Charger de façon incrémentielle les données depuis Azure SQL Database dans le stockage Blob Azure par le biais du portail Azure
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Dans ce tutoriel, vous créez une fabrique de données Azure Data Factory avec un pipeline qui charge les données delta d’une table dans Azure SQL Database vers un stockage Blob Azure.
Dans ce tutoriel, vous allez effectuer les étapes suivantes :
- Préparer le magasin de données pour y stocker la valeur de limite.
- Créer une fabrique de données.
- créez des services liés.
- Créer des jeux de données source, récepteur et filigrane.
- Créer un pipeline.
- Exécuter le pipeline.
- Surveiller l’exécution du pipeline.
- Passer en revue les résultats
- Ajouter plus de données à la source.
- Exécuter de nouveau le pipeline.
- Surveiller la deuxième exécution du pipeline
- Passer en revue les résultats de la deuxième exécution
Vue d’ensemble
Voici le diagramme général de la solution :

Voici les étapes importantes à suivre pour créer cette solution :
Sélectionner la colonne de limite. Sélectionnez une colonne dans le magasin de données sources, qui peut servir à découper les enregistrements nouveaux ou mis à jour pour chaque exécution. Normalement, les données contenues dans cette colonne sélectionnée (par exemple, last_modify_time ou ID) continuent de croître à mesure que des lignes sont créées ou mises à jour. La valeur maximale de cette colonne est utilisée comme limite.
Préparer un magasin de données pour stocker la valeur de limite. Dans ce tutoriel, la valeur de filigrane est stockée dans une base de données SQL.
Créer un pipeline avec le flux de travail suivant :
Le pipeline de cette solution compte les activités suivantes :
- Créez deux activités de recherche. Servez-vous de la première activité de recherche pour récupérer la dernière valeur de filigrane. Utilisez la deuxième activité de recherche pour récupérer la nouvelle valeur de filigrane. Ces valeurs de filigrane sont transmises à l’activité de copie.
- Créez une activité de copie qui copie les lignes du magasin de données source dont la valeur de la colonne de filigrane est supérieure à l’ancienne valeur de filigrane et inférieure à la nouvelle. Elle copie ensuite les données delta du magasin de données source dans un stockage d’objets blob sous la forme d’un nouveau fichier.
- Créez une activité StoredProcedure qui met à jour la valeur de filigrane pour le pipeline s’exécutant la prochaine fois.
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
- Azure SQL Database. Vous utilisez la base de données comme magasin de données source. Si vous n’avez pas de base de données dans Azure SQL Database, consultez Créer une base de données dans Azure SQL Database pour savoir comme en créer une.
- Stockage Azure. Vous utilisez le stockage d’objets blob comme magasin de données récepteur. Si vous ne possédez pas de compte de stockage, consultez l’article Créer un compte de stockage pour découvrir comment en créer un. Créez un conteneur sous le nom adftutorial.
Créer une table de source de données dans votre base de données SQL
Ouvrez SQL Server Management Studio. Dans l’Explorateur de serveurs, cliquez avec le bouton droit sur la base de données, puis choisissez Nouvelle requête.
Exécutez la commande SQL suivante sur votre base de données SQL pour créer une table sous le nom
data_source_tablecomme magasin de source de données :create table data_source_table ( PersonID int, Name varchar(255), LastModifytime datetime ); INSERT INTO data_source_table (PersonID, Name, LastModifytime) VALUES (1, 'aaaa','9/1/2017 12:56:00 AM'), (2, 'bbbb','9/2/2017 5:23:00 AM'), (3, 'cccc','9/3/2017 2:36:00 AM'), (4, 'dddd','9/4/2017 3:21:00 AM'), (5, 'eeee','9/5/2017 8:06:00 AM');Dans ce didacticiel, vous allez utiliser LastModifytime comme colonne de filigrane. Les données contenues dans le magasin de source de données sont indiquées dans le tableau suivant :
PersonID | Name | LastModifytime -------- | ---- | -------------- 1 | aaaa | 2017-09-01 00:56:00.000 2 | bbbb | 2017-09-02 05:23:00.000 3 | cccc | 2017-09-03 02:36:00.000 4 | dddd | 2017-09-04 03:21:00.000 5 | eeee | 2017-09-05 08:06:00.000
Créer une autre table dans la base de données SQL pour stocker la valeur de filigrane supérieure
Exécutez la commande SQL suivante sur votre base de données SQL pour créer une table sous le nom
watermarktablepour stocker la valeur de filigrane :create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Définissez la valeur par défaut du filigrane supérieur avec le nom de table du magasin de données source. Dans ce didacticiel, le nom de table est data_source_table.
INSERT INTO watermarktable VALUES ('data_source_table','1/1/2010 12:00:00 AM')Passez en revue les données contenues dans la table
watermarktable.Select * from watermarktableSortie :
TableName | WatermarkValue ---------- | -------------- data_source_table | 2010-01-01 00:00:00.000
Créer une procédure stockée dans la base de données SQL
Exécutez la commande suivante pour créer une procédure stockée dans votre base de données SQL :
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Créer une fabrique de données
Lancez le navigateur web Microsoft Edge ou Google Chrome. L’interface utilisateur de Data Factory n’est actuellement prise en charge que par les navigateurs web Microsoft Edge et Google Chrome.
Dans le menu de gauche, sélectionnez Créer une ressource>Intégration>Data Factory :
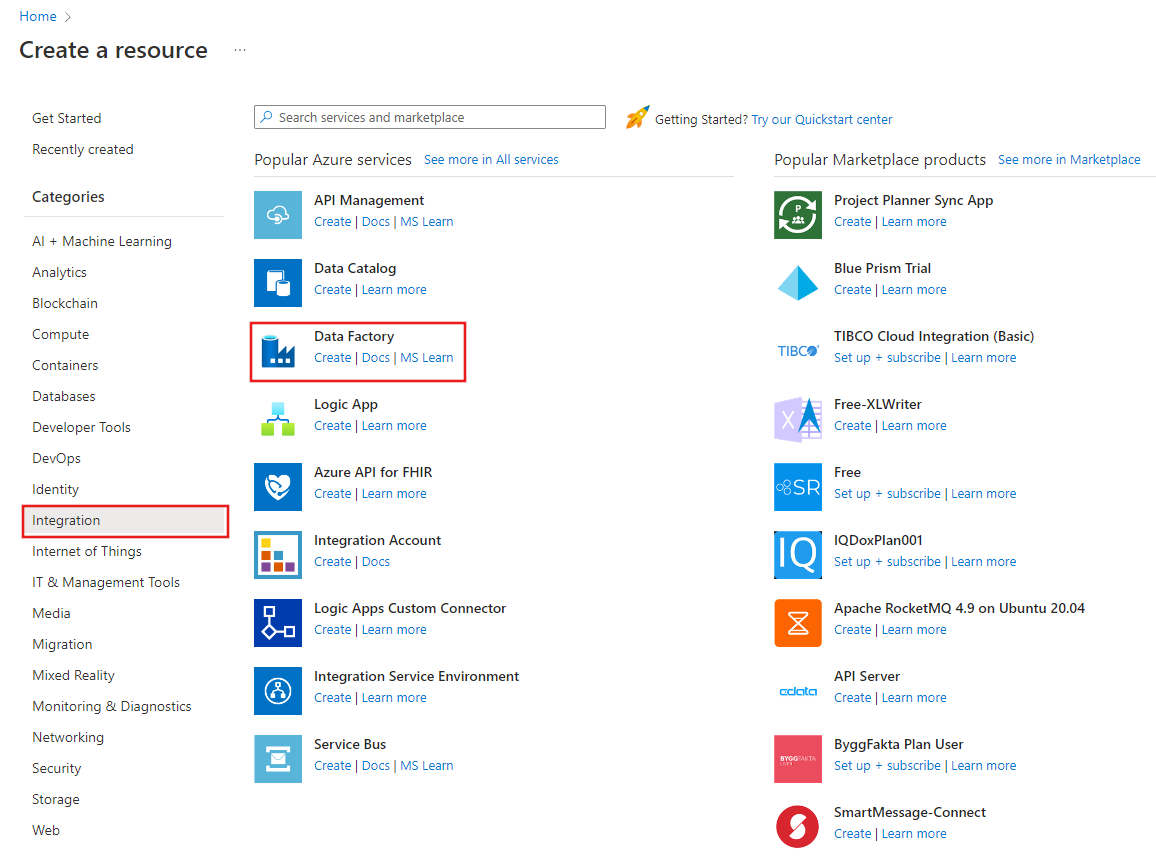
Sur la page Nouvelle fabrique de données, entrez ADFTutorialOnPremDF comme nom.
Le nom de la fabrique de données Azure Data Factory doit être globalement unique. Si vous voyez un point d’exclamation rouge avec l’erreur suivante, changez le nom de la fabrique de données (par exemple, votrenomADFIncCopyTutorialDF), puis tentez de la recréer. Consultez l’article Data Factory - Règles d’affectation des noms pour savoir comment nommer les artefacts Data Factory.
Le nom de fabrique de données « ADFIncCopyTutorialDF » n’est pas disponible
Sélectionnez l’abonnement Azure dans lequel vous voulez créer la fabrique de données.
Pour le groupe de ressources, effectuez l’une des opérations suivantes :
Sélectionnez Utiliser l’existant, puis sélectionnez un groupe de ressources existant dans la liste déroulante.
Sélectionnez Créer, puis entrez le nom d’un groupe de ressources.
Pour plus d’informations sur les groupes de ressources, consultez Utilisation des groupes de ressources pour gérer vos ressources Azure.
Sélectionnez V2 pour la version.
Sélectionnez l’emplacement de la fabrique de données. Seuls les emplacements pris en charge sont affichés dans la liste déroulante. Les magasins de données (Stockage Azure, Azure SQL Database, Azure SQL Managed Instance, etc.) et les services de calcul (HDInsight, etc.) utilisés par une fabrique de données peuvent se trouver dans d’autres régions.
Cliquez sur Créer.
Une fois la création terminée, la page Data Factory s’affiche comme sur l’image.

Sélectionnez Ouvrir dans la vignette Ouvrir Azure Data Factory Studio pour lancer l’interface utilisateur d’Azure Data Factory dans un onglet distinct.
Créer un pipeline
Dans ce didacticiel, vous allez créer un pipeline avec deux activités de recherche, une activité de copie et une activité StoredProcedure chaînées dans le même pipeline.
Dans la page d’accueil de l’interface utilisateur de Data Factory, cliquez sur la vignette Orchestrer.
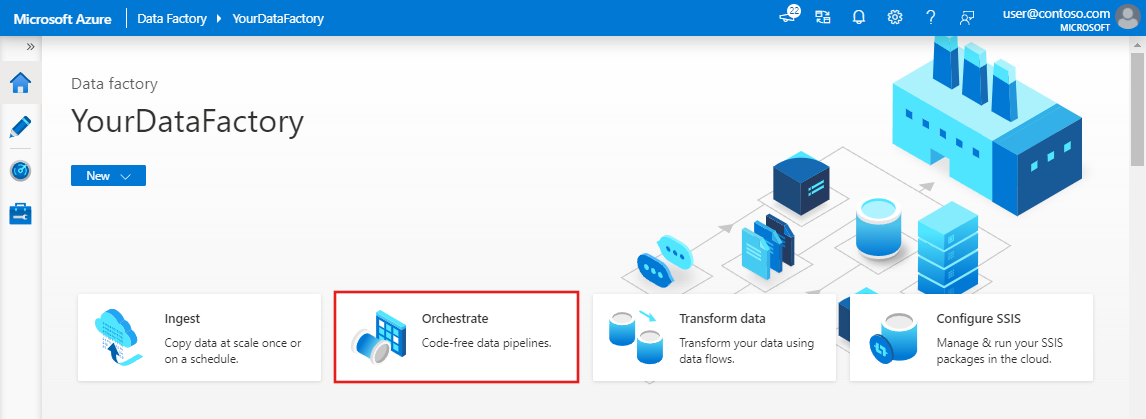
Dans le volet Général, sous Propriétés, spécifiez IncrementalCopyPipeline comme Nom. Réduisez ensuite le panneau en cliquant sur l’icône Propriétés en haut à droite.
Vous allez ajouter la première activité de recherche pour obtenir l’ancienne valeur de filigrane. Dans la boîte à outils Activités, Développez Général, puis faites glisser et déposez une activité Recherche sur la surface du concepteur de pipeline. Changez le nom de l’activité par LookupOldWaterMarkActivity.
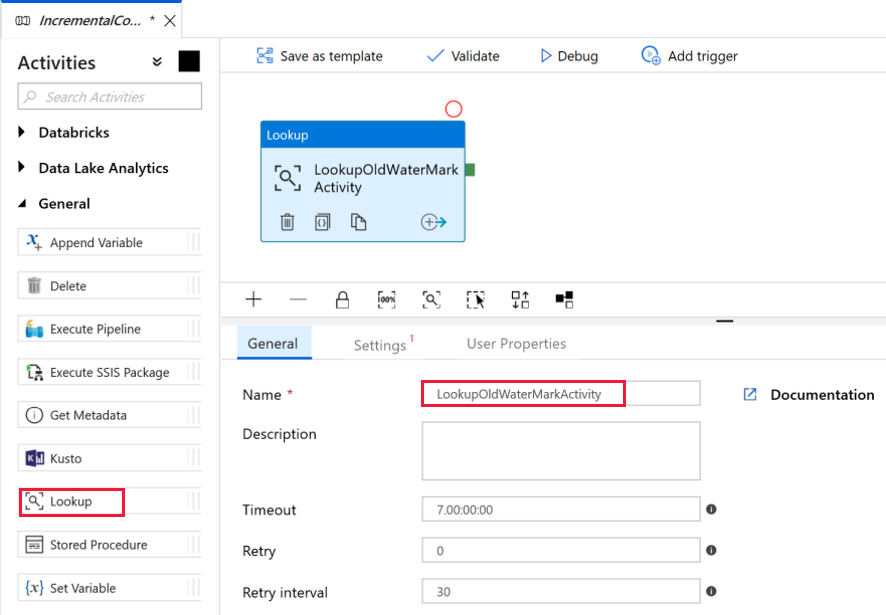
Basculez vers l’onglet Paramètres, puis cliquez sur + Nouveau comme jeu de données source. Dans cette étape, vous créez un jeu de données pour représenter des données dans la table filigrane. Cette table contient l’ancien filigrane utilisé dans l’opération de copie précédente.
Dans la fenêtre Nouveau jeu de données, sélectionnez Azure SQL Database, puis cliquez sur Continuer. Vous voyez une nouvelle fenêtre ouverte pour le jeu de données.
Dans la fenêtre Définir des propriétés pour le jeu de données, entrez WatermarkDataset comme nom.
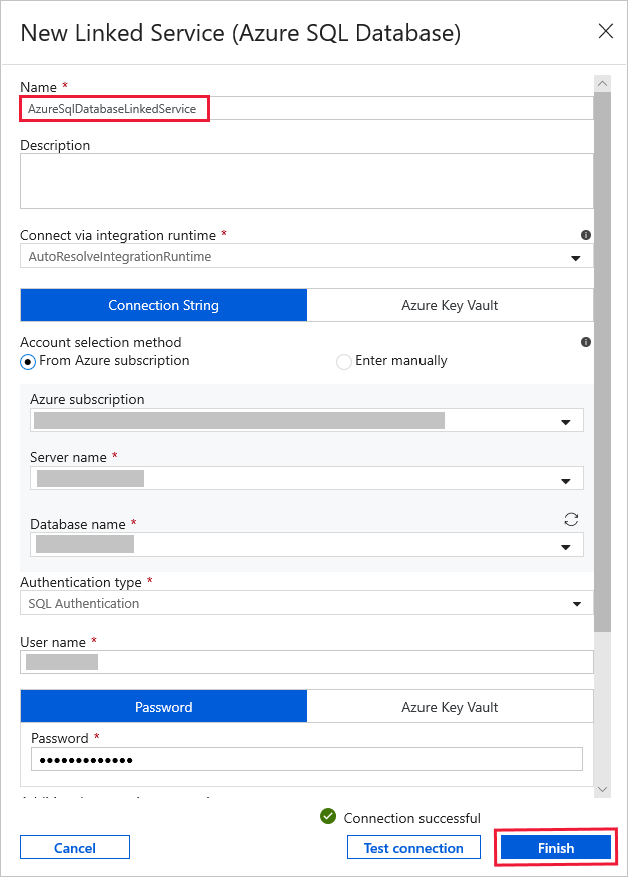
Pour Service lié, sélectionnez Nouveau, puis procédez comme suit :
Entrez AzureSqlDatabaseLinkedService pour Nom.
Sélectionnez votre serveur pour Nom du serveur.
Sélectionnez le nom de la base de données dans la liste déroulante.
Entrez votre nom d’utilisateur et votre mot de passe.
Pour tester la connexion à votre base de données SQL, cliquez sur Tester la connexion.
Cliquez sur Terminer.
Vérifiez que AzureSqlDatabaseLinkedService est sélectionné comme service lié.
Sélectionnez Terminer.
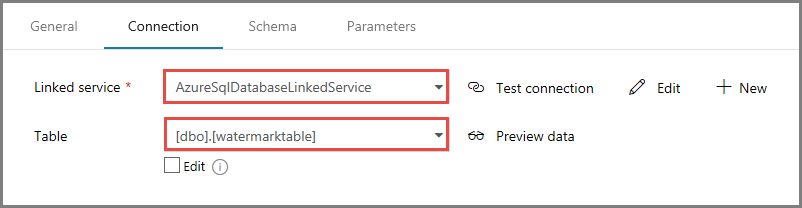
Sous l’onglet Connexion, sélectionnez [dbo].[watermarktable] pour Table. Si vous souhaitez afficher un aperçu des données de la table, cliquez sur Aperçu des données.
Basculez vers l’éditeur de pipeline en cliquant sur l’onglet du pipeline en haut ou bien en cliquant sur le nom du pipeline dans l’arborescence à gauche. Dans la fenêtre Propriétés pour l’activité de recherche, vérifiez que WatermarkDataset est sélectionné dans le champ Jeu de données source.
Dans la boîte à outils Activités, développez Généralet faites glisser et déposez une autre activité de recherche sur la surface du concepteur de pipeline, puis saisissez le nom LookupNewWaterMarkActivity dans l’onglet Général de la fenêtre Propriétés. Cette activité de recherche obtient la nouvelle valeur de filigrane à partir de la table avec les données sources à copier vers la destination.
Dans la fenêtre Propriétés pour la deuxième activité de recherche, basculez vers l’onglet Paramètres, puis cliquez sur Nouveau. Vous créez un jeu de données pour pointer vers la table source qui contient la nouvelle valeur du filigrane (valeur maximale de LastModifyTime).
Dans la fenêtre Nouveau jeu de données, sélectionnez Azure SQL Database, puis cliquez sur Continuer.
Dans la fenêtre Définir des propriétés, entrez SourceDataset comme nom. Sélectionnez AzureSqlDatabaseLinkedService pour Service lié.
Sélectionnez [dbo].[ data_source_table] comme table. Vous allez spécifier une requête sur ce jeu de données plus loin dans le didacticiel. La requête a la priorité sur la table spécifiée à cette étape.
Sélectionnez Terminer.
Basculez vers l’éditeur de pipeline en cliquant sur l’onglet du pipeline en haut ou bien en cliquant sur le nom du pipeline dans l’arborescence à gauche. Dans la fenêtre Propriétés pour l’activité de recherche, vérifiez que SourceDataset est sélectionné dans le champ Jeu de données source.
Sélectionnez Requête pour le champ Utiliser une requête et saisissez la requête suivante : vous sélectionnez uniquement la valeur maximale de LastModifytime à partir de data_table_source. Vérifiez que vous avez également coché Première ligne uniquement.
select MAX(LastModifytime) as NewWatermarkvalue from data_source_table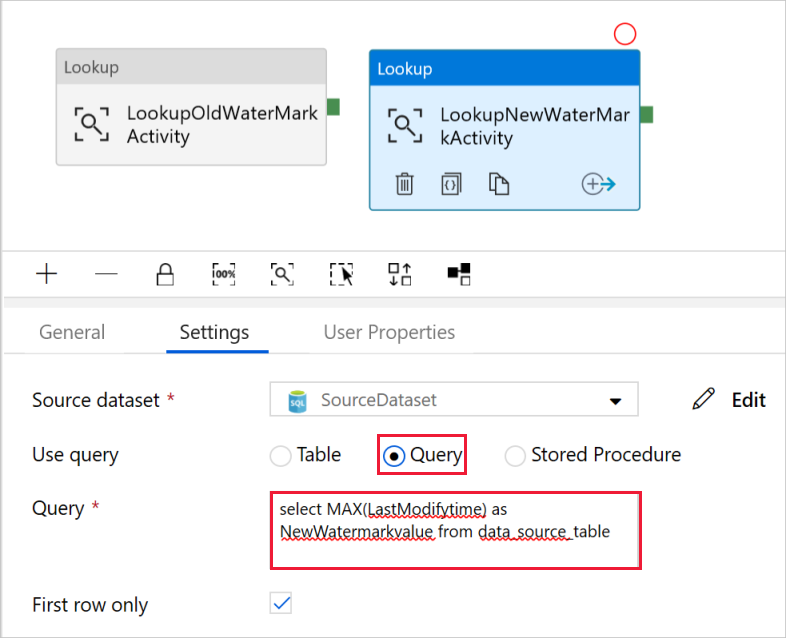
Dans la boîte à outils Activités, développez Déplacer et transformer, glissez-déposez l’activité de copie à partir de la boîte à outils Activités, puis définissez le nom IncrementalCopyActivity.
Connecter les deux activités de recherche à l’activité de copie en faisant glisser le bouton vert attaché aux activités de recherche vers l’activité de copie. Relâchez le bouton de la souris lorsque la couleur de bordure de l’activité de copie passe en bleu.
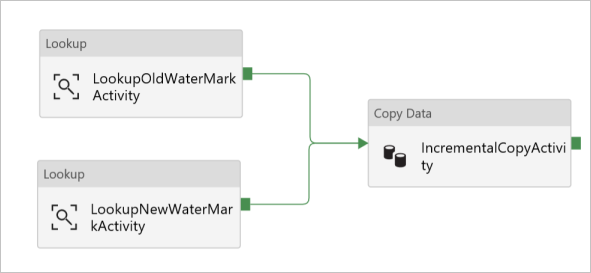
Sélectionnez l’activité de copie et vérifiez que vous vouez les propriétés de l’activité dans la fenêtre Propriétés.
Basculez vers l’onglet Source dans la fenêtrePropriétés, et procédez comme suit :
Sélectionnez SourceDataset pour le champ Jeu de données source.
Sélectionnez Requête pour le champ Utiliser la requête.
Saisissez la requête SQL suivante dans le champ Requête.
select * from data_source_table where LastModifytime > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and LastModifytime <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'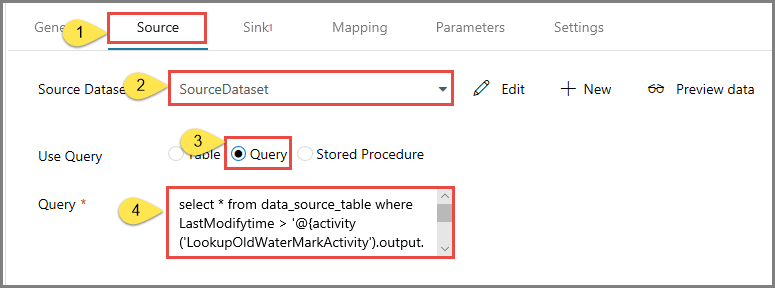
Basculez vers l’onglet Récepteur, puis cliquez sur + Nouveau pour le champ Jeu de données récepteur.
Dans ce didacticiel, le magasin de données récepteur est de type Stockage Blob Azure. Par conséquent, sélectionnez Stockage Blob Azure, puis cliquez sur Continuer dans la fenêtre Nouveau jeu de données.
Dans la fenêtre Sélectionner le format, sélectionnez le type de format de vos données et cliquez sur Continuer.
Dans la fenêtre Définir des propriétés, entrez SinkDataset comme nom. Pour Service lié, sélectionnez + Nouveau. Dans cette étape, vous créez une connexion (service lié) à votre stockage Blob Azure.
Dans la fenêtre Nouveau service lié (Stockage Blob Azure) , effectuez les étapes suivantes :
- Entrez AzureStorageLinkedService pour Nom.
- Sélectionnez votre compte de stockage Azure comme Nom du compte de stockage.
- Testez la connexion, puis cliquez sur Terminer.
Dans la fenêtre Définir des propriétés, vérifiez que AzureStorageLinkedService est sélectionné comme service lié. Sélectionnez Terminer.
Accédez à l’onglet Connexion de SinkDataset et procédez comme suit :
- Pour le champ Chemin de fichier, entrez adftutorial/incrementalcopy. adftutorial est le nom du conteneur d’objets blob et incrementalcopy est le nom du dossier. Cet extrait de code suppose que vous disposez d’un conteneur d’objets blob nommé adftutorial dans le stockage d’objets blob. Créez le conteneur s’il n’existe pas ou attribuez-lui le nom d’un conteneur existant. Azure Data Factory crée automatiquement le dossier de sortie incrementalcopy s’il n’existe pas. Vous pouvez également utiliser le bouton Parcourir pour le chemin d’accès du fichier afin d’accéder à un dossier dans un conteneur d’objets blob.
- Pour la partie Fichier du champ Chemin de fichier, sélectionnez Ajouter du contenu dynamique [Alt+P] , puis entrez
@CONCAT('Incremental-', pipeline().RunId, '.txt')dans la fenêtre ouverte. Sélectionnez Terminer. Le nom de fichier est généré dynamiquement à l’aide de l’expression. Chaque exécution de pipeline possède un ID unique. L’activité de copie utilise l’ID d’exécution pour générer le nom de fichier.
Basculez vers l’éditeur de pipeline en cliquant sur l’onglet du pipeline en haut ou bien en cliquant sur le nom du pipeline dans l’arborescence à gauche.
Dans la boîte à outils Activités, développez Général, et faites glisser et déposez l’activité Procédure stockée de la boîte à outils Activités sur la surface du concepteur de pipeline. Connectez le résultat vert (succès) de l’activité de copie à l’activité Procédure stockée.
Sélectionnez Activité de procédure stockée dans le concepteur de pipeline, remplacez son nom par StoredProceduretoWriteWatermarkActivity.
Passez à l’onglet Compte SQL et sélectionnez AzureSqlDatabaseLinkedService comme service lié.
Basculez vers l’onglet Procédure stockée, et procédez comme suit :
Pour Nom de la procédure stockée, sélectionnez usp_write_watermark.
Pour spécifier des valeurs correspondant aux paramètres de procédure stockée, cliquez sur Import parameter (Paramètre d’importation), puis entrez les valeurs suivantes pour les paramètres :
Nom Type Valeur LastModifiedtime DateTime @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue} TableName String @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName} 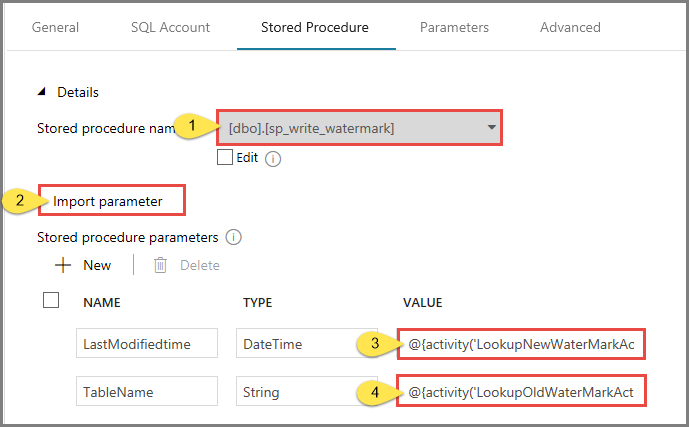
Pour valider les paramètres du pipeline, cliquez sur Valider dans la barre d’outils. Vérifiez qu’il n’y a aucune erreur de validation. Pour fermer la fenêtre Rapport de validation de pipeline, cliquez sur >>.
Publiez des entités (services liés, jeux de données et pipelines) pour le service Azure Data Factory en sélectionnant le bouton Publier tout. Patientez jusqu’à voir le message de réussite de la publication.
Déclencher une exécution du pipeline
Cliquez sur Ajouter un déclencheur dans la barre d’outils, puis sur Déclencher maintenant.
Dans la fenêtre Exécution du pipeline, sélectionnez Terminer.
Surveiller l’exécution du pipeline.
Basculez vers l’onglet Surveiller sur la gauche. Vous pouvez voir l’état de l’exécution du pipeline déclenchée par un déclencheur manuel. Vous pouvez utiliser les liens sous la colonne NOM DU PIPELINE pour voir les détails de l’exécution et réexécuter le pipeline.
Pour voir les exécutions d’activités associées à l’exécution du pipeline, sélectionnez le lien sous la colonne NOM DU PIPELINE. Pour plus de détails sur les exécutions d’activités, sélectionnez le lien Détails (icône en forme de lunettes) dans la colonne NOM DE L’ACTIVITÉ. Sélectionnez Toutes les exécutions de pipelines en haut pour revenir à la vue Exécutions de pipelines. Sélectionnez Actualiser pour actualiser l’affichage.
Passer en revue les résultats.
Connectez-vous à votre compte de Stockage Azure à l’aide des outils tels que Azure Storage Explorer. Vérifiez qu’un fichier de sortie est créé dans le dossier incrementalcopy du conteneur adftutorial.
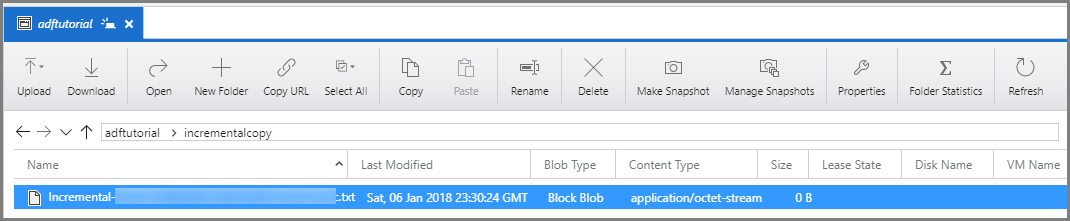
Ouvrez le fichier de sortie et notez que toutes les données sont copiées à partir de la data_source_table dans le fichier de l’objet blob.
1,aaaa,2017-09-01 00:56:00.0000000 2,bbbb,2017-09-02 05:23:00.0000000 3,cccc,2017-09-03 02:36:00.0000000 4,dddd,2017-09-04 03:21:00.0000000 5,eeee,2017-09-05 08:06:00.0000000Vérifiez la valeur la plus récente dans
watermarktable. Vous constatez que la valeur de filigrane a été mise à jour.Select * from watermarktableVoici la sortie :
| TableName | WatermarkValue | | --------- | -------------- | | data_source_table | 2017-09-05 8:06:00.000 |
Ajouter plus de données à la source
Insérez de nouvelles données dans votre base de données (magasin de source de données).
INSERT INTO data_source_table
VALUES (6, 'newdata','9/6/2017 2:23:00 AM')
INSERT INTO data_source_table
VALUES (7, 'newdata','9/7/2017 9:01:00 AM')
Données mises à jour dans votre base de données :
PersonID | Name | LastModifytime
-------- | ---- | --------------
1 | aaaa | 2017-09-01 00:56:00.000
2 | bbbb | 2017-09-02 05:23:00.000
3 | cccc | 2017-09-03 02:36:00.000
4 | dddd | 2017-09-04 03:21:00.000
5 | eeee | 2017-09-05 08:06:00.000
6 | newdata | 2017-09-06 02:23:00.000
7 | newdata | 2017-09-07 09:01:00.000
Déclencher une autre exécution de pipeline
Basculez vers l’onglet Modifier. Cliquez sur le pipeline dans l’arborescence s’il n’est pas ouvert dans le concepteur.
Cliquez sur Ajouter un déclencheur dans la barre d’outils, puis sur Déclencher maintenant.
Surveiller la deuxième exécution du pipeline
Basculez vers l’onglet Surveiller sur la gauche. Vous pouvez voir l’état de l’exécution du pipeline déclenchée par un déclencheur manuel. Vous pouvez utiliser les liens sous la colonne NOM DU PIPELINE pour voir les détails de l’activité et réexécuter le pipeline.
Pour voir les exécutions d’activités associées à l’exécution du pipeline, sélectionnez le lien sous la colonne NOM DU PIPELINE. Pour plus de détails sur les exécutions d’activités, sélectionnez le lien Détails (icône en forme de lunettes) dans la colonne NOM DE L’ACTIVITÉ. Sélectionnez Toutes les exécutions de pipelines en haut pour revenir à la vue Exécutions de pipelines. Sélectionnez Actualiser pour actualiser l’affichage.
Vérifier la deuxième sortie
Dans le stockage d’objets blob, vous constatez qu’un autre fichier a été créé. Dans ce didacticiel, le nom du nouveau fichier est
Incremental-<GUID>.txt. Ouvrez ce fichier. Vous constatez alors qu’il contient deux lignes d’enregistrements.6,newdata,2017-09-06 02:23:00.0000000 7,newdata,2017-09-07 09:01:00.0000000Vérifiez la valeur la plus récente dans
watermarktable. Vous constatez que la valeur de filigrane a été de nouveau mise à jour.Select * from watermarktableExemple de sortie :
| TableName | WatermarkValue | | --------- | -------------- | | data_source_table | 2017-09-07 09:01:00.000 |
Contenu connexe
Dans ce tutoriel, vous avez effectué les étapes suivantes :
- Préparer le magasin de données pour y stocker la valeur de limite.
- Créer une fabrique de données.
- créez des services liés.
- Créer des jeux de données source, récepteur et filigrane.
- Créer un pipeline.
- Exécuter le pipeline.
- Surveiller l’exécution du pipeline.
- Passer en revue les résultats
- Ajouter plus de données à la source.
- Exécuter de nouveau le pipeline.
- Surveiller la deuxième exécution du pipeline
- Passer en revue les résultats de la deuxième exécution
Dans ce tutoriel, le pipeline a copié les données d’une table unique dans SQL Database vers le stockage Blob. Passez au tutoriel suivant pour découvrir comment copier les données de plusieurs tables d’une base de données SQL Server vers SQL Database.