fabrique de données ou un espace de travail Synapse peut être associé à une identité managée affectée par l’utilisateur qui représente le service lors de l’authentification auprès d’autres services Azure. Vous pouvez utiliser cette identité managée pour l’authentification SQL Managed Instance. Le service en question peut accéder à votre base de données et copier des données depuis ou vers celle-ci à l’aide de cette identité.
Pour utiliser l’authentification d’identité managée affectée par l’utilisateur, outre les propriétés génériques décrites dans la section précédente, spécifiez les propriétés suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| credentials | Spécifiez l’identité managée affectée par l’utilisateur en tant qu’objet d’informations d’identification. | Oui |
Vous devez également effectuer les étapes suivantes :
Suivez les étapes décrites dans Approvisionner un administrateur de Microsoft Entra pour votre instance gérée.
Créez des identifiants pour l’identité managée affectée par l’utilisateur. Dans SSMS (SQL Server Management Studio), connectez-vous à votre instance managée à l’aide d’un compte SQL Server administrateur système. Dans la base de données de référence, exécutez le code T-SQL suivant :
CREATE LOGIN [your_factory_or_workspace_ name] FROM EXTERNAL PROVIDERCréez des utilisateurs de base de données autonome pour l’identité managée affectée par l’utilisateur. Connectez-vous à la base de données à partir de laquelle ou vers laquelle vous souhaitez copier des données, puis exécutez la commande T-SQL suivante :
CREATE USER [your_factory_or_workspace_name] FROM EXTERNAL PROVIDERCréez une ou plusieurs identités managées affectées par l’utilisateur et accordez-leur les autorisations nécessaires, comme vous le feriez pour des utilisateurs SQL, par exemple. Exécutez le code suivant. Pour plus d’options, consultez ce document.
ALTER ROLE [role name e.g. db_owner] ADD MEMBER [your_factory_or_workspace_name]Attribuez une ou plusieurs identités managées affectées par l’utilisateur à votre fabrique de données et créez des informations d’identification pour chaque identité managée affectée par l’utilisateur.
Configurez un service lié SQL Managed Instance.
Exemple : utilisation de l’authentification via une identité managée affectée par l’utilisateur
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Version héritée
Les propriétés génériques suivantes sont prises en charge pour un service lié à Azure SQL Managed Instance quand vous appliquez la version Héritée :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur AzureSqlMI. | Oui |
| connectionString | Cette propriété spécifie les informations connectionString nécessaires pour se connecter à l’instance managée SQL avec l’authentification SQL. Pour plus d'informations, consultez les exemples suivants. Le port par défaut est 1433. Si vous utilisez SQL Managed Instance avec un point de terminaison public, spécifiez explicitement le port 3342. Vous pouvez également placer un mot de passe dans Azure Key Vault. En cas d’authentification SQL, extrayez la configuration password de la chaîne de connexion. Pour plus d’informations, consultez Store credential in Azure Key Vault (Stocker les informations d’identification dans Azure Key Vault). |
Oui |
| alwaysEncryptedSettings | Spécifiez les informations alwaysencryptedsettings nécessaires pour permettre à Always Encrypted de protéger les données sensibles stockées dans SQL Server à l’aide d’une identité managée ou d’un principal de service. Pour plus d’informations, consultez la section Utilisation d’Always Encrypted. S’il n’est pas spécifié, le paramètre par défaut Always Encrypted est désactivé. | Non |
| connectVia | Ce runtime d'intégration permet de se connecter au magasin de données. Vous pouvez utiliser un runtime d'intégration auto-hébergé ou un runtime d'intégration Azure si votre instance gérée possède un terminal public et autorise le service à y accéder. À défaut de spécification, l’Azure Integration Runtime par défaut est utilisé. | Oui |
Pour connaître les différents types d’authentifications, consultez les sections suivantes relatives aux propriétés spécifiques et aux prérequis, respectivement :
- Authentification SQL pour la version héritée
- Authentification du principal de service pour la version héritée
- Authentification à l’aide de l’identité managée affectée par le système pour la version héritée
- Authentification à l’aide de l’identité managée affectée par l’utilisateur pour la version héritée
Authentification SQL pour la version héritée
Pour utiliser l’authentification SQL, spécifiez les propriétés génériques décrites dans la section précédente.
Authentification du principal de service pour la version héritée
Pour utiliser l’authentification de principal de service, outre les propriétés génériques décrites dans la section précédente, spécifiez les propriétés suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| servicePrincipalId | Spécifiez l’ID client de l’application. | Oui |
| servicePrincipalKey | Spécifiez la clé de l’application. Marquez ce champ en tant que SecureString afin de le stocker en toute sécurité ou référencez un secret stocké dans Azure Key Vault. | Oui |
| tenant | Spécifiez les informations de locataire, comme le nom de domaine ou l’ID de locataire, dans lequel votre application se trouve. Récupérez-les en pointant la souris dans le coin supérieur droit du Portail Azure. | Oui |
| azureCloudType | Pour l’authentification du principal de service, spécifiez le type d’environnement cloud Azure auquel votre application Microsoft Entra est inscrite. Les valeurs autorisées sont AzurePublic, AzureChina, AzureUsGovernment et AzureGermany. Par défaut, l’environnement cloud du pipeline de fabrique de données ou Synapse est utilisé. |
Non |
Vous devez également suivre les étapes décrites dans Authentification du principal de service pour octroyer l’autorisation correspondante.
Authentification à l’aide de l’identité managée affectée par le système pour la version héritée
Pour utiliser l’authentification basée sur l’identité managée affectée par le système, suivez la même étape que pour la version recommandée dans Authentification à l’aide de l’identité managée affectée par le système.
Authentification à l’aide de l’identité managée affectée par l’utilisateur pour la version héritée
Pour utiliser l’authentification basée sur l’identité managée affectée par l’utilisateur, suivez la même étape que pour la version recommandée dans Authentification à l’aide de l’identité managée affectée par l’utilisateur.
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l'article consacré aux jeux de données. Cette section fournit la liste des propriétés prises en charge par le jeu de données SQL Managed Instance.
Les propriétés suivantes sont prises en charge pour la copie de données vers et à partir d’une instance managée SQL Azure :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur AzureSqlMITable. | Oui |
| schéma | Nom du schéma. | Non pour Source, Oui pour Récepteur |
| table | Nom de la table/vue. | Non pour Source, Oui pour Récepteur |
| tableName | Nom de la table/vue avec schéma. Cette propriété est prise en charge pour la compatibilité descendante. Pour les nouvelles charges de travail, utilisez schema et table. |
Non pour Source, Oui pour Récepteur |
Exemple
{
"name": "AzureSqlMIDataset",
"properties":
{
"type": "AzureSqlMITable",
"linkedServiceName": {
"referenceName": "<SQL Managed Instance linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Propriétés de l’activité de copie
Pour obtenir la liste complète des sections et des propriétés disponibles pour la définition des activités, consultez l'article Pipelines. Cette section fournit la liste des propriétés prises en charge par la source et le récepteur d’instance managée SQL.
Instance managée SQL comme source
Conseil
Pour savoir comment charger efficacement des données à partir de SQL MI à l’aide du partitionnement, voir Copier en parallèle à partir de SQL MI.
Pour la copie de données à partir de l’instance managée SQL, les propriétés suivantes sont prises en charge dans la section source de l’activité de copie :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source d’activité de copie doit être définie sur SqlMISource. | Oui |
| sqlReaderQuery | Cette propriété utilise la requête SQL personnalisée pour lire les données. par exemple select * from MyTable. |
Non |
| sqlReaderStoredProcedureName | Cette propriété est le nom de la procédure stockée qui lit les données dans la table source. La dernière instruction SQL doit être une instruction SELECT dans la procédure stockée. | Non |
| storedProcedureParameters | Ces paramètres concernent la procédure stockée. Les valeurs autorisées sont des paires de noms ou de valeurs. Les noms et la casse des paramètres doivent correspondre aux noms et à la casse des paramètres de la procédure stockée. |
Non |
| isolationLevel | Spécifie le comportement de verrouillage des transactions pour la source SQL. Les valeurs autorisées sont les suivantes : ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. S’il n’est pas spécifié, le niveau d’isolation par défaut de la base de données est utilisé. Pour plus d’informations, consultez ce document. | Non |
| partitionOptions | Spécifie les options de partitionnement des données utilisées pour charger des données à partir de SQL MI. Les valeurs autorisées sont les suivantes : None (valeur par défaut), PhysicalPartitionsOfTable et DynamicRange. Lorsqu’une option de partition est activée (donc, autre que None), le degré de parallélisme pour charger simultanément des données à partir de SQL MI est contrôlé par le paramètre parallelCopies de l’activité de copie. |
Non |
| partitionSettings | Spécifiez le groupe de paramètres pour le partitionnement des données. S’applique lorsque l’option de partitionnement n’est pas None. |
Non |
Sous partitionSettings : |
||
| partitionColumnName | Spécifiez le nom de la colonne source en type entier ou date/DateHeure (int, smallint, bigint, date, smalldatetime, datetime, datetime2 ou datetimeoffset) qu’utilisera le partitionnement par plages de valeurs pour la copie en parallèle. S’il n’est pas spécifié, l’index ou la clé primaire de la table seront automatiquement détectés et utilisés en tant que colonne de partition.S’applique lorsque l’option de partitionnement est DynamicRange. Si vous utilisez une requête pour récupérer des données sources, utilisez ?DfDynamicRangePartitionCondition dans la clause WHERE. Pour obtenir un exemple, consultez la section Copier en parallèle à partir de la base de données SQL. |
Non |
| partitionUpperBound | Valeur maximale de la colonne de partition pour le fractionnement de la plage de partition. Cette valeur est utilisée pour décider du stride de la partition, et non pour filtrer les lignes de la table. Toutes les lignes de la table ou du résultat de la requête seront partitionnées et copiées. Si la valeur n’est pas spécifiée, l’activité de copie la détecte automatiquement. S’applique lorsque l’option de partitionnement est DynamicRange. Pour obtenir un exemple, consultez la section Copier en parallèle à partir de la base de données SQL. |
Non |
| partitionLowerBound | Valeur minimale de la colonne de partition pour le fractionnement de la plage de partition. Cette valeur est utilisée pour décider du stride de la partition, et non pour filtrer les lignes de la table. Toutes les lignes de la table ou du résultat de la requête seront partitionnées et copiées. Si la valeur n’est pas spécifiée, l’activité de copie la détecte automatiquement. S’applique lorsque l’option de partitionnement est DynamicRange. Pour obtenir un exemple, consultez la section Copier en parallèle à partir de la base de données SQL. |
Non |
Notez les points suivants :
- Si sqlReaderQuery est spécifié comme SqlMISource, l’activité de copie exécute cette requête sur la source de l’instance managée SQL pour obtenir les données. Vous pouvez également spécifier une procédure stockée en spécifiant sqlReaderStoredProcedureName et storedProcedureParameters si la procédure stockée accepte des paramètres.
- Lorsque vous utilisez une procédure stockée dans la source pour récupérer des données, sachez que si votre procédure stockée est conçue pour renvoyer un schéma différent quand une valeur de paramètre différente est entrée, vous risquez d’échouer ou d’obtenir un résultat inattendu lors de l’importation d’un schéma à partir de l’interface utilisateur ou lors de la copie de données dans la base de données SQL avec création de table automatique.
Exemple : Utilisation d'une requête SQL
"activities":[
{
"name": "CopyFromAzureSqlMI",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Managed Instance input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlMISource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Exemple : Utilisation d'une procédure stockée
"activities":[
{
"name": "CopyFromAzureSqlMI",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Managed Instance input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlMISource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Définition de la procédure stockée
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Instance managée SQL comme récepteur
Conseil
Pour en savoir plus sur les bonnes pratiques, les configurations et les comportements d’écriture pris en charge, consultez l’article Bonnes pratiques de chargement de données dans SQL Managed Instance.
Pour la copie de données vers une instance managée SQL, les propriétés suivantes sont prises en charge dans la section du récepteur d’activité de copie :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du récepteur de l'activité de copie doit être définie sur SqlMISink. | Oui |
| preCopyScript | Cette propriété spécifie une requête SQL que l’activité de copie doit exécuter avant l’écriture des données dans l’instance managée SQL. Elle n'est appelée qu'une seule fois par copie. Vous pouvez utiliser cette propriété pour nettoyer des données préchargées. | Non |
| tableOption | Spécifie si la table du récepteur doit être créée automatiquement si elle n’existe pas en fonction du schéma source. La création automatique de la table n’est pas prise en charge quand le récepteur spécifie une procédure stockée. Les valeurs autorisées sont none (par défaut) et autoCreate. |
Non |
| sqlWriterStoredProcedureName | Nom de la procédure stockée qui définit comment appliquer des données sources dans une table cible. Cette procédure stockée est appelée par lot. Pour les opérations qui ne s’exécutent qu’une seule fois et qui n’ont rien à voir avec les données sources (par exemple, supprimer ou tronquer), utilisez la propriété preCopyScript.Voir l’exemple dans la section Appel d’une procédure stockée à partir d’un récepteur SQL. |
Non |
| storedProcedureTableTypeParameterName | Nom du paramètre du type de table spécifié dans la procédure stockée. | Non |
| sqlWriterTableType | Nom du type de table à utiliser dans la procédure stockée. L'activité de copie rend les données déplacées disponibles dans une table temporaire avec ce type de table. Le code de procédure stockée peut ensuite fusionner les données copiées avec les données existantes. | Non |
| storedProcedureParameters | Paramètres de la procédure stockée. Les valeurs autorisées sont des paires de noms et de valeurs. Les noms et la casse des paramètres doivent correspondre aux noms et à la casse des paramètres de la procédure stockée. |
Non |
| writeBatchSize | Nombre de lignes à insérer dans la table SQL par lot. Les valeurs autorisées sont des entiers pour le nombre de lignes. Par défaut, le service détermine de façon dynamique la taille de lot appropriée selon la taille de ligne. |
Non |
| writeBatchTimeout | Le temps d’attente pour que l’opération d’insertion, d’insertion ascendante et de procédure stockée se termine avant l’expiration du délai. Les valeurs autorisées sont celles qui expriment un intervalle de temps. Exemple : « 00:30:00 » pour 30 minutes. Si aucune valeur n’est spécifiée, le délai d’expiration est par défaut « 00:30:00 ». |
Non |
| maxConcurrentConnections | La limite supérieure de connexions simultanées établies au magasin de données pendant l’exécution de l’activité. Spécifiez une valeur uniquement lorsque vous souhaitez limiter les connexions simultanées. | Aucune |
| WriteBehavior | Spécifiez le comportement d’écriture pour l’activité de copie afin de charger des données dans Azure SQL MI. La valeur autorisée est Insert ou Upsert. Par défaut, le service utilise Insert pour charger des données. |
Non |
| upsertSettings | Spécifiez le groupe de paramètres pour le comportement d’écriture. S’applique quand l’option WriteBehavior a la valeur Upsert. |
Non |
Sous upsertSettings : |
||
| useTempDB | Spécifiez si vous souhaitez utiliser la table temporaire globale ou la table physique en tant que table intermédiaire pour faire un upsert. Par défaut, le service utilise une table temporaire globale en tant que table intermédiaire. La valeur est true. |
Non |
| interimSchemaName | Spécifiez le schéma intermédiaire utilisé pour créer la table intermédiaire en cas d’utilisation d’une table physique. Remarque : L’utilisateur a besoin d’une autorisation de créer et supprimer une table. Par défaut, la table intermédiaire partage le même schéma que la table du récepteur. S’applique quand l’option useTempDB a la valeur False. |
Non |
| clés | Spécifiez les noms de colonne à des fins d’identification unique des lignes. Vous pouvez utiliser une seule clé ou une série de clés. Si la valeur n’est pas spécifiée, la clé primaire est utilisée. | Non |
Exemple 1 : Ajout de données
"activities":[
{
"name": "CopyToAzureSqlMI",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Managed Instance output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlMISink",
"tableOption": "autoCreate",
"writeBatchSize": 100000
}
}
}
]
Exemple 2 : Appeler une procédure stockée pendant la copie
Pour en savoir plus, consultez Appel d'une procédure stockée à partir d'un récepteur SQL MI.
"activities":[
{
"name": "CopyToAzureSqlMI",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Managed Instance output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlMISink",
"sqlWriterStoredProcedureName": "CopyTestStoredProcedureWithParameters",
"storedProcedureTableTypeParameterName": "MyTable",
"sqlWriterTableType": "MyTableType",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" }
}
}
}
}
]
Exemple 3 : Faire un upsert des données
"activities":[
{
"name": "CopyToAzureSqlMI",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Managed Instance output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlMISink",
"tableOption": "autoCreate",
"writeBehavior": "upsert",
"upsertSettings": {
"useTempDB": true,
"keys": [
"<column name>"
]
},
}
}
}
]
Copier en parallèle à partir de SQL MI
Le connecteur Azure SQL Managed Instance dans l’activité de copie propose un partitionnement de données intégré pour copier des données en parallèle. Vous trouverez des options de partitionnement de données dans l’onglet Source de l’activité de copie.
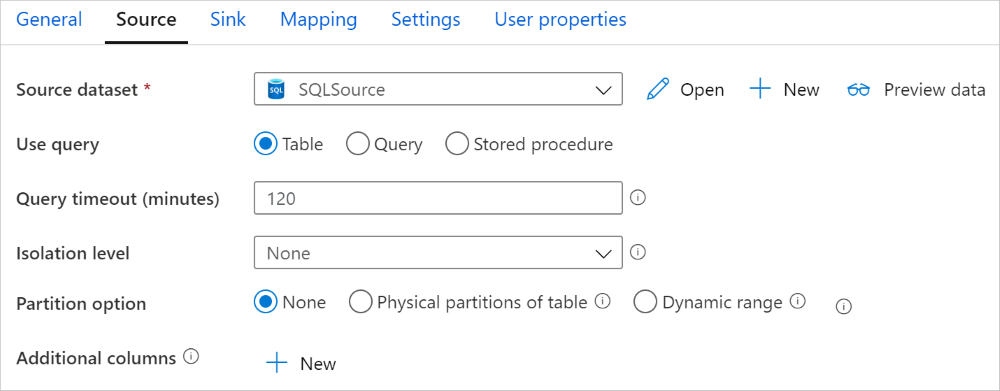
Lorsque vous activez la copie partitionnée, l’activité de copie exécute des requêtes en parallèle sur votre source SQL MI pour charger des données par partitions. Le degré de parallélisme est contrôlé via le paramètre parallelCopies sur l’activité de copie. Par exemple, si vous définissez parallelCopies sur la valeur quatre, le service génère et exécute simultanément quatre requêtes selon l’option de partition et les paramètres que vous avez spécifiés, chacune récupérant une partie des données de votre MI SQL.
Il vous est recommandé d’activer la copie en parallèle avec partitionnement des données, notamment lorsque vous chargez une grande quantité de données à partir de SQL MI. Voici quelques suggestions de configurations pour différents scénarios. Lors de la copie de données dans un magasin de données basé sur un fichier, il est recommandé d’écrire les données dans un dossier sous la forme de plusieurs fichiers (spécifiez uniquement le nom du dossier). Les performances seront meilleures qu’avec l’écriture de données dans un seul fichier.
| Scénario | Paramètres suggérés |
|---|---|
| Chargement complet à partir d’une table volumineuse, avec des partitions physiques. | Option de partition : Partitions physiques de la table. Pendant l’exécution, le service détecte automatiquement les partitions physiques et copie les données par partition. Pour vérifier si votre table possède, ou non, une partition physique, vous pouvez vous reporter à cette requête. |
| Chargement complet d’une table volumineuse, sans partitions physiques, avec une colonne d’entiers ou DateHeure pour le partitionnement des données. | Options de partition : Partition dynamique par spécification de plages de valeurs. Colonne de partition (facultatif) : Spécifiez la colonne utilisée pour partitionner les données. Si la valeur n’est pas spécifiée, la colonne de l’index ou de la clé primaire est utilisée. Limite supérieure de partition et limite inférieure de partition (facultatif) : Spécifiez si vous souhaitez déterminer le stride de la partition. Cela ne permet pas de filtrer les lignes de la table ; toutes les lignes de la table sont partitionnées et copiées. Si les valeurs ne sont pas spécifiées, l’activité de copie les détecte automatiquement. Par exemple, si les valeurs de la colonne de partition « ID » sont comprises entre 1 et 100, et que vous définissez la limite inférieure à 20 et la limite supérieure à 80, avec la copie parallèle à 4, le service récupère des données en fonction de 4 partitions, (ID des plages <=20, [21, 50], [51, 80] et >=81, respectivement). |
| Chargement d’une grande quantité de données à l’aide d’une requête personnalisée, sans partitions physiques, et avec une colonne d’entiers ou de date/DateHeure pour le partitionnement des données. | Options de partition : Partition dynamique par spécification de plages de valeurs. Requête: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Colonne de partition : Spécifiez la colonne utilisée pour partitionner les données. Limite supérieure de partition et limite inférieure de partition (facultatif) : Spécifiez si vous souhaitez déterminer le stride de la partition. Cela ne permet pas de filtrer les lignes de la table ; toutes les lignes du résultat de la requête sont partitionnées et copiées. Si la valeur n’est pas spécifiée, l’activité de copie la détecte automatiquement. Par exemple, si les valeurs de la colonne de partition « ID » sont comprises entre 1 et 100, et que vous définissez la limite inférieure à 20 et la limite supérieure à 80, avec la copie parallèle à 4, le service récupère des données en fonction de 4 partitions (ID des plages <=20, [21, 50], [51, 80] et >=81, respectivement). Voici d’autres exemples de requêtes pour différents scénarios : 1. Interroger l’ensemble de la table : SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Interroger une table avec une sélection de colonnes et des filtres de la clause WHERE supplémentaires : SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Effectuer une requête avec des sous-requêtes : SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Effectuer une requête avec une partition dans une sous-requête : SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Meilleures pratiques pour charger des données avec l’option de partition :
- Choisissez une colonne distinctive comme colonne de partition (p. ex. : clé primaire ou clé unique) pour éviter l’asymétrie des données.
- Si la table possède une partition intégrée, utilisez l’option de partition « Partitions physiques de la table » pour obtenir de meilleures performances.
- Si vous utilisez Azure Integration Runtime pour copier des données, vous pouvez définir des « unités d’intégration de données (DIU) » plus grandes (>4) pour utiliser davantage de ressources de calcul. Vérifiez les scénarios applicables ici.
- Le « degré de parallélisme de copie » contrôle le nombre de partitions : un nombre trop élevé nuit parfois aux performances. Il est recommandé de définir ce nombre selon (DIU ou nombre de nœuds d'IR auto-hébergé) * (2 à 4).
Exemple : chargement complet à partir d’une table volumineuse, avec des partitions physiques
"source": {
"type": "SqlMISource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Exemple : requête avec partition dynamique par spécification de plages de valeurs
"source": {
"type": "SqlMISource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Exemple de requête pour vérifier une partition physique
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Si la table a une partition physique, vous voyez « HasPartition » avec la valeur « yes » (oui) comme suit.

Bonnes pratiques de chargement de données dans une instance managée SQL
Quand vous copiez des données vers une instance managée SQL, vous pouvez avoir besoin d’un comportement d’écriture différent :
- Append: Mes données sources contiennent uniquement de nouveaux enregistrements.
- Upsert : Mes données sources contiennent à la fois des insertions et des mises à jour.
- Remplacer : Je veux recharger la totalité de la table de dimension à chaque fois.
- Écrire avec une logique personnalisée : J’ai besoin d’un traitement supplémentaire avant l’insertion finale dans la table de destination.
Consultez les sections correspondantes pour savoir comment effectuer des configurations et connaître les bonnes pratiques associées.
Ajout de données
L’ajout de données est le comportement par défaut de ce connecteur de récepteur SQL Managed Instance. Le service effectue une insertion en bloc pour écrire efficacement dans votre table. Vous pouvez configurer la source et le récepteur en conséquence dans l’activité de copie.
Effectuer un upsert de données
L’activité de copie prend maintenant en charge le chargement en mode natif des données dans une table temporaire de base de données, puis met à jour les données dans la table du récepteur s’il existe une clé ou insère les nouvelles données dans le cas contraire. Pour en savoir plus sur les paramètres upsert dans les activités de copie, consultez SQL Managed Instance en tant que récepteur.
Remplacer l’intégralité de la table
Vous pouvez configurer la propriété preCopyScript dans un récepteur d’activité de copie. Dans le cas présent, pour chaque activité Copy qui s’exécute, le service exécute d’abord le script. Il exécute ensuite la copie pour insérer les données. Par exemple, pour remplacer l’intégralité de la table par les données les plus récentes, spécifiez un script pour d’abord supprimer tous les enregistrements avant de charger en bloc les nouvelles données à partir de la source.
Écrire des données avec une logique personnalisée
Les étapes permettant d’écrire des données à l’aide d’une logique personnalisée sont semblables à celles décrites dans la section Effectuer un upsert de données. Quand vous devez appliquer un traitement supplémentaire avant l’insertion finale des données sources dans la table de destination, vous pouvez effectuer le chargement vers une table de mise en lots, puis appeler une activité de procédure stockée ou appeler une procédure stockée dans le récepteur de l’activité de copie pour appliquer les données.
Appel d'une procédure stockée à partir d'un récepteur SQL
Quand vous copiez des données dans une instance managée SQL, vous pouvez également configurer et appeler une procédure stockée spécifiée par l’utilisateur avec des paramètres supplémentaires sur chaque lot de la table source. La fonction de procédure stockée tire parti des paramètres table.
Vous pouvez utiliser une procédure stockée à la place des mécanismes de copie intégrée. Par exemple, quand vous souhaitez appliquer un traitement supplémentaire avant l’insertion finale de données sources dans la table de destination. Fusionner des colonnes, rechercher des valeurs supplémentaires et effectuer des insertions dans plusieurs tables sont des exemples de traitement supplémentaire.
L’exemple suivant montre comment utiliser une procédure stockée pour effectuer une opération upsert simple dans une table de la base de données SQL Server. Supposons que les données d’entrée et la table réceptrice Marketing ont trois colonnes : ProfileID, State et Category. Effectuez l’opération upsert basée sur la colonne ProfileID et appliquez-la uniquement à une catégorie spécifique appelée « ProductA ».
Dans votre base de données, définissez le type de table avec le même nom que sqlWriterTableType. Le schéma du type de table doit être identique au schéma retourné par vos données d'entrée.
CREATE TYPE [dbo].[MarketingType] AS TABLE( [ProfileID] [varchar](256) NOT NULL, [State] [varchar](256) NOT NULL, [Category] [varchar](256) NOT NULL )Dans votre base de données, définissez la procédure stockée portant le même nom que sqlWriterStoredProcedureName. Elle gère les données d’entrée à partir de la source que vous avez spécifiée et les fusionne dans la table de sortie. Le nom de paramètre du type de table de la procédure stockée doit être identique au tableName défini dans le jeu de données.
CREATE PROCEDURE spOverwriteMarketing @Marketing [dbo].[MarketingType] READONLY, @category varchar(256) AS BEGIN MERGE [dbo].[Marketing] AS target USING @Marketing AS source ON (target.ProfileID = source.ProfileID and target.Category = @category) WHEN MATCHED THEN UPDATE SET State = source.State WHEN NOT MATCHED THEN INSERT (ProfileID, State, Category) VALUES (source.ProfileID, source.State, source.Category); ENDDans votre pipeline, définissez la section Récepteur SQL MI de l’activité de copie comme suit :
"sink": { "type": "SqlMISink", "sqlWriterStoredProcedureName": "spOverwriteMarketing", "storedProcedureTableTypeParameterName": "Marketing", "sqlWriterTableType": "MarketingType", "storedProcedureParameters": { "category": { "value": "ProductA" } } }
Propriétés du mappage de flux de données
Lors de la transformation de données dans le flux de données de mappage, vous pouvez lire et écrire dans des tables à partir d’Azure SQL Managed Instance. Pour plus d’informations, consultez la transformation de la source et la transformation du récepteur dans le flux de données de mappage.
Transformation de la source
Le tableau ci-dessous répertorie les propriétés prises en charge par une source Azure SQL Managed Instance. Vous pouvez modifier ces propriétés sous l’onglet Options de la source.
| Nom | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Table de charge de travail | Si vous sélectionnez Table comme entrée, le flux de données extrait toutes les données de la table spécifiée dans le jeu de données. | Non | - | - |
| Requête | Si vous sélectionnez Requête comme entrée, spécifiez une requête SQL pour extraire des données de la source, qui remplace toute table que vous spécifiez dans le jeu de données. L’utilisation de requêtes est un excellent moyen de réduire le nombre de lignes pour les tests ou les recherches. La clause Order By n’est pas prise en charge, mais vous pouvez définir une instruction SELECT FROM complète. Vous pouvez également utiliser des fonctions de table définies par l’utilisateur. select * from udfGetData() est une fonction UDF dans SQL qui retourne une table que vous pouvez utiliser dans le flux de données. Exemple de requête : Select * from MyTable where customerId > 1000 and customerId < 2000. |
Non | String | query |
| Taille du lot | Spécifiez la taille de lot que doivent avoir les lectures créées à partir d’un large volume de données. | Non | Integer | batchSize |
| Niveau d’isolation | Choisissez l’un des niveaux d’isolation suivants : – Lecture validée. – Lecture non validée (par défaut). – Lecture renouvelable. – Sérialisable. – Aucun (ignorer le niveau d’isolation). |
Non | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZABLE NONE |
isolationLevel |
| Activer l’extraction incrémentielle | Utilisez cette option pour indiquer à ADF de traiter seulement les lignes qui ont changé depuis la dernière exécution du pipeline. | Non | - | - |
| Colonne incrémentielle | Quand vous utilisez la fonctionnalité d’extraction incrémentielle, vous devez choisir la colonne date/heure ou numérique que vous voulez utiliser comme filigrane dans votre table source. | Non | - | - |
| Activer la capture native des changements de données (préversion) | Utilisez cette option pour indiquer à ADF de traiter seulement les données delta capturées par la technologie de capture des changements de données SQL depuis la dernière exécution du pipeline. Avec cette option, les données delta, y compris l’insertion, la mise à jour et la suppression de lignes, sont chargées automatiquement sans utiliser de colonne incrémentielle. Vous devez activer la capture des changements de données sur Azure SQL MI avant d’utiliser cette option dans ADF. Pour plus d’informations sur cette option dans ADF, consultez la capture native des changements de données. | Non | - | - |
| Commencer la lecture depuis le début | La définition de cette option avec l’extraction incrémentielle indique à ADF de lire toutes les lignes lors de la première exécution d’un pipeline qui a l’extraction incrémentielle activée. | Non | - | - |
Conseil
L’expression de table commune (CTE) dans SQL n’est pas prise en charge dans le mode Requête du flux de données de mappage, car le prérequis pour utiliser ce mode est que les requêtes puissent être utilisées dans la clause FROM de requête SQL, ce que ne peuvent pas faire les expressions CTE. Pour utiliser des expressions CTE, vous devez créer une procédure stockée avec la requête suivante :
CREATE PROC CTESP @query nvarchar(max)
AS
BEGIN
EXECUTE sp_executesql @query;
END
Utilisez ensuite le mode Procédure stockée dans la transformation source du flux de données de mappage et définissez @query comme dans l’exemple with CTE as (select 'test' as a) select * from CTE. Vous pouvez ensuite utiliser les expressions CTE comme vous le voulez.
Exemple de script de source Azure SQL Managed Instance
Quand vous utilisez Azure SQL Managed Instance comme type de source, le script de flux de données associé est le suivant :
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from MYTABLE',
format: 'query') ~> SQLMISource
Transformation du récepteur
Le tableau ci-dessous répertorie les propriétés prises en charge par un récepteur Azure SQL Managed Instance. Vous pouvez modifier ces propriétés sous l’onglet Options du récepteur.
| Name | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Mettre à jour la méthode | Spécifiez les opérations autorisées sur la destination de votre base de données. Par défaut, seules les insertions sont autorisées. Pour mettre à jour, effectuer un upsert ou supprimer des lignes, une transformation de modification de ligne est requise afin de baliser les lignes relatives à ces actions. |
Oui | true ou false |
deletable insertable updateable upsertable |
| Colonnes clés | Pour les mises à jour, les opérations upsert et les suppressions, une ou plusieurs colonnes clés doivent être définies afin de déterminer la ligne à modifier. Le nom de colonne que vous choisissez comme clé sera utilisé dans le cadre des opérations suivantes de mise à jour, d’upsert et de suppression. Vous devez donc choisir une colonne qui existe dans le mappage du récepteur. |
Non | Array | clés |
| Ignorer l’écriture des colonnes clés | Si vous ne souhaitez pas écrire la valeur dans la colonne clé, sélectionnez « Ignorer l’écriture des colonnes clés ». | Non | true ou false |
skipKeyWrites |
| Action table | Détermine si toutes les lignes de la table de destination doivent être recréées ou supprimées avant l’écriture. - Aucun : Aucune action ne sera effectuée sur la table. - Recréer : La table sera supprimée et recréée. Obligatoire en cas de création dynamique d’une nouvelle table. - Tronquer : Toutes les lignes de la table cible seront supprimées. |
Non | true ou false |
recreate truncate |
| Taille du lot | Spécifiez le nombre de lignes écrites dans chaque lot. Les plus grandes tailles de lot améliorent la compression et l’optimisation de la mémoire, mais risquent de lever des exceptions de type mémoire insuffisante lors de la mise en cache des données. | Non | Integer | batchSize |
| Pré et post-scripts SQL | Spécifiez des scripts SQL multilignes qui s’exécutent avant (prétraitement) et après (post-traitement) l’écriture de données dans votre base de données de réception. | Non | String | preSQLs postSQLs |
Conseil
- Il est recommandé de diviser les scripts de commandes par lot uniques contenant plusieurs commandes en plusieurs lots.
- Seules des instructions DDL (Data Definition Language, langage de définition de données) et DML (Data Manipulation Language, langage de manipulation de données) qui retournent un seul nombre de mises à jour peuvent être exécutées dans un lot. Pour en savoir plus, consultez Exécution d’opérations par lot
Exemple de script de récepteur Azure SQL Managed Instance
Quand vous utilisez Azure SQL Managed Instance comme type de récepteur, le script de flux de données associé est le suivant :
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SQLMISink
Propriétés de l’activité Lookup
Pour en savoir plus sur les propriétés, consultez Activité Lookup.
Propriétés de l’activité GetMetadata
Pour en savoir plus sur les propriétés, consultez Activité GetMetadata.
Mappage de type de données pour une instance managée SQL
Quand des données sont copiées vers et depuis SQL Managed Instance à l’aide de l’activité de copie, les mappages suivants sont utilisés entre les types de données SQL Managed Instance et les types de données intermédiaires utilisés en interne dans le service. Pour savoir comment l'activité de copie mappe le schéma et le type de données entre la source et le récepteur, consultez Mappages de schémas et de types de données.
| Type de données d’une instance managée SQL | Type de données de service intermédiaire |
|---|---|
| bigint | Int64 |
| binary | Byte[] |
| bit | Boolean |
| char | String, Char[] |
| Date | DateTime |
| Datetime | DateTime |
| datetime2 | DateTime |
| Datetimeoffset | DateTimeOffset |
| Decimal | Decimal |
| FILESTREAM attribute (varbinary(max)) | Byte[] |
| Float | Double |
| image | Byte[] |
| int | Int32 |
| money | Decimal |
| NCHAR | String, Char[] |
| ntext | String, Char[] |
| numeric | Decimal |
| NVARCHAR | String, Char[] |
| real | Unique |
| rowversion | Byte[] |
| smalldatetime | DateTime |
| SMALLINT | Int16 |
| SMALLMONEY | Decimal |
| sql_variant | Object |
| text | String, Char[] |
| time | TimeSpan |
| timestamp | Byte[] |
| TINYINT | Int16 |
| UNIQUEIDENTIFIER | Guid |
| varbinary | Byte[] |
| varchar | String, Char[] |
| Xml | String |
Notes
Pour les types de données mappés avec le type intermédiaire Decimal,l’activité de copie prend actuellement en charge une précision maximale de 28. Si vous disposez de données qui nécessitent une précision supérieure à 28, pensez à les convertir en chaîne dans une requête SQL.
Utilisation d’Always Encrypted
Quand vous copiez des données depuis/vers SQL Managed Instance avec Always Encrypted, effectuez les étapes suivantes :
Stockez la valeur Clé principale de colonne (CMK) dans un coffre Azure Key Vault. En savoir plus sur la configuration d’Always Encrypted à l’aide d’Azure Key Vault
Vérifiez que le coffre de clés où la valeur Clé principale de colonne (CMK) est stockée est totalement accessible. Consultez cet article pour connaître les autorisations requises.
Créez un service lié pour vous connecter à votre base de données SQL et activez la fonction « Always Encrypted » en utilisant une identité managée ou un principal de service.
Notes
SQL Managed Instance Always Encrypted prend en charge les scénarios suivants :
- Les magasins de données sources ou récepteurs utilisent l’identité managée ou le principal de service comme type d’authentification du fournisseur de clés.
- Les magasins de données sources et récepteurs utilisent l’identité managée comme type d’authentification du fournisseur de clés.
- Les magasins de données sources et récepteurs utilisent le même principal de service que le type d’authentification du fournisseur de clés.
Notes
Actuellement, SQL Managed Instance Always Encrypted est pris en charge uniquement pour la transformation de la source dans les flux de données de mappage.
Capture native des changements de données
Azure Data Factory peut prendre en charge les fonctionnalités de capture native des changements de données pour SQL Server, Azure SQL DB et Azure SQL MI. Les changements de données, notamment l’insertion, la mise à jour et la suppression de lignes dans les magasins SQL, peuvent être détectés et extraits automatiquement par le flux de données de mappage ADF. Avec l’expérience sans code du flux de données de mappage, les utilisateurs peuvent facilement réaliser un scénario de réplication de données à partir de magasins SQL en ajoutant une base de données comme magasin de destination. De plus, les utilisateurs peuvent également composer une logique de transformation de données intermédiaire pour obtenir un scénario ETL incrémentiel à partir de magasins SQL.
Veillez à ne pas changer le nom du pipeline et de l’activité, afin que le point de contrôle puisse être enregistré par ADF pour que vous puissiez obtenir automatiquement les données modifiées à partir de la dernière exécution. Si vous changez le nom de votre pipeline ou de votre activité, le point de contrôle est réinitialisé, ce qui vous oblige à recommencer depuis le début ou à récupérer les prochaines modifications lors de la prochaine exécution. Pour changer le nom du pipeline ou le nom de l’activité en gardant le point de contrôle afin d’obtenir automatiquement les changements de données de la dernière exécution, utilisez votre propre clé de point de contrôle dans l’activité de flux de données.
Lorsque vous déboguez le pipeline, cette fonctionnalité fonctionne de la même façon. Sachez que le point de contrôle est réinitialisé lorsque vous actualisez votre navigateur lors de l’exécution du débogage. Une fois que vous êtes satisfait du résultat du pipeline de l’exécution du débogage, vous pouvez publier et déclencher le pipeline. Au moment où vous déclenchez pour la première fois votre pipeline publié, il redémarre automatiquement à partir du début ou obtient les modifications à partir de ce moment-là.
Dans la section de monitoring, vous avez toujours la possibilité de réexécuter un pipeline. Dans ce cas, les données modifiées sont toujours capturées à partir du point de contrôle précédent de votre exécution de pipeline sélectionnée.
Exemple 1 :
Quand vous chaînez directement une transformation de source référencée dans un jeu de données utilisant CDC SQL à une transformation de récepteur référencée dans une base de données dans un flux de données de mappage, les changements qui se produisent dans la source SQL sont automatiquement appliqués à la base de données cible, pour obtenir facilement un scénario de réplication de données entre les bases de données. Vous pouvez utiliser la méthode de mise à jour dans la transformation du récepteur pour sélectionner si vous voulez autoriser l’insertion, la mise à jour ou la suppression sur la base de données cible. L’exemple de script dans le flux de données de mappage est décrit ci-dessous.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
keys:['id'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Exemple 2 :
Si vous voulez activer le scénario ETL au lieu de la réplication de données entre bases de données via CDC SQL, vous pouvez utiliser des expressions dans le flux de données de mappage, notamment isInsert(1), isUpdate(1) et isDelete(1) pour différencier les lignes qui ont différents types d’opération. Voici un exemple de script de flux de données de mappage qui dérive une colonne avec la valeur : 1 pour indiquer des lignes insérées, 2 pour indiquer des lignes mises à jour et 3 pour indiquer des lignes supprimées dans les transformations en aval afin de traiter les données delta.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 derive(operationType = iif(isInsert(1), 1, iif(isUpdate(1), 2, 3))) ~> derivedColumn1
derivedColumn1 sink(allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Limitation connue :
- Seuls les changements nets de CDC SQL sont chargés par ADF via cdc.fn_cdc_get_net_changes_.
Mettre à niveau la version d’Azure SQL Managed Instance
Pour mettre à niveau la version d’Azure SQL Managed Instance, dans la page Modifier le service lié, sélectionnez Recommandé sous Version, puis configurez le service lié en faisant référence aux Propriétés du service lié pour la version recommandée.
Différences entre la version recommandée et la version héritée
Le tableau ci-dessous présente les différences dans Azure SQL Managed Instance lors de l’utilisation de la version recommandée et de la version héritée.
| Version recommandée | Version héritée |
|---|---|
Prend en charge TLS 1.3 via encrypt en tant que strict. |
TLS 1.3 n’est pas pris en charge. |
Contenu connexe
Consultez les magasins de données pris en charge pour obtenir la liste des sources et magasins de données pris en charge en tant que récepteurs par l’activité de copie.