Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
APPLIES TO : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Data Factory dans Microsoft Fabric est la prochaine génération de Azure Data Factory, avec une architecture plus simple, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'intégration des données, commencez par Fabric Data Factory. Les charges de travail ADF existantes peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Le système de métadonnées Common Data Model (CDM) permet aux données et à leur signification d’être facilement partagées entre les applications et les processus métier. Pour plus d’informations, consultez la vue d’ensemble Common Data Model.
Dans les pipelines Azure Data Factory et Synapse, les utilisateurs peuvent transformer des données à partir d’entités CDM au format model.json et manifeste stockés dans Azure Data Lake Store Gen2 (ADLS Gen2) à l’aide de flux de données de mappage. Vous pouvez également recevoir des données au format CDM à l’aide des références d’entité CDM qui déposeront vos données au format CSV ou Parquet dans des dossiers partitionnés.
Propriétés du mappage de flux de données
Le Common Data Model est disponible en tant que jeu de données inline dans les flux de données de mappage en tant que source et récepteur.
Remarque
Lorsque vous écrivez des entités CDM, vous devez avoir une définition d’entité CDM existante (schéma de métadonnées) déjà définie pour l’utiliser comme référence. Le récepteur de flux de données lira ce fichier d’entité CDM et importera le schéma dans votre récepteur pour le mappage de champs.
Remarque
Lorsque vous utilisez CDM avec capture de données modifiées (CDC) dans les flux de données, les mises à jour sont détectées à l’aide d’une approche CDC basée sur des fichiers pilotée par les horodatages modifiés du dernier fichier.
Propriétés de source
Le tableau ci-dessous répertorie les propriétés prises en charge par une source CDM. Vous pouvez modifier ces propriétés sous l’onglet Options de source.
| Nom | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Format | Le format doit être cdm |
Oui | cdm |
format |
| Format de métadonnées | Où se trouve la référence d’entité aux données. Si vous utilisez la version 1.0 de CDM, choisissez manifeste. Si vous utilisez une version CDM antérieure à 1.0, choisissez model.json. | Oui |
'manifest' ou 'model' |
manifestType |
| Emplacement racine : conteneur | Nom de conteneur du dossier CDM | Oui | String | fileSystem |
| Emplacement racine : chemin d’accès au dossier | Emplacement du dossier racine du dossier CDM | Oui | String | folderPath |
| Fichier manifeste : chemin d’accès de l’entité | Chemin d’accès du dossier de l’entité dans le dossier racine | non | String | entityPath |
| Fichier manifeste : nom du manifeste | Nom du fichier manifeste. La valeur par défaut est « Default » | Non | String | manifestName |
| Filtrer par date de dernière modification | Pour filtrer les fichiers en fonction de leur date de dernière modification | non | Timestamp | modifiedAfter modifiedBefore |
| Service lié au schéma | Le service lié dans lequel se trouve le corpus | oui, en cas d’utilisation du manifeste |
'adlsgen2' ou 'github' |
corpusStore |
| Conteneur de référence d’entité | Le corpus du conteneur est dans | oui, si vous utilisez le manifeste et le corpus dans ADLS Gen2 | String | adlsgen2_fileSystem |
| Référentiel de référence d’entité | nom du référentiel GitHub | Oui, si vous utilisez le manifeste et le corpus dans GitHub | String | github_repository |
| Branche de référence d’entité | branche de référentiel GitHub | Oui, si vous utilisez le manifeste et le corpus dans GitHub | String | github_branch |
| Dossier de corpus | l’emplacement racine du corpus | oui, en cas d’utilisation du manifeste | String | corpusPath |
| Entité de corpus | Chemin d’accès vers la référence d’entité | Oui | String | entité |
| N’autoriser aucun fichier trouvé | Si la valeur est true, aucune erreur n’est levée si aucun fichier n’est trouvé | non |
true ou false |
ignoreNoFilesFound |
Lorsque vous sélectionnez « Référence d’entité » dans les transformations de source et de récepteur, vous pouvez sélectionner les trois options suivantes comme emplacement de votre référence d’entité :
- Local utilise l’entité définie dans le fichier manifeste déjà utilisé par le service
- Custom (personnalisé) vous demande de pointer vers un fichier manifeste d’entité différent du fichier manifeste que le service utilise
- Standard utilise une référence d’entité à partir de la bibliothèque standard d’entités CDM conservées dans
GitHub.
Paramètres de récepteur
- Pointez sur le fichier de référence d’entité CDM qui contient la définition de l’entité que vous souhaitez écrire.
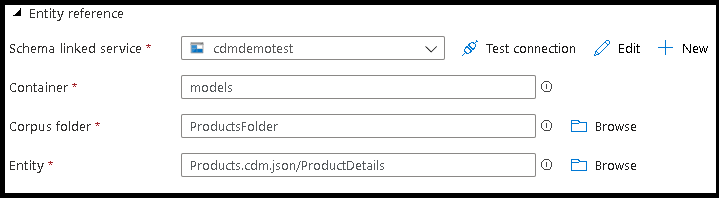
- Définissez le chemin d’accès à la partition et le format des fichiers de sortie que vous souhaitez que le service utilise pour l’écriture de vos entités.
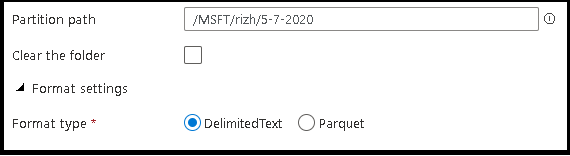
- Définissez l’emplacement du fichier de sortie ainsi que l’emplacement et le nom du fichier manifeste.

Importer un schéma
CDM est uniquement disponible en tant que jeu de données inline et, par défaut, n’a pas de schéma associé. Pour récupérer les métadonnées des colonnes, cliquez sur le bouton Importer le schéma sous l’onglet Projection. Cela vous permet de référencer les noms de colonnes et les types de données spécifiés par le corpus. Pour importer le schéma, une session de débogage de flux de données doit être active et vous devez disposer d’un fichier de définition d’entité CDM vers lequel pointer.
Lors du mappage des colonnes de flux de données aux propriétés des entités dans la transformation du récepteur, cliquez sur l’onglet « Mappage » et sélectionnez « Importer le schéma ». Le service lira la référence d’entité vers laquelle vous avez pointé dans vos options de récepteur, ce qui vous permet de mapper le schéma CDM cible.
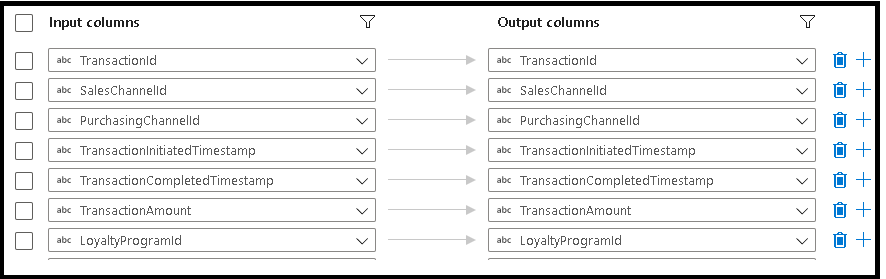
Remarque
Lorsque vous utilisez model.json type de source provenant de flux de données Power BI ou Power Platform, vous pouvez rencontrer des erreurs « le chemin d’accès au corpus est null ou vide » de la transformation source. Cela est probablement dû à des problèmes de mise en forme du chemin d’accès de l’emplacement de la partition dans le fichier model.json. Pour résoudre ce problème, procédez comme suit :
- Ouvrez le fichier model.json dans un éditeur de texte
- Recherchez les partitions.Location, propriété
- Remplacez « blob.core.windows.net » par « dfs.store.core.windows.net »
- Corrigez tout encodage « % 2F » dans l’URL en « / »
- Si vous utilisez des flux de données ADF, les caractères spéciaux dans le chemin du fichier de partition doivent être remplacés par des valeurs alphanumériques ou basculer vers Azure Synapse flux de données
Exemple de script de flux de données sources CDM
source(output(
ProductSizeId as integer,
ProductColor as integer,
CustomerId as string,
Note as string,
LastModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
entity: 'Product.cdm.json/Product',
format: 'cdm',
manifestType: 'manifest',
manifestName: 'ProductManifest',
entityPath: 'Product',
corpusPath: 'Products',
corpusStore: 'adlsgen2',
adlsgen2_fileSystem: 'models',
folderPath: 'ProductData',
fileSystem: 'data') ~> CDMSource
Propriétés du récepteur
Le tableau ci-dessous répertorie les propriétés prises en charge par un récepteur CDM. Vous pouvez modifier ces propriétés sous l’onglet Paramètres.
| Nom | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Format | Le format doit être cdm |
Oui | cdm |
format |
| Emplacement racine : conteneur | Nom de conteneur du dossier CDM | Oui | String | fileSystem |
| Emplacement racine : chemin d’accès au dossier | Emplacement du dossier racine du dossier CDM | Oui | String | folderPath |
| Fichier manifeste : chemin d’accès de l’entité | Chemin d’accès du dossier de l’entité dans le dossier racine | non | String | entityPath |
| Fichier manifeste : nom du manifeste | Nom du fichier manifeste. La valeur par défaut est « Default » | Non | String | manifestName |
| Service lié au schéma | Le service lié dans lequel se trouve le corpus | Oui |
'adlsgen2' ou 'github' |
corpusStore |
| Conteneur de référence d’entité | Le corpus du conteneur est dans | oui, si corpus dans ADLS Gen2 | String | adlsgen2_fileSystem |
| Référentiel de référence d’entité | nom du référentiel GitHub | Oui, si le corpus dans GitHub | String | github_repository |
| Branche de référence d’entité | branche de référentiel GitHub | Oui, si le corpus dans GitHub | String | github_branch |
| Dossier de corpus | l’emplacement racine du corpus | Oui | String | corpusPath |
| Entité de corpus | Chemin d’accès vers la référence d’entité | Oui | String | entité |
| Chemin d’accès de partition | Emplacement où la partition sera écrite | non | String | partitionPath |
| Vider le dossier | Si le dossier de destination est vidé avant l’écriture | non |
true ou false |
truncate |
| Type de format | Choisir pour spécifier le format parquet | non |
parquet si spécifié |
subformat |
| Délimiteur de colonne | En cas d’écriture dans DelimitedText, comment délimiter des colonnes | oui, en cas d’écriture dans DelimitedText | String | columnDelimiter |
| Première ligne comme en-tête | En cas d’utilisation de DelimitedText, si les noms des colonnes sont ajoutés en tant qu’en-tête | non |
true ou false |
columnNamesAsHeader |
Exemple de script de flux de données de récepteur CDM
Le script de flux de données associé est le suivant :
CDMSource sink(allowSchemaDrift: true,
validateSchema: false,
entity: 'Product.cdm.json/Product',
format: 'cdm',
entityPath: 'ProductSize',
manifestName: 'ProductSizeManifest',
corpusPath: 'Products',
partitionPath: 'adf',
folderPath: 'ProductSizeData',
fileSystem: 'cdm',
subformat: 'parquet',
corpusStore: 'adlsgen2',
adlsgen2_fileSystem: 'models',
truncate: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CDMSink
Contenu connexe
Créer une transformation de source dans le flux de données de mappage.