Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Important
La mise à l’échelle automatique Lakebase est disponible dans les régions suivantes : eastus, eastus2, centralus, southcentralus, westus, westus2, canadacentral, brazilsouth, northeurope, uksouth, westeurope, australiaeast, centralindia, southeastasia
La version Lakebase Autoscaling est la dernière de Lakebase, avec l'évolutivité automatique, la mise à l’échelle jusqu'à zéro, la création de branches et la restauration instantanée. Si vous êtes un utilisateur Lakebase Provisionné, consultez Lakebase Provisioned.
La mise à l’échelle automatique de Lakebase Postgres est une base de données Postgres entièrement gérée intégrée à la plateforme Databricks Data Intelligence. Elle est conçue pour toutes les applications nécessitant un traitement transactionnel en ligne (OLTP) et la fourniture de données à faible latence. Lakebase apporte ces fonctionnalités à votre lakehouse, ce qui vous permet de créer des applications transactionnelles en temps réel en même temps que vos charges de travail d’analytique.
La mise à l’échelle automatique de Lakebase Postgres combine la fiabilité et la familiarité de Postgres avec les fonctionnalités de base de données modernes, notamment la mise à l’échelle automatique, la mise à l’échelle à zéro, la branchement et la restauration instantanée. Ces fonctionnalités permettent des workflows de développement flexibles, des opérations rentables et une itération rapide.
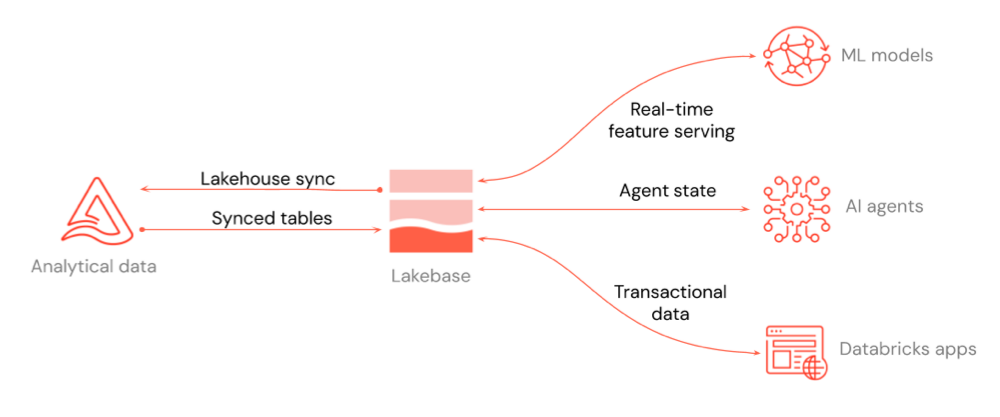
Le diagramme montre comment Lakebase s’intègre au reste de la plateforme : fonctionnalité en temps réel servant pour les modèles ML et le Feature Store, l’état de l’agent pour les agents IA et les données transactionnelles pour Databricks Apps ou toute application que vous y connectez.
Vous pouvez déplacer des données dans les deux sens entre votre lakehouse et Lakebase. Les tables synchronisées déplacent les données de lakehouse vers Lakebase afin que vos applications puissent les interroger à faible latence.
Exemples de cas d’usage et types de charge de travail
Voici quelques exemples des nombreuses façons d’utiliser une base de données Postgres OLTP comme Lakebase dans les secteurs : recommandations personnalisées et ciblage dans le commerce électronique et la vente au détail, données d’essai clinique et systèmes de recommandation dans les soins de santé, trading automatisé et analytique de streaming dans les services financiers, télémétrie des machines et flux de travail de maintenance dans la fabrication.
Les types de charges de travail courants pour les bases de données OLTP peuvent inclure les éléments suivants :
- Service des données : Fournissez des informations stratégiques des tables de référence aux applications avec une faible latence et un haut débit de requêtes par seconde (QPS).
- Stocker l’état de l’application : Gérer l’état du flux de travail et de l’agent dans un magasin de données transactionnel.
- Service des fonctionnalités : Servez des données caractérisations à faible latence pour les modèles ML.
Intégration de Databricks
Le diagramme ci-dessus met en évidence trois cas d’usage d’intégration clés :
- Service de caractéristiques en temps réel : Utilisez des projets Lakebase en tant que magasin en ligne pour les modèles ML et le store de caractéristiques, afin de pouvoir servir des données featurisées à faible latence. Consultez le Magasin de fonctionnalités en ligne (Lakebase) et Service des fonctionnalités.
- État de l’agent pour les agents IA : Stockez et gérez l’état des agents IA dans une base de données transactionnelle, de sorte que les conversations et le contexte de flux de travail persistent entre les requêtes.
- Données transactionnelles pour les applications : Conserver des données pour Databricks Apps ou toute application que vous connectez à Lakebase. Pour Databricks Apps, ajoutez un projet Lakebase en tant que ressource d’application. Consultez Ajouter une ressource Lakebase à une application Databricks.
Lakebase Mise en service
Lakebase Provisioned est l’offre Lakebase d’origine qui utilise les ressources de calcul provisionnées que vous échellez manuellement. Les instances existantes provisionnées continuent d’être prises en charge. Le développement De Lakebase est axé sur la mise à l’échelle automatique. Si vous avez des instances provisionnés ou évaluez les deux options, consultez Qu’est-ce que Lakebase Provisioned ? et la mise à l’échelle automatique par défaut.
Qu’est-ce qu’un projet ?
Les ressources de mise à l’échelle automatique Lakebase sont organisées en structure de projet . Un projet est le conteneur de niveau supérieur pour vos ressources de base de données. Lorsque vous créez une base de données de mise à l’échelle automatique Lakebase, vous créez un projet. Le projet contient vos branches (environnements de base de données), calculs, rôles et bases de données. Considérez un projet comme unité d’organisation pour une application ou une charge de travail. Vous pouvez avoir plusieurs projets dans un espace de travail, chacun avec ses propres branches et données.
Organisation des projets
La compréhension de la hiérarchie des objets au sein d’un projet vous aide à organiser et à gérer vos ressources :
Databricks Workspace
└── Project(s)
└── Branch(es)
├── Compute (primary R/W)
├── Read replica(s) (optional)
├── Role(s)
└── Database(s)
└── Schema(s)
Chaque niveau de la hiérarchie sert un objectif spécifique :
| Objet | Descriptif |
|---|---|
| Projet | Conteneur de niveau supérieur pour vos ressources de base de données. Un projet contient des branches, des bases de données, des rôles et des ressources de calcul. Consultez Gérer les projets. |
| Branche | Environnement de base de données isolé qui partage le stockage avec sa branche parente. Chaque projet peut contenir plusieurs branches. Consultez Gérer les branches. |
| Calculer | Serveur Postgres qui alimente une branche. Chaque branche a son propre calcul qui fournit la puissance de traitement et la mémoire pour les opérations de base de données. Consultez Gérer les calculs. |
| Base de données | Base de données Postgres standard au sein d’une branche. Chaque branche peut contenir plusieurs bases de données avec leurs propres tables, schémas et données. Consultez Gérer les bases de données. |
Présentation des branches
L'une des fonctionnalités les plus puissantes de Lakebase Postgres est le regroupement en branches. Comme les branches Git pour votre code, les branches vous permettent de créer des environnements de base de données isolés pour le développement et les tests, sans affecter la production.
Pourquoi cela est important : Les flux de travail de base de données traditionnels nécessitent des serveurs de développement et de préproduction distincts, des actualisations manuelles des données et une coordination minutieuse. Avec les branches, vous pouvez :
- Créer instantanément un environnement de développement avec des données de production
- Tester les modifications de schéma en toute sécurité avant de les appliquer à la production
- Se remettre des erreurs en créant des branches à tout moment
- Payer uniquement pour les données que vous modifiez, pas les bases de données en double complètes
| Sujet | Descriptif |
|---|---|
| Branches | Découvrez comment les branches fonctionnent, les flux de travail courants et les meilleures pratiques pour votre équipe. |
| Gérer des branches | Créez, réinitialisez et supprimez des branches pour le développement et le test. |
| Branches protégées | Protégez les branches de production contre les modifications et suppressions accidentelles. |
Concepts de base
Lakebase repose sur plusieurs innovations clés qui la différencient des systèmes de base de données traditionnels :
- Calcul et stockage séparés : Mettez à l’échelle les ressources de calcul indépendamment du stockage pour optimiser les coûts et la flexibilité.
- Mise à l’échelle automatique : Le calcul s’ajuste automatiquement en fonction de la demande de charge de travail, avec prise en charge de la mise à l’échelle à zéro pendant les périodes d’inactivité.
- Stockage de copie en écriture : Permet la création de branches instantanées où vous payez uniquement les modifications de données, plutôt que des duplications complètes.
- Opérations instantanées dans le temps : Créer des branches ou restaurer à tout moment dans votre fenêtre de restauration configurée (0 à 30 jours)
Ces concepts fonctionnent ensemble pour permettre des workflows de développement flexibles, des opérations rentables et une récupération rapide des erreurs.
Pour obtenir une explication détaillée de chaque concept de base, consultez concepts de base.