Copiez de manière incrémentielle des données de Azure SQL Database vers le stockage Blob à l’aide du suivi des modifications dans le Portail Azure
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Dans une solution d’intégration de données, le chargement incrémentiel de données après des chargements de données initiaux est un scénario largement utilisé. Les données modifiées au cours d’une période dans votre magasin de données source peuvent être facilement découpées (par exemple,LastModifyTime, CreationTime). Mais dans certains cas, il n’existe pas de manière explicite pour identifier les données delta depuis le dernier traitement des données. Vous pouvez utiliser la technologie de suivi des modifications prise en charge par les magasins de données tels qu’Azure SQL Database et SQL Server pour identifier les données delta.
Ce tutoriel explique comment utiliser Azure Data Factory avec le suivi des modifications afin de charger de façon incrémentielle des données delta d’Azure SQL Database dans Stockage Blob Azure. Pour plus d’informations sur le suivi des modifications, consultez Suivi des modifications dans SQL Server.
Dans ce tutoriel, vous allez effectuer les étapes suivantes :
- Préparez le magasin de données sources.
- Créer une fabrique de données.
- créez des services liés.
- Créez des jeux de données source, récepteur et de suivi des modifications.
- Créez, exécutez et surveillez le pipeline de copie complète.
- Ajoutez ou mettez à jour des données dans la table source.
- Créez, exécutez et surveillez le pipeline de copie incrémentielle.
Solution générale
Dans ce didacticiel, vous créez deux pipelines qui effectuent les opérations suivantes.
Notes
Ce tutoriel utilise Azure SQL Database comme magasin de données source. Vous pouvez également utiliser SQL Server.
Chargement initial de données historiques : vous créez un pipeline avec une activité de copie qui copie l’ensemble des données du magasin de données source (Azure SQL Database) dans le magasin de données de destination (Stockage Blob Azure) :
- Activez la technologie de suivi des modifications dans la base de données source dans Azure SQL Database.
- Obtenez la valeur initiale de
SYS_CHANGE_VERSIONdans la base de données comme base de référence pour la capture des données modifiées. - Chargez les données complètes de la base de données source vers un compte de stockage Blob Azure.

Chargement incrémentiel des données delta selon une planification : vous créez un pipeline avec les activités suivantes et vous l’exécutez régulièrement :
Créez deux activités de recherche pour obtenir les anciennes et nouvelles valeurs
SYS_CHANGE_VERSIONde Azure SQL Database.Créez une activité de copie pour copier les données insérées, mises à jour ou supprimées (données delta) entre les deux valeurs
SYS_CHANGE_VERSIONd’Azure SQL Database dans Stockage Blob Azure.Vous chargez les données delta en associant les clés primaires des lignes modifiées (entre deux valeurs
SYS_CHANGE_VERSION) des donnéessys.change_tracking_tablesdans la table source, puis déplacez les données delta vers la destination.Créez une activité de procédure stockée pour mettre à jour la valeur de
SYS_CHANGE_VERSIONpour la prochaine exécution du pipeline.

Prérequis
- Abonnement Azure. Si vous n’en avez pas, créez un compte gratuit avant de commencer.
- Azure SQL Database. Vous utilisez une base de données dans Azure SQL Database comme magasin de données source. Si vous n’en avez pas, consultez Créer une base de données dans Azure SQL Database pour connaître la procédure à suivre pour en créer une.
- Compte Azure Storage. Vous utilisez le stockage Blob comme magasin de données récepteur. Si vous ne possédez pas de compte de stockage Azure, procédez de la manière décrite dans l’article Créer un compte de stockage pour en créer un. Créez un conteneur sous le nom adftutorial.
Notes
Nous vous recommandons d’utiliser le module Azure Az PowerShell pour interagir avec Azure. Pour bien démarrer, consultez Installer Azure PowerShell. Pour savoir comment migrer vers le module Az PowerShell, consultez Migrer Azure PowerShell depuis AzureRM vers Az.
Créer une table de source de données dans Azure SQL Database
Ouvrez SQL Server Management Studio, puis connectez-vous à SQL Database.
Dans l’Explorateur de serveurs, cliquez avec le bouton droit sur votre base de données puis sélectionnez Nouvelle requête.
Exécutez la commande SQL suivante sur votre base de données pour créer une table sous le nom
data_source_tablecomme magasin de données source :create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);Activez le suivi de modifications sur votre base de données et la table source (
data_source_table) en exécutant la requête SQL suivante.Notes
- Remplacez
<your database name>par le nom de la base de données dans Azure SQL Database qui adata_source_table. - Dans cet exemple, les données modifiées sont conservées pendant deux jours. Si vous chargez les données modifiées tous les trois jours ou plus, certaines données modifiées ne sont pas incluses. Vous devez soit modifier la valeur de
CHANGE_RETENTIONpar un plus grand nombre, soit vous assurer que votre période de chargement des données modifiées est dans les deux jours. Pour plus d’informations, consultez Activer le suivi des modifications pour une base de données.
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)- Remplacez
Créez une nouvelle table et stockez
ChangeTracking_versionavec une valeur par défaut en exécutant la requête suivante :create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)Notes
Si les données ne sont pas modifiées une fois que vous avez activé le suivi des modifications pour SQL Database, la valeur de la version de suivi des modifications est
0.Exécutez la requête suivante pour créer une procédure stockée dans votre base de données. Le pipeline appelle cette procédure stockée pour mettre à jour la version de suivi des modifications dans la table que vous avez créée à l’étape précédente.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Créer une fabrique de données
Ouvrez le navigateur web Microsoft Edge ou Google Chrome. Actuellement, seuls les navigateurs prennent en charge l’interface utilisateur (IU) Data Factory.
Dans le Portail Azure, dans le menu de gauche, sélectionnez Créer une ressource.
Sélectionnez Intégration>Data Factory.
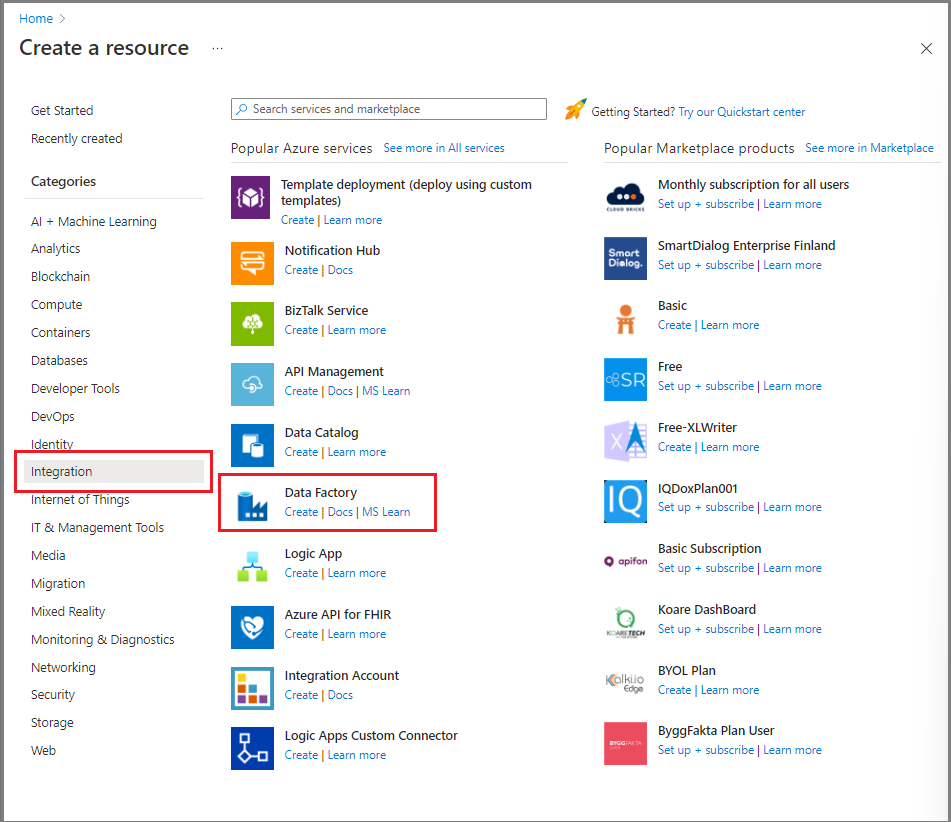
Sur la page Nouvelle fabrique de données, entrez ADFTutorialDataFactory comme nom.
Le nom de la fabrique de données doit être un nom global unique. Si vous obtenez une erreur indiquant que le nom que vous avez choisi n’est pas disponible, remplacez le nom (par exemple, votrenomADFTutorielDataFactory) et réessayez de créer la fabrique de données. Pour plus d’informations, consultez Règle de nom Azure Data Factory.
Sélectionnez l’abonnement Azure dans lequel vous voulez créer la fabrique de données.
Pour Groupe de ressources, réalisez l’une des opérations suivantes :
- Sélectionnez Utiliser l’existant, puis sélectionnez un groupe de ressources existant dans la liste déroulante.
- Sélectionnez Créer, puis entrez le nom d’un groupe de ressources.
Pour plus d’informations sur les groupes de ressources, consultez Utilisation des groupes de ressources pour gérer vos ressources Azure.
Pour Version, sélectionnez V2.
Pour Région, sélectionnez la région de la fabrique de données.
La liste déroulante affiche uniquement les emplacements pris en charge. Les magasins de données (comme Stockage Azure et Azure SQL Database) et les services de calcul (comme Azure HDInsight) qu’une fabrique de données utilise peuvent se trouver dans d’autres régions.
Sélectionnez Suivant : Configuration Git. Configurez le référentiel en suivant les instructions de la Méthode de configuration 4 : Pendant la création de la fabrique, ou cochez la case Configurer Git plus tard.
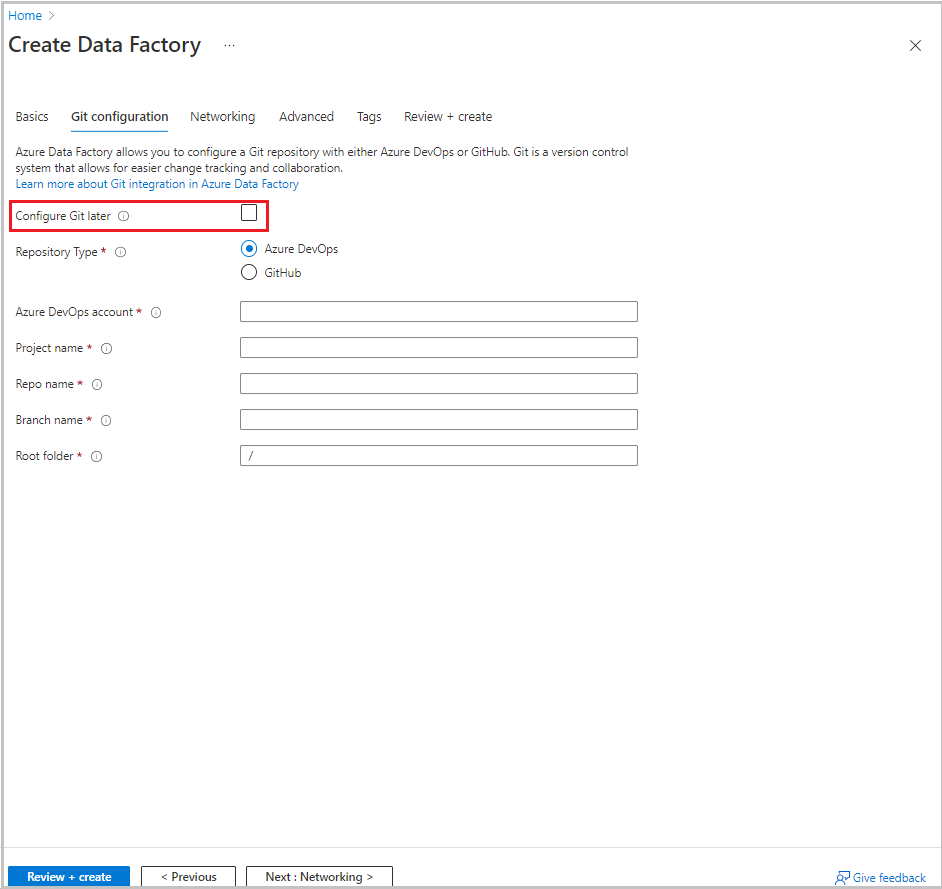
Sélectionnez Revoir + créer.
Sélectionnez Create (Créer).
Sur le tableau de bord, la vignette Déploiement de Data Factory affiche l’état.

Une fois la création terminée, la page Data Factory s’affiche. Sélectionnez la vignette Launch Studio pour ouvrir l’interface utilisateur Azure Data Factory dans un onglet distinct.
Créez des services liés
Vous allez créer des services liés dans une fabrique de données pour lier vos magasins de données et vos services de calcul à la fabrique de données. Dans cette section, vous allez créer des services liés à votre compte de stockage Azure et à votre base de données dans Azure SQL Database.
Créer un service lié Stockage Azure
Pour lier votre compte de stockage à la fabrique de données :
- Dans l’interface utilisateur de Data Factory, sous l’onglet Gérer , sous Connexions, sélectionnez Services liés. Sélectionnez ensuite + Nouveau ou le bouton Créer un service lié .
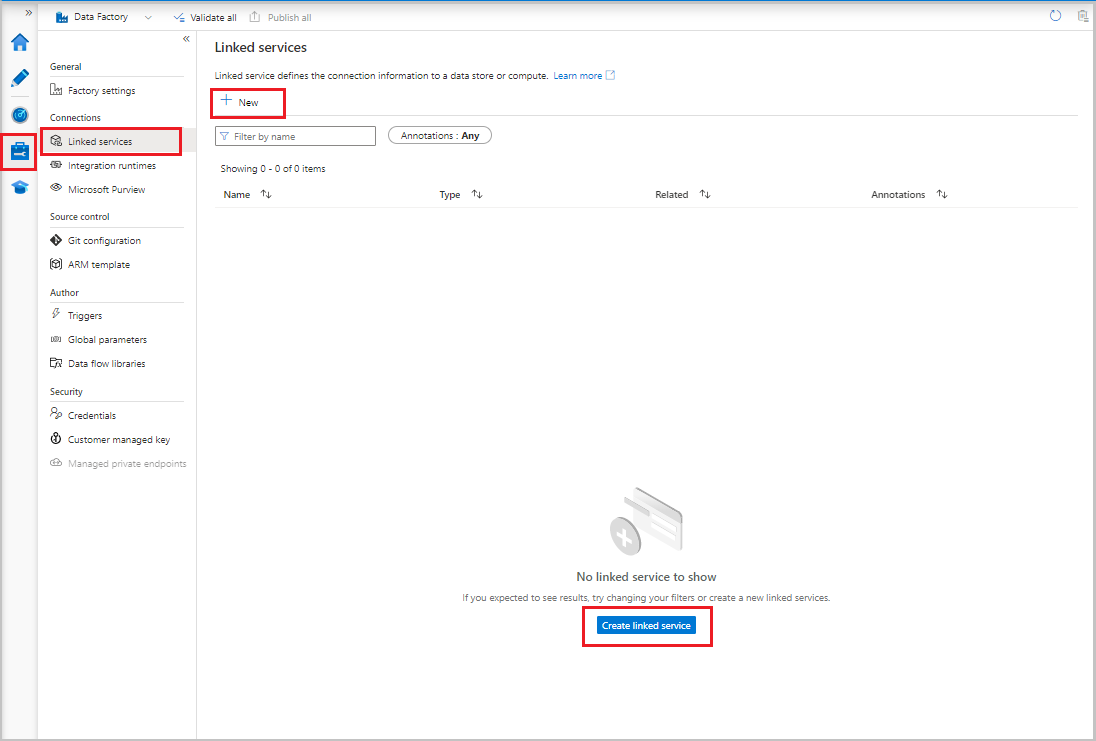
- Dans la page Nouveau service lié, sélectionnez Stockage Blob Azure, puis sélectionnez Continuer.
- Entrez les informations suivantes :
- Pour le Nom, entrez AzureStorageLinkedService.
- Pour Se connecter via le runtime d’intégration, sélectionnez le runtime d’intégration.
- Pour Type d’authentification, sélectionnez une méthode d’authentification.
- Pour Nom du compte de stockage, sélectionnez votre compte de stockage Azure.
- Sélectionnez Create (Créer).
Créer un service lié Azure SQL Database
Pour lier votre base de données à la fabrique de données :
Dans l’interface utilisateur de Data Factory, sous l’onglet Gérer , sous Connexions, sélectionnez Services liés. Sélectionnez + Nouveau.
Dans la fenêtre Nouveau service lié, sélectionnez Azure SQL Database, puis sélectionnez Continuer.
Entrez les informations suivantes :
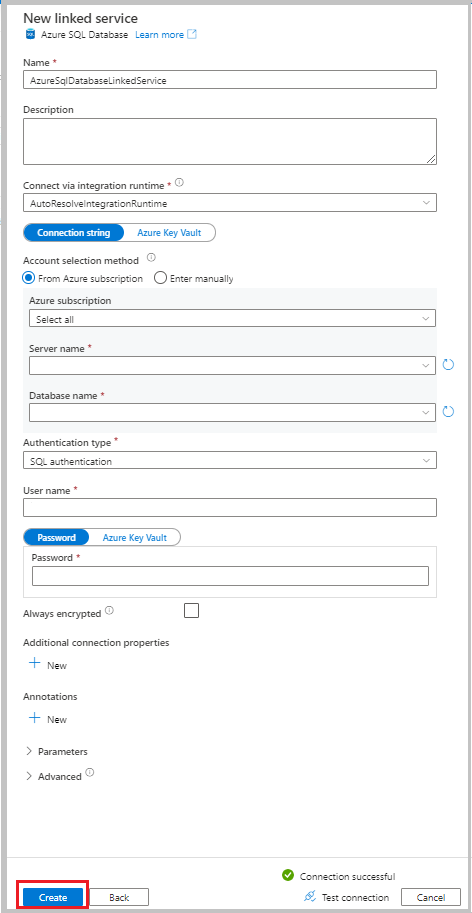
- Pour le Nom, entrez AzureSqlDatabaseLinkedService.
- Pour Nom du serveur, sélectionnez votre serveur.
- Pour Nom de la base de données, sélectionnez votre base de données.
- Pour Type d’authentification, sélectionnez une méthode d’authentification. Ce tutoriel utilise l’authentification SQL à des fins de démonstration.
- Pour Nom d’utilisateur, entrez le nom de l’utilisateur.
- Pour Mot de passe, entrez un mot de passe pour l’utilisateur. Vous pouvez également fournir les informations relatives auService lié Azure Key Vault - AKV, Nom du secret et à Version du secret.
Sélectionnez Tester la connexion pour tester la connexion.
Sélectionnez Créer pour créer le service lié.
Créez les jeux de données
Dans cette section, vous créez des jeux de données pour représenter la source de données et la destination des données, et l’emplacement des valeurs SYS_CHANGE_VERSION.
Créer un jeu de données pour représenter les données sources
Dans l’interface utilisateur de Data Factory, sous l’onglet Auteur , sélectionnez le signe plus (+). Sélectionnez ensuite Jeu de données ou sélectionnez les points de suspension pour les actions de jeu de données.
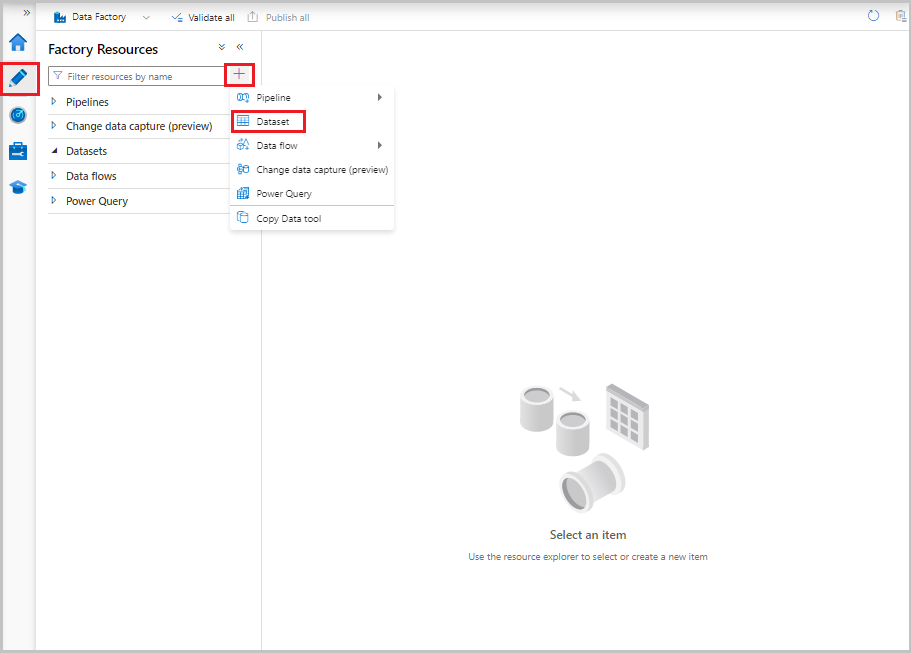
Sélectionnez Azure SQL Database, puis Continuer.
Dans la fenêtre Définir les propriétés, procédez comme suit :
- Pour Nom, entrez SourceDataset.
- Pour Service lié, sélectionnez AzureSqlDatabaseLinkedService.
- Pour Nom de la table, sélectionnez dbo.data_source_table.
- Pour Importer le schéma, sélectionnez l’option À partir de la connexion/du magasin .
- Sélectionnez OK.

Créez un jeu de données pour représenter les données copiées dans le magasin de données récepteur
Dans la procédure suivante, vous créez un jeu de données pour représenter les données copiées à partir du magasin de données source. Vous avez créé le conteneur adftutorial dans le stockage Blob Azure dans le cadre des conditions préalables. Créez le conteneur s’il n’existe pas ou attribuez-lui le nom d’un conteneur existant. Dans ce didacticiel, le nom de fichier de sortie est généré dynamiquement à l’aide de l’expression : @CONCAT('Incremental-', pipeline().RunId, '.txt').
Dans l’interface utilisateur de Data Factory, sous l’onglet Auteur , sélectionnez +. Sélectionnez ensuite Jeu de données ou sélectionnez les points de suspension pour les actions de jeu de données.
Sélectionnez Stockage Blob Azure, puis Continuer.
Sélectionnez le format du type de données DelimitedText et puis sélectionnez Continuer.
Dans la fenêtre Définir les propriétés, procédez comme suit :
- Pour Nom, entrez SinkDataset.
- Pour Service lié, sélectionnez AzureBlobStorageLinkedService.
- Pour Chemin d’accès au fichier, entrez adftutorial/incchgtracking.
- Sélectionnez OK.
Une fois le jeu de données affiché dans l’arborescence, accédez à l’onglet Connexion et sélectionnez la zone de texte Nom de fichier. Lorsque l’option Ajouter du contenu dynamique s’affiche, sélectionnez-la.
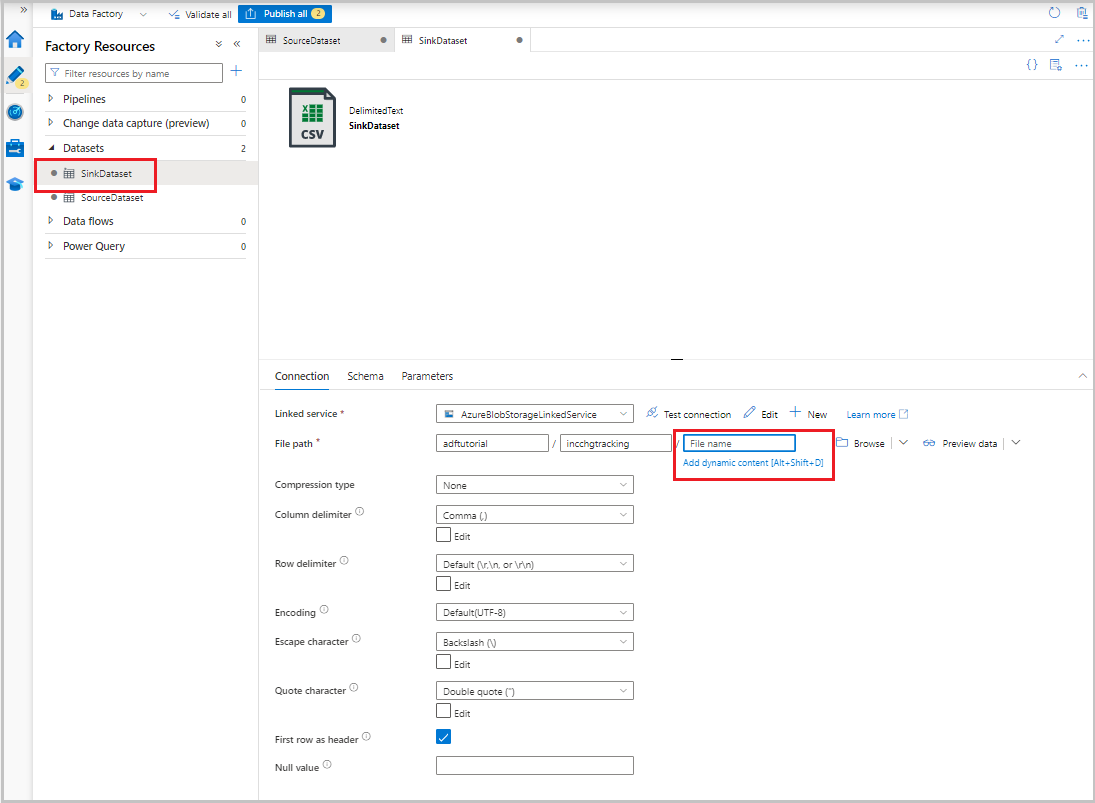
La fenêtre Générateur d’expressions de pipeline s’affiche. Collez
@concat('Incremental-',pipeline().RunId,'.csv')dans la zone de texte.Sélectionnez OK.
Créer un jeu de données pour représenter les données de suivi des modifications
Dans la procédure suivante, vous créez un jeu de données pour stocker la version de suivi des modifications. Vous avez créé la table table_store_ChangeTracking_version dans le cadre des conditions préalables.
- Dans l’interface utilisateur de Data Factory, sous l’onglet Auteur , sélectionnez +, puis sélectionnez Jeu de données.
- Sélectionnez Azure SQL Database, puis Continuer.
- Dans la fenêtre Définir les propriétés, procédez comme suit :
- Pour Nom, entrez ChangeTrackingDataset.
- Pour Service lié, sélectionnez AzureSqlDatabaseLinkedService.
- Pour Nom de la table, sélectionnez dbo.table_store_ChangeTracking_version.
- Pour Importer le schéma, sélectionnez l’option À partir de la connexion/du magasin .
- Sélectionnez OK.
Créer un pipeline pour la copie complète
Dans la procédure suivante, vous créez un pipeline avec une activité de copie qui copie l’ensemble des données du magasin de données source (Azure SQL Database) dans le magasin de données de destination (Stockage Blob Azure) :
Dans l’interface utilisateur de Data Factory, sous l’onglet Auteur, sélectionnez +, puis sélectionnez Pipeline>Pipeline.
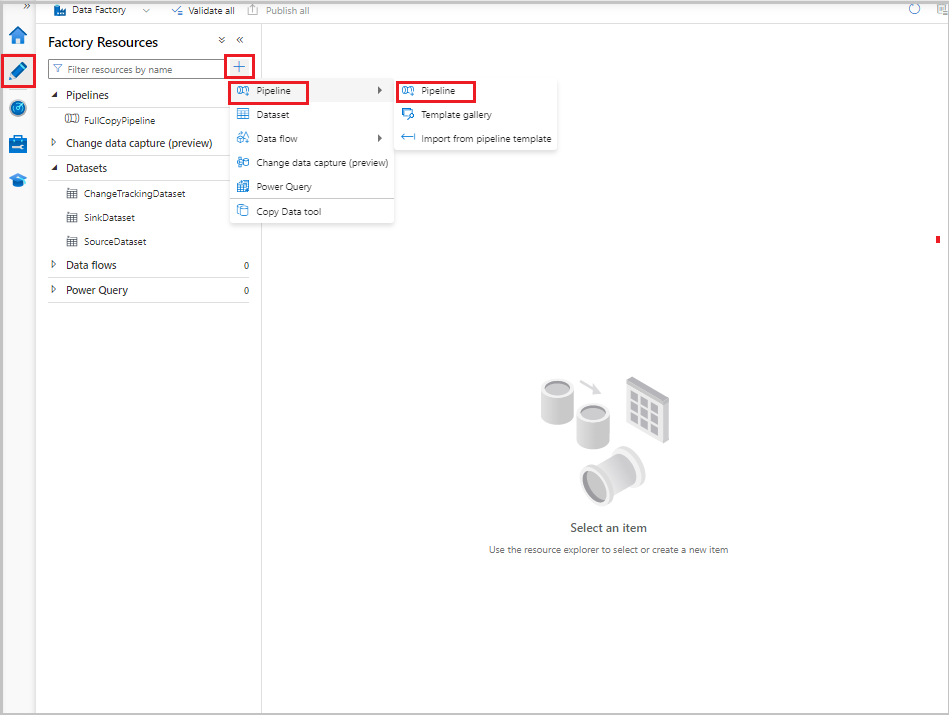
Un nouvel onglet s’affiche pour configurer le pipeline. Le pipeline apparaît également dans l’arborescence. Dans la fenêtre Propriétés, renommez le pipeline en FullCopyPipeline.
Dans la boîte à outils Activités, développez l’option Déplacer et transformer. Exécutez l’une des étapes suivantes :
- Faites glisser l’activité de copie vers l’aire du concepteur de pipeline.
- Dans la barre de recherche sous Activités, recherchez l’activité de copie de données, puis définissez le nom sur FullCopyActivity.
Basculez vers l’onglet Source. Pour Jeu de données source, sélectionnez SourceDataset.
Basculez vers l’onglet Récepteur. Pour Jeu de données récepteur, sélectionnez SinkDataset.
Pour valider la définition du pipeline, sélectionnezValider dans la barre d’outils. Vérifiez qu’il n’y a aucune erreur de validation. Fermez la sortie de validation du pipeline.
Pour publier des entités (services liés, jeux de données et pipelines), sélectionnez Publier tout. Patientez jusqu’à voir le message Publication réussie.

Pour afficher les notifications, sélectionnez le bouton Afficher les notifications .
Exécuter le pipeline de copie complète
Dans l’interface utilisateur de Data Factory, dans la barre d’outils du pipeline, sélectionnez Ajouter un déclencheur, puis Sélectionnez Déclencher maintenant.
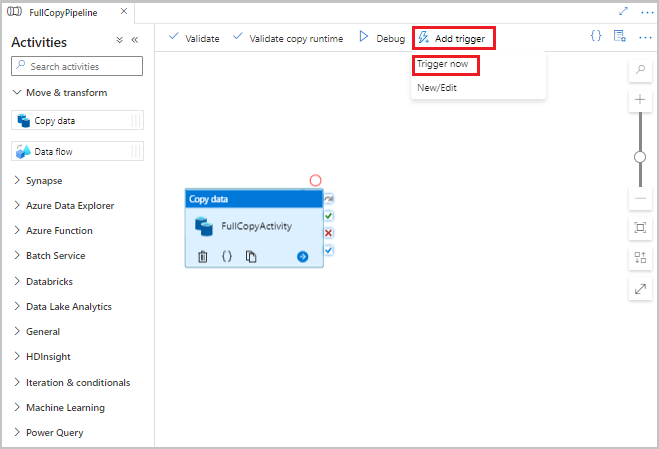
Dans la fenêtre Exécution de pipeline, sélectionnez OK.

Surveiller le pipeline de copie complète
Dans l’interface utilisateur de Data Factory, sélectionnez l’onglet Surveiller . L’exécution du pipeline et son état apparaissent dans la liste. Pour actualiser la liste, sélectionnez Actualiser. Pointez sur l’exécution du pipeline pour obtenir l’option Réexécuter ou Consommation .
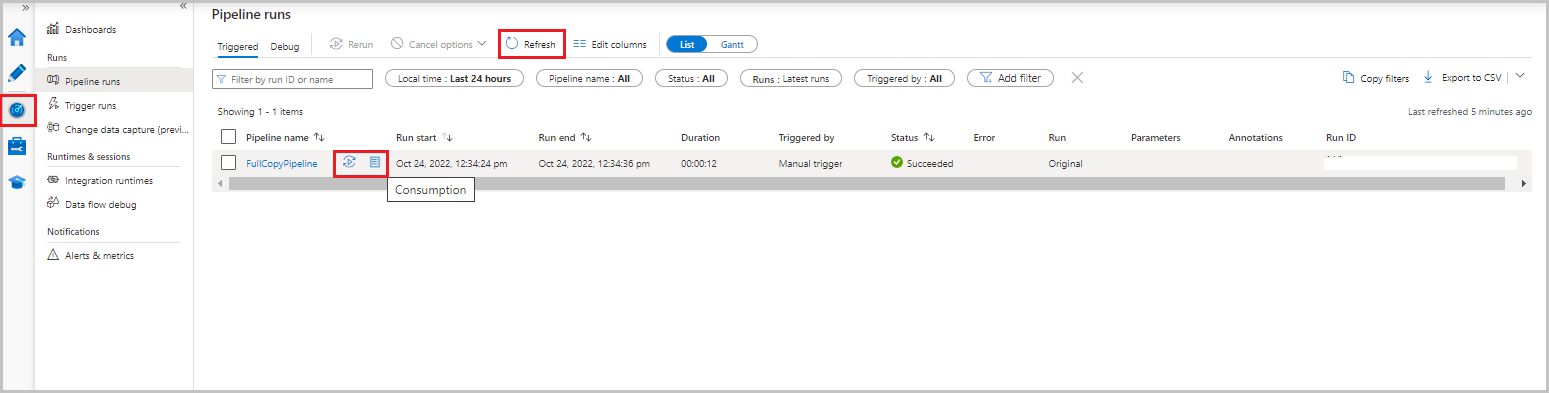
Pour afficher les exécutions d’activités associées à l’exécution de pipeline, sélectionnez le nom du pipeline dans la colonne Nom du pipeline. Il n’y a qu’une seule activité dans le pipeline, il n’y a donc qu’une seule entrée dans la liste. Pour revenir à la vue des exécutions du pipeline, sélectionnez le lien Toutes les exécutions de pipeline affiché en haut.
Passer en revue les résultats.
Le dossier incchgtracking du conteneur adftutorial inclut un fichier nommé incremental-<GUID>.csv.

Le fichier doit contenir les données de votre base de données :
PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
5,eeee,PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
Ajouter plus de données à la table source
Exécutez la requête suivante par rapport à votre base de données pour ajouter une ligne et mettre à jour une ligne :
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
Créer un pipeline pour la copie delta
Dans la procédure suivante, vous créez un pipeline avec activités, et vous l’exécutez régulièrement. Lorsque vous exécutez le pipeline :
- Les activités de recherche obtiennent les valeurs
SYS_CHANGE_VERSIONanciennes et nouvelles dans Azure SQL Database et les transmettent à l’activité de copie. - L’activité de copie copie les données insérées, mises à jour ou supprimées entre deux valeurs
SYS_CHANGE_VERSIONd’Azure SQL Database dans Stockage Blob Azure. - L’activité de procédure stockée met à jour la valeur
SYS_CHANGE_VERSIONpour la prochaine exécution du pipeline.
Dans l’interface utilisateur de Data Factory, basculez vers l’onglet Auteur . Sélectionnez +, puis sélectionnez Pipeline>Pipeline.
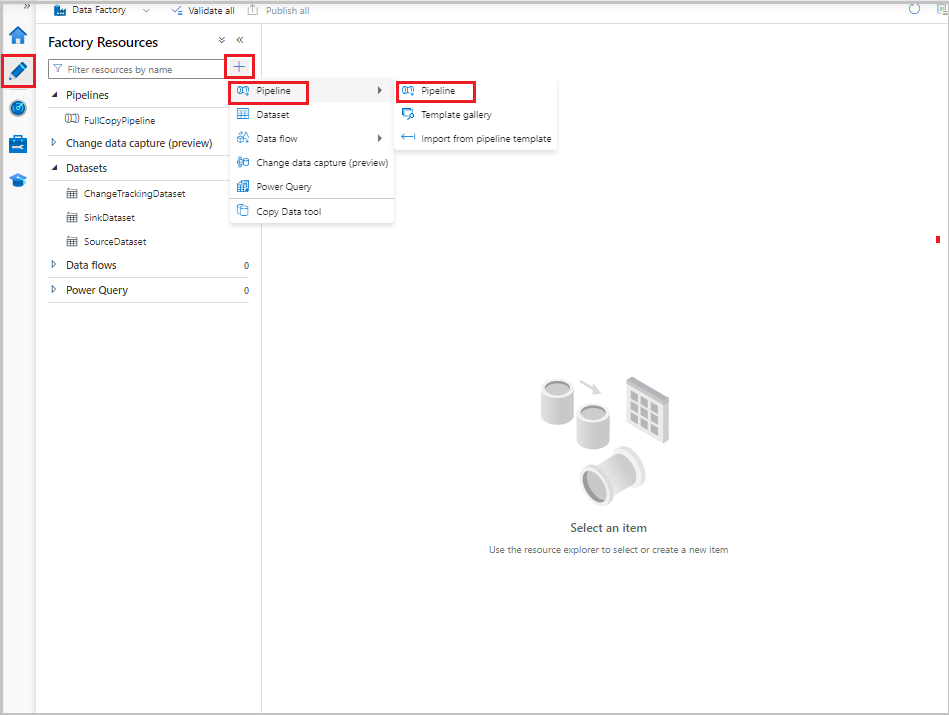
Un nouvel onglet s’affiche pour configurer le pipeline. Le pipeline apparaît également dans l’arborescence. Dans la fenêtre Propriétés, renommez le pipeline en IncrementalCopyPipeline.
Développez Général dans la boîte à outils Activités . Faites glisser l’activité Recherche vers la surface du concepteur de pipeline, ou cherchez dans la boîte Activités de recherche. Définissez le nom de l’activité sur LookupLastChangeTrackingVersionActivity. Cette activité permet d’obtenir la version de suivi des modifications utilisée dans la dernière opération de copie qui est stockée dans la table
table_store_ChangeTracking_version.Passez dans l’onglet Paramètres de la fenêtre Propriétés. Pour Jeu de données source, sélectionnez ChangeTrackingDataset.
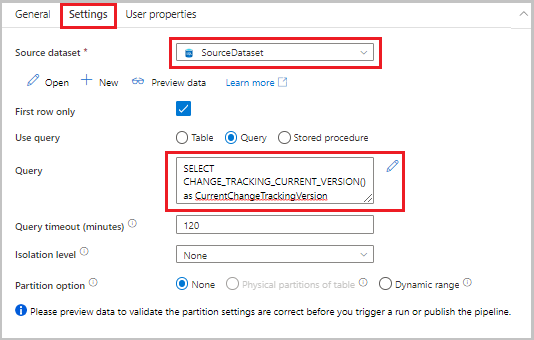
Faites glisser l’activité de recherche de la boîte à outils Activités vers la surface du concepteur de pipeline. Définissez le nom de l’activité sur LookupCurrentChangeTrackingVersionActivity. Cette activité permet d’obtenir la version de suivi des modifications en cours.
Passez dans l’onglet Paramètres de la fenêtre Propriétés, puis effectuez les actions suivantes :
Pour Jeu de données source, sélectionnez SourceDataset.
Pour Utiliser la requête, sélectionnez Requête.
Pour Requête, entrez la requête SQL suivante :
SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion
Dans la boîte à outils Activités, développez l’option Déplacer et transformer. Faites glisser l’activité de copie de données vers l’aire du concepteur de pipeline. Définissez le nom de l’activité sur IncrementalCopyActivity. Cette activité permet de copier les données entre la dernière version de suivi des modifications et la version de suivi des modifications en cours dans le magasin de données de destination.
Passez dans l’onglet Source de la fenêtre Propriétés, puis effectuez les actions suivantes :
Pour Jeu de données source, sélectionnez SourceDataset.
Pour Utiliser la requête, sélectionnez Requête.
Pour Requête, entrez la requête SQL suivante :
SELECT data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) AS CT ON data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}
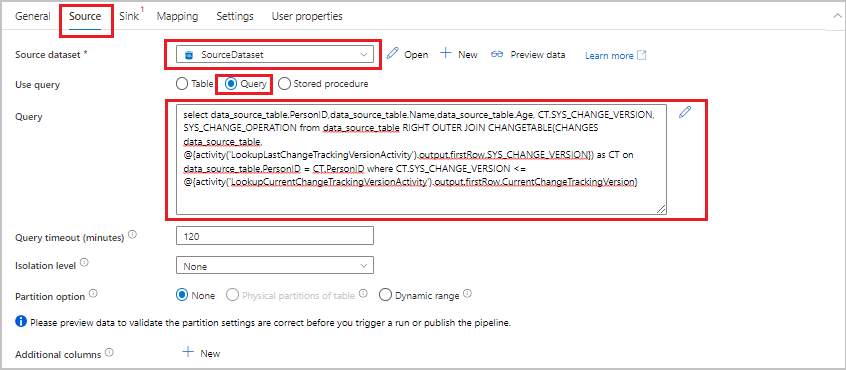
Basculez vers l’onglet Récepteur. Pour Jeu de données récepteur, sélectionnez SinkDataset.
Connectez les deux activités de recherche à l’activité de copie une par une. Faites glisser le bouton vert attaché à l’activité de recherche vers l’activité de copie.
Glissez-déposez l’activité procédure stockée de la boîte à outils Activités vers la surface du concepteur de pipeline. Définissez le nom de l’activité sur StoredProceduretoUpdateChangeTrackingActivity. Cette activité permet de mettre à jour la version de suivi des modifications dans la table
table_store_ChangeTracking_version.Basculez vers l’onglet Paramètres, puis procédez comme suit :
- Pour Service lié, sélectionnez AzureSqlDatabaseLinkedService.
- Pour Nom de la procédure stockée, sélectionnez Update_ChangeTracking_Version.
- Sélectionnez Importer.
- Dans la section Paramètres de procédure stockée, spécifiez les valeurs suivantes pour les paramètres :
Nom Type Valeur CurrentTrackingVersionInt64 @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}TableNameString @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}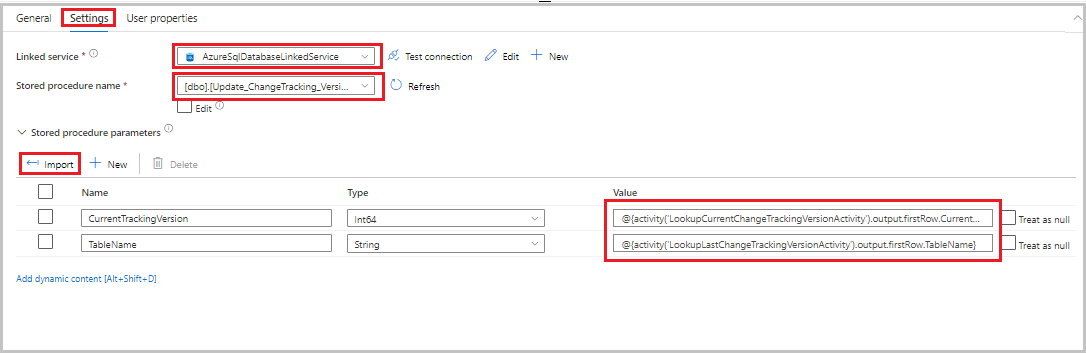
Connectez l’activité Copie à l’activité Procédure stockée. Faites glisser le bouton vert attaché à l’activité de copie vers l’activité de procédure stockée.
Sélectionnez Valider dans la barre d’outils. Vérifiez qu’il n’y a aucune erreur de validation. Fermer la fenêtre Rapport de validation de pipeline.
Publiez des entités (services liés, jeux de données et pipelines) pour le service Data Factory en sélectionnant le bouton Publier tout. Patientez jusqu’à ce que le message Publication réussie s’affiche.
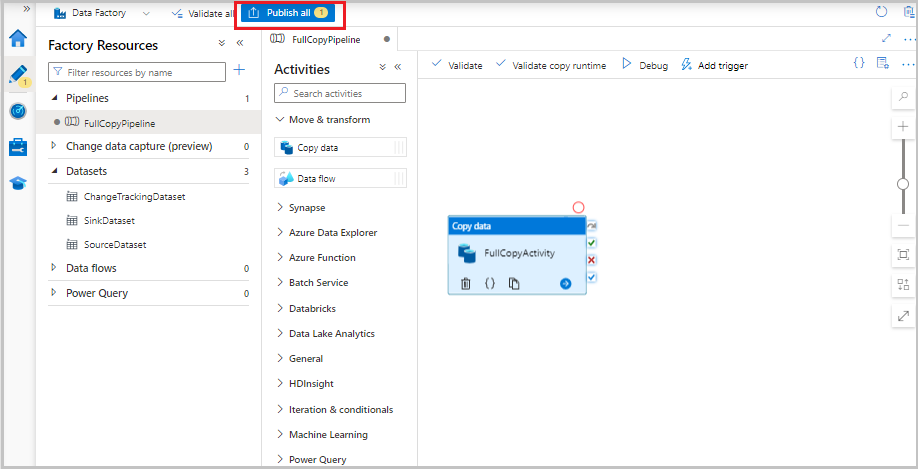
Exécuter le pipeline de copie incrémentielle
Sélectionnez Ajouter un déclencheur dans la barre d’outils du pipeline, puis Déclencher maintenant.
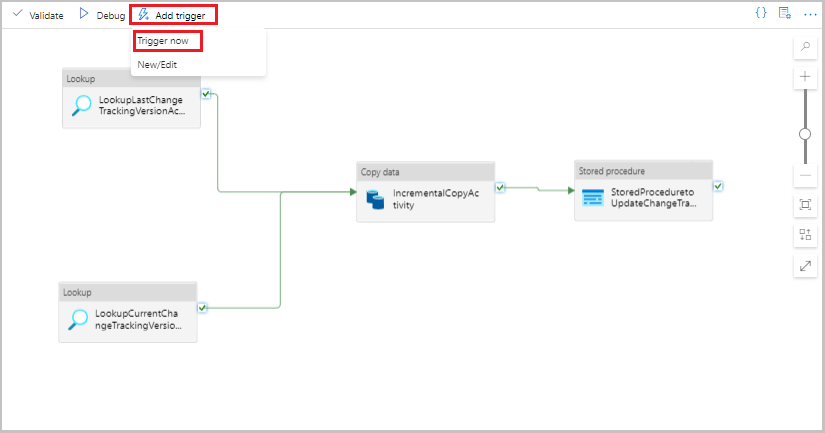
Dans la fenêtre Exécution de pipeline, sélectionnez OK.
Surveiller le pipeline de copie incrémentielle
Sélectionnez l’onglet Surveiller . L’exécution du pipeline et son état apparaissent dans la liste. Pour actualiser la liste, sélectionnez Actualiser.
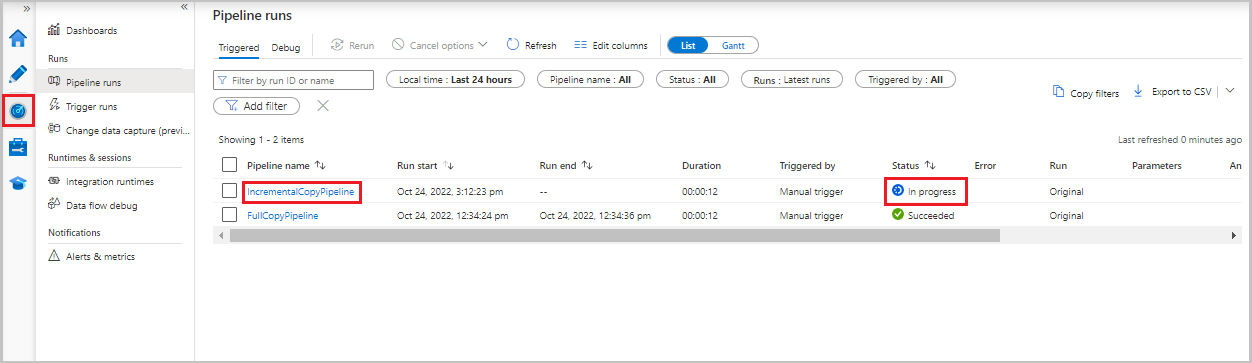
Pour afficher les exécutions d’activités associées à l’exécution de pipeline, sélectionnez le lien IncrementalCopyPipeline dans la colonne Nom du pipeline. Les exécutions d’activité apparaissent dans une liste.
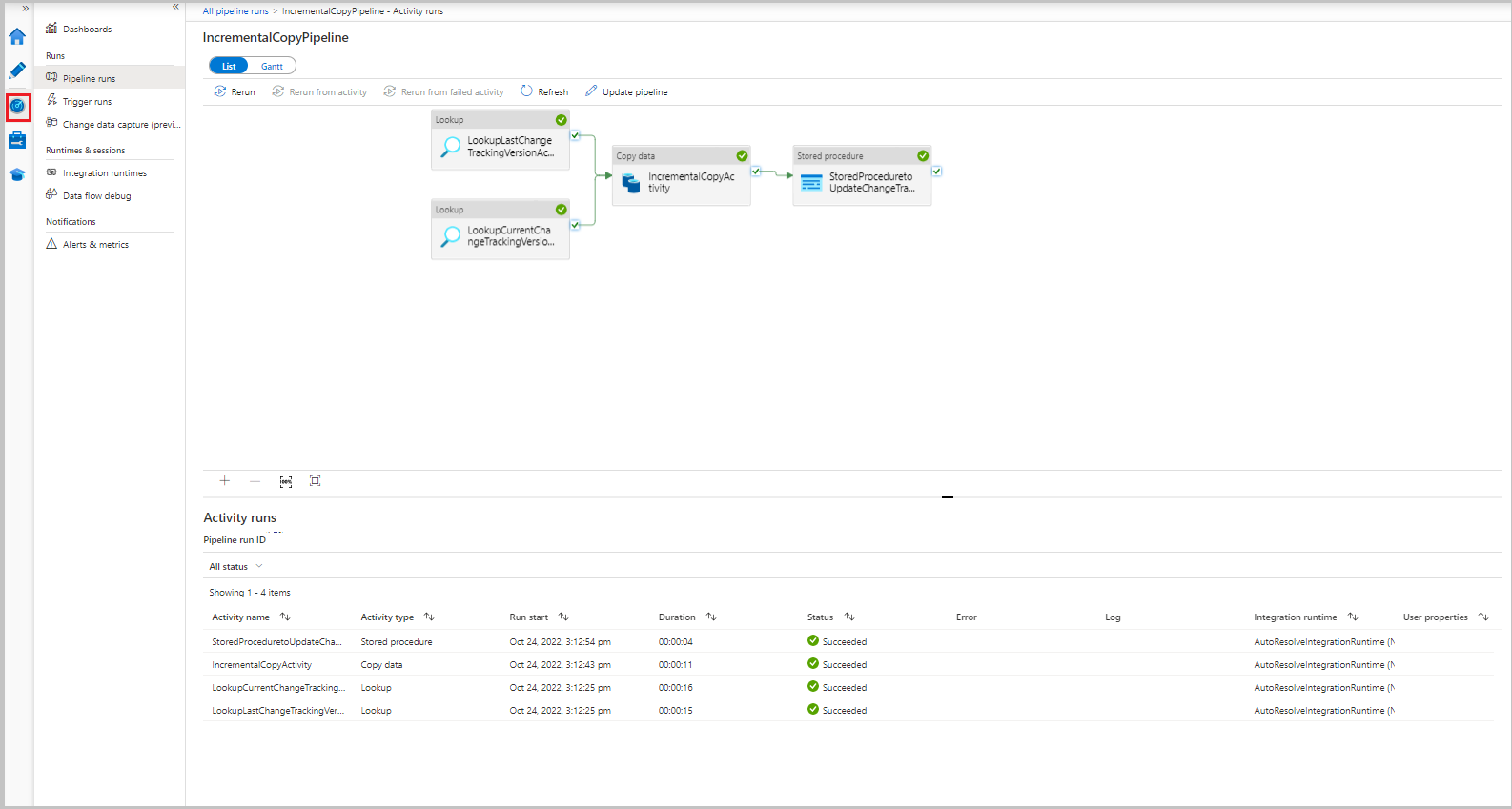
Passer en revue les résultats.
Le deuxième fichier apparaît dans le dossier incchgtracking du conteneur adftutorial .
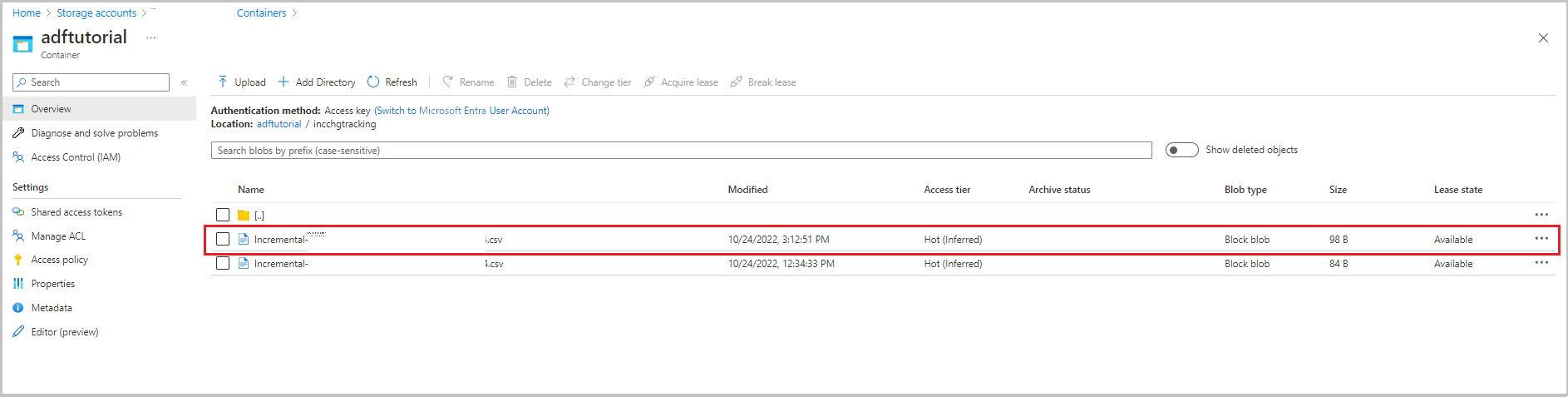
Le fichier ne doit contenir que les données delta de votre base de données. L’enregistrement avec U correspondant à la ligne mise à jour dans la base de données et I à la ligne ajoutée.
PersonID,Name,Age,SYS_CHANGE_VERSION,SYS_CHANGE_OPERATION
1,update,10,2,U
6,new,50,1,I
Les trois premières colonnes correspondent aux données modifiées de data_source_table. Les deux dernières colonnes sont les métadonnées de la table pour le système de suivi des modifications. La quatrième colonne correspond à la valeur SYS_CHANGE_VERSION de chaque ligne modifiée. La cinquième colonne correspond à l’opération : U = mise à jour, I = insertion. Pour plus d’informations sur le suivi des modifications, consultez CHANGETABLE.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
Contenu connexe
Passez au tutoriel suivant pour en savoir plus sur la copie des fichiers nouveaux et modifiés uniquement en fonction de LastModifiedDate :