Transformation du récepteur dans le flux de données de mappage
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Les flux de données sont disponibles à la fois dans les pipelines Azure Data Factory et Azure Synapse. Cet article s’applique aux flux de données de mappage. Si vous débutez dans le domaine des transformations, consultez l’article d’introduction Transformer des données avec un flux de données de mappage.
Une fois que vous avez terminé de transformer vos données, écrivez-les dans un magasin de destination à l’aide de la transformation du récepteur. Chaque flux de données requiert la transformation d'au moins un récepteur. Vous pouvez cependant écrire dans autant de récepteurs que nécessaire pour terminer votre flux de transformations. Pour écrire dans des récepteurs supplémentaires, créez de nouveaux flux via de nouvelles branches et des fractionnements conditionnels.
Chaque transformation de récepteur est associée à exactement un objet de jeu de données ou à un service lié unique. La transformation du récepteur détermine la forme et l’emplacement des données sur lesquelles vous souhaitez écrire.
Jeux de données inlined
Lors de la création d’une transformation de récepteur, indiquez si vos informations de récepteur sont définies au sein d’un objet de jeu de données ou dans la transformation du récepteur. La plupart des formats sont uniquement disponibles dans l’un ou l’autre. Pour savoir comment utiliser un connecteur en particulier, référez-vous à la documentation le concernant.
Si un format est pris en charge à la fois inlined et dans les objets de jeu de données, notez que ces deux options présentent des avantages. Les objets de jeu de données sont des entités réutilisables qui peuvent être utilisées dans d’autres flux de données et activités telles que la copie. Ces entités réutilisables sont particulièrement utiles lorsque vous utilisez un schéma renforcé. Les jeux de données ne sont pas basés sur Spark. Il peut arriver que vous deviez remplacer certains paramètres ou la projection de schéma dans la transformation du récepteur.
Les jeux de données inlined sont recommandés lorsque vous utilisez des schémas flexibles, d’instances de récepteurs uniques ou de récepteurs paramétrables. Si votre récepteur est fortement paramétrable, les jeux de données inlined vous permettront de ne pas créer d’objet « factice ». Les jeux de données inlined sont basés sur Spark et leurs propriétés sont natives au flux de données.
Pour utiliser un jeu de données inlined, sélectionnez le format de votre choix à l’aide du sélecteur Type de récepteur. Au lieu de sélectionner un jeu de données récepteur, sélectionnez le service lié auquel vous souhaitez vous connecter.
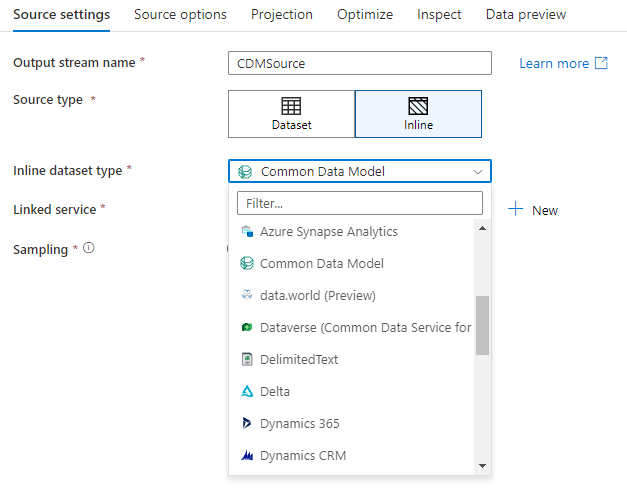
BASE de l’espace de travail (espaces de travail Synapse uniquement)
Lorsque vous utilisez des flux de données dans des espaces de travail Azure Synapse, vous disposez d’une option supplémentaire pour recevoir vos données directement dans un type de base de données qui se trouve à l’intérieur de votre espace de travail synapse. Cela permet d’éviter d’ajouter des services liés ou des jeux de données pour ces bases de données. Les bases de données créées via les modèles de base de données Azure Synapse sont également accessibles lorsque vous sélectionnez Base de données de l’espace de travail.
Notes
Le connecteur Workspace DB d’Azure Synapse est actuellement en préversion publique et peut uniquement s’utiliser avec des bases de données Spark Lake pour l’instant.
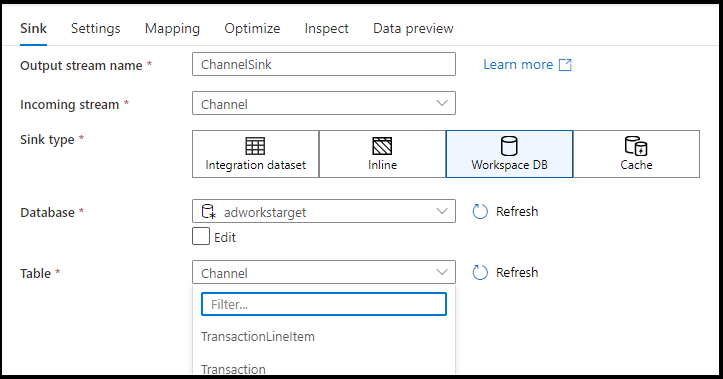
Types de récepteurs pris en charge
Le flux de données de mappage suit une approche basée sur l’extraction, le chargement et la transformation (ELT, extract, load, transform) et fonctionne avec des jeux de données intermédiaires qui se trouvent tous dans Azure. Actuellement, les jeux de données suivants peuvent être utilisés dans une transformation de récepteur.
| Connecteur | Format | Jeu de données/Inlined |
|---|---|---|
| Stockage Blob Azure | Avro Texte délimité Delta JSON ORC Parquet |
✓/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB pour NoSQL | ✓/- | |
| Azure Data Lake Storage Gen1 | Avro Texte délimité JSON ORC Parquet |
✓/- ✓/- ✓/- ✓/✓ ✓/- |
| Azure Data Lake Storage Gen2 | Avro Common Data Model Texte délimité Delta JSON ORC Parquet |
✓/✓ -/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Database pour MySQL | ✓/✓ | |
| Base de données Azure pour PostgreSQL | ✓/✓ | |
| Explorateur de données Azure | ✓/✓ | |
| Azure SQL Database | ✓/✓ | |
| Azure SQL Managed Instance | ✓/- | |
| Azure Synapse Analytics | ✓/- | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| Fabric Lakehouse | ✓/✓ | |
| SFTP | Avro Texte délimité JSON ORC Parquet |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Snowflake | ✓/✓ | |
| SQL Server | ✓/✓ |
Les paramètres spécifiques à ces connecteurs se trouvent sous l’onglet Paramètres. Vous trouverez des informations et des exemples de scripts de flux de données concernant ces paramètres dans la documentation relative aux connecteurs.
Le service a accès à plus de 90 connecteurs natifs. Pour écrire des données sur ces autres sources à partir de votre flux de données, utilisez l’activité de copie pour charger ces données à partir d’un récepteur pris en charge.
Paramètres de récepteur
Après avoir ajouté un récepteur, configurez-le via l'onglet Récepteur. Sous cet onglet, vous pouvez sélectionner ou créer le jeu de données dans lequel votre récepteur écrira. Les valeurs de développement des paramètres de jeux de données peuvent être configurées dans les Paramètres de débogage. (Le mode débogage doit être activé.)
La vidéo suivant explique un certain nombre d’options de récepteur pour les types de fichiers délimités par du texte,
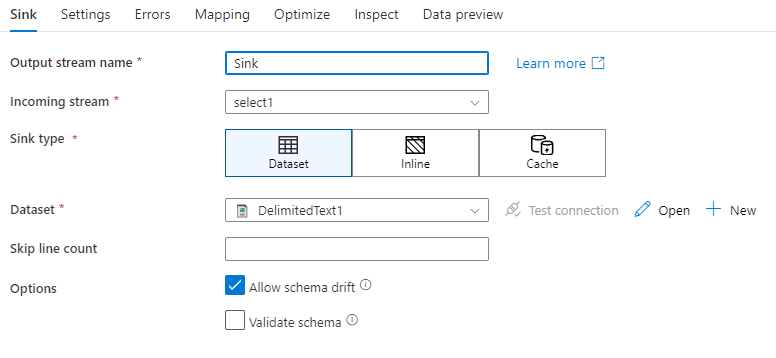
Dérive de schéma : La dérive de schéma est la capacité du service à gérer nativement des schémas flexibles dans vos flux de données sans avoir besoin de définir explicitement des changements de colonnes. Activez Autoriser la dérive de schéma pour écrire des colonnes supplémentaires, en plus de ce qui est défini dans le schéma de données du récepteur.
Valider le schéma : si l’option Valider le schéma est sélectionnée, le flux de données échoue si une colonne dans la projection du récepteur est introuvable dans le magasin du récepteur, ou si les types de données ne correspondent pas. Utilisez ce paramètre pour que le schéma du récepteur respecte le contrat de votre projection définie. Il est utile dans les scénarios de récepteur de base de données pour signaler que les noms ou les types de colonne ont changé.
Récepteur de cache
Un récepteur de cache existe lorsqu’un flux de données écrit des données dans le cache Spark et non dans un magasin de données. Dans les flux de données de mappage, vous pouvez référencer ces données à la fois dans le même flux à l’aide d’une recherche dans le cache. Cela est utile lorsque vous souhaitez référencer des données dans le cadre d’une expression, mais que vous ne souhaitez pas explicitement y joindre les colonnes. La recherche d’une valeur maximale dans un magasin de données et la mise en correspondance des codes d’erreur avec une base de données de messages d’erreur sont des situations courantes dans lesquelles un récepteur de cache peut être utile.
Pour écrire dans un récepteur de cache, ajoutez une transformation de récepteur et sélectionnez Cache comme type de récepteur. Contrairement à d’autres types de récepteurs, vous ne devez pas sélectionner un jeu de données ou un service lié, car vous n’écrivez pas dans un magasin externe.
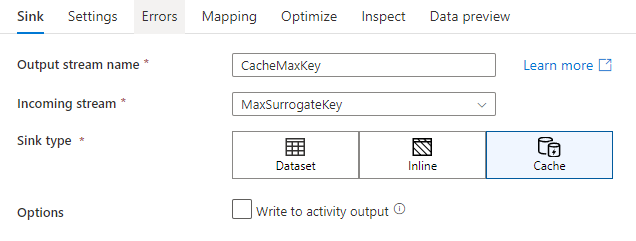
Dans les paramètres du récepteur, vous pouvez éventuellement spécifier les colonnes clés du récepteur de cache. Elles sont utilisées comme conditions de correspondance lors de l’utilisation de la fonction lookup() dans une recherche dans le cache. Si vous spécifiez des colonnes clés, vous ne pouvez pas utiliser la fonction outputs() dans une recherche dans le cache. Pour en savoir plus sur la syntaxe de recherche dans le cache, consultez recherches mises en cache.
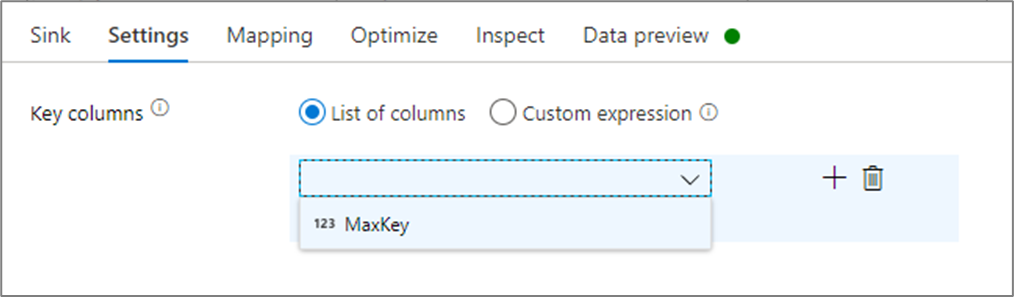
Par exemple, si je spécifie une seule colonne clé de column1 dans un récepteur de cache appelé cacheExample, l’appel de cacheExample#lookup() aurait un paramètre spécifiant la ligne à laquelle le récepteur de cache doit correspondre. La fonction génère une colonne complexe unique avec des sous-colonnes pour chaque colonne mappée.
Notes
Un récepteur de cache doit se trouver dans un flux de données complètement indépendant de toute transformation qui y fait référence par le biais d’une recherche dans le cache. Un récepteur de cache doit également être le premier récepteur écrit.
Écrire dans la sortie de l’activité Le récepteur mis en cache peut éventuellement écrire vos données de sortie dans l’entrée de l’activité de pipeline suivante. Cela vous permettra de transmettre rapidement et facilement des données de votre activité de flux de données sans avoir à conserver les données dans un magasin de données.
Mettre à jour la méthode
Pour les types de récepteur de base de données, l’onglet Paramètres inclut une propriété « Méthode de mise à jour ». La valeur par défaut est l’insertion, mais il inclut également des options de case à cocher pour la mise à jour, l’upsert et la suppression. Pour utiliser ces options supplémentaires, vous devez ajouter une transformation de modification de ligne (Alter Row) avant le récepteur. L’opération Alter Row vous permet de définir les conditions pour chacune des actions de base de données. Si votre source est une source d’activation de CDC native, vous pouvez définir les méthodes de mise à jour sans modification de ligne (Alter Row), car ADF connaît déjà les marqueurs de ligne pour l’insertion, la mise à jour, l’upsert et la suppression.
Mappages de champs
Comme pour une transformation de sélection (Select), l'onglet Mappage du récepteur vous permet de choisir les colonnes entrantes dans lesquelles l'écriture interviendra. Par défaut, toutes les colonnes d'entrée, y compris les colonnes dérivées, sont mappées. Ce comportement est connu sous le nom de mappage automatique.
Lorsque vous désactivez le mappage automatique, vous pouvez ajouter des mappages basés sur des colonnes ou des mappages basés sur des règles. Avec le mappage basé sur des règles, vous pouvez écrire des expressions avec des critères spéciaux. Le mappage fixe mappe les noms de colonnes logiques et physiques. Pour plus d'informations sur le mappage basé sur des règles, consultez Modèles de colonne dans le flux de données de mappage.
Ordre des récepteurs personnalisé
Par défaut, les données sont écrites dans plusieurs récepteurs selon un ordre non déterministe. Le moteur d’exécution écrit les données en parallèle à l’issue de la logique de transformation et l’ordre des récepteurs peut varier d’une exécution à l’autre. Pour spécifier l’ordre exact des récepteurs, activez Ordre des récepteurs personnalisé sous l’onglet Général du flux de données. Quand cette option est activée, les récepteurs sont écrits séquentiellement dans l’ordre croissant.
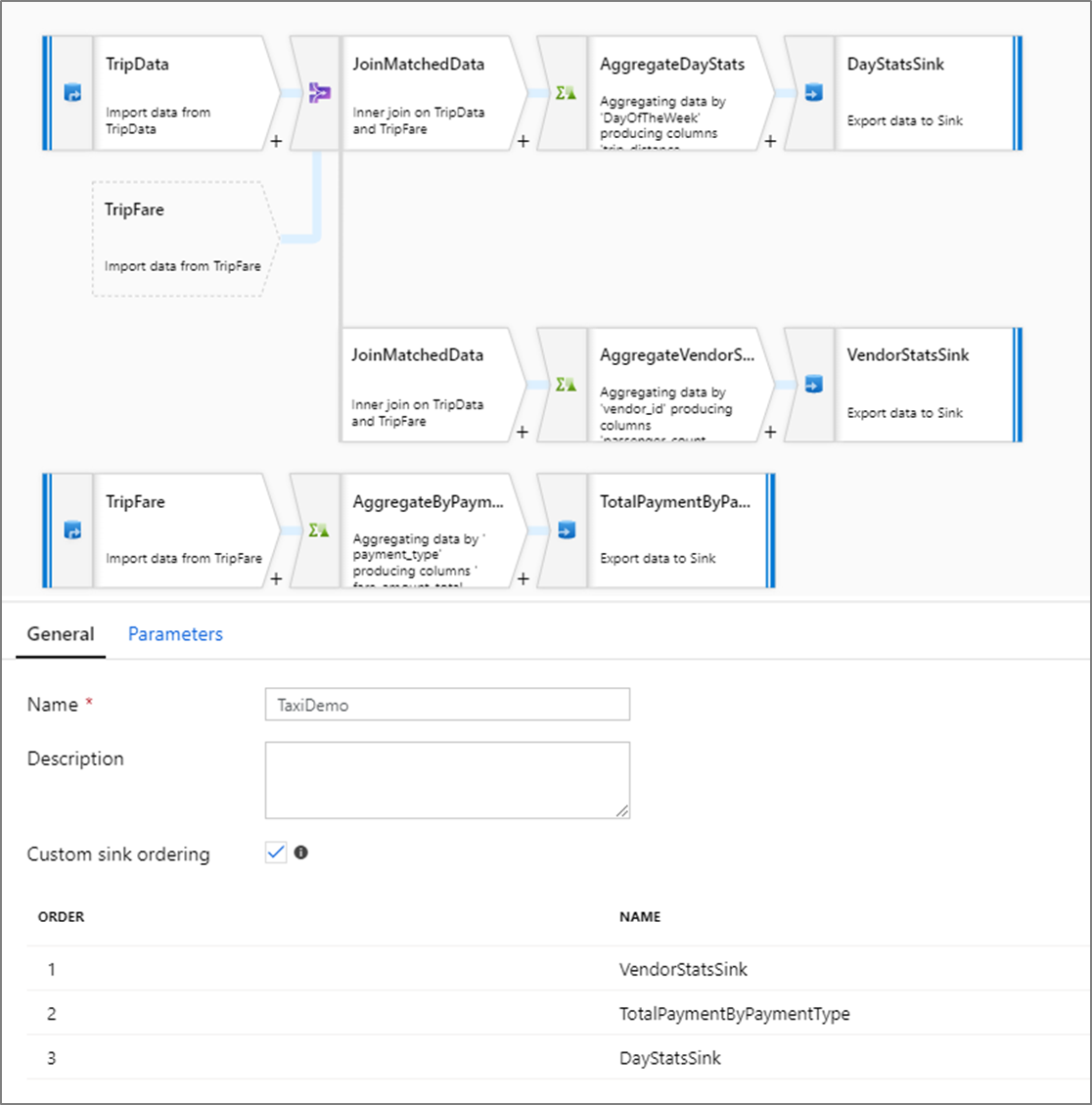
Remarque
Lors de l’utilisation de recherches mises en cache, assurez-vous que l’ordre des récepteurs mis en cache est défini sur 1, le plus bas (ou le premier) dans le classement.
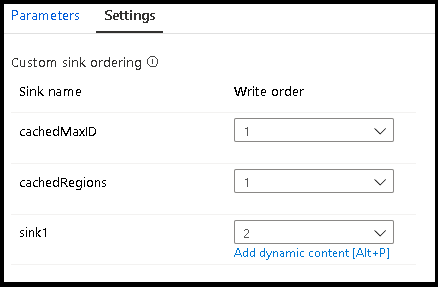
Groupes de récepteurs
Vous pouvez regrouper les récepteurs en appliquant le même numéro d’ordre pour une série de récepteurs. Le service traitera ces récepteurs comme des groupes qui peuvent s’exécuter en parallèle. Les options d’exécution en parallèle s’affichent dans l’activité de flux de données du pipeline.
Erreurs
Sous l’onglet Erreurs du récepteur, vous pouvez configurer la gestion des lignes d’erreur pour capturer et rediriger la sortie pour les erreurs du pilote de base de données et les assertions ayant échoué.
Lors de l’écriture dans des bases de données, certaines lignes de données peuvent échouer en raison de contraintes définies par la destination. Par défaut, l’exécution d’un flux de données échouera à la première erreur rencontrée. Dans certains connecteurs, vous pouvez choisir de Continuer en cas d’erreur, ce qui permet à votre flux de données de se terminer, même si des lignes individuelles comportent des erreurs. Actuellement, cette fonctionnalité n’est disponible que dans Azure Synapse et Azure SQL Database. Pour plus d’informations, consultez Gestion des lignes d’erreurs dans Azure SQL Database.
Vous trouverez ci-dessous un didacticiel vidéo sur l’utilisation automatique de la gestion des lignes d’erreur de base de données dans votre transformation du récepteur.
Pour les lignes d’échec d’assertion, vous pouvez utiliser la transformation d’assertion en amont dans votre flux de données, puis rediriger les assertions ayant échoué vers un fichier de sortie dans l’onglet Erreurs du récepteur. Vous avez également la possibilité ici d’ignorer les lignes avec des échecs d’assertion et de ne pas générer ces lignes du tout dans le magasin de données de destination récepteur.
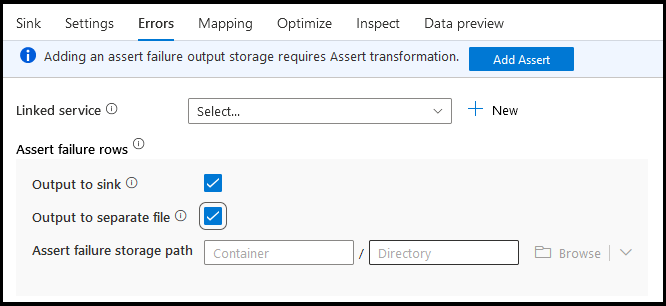
Aperçu des données dans le récepteur
Lors de la récupération d’un aperçu des données sur un mode débogage, aucune donnée n’est écrite dans votre récepteur. Une capture instantanée des données est renvoyée, mais rien n'est écrit à l'emplacement de destination. Pour tester l'écriture de données dans votre récepteur, exécutez un débogage de pipeline à partir du canevas du pipeline.
Script de flux de données
Exemple
Ci-dessous se trouve un exemple de transformation de récepteur et de son script de flux de données :
sink(input(
movie as integer,
title as string,
genres as string,
year as integer,
Rating as integer
),
allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:false,
updateable:true,
upsertable:false,
keys:['movie'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
saveOrder: 1,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Contenu connexe
Maintenant que vous avez créé votre flux de données, ajoutez une activité de flux de données à votre pipeline.