Copier les données depuis Azure Data Lake Storage Gen1 vers Gen2 avec Azure Data Factory
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Azure Data Lake Storage Gen2 est un ensemble de fonctionnalités dédiées à l’analytique de Big Data qui est intégrée au service Stockage Blob Azure. Il vous permet d’interagir avec vos données selon les deux paradigmes que sont le système de fichiers et le stockage d’objets.
Si vous utilisez actuellement Azure Data Lake Storage Gen1, vous pouvez essayer Azure Data Lake Storage Gen2 en copiant les données de Data Lake Storage Gen1 vers Gen2 à l’aide du service Azure Data Factory.
Azure Data Factory est un service informatique d’intégration de données informatique intégralement managé. Vous pouvez utiliser le service pour remplir le lac avec des données provenant d’un ensemble étendu de banques de données locales et cloud quand vous créez vos solutions d’analytique. Pour obtenir une liste des connecteurs pris en charge, consultez le tableau des banques de données prises en charge.
Azure Data Factory offre une solution de déplacement des données managées qui est évolutive. En raison de l’architecture scale-out de Data Factory ,elle peut ingérer des données à un débit élevé. Pour plus d’informations, consultez Performances de l’activité de copie.
Cet article vous explique comment utiliser l’outil de copie de données de Data Factory pour copier des données depuis Azure Data Lake Storage Gen1 vers Azure Data Lake Storage Gen2. Vous pouvez procéder de même pour copier des données à partir d’autres types de banques de données.
Prérequis
- Un abonnement Azure. Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
- Compte Azure Data Lake Storage Gen1 contenant des données.
- Compte de stockage Azure avec Data Lake Storage Gen2 activé. Si vous n’avez pas de compte de stockage, créez-en un.
Créer une fabrique de données
Si vous n’avez pas encore créé votre fabrique de données, suivez les étapes de démarrage rapide : Créer une fabrique de données à l’aide du Portail Azure et Azure Data Factory Studio pour en créer une. Après la création, accédez à la fabrique de données dans le Portail Azure.

Sélectionnez Ouvrir dans la mosaïque Ouvrir Azure Data Factory Studio pour lancer l’application d’intégration de données dans un onglet distinct.
Charger des données dans Azure Data Lake Storage Gen2
Sur la page d’accueil, sélectionnez la mosaïque Ingérer pour lancer l’outil de copie des données.
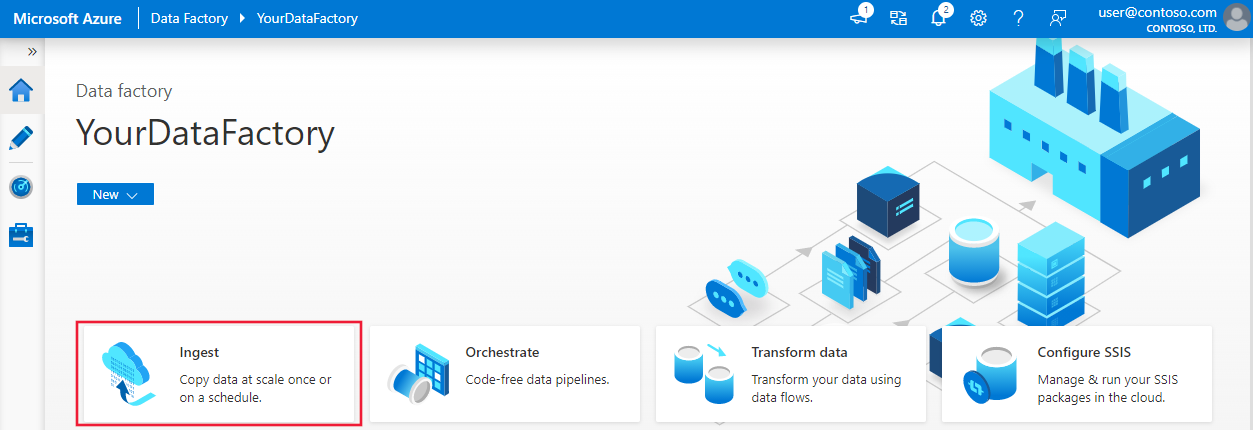
Sur la page Propriétés, choisissez Tâche de copie intégrée sous Type de tâche et choisissez Exécuter une fois maintenant sous Cadence ou planification des tâches, puis sélectionnez Suivant.
Dans la page Banque de données sources, sélectionnez + Nouvelle connexion.
Sélectionnez Azure Data Lake Storage Gen1 dans la galerie des connecteurs, puis sélectionnez Continuer.
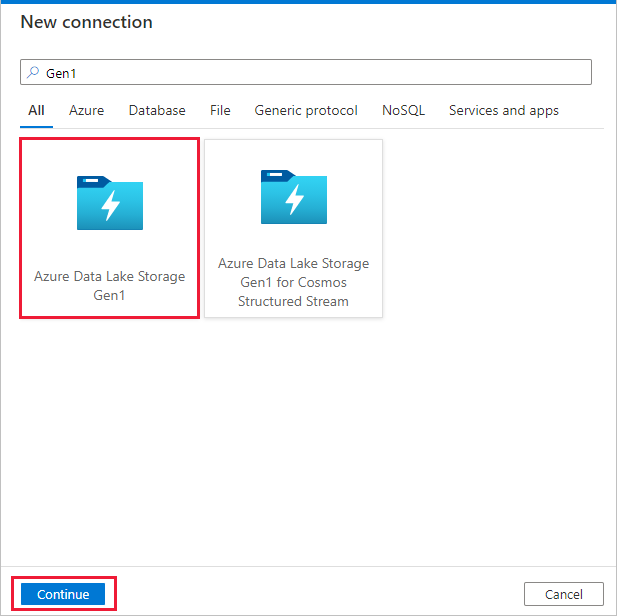
Dans la page Nouvelle connexion (Azure Data Lake Storage Gen1) , effectuez ces étapes :
- Sélectionnez votre Data Lake Storage Gen1 pour le nom du compte, puis spécifiez ou confirmez le locataire.
- Sélectionnez Tester la connexion pour vérifier les paramètres. Sélectionnez ensuite Créer.
Important
Dans cette procédure pas à pas, vous utilisez une identité managée pour des ressources Azure afin d’authentifier votre solution Azure Data Lake Storage Gen1. Pour accorder à l’identité managée les autorisations appropriées dans Azure Data Lake Storage Gen1, suivez ces instructions.
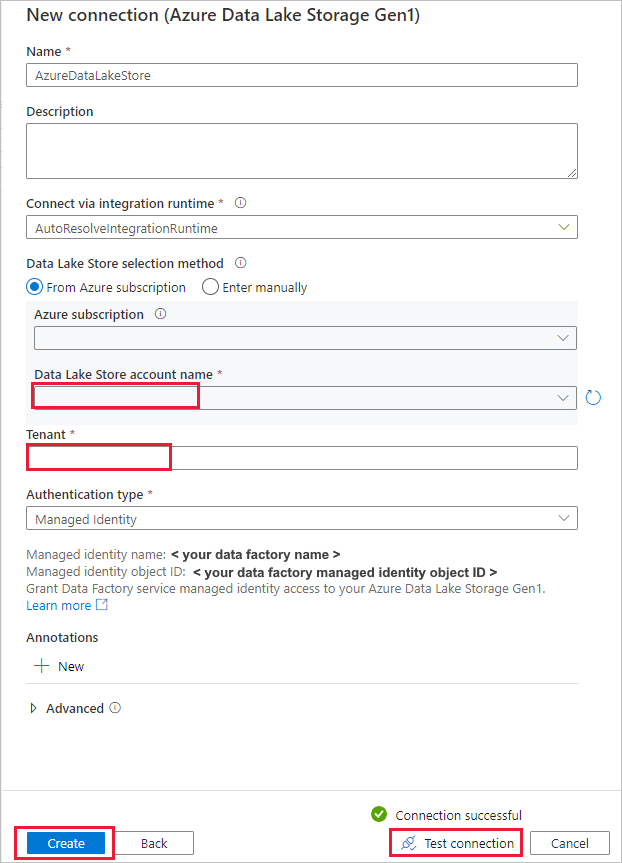
Sur la page Banque de données source, procédez comme suit.
- Sélectionnez la nouvelle connexion dans la section Connexion.
- Sous Fichier ou dossier, accédez au fichier ou au dossier où vous voulez copier les données. Sélectionnez le dossier ou le fichier, puis sélectionnez OK.
- Spécifiez le comportement de copie en sélectionnant les options Copier les fichiers de façon récursive et Copie binaire. Sélectionnez Suivant.
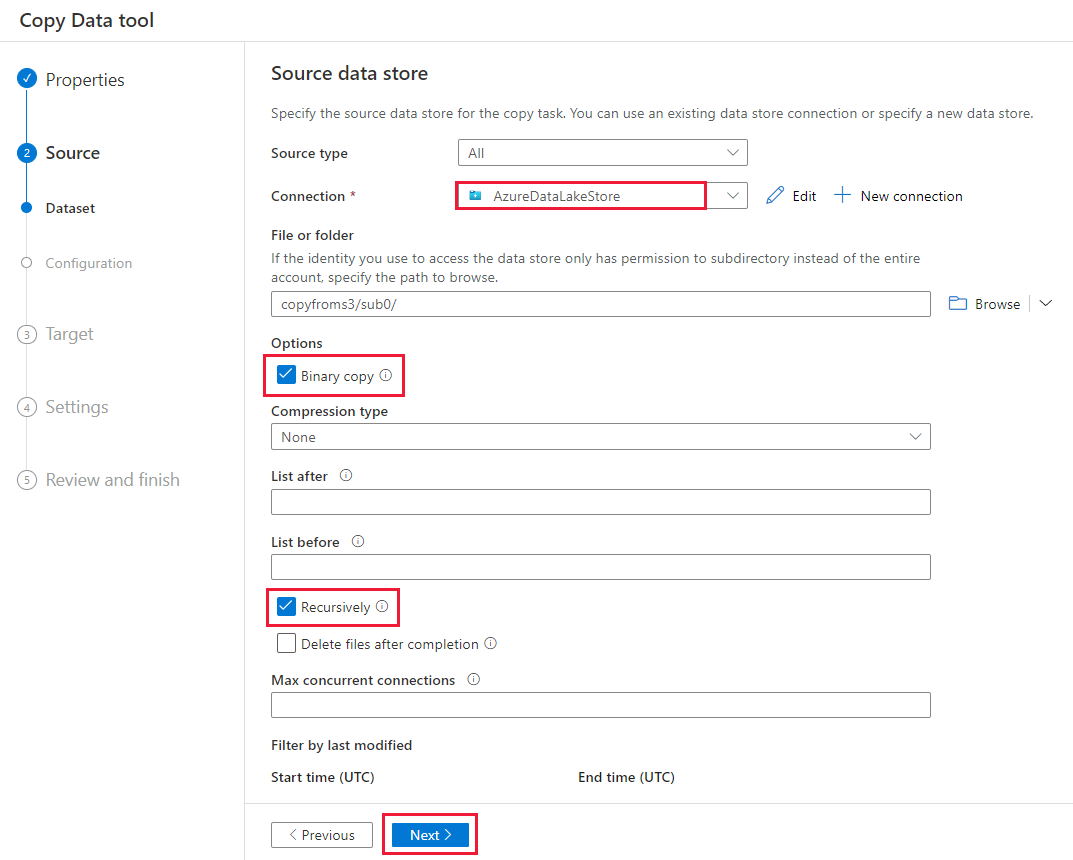
Dans la page Magasin de données de destination, sélectionnez + Nouvelle connexion>Azure Data Lake Storage Gen2>Continuer.
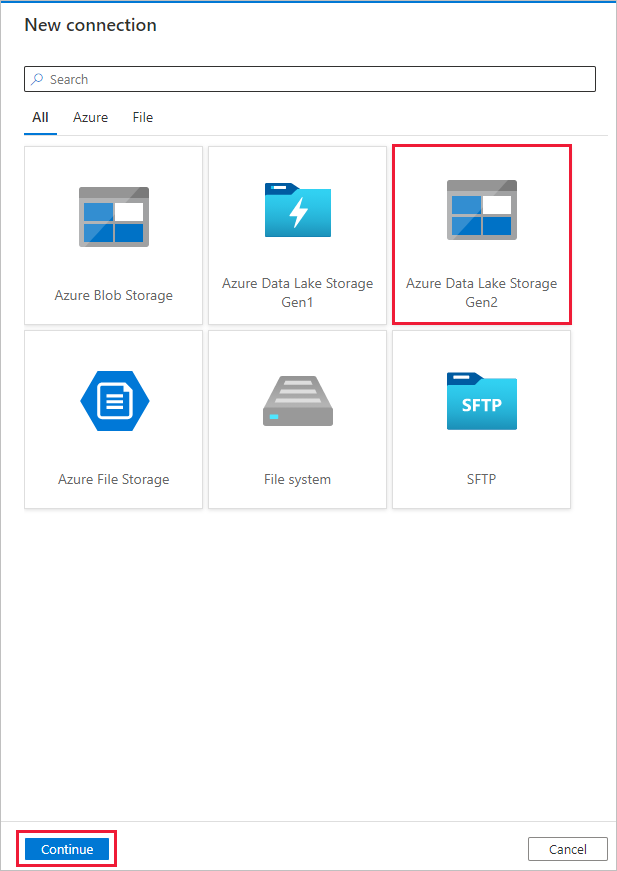
Dans la page Nouvelle connexion (Azure Data Lake Storage Gen2) , effectuez ces étapes :
- Sélectionnez votre compte activé pour Data Lake Storage Gen2 dans la liste déroulante Nom du compte de stockage.
- Sélectionnez Créer pour créer la connexion.
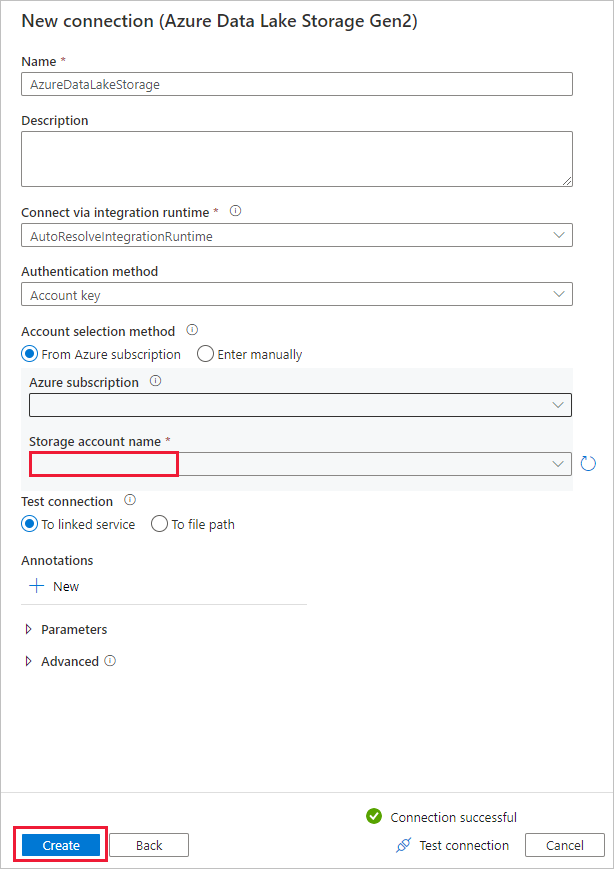
Sur la page Magasin de données de destination, procédez comme suit.
- Sélectionnez la nouvelle connexion dans le bloc Connexion.
- Sous Chemin d’accès du dossier, entrez copyfromadlsgen1 comme nom du dossier de sortie, puis sélectionnez Suivant. Data Factory crée le système de fichiers et les sous-dossiers Azure Data Lake Storage Gen2 correspondants pendant la copie s’il ne les trouve pas.
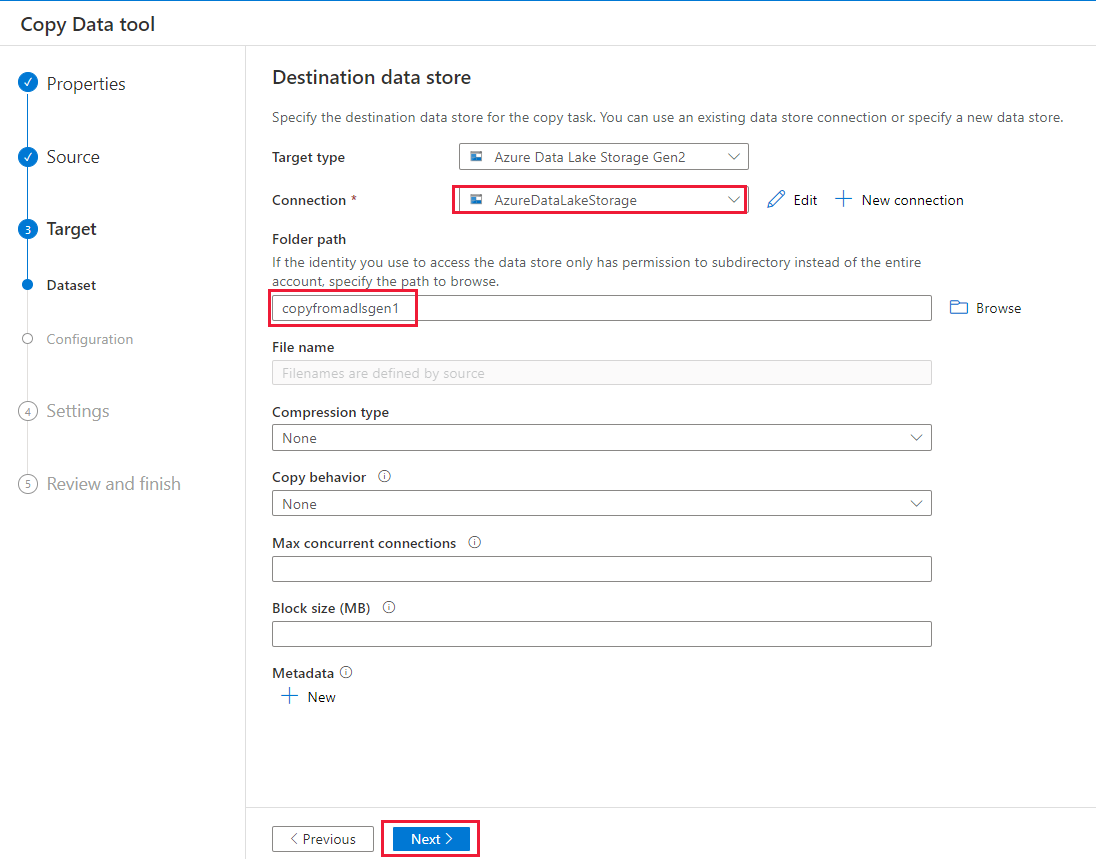
Dans la page Paramètres, spécifiez CopyFromADLSGen1ToGen2 pour le champ Nom de tâche, puis sélectionnez Suivant pour utiliser les paramètres par défaut.
Dans la page Résumé, vérifiez les paramètres, puis cliquez sur Suivant.
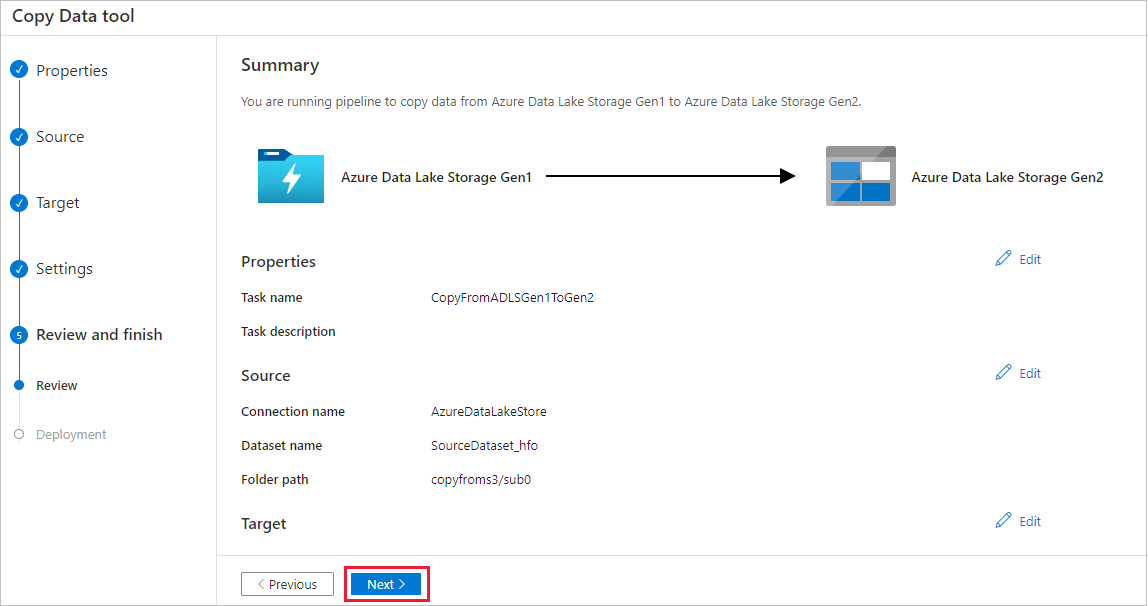
Dans la page Déploiement, sélectionnez Surveiller pour superviser le pipeline.
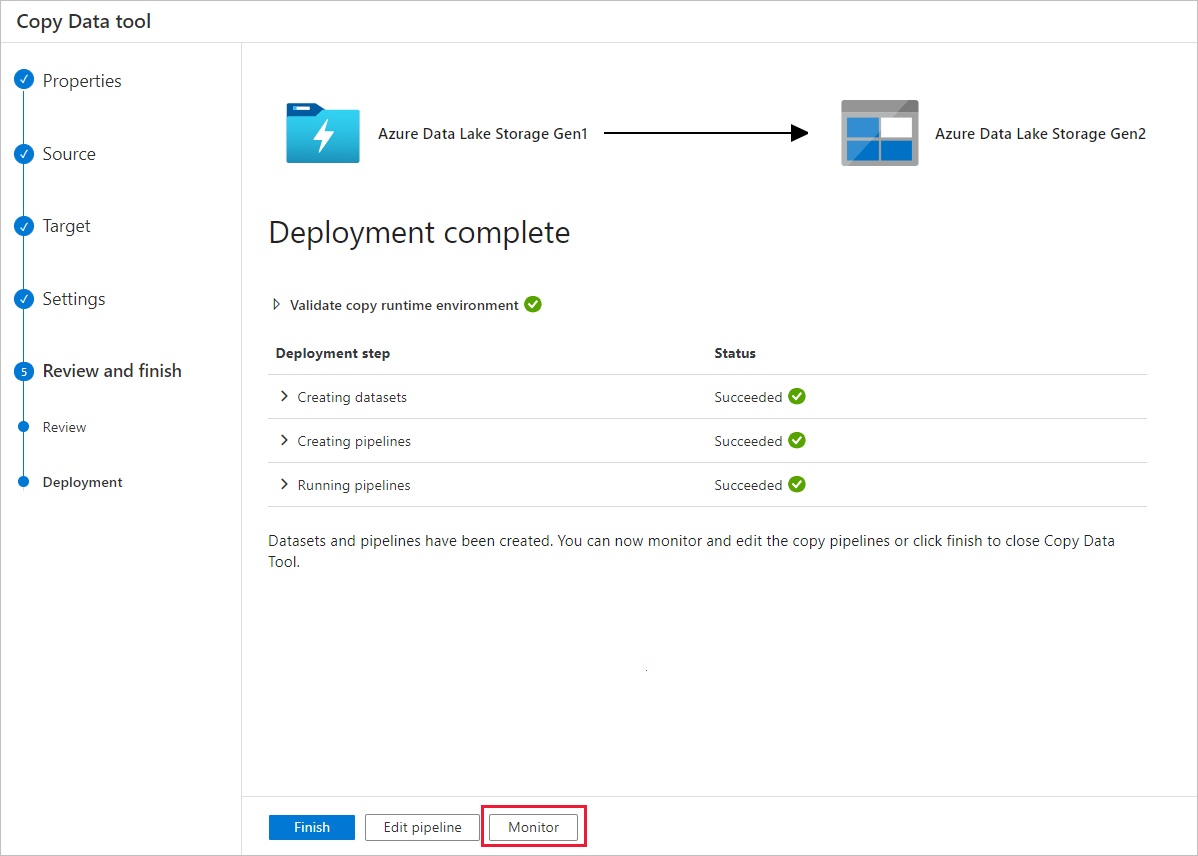
Notez que l’onglet Surveiller sur la gauche est sélectionné automatiquement. La colonne Nom du pipeline comprend les liens permettant d’afficher les détails de l’exécution de l’activité et de réexécuter le pipeline.
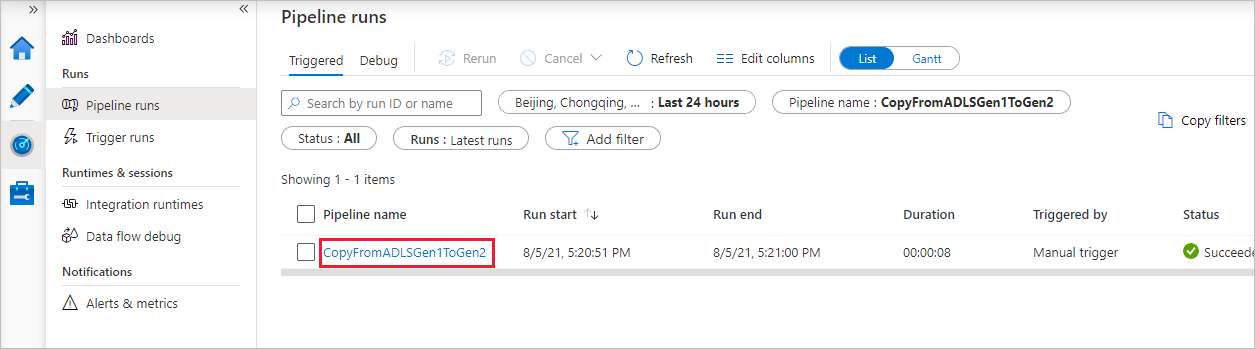
Pour afficher les exécutions d’activités associées à l’exécution du pipeline, sélectionnez le lien dans la colonne Nom du pipeline. Il n’y a qu’une seule activité (activité de copie) dans le pipeline ; vous ne voyez donc qu’une seule entrée. Pour revenir à l’affichage des exécutions de pipeline, sélectionnez le lien Toutes les exécutions de pipeline dans le menu de navigation en haut. Sélectionnez Actualiser pour actualiser la liste.
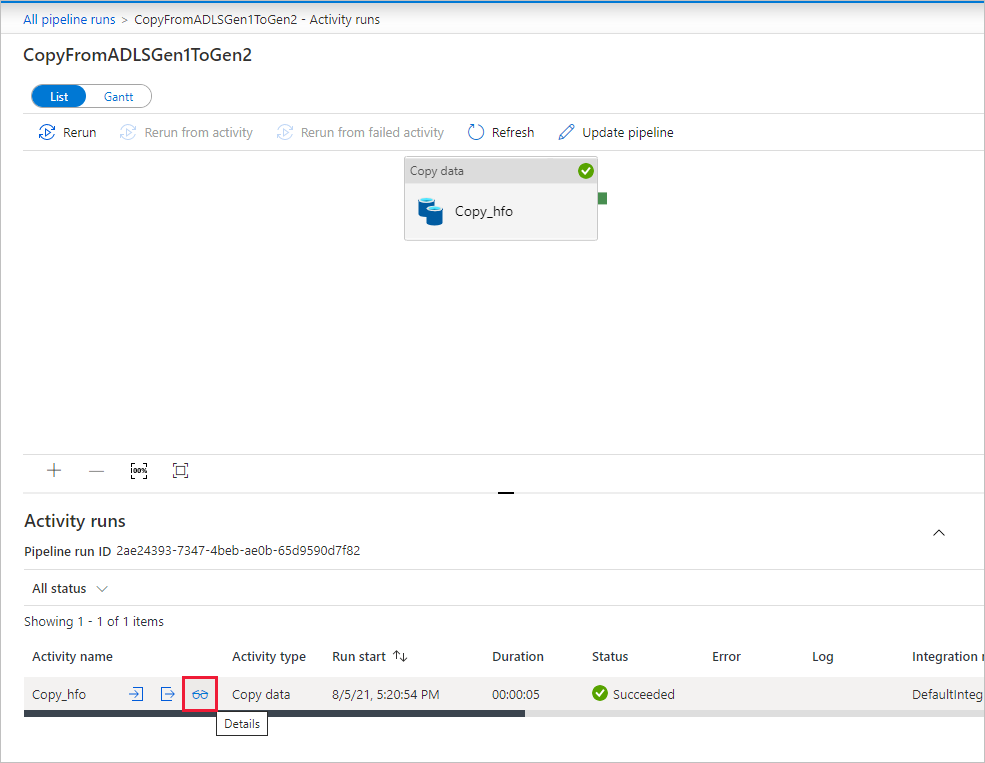
Pour surveiller les détails d’exécution de chaque activité de copie, sélectionnez le lien Détails (image de lunettes) sous la colonne Nom de l’activité dans la vue de surveillance des activités. Vous pouvez suivre les informations détaillées comme le volume de données copiées à partir de la source dans le récepteur, le débit des données, les étapes d’exécution avec une durée correspondante et les configurations utilisées.
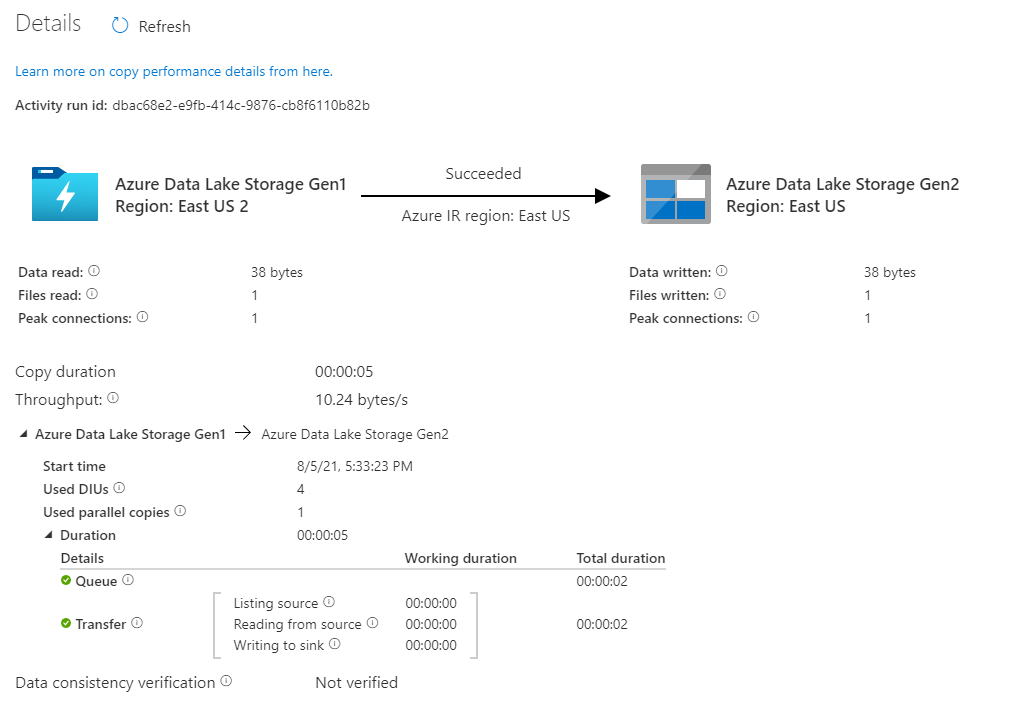
Vérifiez que les données ont bien été copiées dans votre compte Azure Data Lake Storage Gen2.
Meilleures pratiques
Pour évaluer la mise à niveau d’Azure Data Lake Storage Gen1 vers Azure Data Lake Storage Gen2 en général, consultez Mettre à niveau vos solutions d’analytique de Big Data d’Azure Data Lake Storage Gen1 vers Azure Data Lake Storage Gen2. Les sections suivantes présentent les bonnes pratiques d’utilisation du service Data Factory pour effectuer une mise à niveau des données de Data Lake Storage Gen1 vers Data Lake Storage Gen2.
Migration initiale des données d’instantané
Performances
ADF offre une architecture serverless qui autorise le parallélisme à différents niveaux, ce qui permet aux développeurs de créer des pipelines pour utiliser pleinement la bande passante de votre réseau, ainsi que les IOPS et la bande passante de stockage pour maximiser le débit de déplacement de données pour votre environnement.
Les clients ont réussi à migrer des pétaoctets de données constitués de centaines de millions de fichiers de Data Lake Storage Gen1 vers Gen2, avec un débit soutenu de 2 Gbits/s et plus.
Vous pouvez obtenir des vitesses de déplacement des données supérieures en appliquant différents niveaux de parallélisme :
- Une seule activité de copie peut tirer parti des ressources de calcul évolutives. Lorsque vous utilisez Azure Integration Runtime, vous pouvez spécifier jusqu’à 256 unités d’intégration de données (DIU) pour chaque activité de copie serverless. Lorsque vous utilisez un Integration Runtime auto-hébergé, vous pouvez effectuer un scale-up de la machine ou un scale-out vers plusieurs machines (jusqu’à 4 nœuds), et une seule activité de copie partitionne son jeu de fichiers sur tous les nœuds.
- Une activité de copie unique lit et écrit dans le magasin de données à l’aide de plusieurs conversations.
- Le flux de contrôle ADF peut démarrer plusieurs activités de copie en parallèle, par exemple Pour chaque boucle.
Partitions de données
Si vos données dans Data Lake Storage Gen1 ont une taille totale inférieure à 10 To et sont réparties dans moins d’un million de fichiers, vous pouvez copier toutes les données en exécutant une seule activité de copie. Si vous avez une plus grande quantité de données à copier, ou si vous souhaitez pouvoir gérer la migration des données par lots et traiter chaque lot dans un laps de temps défini, il est préférable de partitionner les données. Autre avantage, le partitionnement réduit le risque de survenue de problèmes inattendus.
Pour partitionner les fichiers, vous pouvez utiliser name range- listAfter/listBefore dans la propriété de l’activité de copie. Chaque activité de copie peut être configurée pour copier une partition à la fois, afin que plusieurs activités de copie puissent copier des données à partir d’un seul compte Data Lake Storage Gen1 en même temps.
Limitation du débit
Il est recommandé de procéder à un examen des performances avec un exemple de jeu de données représentatif, afin de pouvoir déterminer la taille de partition appropriée.
Commencez avec une seule partition et une seule activité de copie avec le paramètre DIU par défaut. Il est toujours recommandé de définir la Copie en parallèle comme vide (valeur par défaut) . Si le débit de copie ne vous convient pas, identifiez et résolvez les goulots d’étranglement de performances en suivant les étapes de réglage des performances.
Augmentez progressivement le paramètre DIU jusqu'à atteindre la limite de bande passante de votre réseau ou la limite IOPS/bande passante des magasins de données, ou vous avez atteint le nombre maximal de 256 DIU autorisé pour une activité de copie unique.
Si vous avez maximisé les performances d’une activité de copie unique, mais que n’avez pas encore atteint les limites supérieures de débit de votre environnement, vous pouvez exécuter plusieurs activités de copie en parallèle.
Si vous constatez un nombre conséquent d’erreurs de limitation à partir de l’analyse de l’activité de copie, cela signifie que vous avez atteint la limite de capacité de votre compte de stockage. ADF effectue automatiquement une nouvelle tentative pour surmonter chaque erreur de limitation afin de s’assurer qu’aucune donnée n’est perdue, mais un nombre excessif de tentatives peut également dégrader le débit de copie. Dans ce cas, il est recommandé de réduire le nombre d’activités de copie exécutées en même temps afin d’éviter des quantités significatives d’erreurs de limitation. Si vous avez utilisé une seule activité de copie pour copier des données, vous êtes encouragé à réduire le nombre d’unités d’intégration de données (DIU).
Migration des données Delta
Vous pouvez utiliser plusieurs approches pour charger uniquement les fichiers nouveaux ou mis à jour à partir de Data Lake Storage Gen1 :
- Chargez les fichiers nouveaux ou mis à jour en fonction du nom de fichier ou de dossier partitionné chronologiquement. Par exemple : /2019/05/13/*.
- Chargez les fichiers nouveaux ou mis à jour en fonction de la date de dernière modification. Si vous copiez de grandes quantités de fichiers, créez d’abord des partitions afin d’éviter que le débit de copie faible ne résulte de l’analyse de l’activité de copie unique sur l’ensemble de votre compte Data Lake Storage Gen1 pour identifier les nouveaux fichiers.
- Identifiez les fichiers nouveaux ou mis à jour par une solution ou un outil tiers. Ensuite, passez le nom de fichier ou de dossier au pipeline Data Factory via le paramètre ou une table ou un fichier.
La fréquence appropriée pour effectuer le chargement incrémentiel dépend du nombre total de fichiers dans Azure Data Lake Storage Gen1 et du volume de fichiers nouveaux ou mis à jour devant être chargés à chaque fois.
Sécurité du réseau
Par défaut, ADF transfère les données d’Azure Data Lake Storage Gen1 vers Gen2 à l’aide d’une connexion chiffrée sur le protocole HTTPS. Le protocole HTTPS assure le chiffrement des données en transit et empêche les écoutes clandestines et les attaques de l’intercepteur.
Sinon, si vous ne souhaitez pas que les données soient transférées via l’internet public, vous pouvez obtenir une sécurité accrue en les transférant via un réseau privé.
Conserver les listes de contrôle d’accès (ACL)
Si vous souhaitez répliquer les listes de contrôle d’accès ainsi que les fichiers de données quand vous migrez de Data Lake Storage Gen1 vers Data Lake Storage Gen2, consultez Conserver les listes de contrôle d’accès à partir de Data Lake Storage Gen1.
Résilience
Dans une exécution d’activité de copie unique, ADF intègre un mécanisme de nouvelle tentative qui permet de gérer un certain niveau d’échecs temporaires dans les magasins de données ou dans le réseau sous-jacent. Si vous migrez plus de 10 To de données, nous vous recommandons de les partitionner afin de réduire le risque de problèmes inattendus.
Vous pouvez également activer la tolérance de panne dans l’activité de copie afin d’ignorer les erreurs prédéfinies. Vous pouvez également activer la vérification de la cohérence des données dans l’activité de copie pour effectuer une vérification supplémentaire afin de garantir non seulement que les données sont copiées entre le magasin source et le magasin de destination, mais aussi que leur cohérence dans les deux magasins est vérifiée.
Autorisations
Dans Data Factory, le connecteur Data Lake Storage Gen1 prend en charge le principal de service et l’identité managée pour les authentifications de ressources Azure. Le connecteur Data Lake Storage Gen2 prend en charge la clé de compte, le principal de service et l’identité managée pour les authentifications de ressources Azure. Pour permettre à Data Factory de parcourir et de copier l’ensemble des fichiers ou des listes de contrôle d’accès dont vous avez besoin, accordez des autorisations suffisamment élevées au compte utilisé pour parcourir, lire ou écrire tous les fichiers et définir des listes de contrôle d’accès, le cas échéant. Vous devez accorder au compte un rôle de super-utilisateur ou de propriétaire pendant la période de migration et supprimer les autorisations élevées une fois la migration terminée.