Fédération multi-site et multi-région
De nombreuses solutions sophistiquées exigent que les mêmes flux d’événements soient mis à disposition pour être consommés à plusieurs emplacements, ou qu’ils soient collectés dans plusieurs emplacements puis consolidés à un emplacement spécifique pour être consommés. Il est également souvent nécessaire d’enrichir ou de réduire les flux d’événements ou de procéder à des conversions de formats d’événements, même au sein d’une seule région et solution.
Concrètement, cela signifie que votre solution gérera plusieurs Event Hubs, souvent dans des régions et des espaces de noms Event Hubs différents, puis reproduira les événements entre eux. Vous pouvez également échanger des événements avec des sources et des cibles comme Azure Service Bus, Azure IoT Hub ou Apache Kafka.
La gestion de plusieurs Event Hubs actifs dans différentes régions permet également aux clients de choisir et de basculer entre eux si leur contenu est fusionné, ce qui rend le système global plus résilient face aux problèmes de disponibilité régionale.
Ce chapitre « Fédération » explique les modèles de fédération et la façon de réaliser ces modèles à l’aide des runtimes Azure Stream Analytics ou Azure Functions serverless, avec la possibilité d’avoir son propre code de transformation ou d’enrichissement directement dans le chemin de flux des événements.
Modèles de Fédération
Il existe de nombreuses raisons pour lesquelles vous pourriez vouloir déplacer des événements entre différents Event Hubs ou vers d’autres sources et cibles. Nous énumérons les modèles les plus importants dans cette section et proposons également des liens vers des conseils plus détaillés pour chaque modèle.
- Résilience face aux événements de disponibilité régionale
- Optimisation de la latence
- Validation, réduction et enrichissement
- Intégration aux services d’analytique
- Consolidation et normalisation des flux d’événements
- Fractionnement et routage des flux d’événements
- Projections de journal
Résilience face aux événements de disponibilité régionale
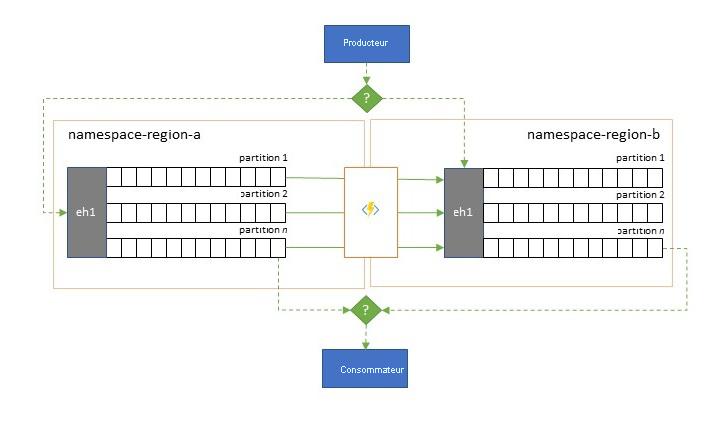
Bien que la disponibilité et la fiabilité maximales soient les principales priorités opérationnelles des Event Hubs, il existe néanmoins de nombreuses raisons pour lesquelles un producteur ou un consommateur peut être incapable de communiquer avec le « principal » Event Hubs qui lui a été attribué, en raison de problèmes de mise en réseau ou de résolution de noms ou pour lesquelles un Event Hubs ne répond temporairement plus ou renvoie des erreurs.
De telles conditions ne sont pas « désastreuses » au point de vouloir abandonner complètement le déploiement régional comme vous pourriez le faire dans une situation de récupération d’urgence, mais le scénario d’entreprise de certaines applications pourrait déjà être concerné par des événements de disponibilité qui ne durent pas plus de quelques minutes vo,ire quelques secondes.
Il existe deux modèles fondamentaux pour faire face à de tels scénarios :
- Le modèle de réplication consiste à répliquer le contenu d’un Event Hubs principal vers un Event Hubs secondaire. L’Event Hubs principal est généralement utilisé par l’application pour produire et consommer des événements et le hub secondaire sert d’option de secours au cas où Event Hubs principal ne serait plus disponible. La réplication étant unidirectionnelle, du hub principal au secondaire, un basculement des producteurs et des consommateurs d’un Event Hub principal indisponible vers le hub secondaire fera que l’ancien hub principal ne recevra plus de nouveaux événements et ne sera donc plus à jour. La réplication pure ne convient donc qu’aux scénarios de basculement unidirectionnel. Une fois le basculement effectué, l’ancien hub principal est abandonné et un nouveau Event Hubs secondaire doit être créé dans une autre région cible.
- Le modèle de fusion complète le modèle de réplication en effectuant une fusion continue du contenu de deux Event Hubs ou plus. Chaque événement initialement produit dans l’un des Event Hubs inclus dans le schéma est répliqué dans les autres Event Hubs. À mesure que les événements sont répliqués, ils sont annotés de telle sorte qu’ils sont ensuite ignorés par le processus de réplication de la cible de réplication. L’utilisation du modèle de fusion permet d’obtenir à terme deux Event Hubs ou plus qui contiendront le même ensemble d’événements de manière cohérente.
Dans les deux cas, le contenu des Event Hubs ne sera pas identique. Les événements provenant d’un même producteur et regroupés par la même clé de partition apparaîtront dans le même ordre relatif que ceux soumis à l’origine, mais l’ordre absolu des événements peut différer. Cela est particulièrement vrai pour les scénarios où le nombre de partitions des Event Hubs source et cible diffère, ce qui est souhaitable pour plusieurs des modèles étendus décrits ici. Un séparateur ou un routeur peut obtenir une tranche d’un Event Hubs beaucoup plus grand avec des centaines de partitions et la canaliser vers un Event Hubs plus petit avec seulement quelques partitions, ce qui est plus adapté pour traiter le sous-ensemble avec des ressources de traitement limitées. À l’inverse, une consolidation peut canaliser les données de plusieurs Event Hubs plus petits vers un seul Event Hubs plus grand, avec davantage de partitions, pour répondre aux besoins de traitement et de débit consolidés.
Le critère de regroupement des événements est la clé de partition et non l’ID de la partition d’origine. Vous trouverez plus d’informations sur l’ordre relatif et sur la façon d’effectuer un basculement d’un Event Hubs à un autre sans avoir recours à la même portée de décalage des flux dans la description du modèle de réplication.
Instructions :
Optimisation de la latence
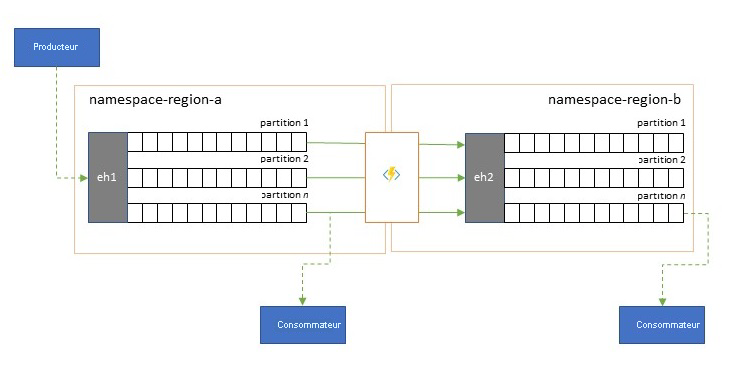
Les flux d’événements sont écrits une seule fois par les producteurs, mais peuvent être lus autant de fois que nécessaire par les consommateurs d’événements. Dans les scénarios où un flux d’événements dans une région est partagé par plusieurs consommateurs et doit être consulté à plusieurs reprises pendant le traitement analytique résidant dans une région différente, ou avec des demandes continues qui épuiseraient les consommateurs concurrents, il peut être avantageux de placer une copie du flux d’événements près du processeur analytique pour réduire la latence aller-retour.
Voici de bons exemples de situations où la réplication doit être privilégiée par rapport à la consommation d’événements provenant de régions éloignées, en particulier lorsque les régions sont très éloignées les unes des autres. Par exemple, l’Europe et l’Australie étant presque aux antipodes géographiquement, les latences de réseau peuvent facilement dépasser 250 ms pour un aller-retour. Il est impossible d’accélérer la vitesse de la lumière, mais vous pouvez réduire le nombre d’allers-retours à latence élevée pour interagir avec les données.
Instructions :
Validation, réduction et enrichissement
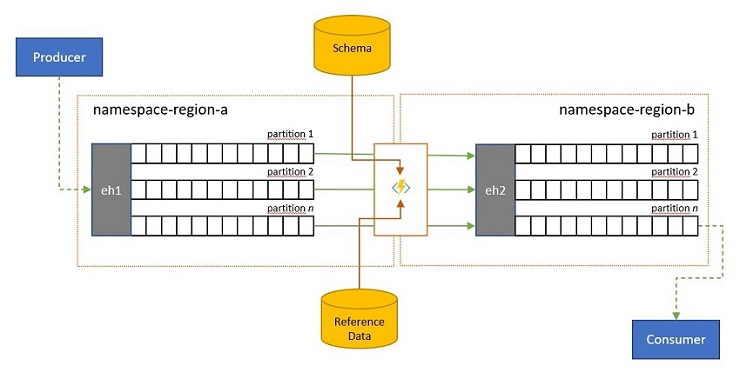
Les flux d’événements peuvent être envoyés à un Event Hubs par des clients externes à votre propre solution. Ces flux d’événements peuvent nécessiter la vérification de la conformité des événements envoyés en externe avec un schéma donné, ainsi que la suppression des événements non conformes.
Dans les scénarios où les clients disposent d’une bande passante extrêmement limitée, comme c’est le cas dans de nombreux scénarios « Internet des objets » avec une bande passante limitée, ou lorsque les événements sont initialement envoyés sur des réseaux non IP avec des tailles de paquets limitées, il peut être nécessaire d’enrichir les événements avec des données de référence pour ajouter un contexte supplémentaire afin de pouvoir être utilisés par les processeurs d’événements en aval.
Dans d’autres cas, en particulier lors de la consolidation des flux, il peut être nécessaire de réduire la complexité ou la taille des données d’événement en omettant certains détails.
Toutes ces opérations peuvent avoir lieu dans le cadre de la réplication, de la consolidation ou de la fusion des flux.
Instructions :
Intégration aux services d’analytique
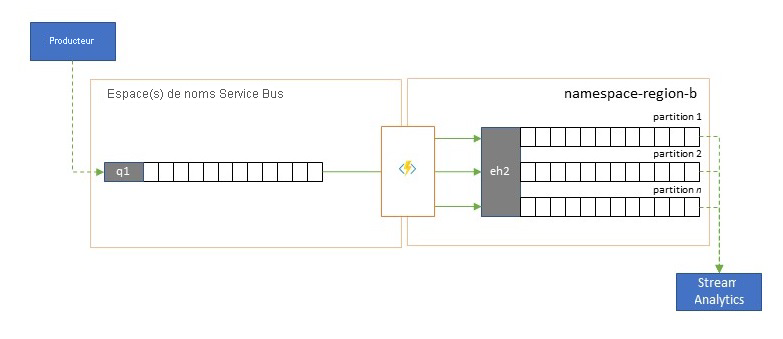
Plusieurs services d’analyse natifs Cloud d’Azure comme Azure Stream Analytics ou Azure Synapse fonctionnent mieux avec des données diffusées en continu ou prétraitées à partir d’Azure Event Hubs. Azure Event Hubs permet également l’intégration à plusieurs packages d’analyse open source tels qu’Apache Samza, Apache Flink, Apache Spark et Apache Storm.
Si votre solution utilise principalement Service Bus ou Event Grid, vous pouvez rendre ces événements facilement accessibles à ces systèmes d’analyse et les archiver avec Event Hubs Capture en les canalisant dans Event Hubs. Event Grid peut le faire de façon native grâce à son intégration Event Hub. Pour Service Bus, suivez l’aide de réplication Service Bus.
Azure Stream Analytics s’intègre directement à Event Hubs.
Instructions :
Consolidation et normalisation des flux d’événements
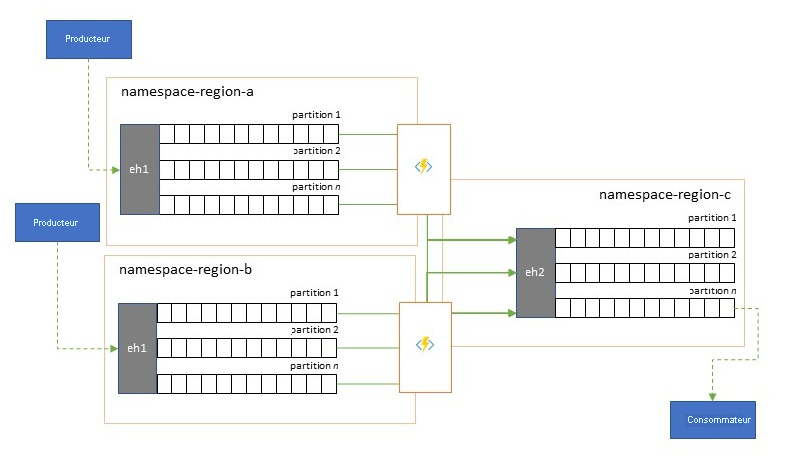
Les solutions mondiales sont souvent composées d’empreintes régionales qui sont largement indépendantes et qui ont notamment leurs propres capacités d’analyse, mais les perspectives d’analyse suprarégionales et mondiales nécessiteront une perspective intégrée. C’est pourquoi il convient de procéder à une consolidation centrale des mêmes flux d’événements qui sont évalués dans les empreintes régionales respectives pour la perspective locale.
La normalisation est une variante du scénario de consolidation, dans laquelle deux ou plusieurs flux d’événements entrants transportent le même type d’événements, mais avec des structures différentes ou des codages différents, et où les événements doivent être transcodés ou transformés avant de pouvoir être consommés.
La normalisation peut également inclure des travaux de chiffrement tels que le déchiffrement de charges utiles chiffrées de bout en bout, puis leur rechiffrement à l’aide de clés et d’algorithmes différents pour le public de consommateurs en aval.
Instructions :
Fractionnement et routage des flux d’événements
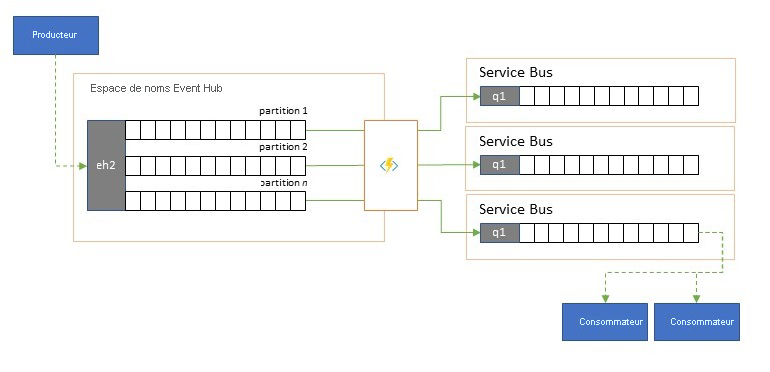
Azure Event Hubs est parfois utilisé dans des scénarios de type « publication-abonnement » où un torrent entrant d’événements ingérés dépasse de loin la capacité d’Azure Service Bus ou d’Azure Event Grid, qui ont tous les deux des capacités natives de filtrage et de distribution de publication et d’abonnement et sont privilégiés pour ce modèle.
Alors qu’une véritable capacité de « publication-abonnement » permet aux abonnés de choisir les événements de leur choix, le modèle de fractionnement prévoit que le producteur associe les événements à des partitions selon un modèle de distribution prédéterminé et que les consommateurs désignés extraient ensuite exclusivement à partir de « leur » partition. Event Hubs mettant en mémoire tampon le trafic global, le contenu d’une partition particulière, représentant une fraction du volume de débit d’origine, peut alors être reproduit dans une file d’attente pour une consommation fiable, transactionnelle et concurrentielle par les consommateurs.
Dans de nombreux scénarios où Azure Event Hubs est principalement utilisé pour déplacer des événements dans une application au sein d’une région, il arrive que certains événements, provenant peut-être d’une seule partition, doivent également être mis à disposition ailleurs. Ce scénario est similaire au scénario de découpage, mais il peut utiliser un routeur évolutif qui prend en compte tous les messages arrivant dans Event Hubs et opère un cherry-pick de quelques-uns pour un routage ultérieur et peut différencier les cibles de routage en fonction des métadonnées ou du contenu des événements.
Instructions :
Projections de journal
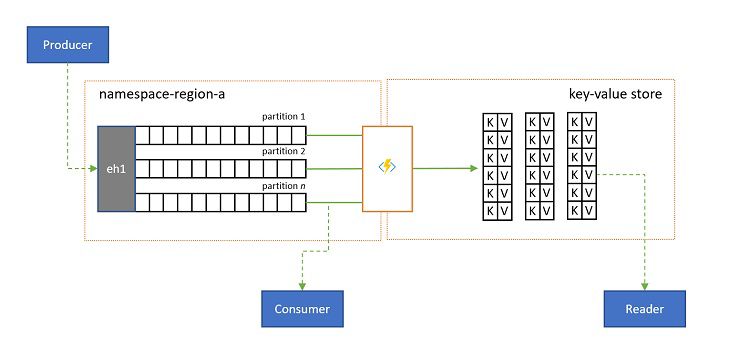
Dans certains scénarios, vous voudrez avoir accès à la dernière valeur envoyée pour tout sous-flux d’un événement, généralement distingué par la clé de partition. Dans Apache Kafka, cela est souvent possible en activant le « compactage du journal » sur une rubrique, qui ignore tous les événements sauf le plus récent étiqueté avec une clé unique. L’approche du compactage du journal présente trois inconvénients aggravants :
- Le compactage nécessite une réorganisation continue du journal, ce qui est une opération excessivement coûteuse pour un répartiteur, qui est optimisé pour les charges de travail en ajout seul.
- Le compactage est destructif et ne permet pas d’avoir une perspective compactée et non compactée du même flux.
- Un flux compacté possède toujours un modèle d’accès séquentiel, ce qui signifie que pour trouver la valeur souhaitée dans le journal, il faut lire le journal en entier dans le pire des cas, ce qui conduit généralement à des optimisations qui implémentent le même modèle présenté ici : la projection du contenu du journal dans une base de données ou un cache.
En fin de compte, un journal compacté est un magasin de paires clé-valeur et, par conséquent, il constitue la pire option d’implémentation possible pour un tel magasin. Il est bien plus efficace pour les recherches et les requêtes de créer et d’utiliser une projection permanente du journal sur un véritable magasin de paires clé-valeur ou sur une autre base de données.
Étant donné que les événements sont immuables et que l’ordre est toujours préservé dans un journal, toute projection d’un journal dans un magasin de paires clé-valeur sera toujours identique pour la même plage d’événements, ce qui signifie qu’une projection que vous tenez à jour fournit toujours une vue faisant autorité et qu’il n’y a jamais de bonne raison de la recréer à partir du contenu du journal une fois créée.
Instructions :
Technologies d’application de réplication
L’implémentation des modèles ci-dessus requiert un environnement d’exécution évolutif et fiable pour les tâches de réplication que vous souhaitez configurer et exécuter. Sur Azure, les environnements de runtime les plus adaptés à ces tâches sont les tâches sans état, à savoir Azure Stream Analytics pour les tâches de réplication de flux avec état et Azure Functions pour les tâches de réplication sans état.
Applications de réplication avec état dans Azure Stream Analytics
Pour les applications de réplication avec état qui doivent prendre en compte les relations entre les événements, créer des événements composites, enrichir ou réduire les événements, créer des agrégats de données et transformer des charges utiles d’événements, Azure Stream Analytics est la meilleure option d’implémentation.
Dans Azure Stream Analytics, vous créez des travaux qui intègrent des entrées et des sorties et intégrez les données des entrées au moyen de requêtes qui donnent un résultat qui est ensuite mis à disposition sur les sorties.
Les requêtes sont basées sur le langage de requête SQL et peuvent être utilisées pour filtrer, trier, agréger et joindre facilement des données de streaming sur une période de temps donnée. Vous pouvez également étendre ce langage SQL avec des fonctions définies par l’utilisateur en C# et en JavaScript. Vous pouvez facilement modifier les options d’ordre des événements et la durée des fenêtres de temps lors des opérations d’agrégation via de simples constructions et/ou configurations de langage.
Chaque travail a une ou plusieurs sorties pour les données transformées, et vous pouvez définir ce qui arrive en fonction des informations que vous avez analysées. Vous pouvez par exemple :
- Envoyez des données à des services tels qu’Azure Functions ou Rubriques/Files d'attente Service Bus pour déclencher des communications ou flux de travail personnalisés en aval.
- Envoyer des données à un tableau de bord Power BI pour un tableau de bord en temps réel.
- Stocker des données dans d’autres services de stockage Azure (par exemple, Azure Data Lake, Azure Synapse Analytics, etc.) pour effectuer des analyses par lots ou effectuer l’apprentissage d’un modèle Machine Learning basé sur de très grands pools indexés de données historiques.
- Projections de magasin (également appelées « vues matérialisées ») dans des bases de données (SQL Database, Azure Cosmos DB).
Applications de réplication sans état dans Azure Functions
Pour les tâches de réplication sans état où vous souhaitez transférer des événements sans tenir compte de leurs charges utiles ou les traiter séparément sans avoir à considérer les relations des événements (à l’exception de leur ordre relatif), vous pouvez utiliser Azure Functions, qui offre une très grande flexibilité.
Azure Functions dispose de déclencheurs et de liens de sortie préconstruits et évolutifs pour Azure Event Hubs, Azure IoT Hub, Azure Service Bus, Azure Event Grid et Stockage File d’attente Azure, ainsi que d’extensions personnalisées pour RabbitMQ et Apache Kafka. La plupart des déclencheurs s’adaptent de manière dynamique aux besoins de débit en mettant à l’échelle le nombre d’instances exécutées simultanément sur la base des métriques documentées.
Pour générer des projections de journal, Azure Functions prend en charge les liaisons de sortie pour Azure Cosmos DB et Stockage Table Azure.
Azure Functions peut s’exécuter sous une identité managée Azure et, grâce à cela, il peut conserver les valeurs de configuration des informations d’identification dans un stockage dont l’accès est étroitement contrôlé à l’intérieur d’Azure Key Vault.
De plus, Azure Functions permet aux tâches de réplication de s’intégrer directement aux réseaux virtuels Azure et aux points de terminaison de service pour tous les services de messagerie Azure, et il est facilement intégré à Azure Monitor.
Grâce au plan de consommation d’Azure Functions, les déclencheurs prédéfinis peuvent même être réduits à zéro alors qu’aucun message n’est disponible pour la réplication, ce qui signifie qu’aucuns frais ne vous sont facturés pour garder la configuration prête à une mise à l’échelle. Le principal inconvénient de l’utilisation du plan de consommation est que la latence des tâches de réplication sortant de cet état est nettement plus élevée qu’avec les plans d’hébergement où l’infrastructure est maintenue en fonctionnement.
En revanche, la plupart des moteurs de réplication de messagerie et d’événements, tels que MirrorMaker d’Apache Kafka, nécessitent que vous fournissiez un environnement d’hébergement et que vous mettiez vous-même le moteur de réplication à l’échelle. Cela comprend la configuration et l’intégration des fonctionnalités de sécurité et de mise en réseau et la facilitation du flux des données de surveillance, et vous n’avez toujours pas la possibilité d’injecter des tâches de réplication personnalisées dans le flux.
Choix entre Azure Functions et Azure Stream Analytics
Azure Stream Analytics (ASA) est la meilleure option chaque fois que vous devez traiter la charge utile de vos événements tout en les reproduisant. ASA peut copier les événements un par un ou il peut créer des agrégats qui condensent les informations des flux d’événements avant de les transférer. Il peut facilement s’appuyer sur des données de référence complémentaires conservées dans Stockage Blob Azure ou Azure SQL Database sans avoir à importer ces données dans un flux.
Avec ASA, vous pouvez facilement créer des vues matérialisées et persistantes des flux dans des bases de données à grande échelle. Il s’agit d’une approche beaucoup plus efficace que l’imposant modèle de « compactage de journal » d’Apache Kafka et que les projections volatiles de tables côté client de Kafka Streams.
ASA peut facilement traiter des événements dont les charges utiles sont encodées dans les formats CSV, JSON et Apache Avro, et vous pouvez brancher des désérialiseurs personnalisés pour tout autre format.
Pour toutes les tâches de réplication où vous souhaitez copier des flux d’événements « tels quels » et sans toucher aux charges utiles, si vous devez implémenter un routeur, effectuer des opérations de chiffrement ou modifier l’encodage des charges utiles ou si vous avez besoin d’un contrôle total sur le contenu des flux de données, Azure Functions est la meilleure option.
Étapes suivantes
Dans cet article, nous avons exploré un éventail de modèles de fédération et expliqué le rôle d’Azure Functions en tant que runtime de réplication d’événements et de messages dans Azure.
Ensuite, vous voudrez peut-être lire comment configurer une application de réplication avec Azure Stream Analytics ou Azure Functions, puis comment répliquer des flux d’événements entre Event Hubs et divers autres systèmes de messagerie et d’événements :
- Modèles de tâches de réplication des événements
- Traiter des données avec Azure Stream Analytics
- Applications de réplication d’événements dans Azure Functions
- Réplication d’événements entre Event Hubs
- Réplication d’événements sur Azure Service Bus
- Utilisation d’Apache Kafka MirrorMaker avec Event Hubs
Commentaires
Bientôt disponible : Tout au long de l’année 2024, nous abandonnerons progressivement le mécanisme de retour d’information GitHub Issues pour le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour