Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
S'applique uniquement à :![]() Portail Foundry (classique). Cet article n’est pas disponible pour le nouveau portail Foundry.
En savoir plus sur le nouveau portail.
Portail Foundry (classique). Cet article n’est pas disponible pour le nouveau portail Foundry.
En savoir plus sur le nouveau portail.
Découvrez comment afficher les résultats de trace qui fournissent une visibilité sur l’exécution d’applications IA. Utilisez des traces pour diagnostiquer les appels d’outils incorrects, les messages trompeurs, les problèmes de latence, et les scores faibles d'évaluation.
Dans cet article, vous allez apprendre à :
- Activez le suivi pour un project.
- Instrumentez le Kit de développement logiciel (SDK) OpenAI.
- Capturer le contenu du message (facultatif).
- Affichez les lignes de temps et les intervalles de trace.
- Connectez le suivi avec des boucles d’évaluation.
Cet article explique comment afficher les résultats de trace pour les applications IA à l’aide du Kit de développement logiciel (SDK) OpenAI avec OpenTelemetry dans Microsoft Foundry.
Prerequisites
Vous avez besoin des éléments suivants pour suivre ce tutoriel :
Un projet Foundry a été créé.
Application IA qui utilise le Kit de développement logiciel (SDK) OpenAI pour effectuer des appels aux modèles hébergés dans Foundry.
Activer le suivi dans votre project
Foundry stocke les traces dans Azure Application Insights à l’aide d’OpenTelemetry. Les nouvelles ressources ne provisionnent pas Application Insights automatiquement. Associez (ou créez) une ressource une seule fois par ressource Foundry.
Les étapes suivantes montrent comment configurer votre ressource :
Accédez au portail Foundry et accédez à votre projet.
Dans la barre de navigation latérale, sélectionnez Traçage.
Si une ressource Azure Application Insights n'est pas associée à votre ressource Foundry, associez-en une. Si vous disposez déjà d’une ressource Application Insights associée, vous ne voyez pas la page d’activation ci-dessous et vous pouvez ignorer cette étape.
capture d’écran
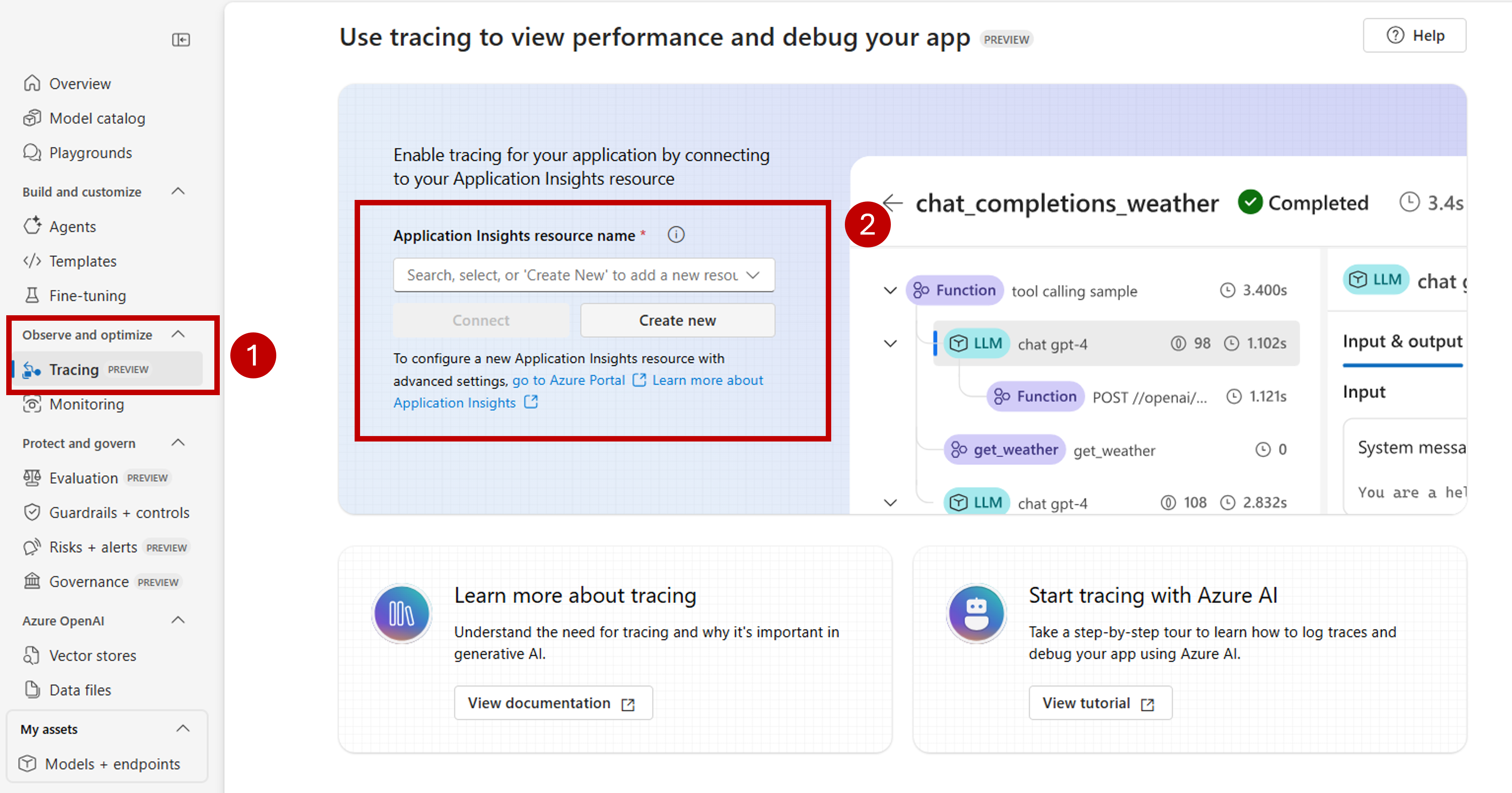
Pour réutiliser un Azure Application Insights existant, utilisez le nom de la ressource Application Insights pour localiser la ressource et sélectionner Connect.
Conseil / Astuce
Pour vous connecter à une application Azure Insights existante, vous devez avoir au moins un accès de contributeur à la ressource Foundry (ou Hub).
Pour vous connecter à une nouvelle ressource Azure Application Insights, sélectionnez l’option Create new.
Utilisez l’Assistant Configuration pour configurer le nom de la nouvelle ressource.
Par défaut, la nouvelle ressource est créée dans le même groupe de ressources que celui où la ressource Foundry a été créée. Utilisez l’option Paramètres avancés pour configurer un autre groupe de ressources ou abonnement.
Conseil / Astuce
Pour créer une ressource Azure Application Insights, vous avez également besoin d’un rôle contributeur au groupe de ressources que vous avez sélectionné (ou celui par défaut).
Sélectionnez Créer pour créer la ressource et la connecter à la ressource Foundry.
Une fois la connexion configurée, vous êtes prêt à utiliser le suivi dans n'importe quel project dans la ressource.
Conseil / Astuce
Assurez-vous que le rôle Log Analytics Reader est attribué à votre ressource Application Insights. Pour en savoir plus sur l’attribution de rôles, consultez Assigner des rôles Azure à l’aide du Azure portal. Utilisez les groupes Microsoft Entra pour gérer plus facilement les accès pour les utilisateurs.
Accédez à la page d'accueil de votre project et copiez l'URI de point de terminaison du project. Vous en aurez besoin ultérieurement.
Une capture d’écran montrant comment copier l’URI du point de terminaison du projet.
Important
L'utilisation du point de terminaison d'un project nécessite la configuration de Microsoft Entra ID dans votre application. Si vous n'avez pas configuré l'ID Entra, utilisez la chaîne de connexion Azure Application Insights comme indiqué à l'étape 3 du didacticiel.

Afficher les résultats de trace dans le portail Foundry
Une fois le suivi configuré et que votre application est instrumentée, vous pouvez afficher les résultats de trace dans le portail Foundry :
Accédez au portail Foundry et accédez à votre projet.
Dans la barre de navigation latérale, sélectionnez Traçage.
Vous verrez une liste des résultats de suivi de vos applications instrumentées. Chaque trace montre :
- ID de trace : identificateur unique pour la trace
- Heure de début : lorsque la trace a commencé
- Durée : durée de l’opération
- État : État de réussite ou d’échec
- Opérations : nombre de segments dans la trace
Sélectionnez une trace pour afficher les résultats de trace détaillés, notamment :
- Chronologie d’exécution complète
- Données d’entrée et de sortie pour chaque opération
- Métriques et minutage des performances
- Détails de l’erreur s’il s’est produit
- Attributs et métadonnées personnalisés
Instrumenter le Kit de développement logiciel (SDK) OpenAI
Lors du développement avec le Kit de développement logiciel (SDK) OpenAI, vous pouvez instrumenter votre code afin que les traces soient envoyées à Foundry. Procédez comme suit pour instrumenter votre code :
Installer des packages :
pip install azure-ai-projects azure-monitor-opentelemetry opentelemetry-instrumentation-openai-v2(Facultatif) Capturer le contenu du message :
- PowerShell :
setx OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT true - Bash :
export OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=true
- PowerShell :
Obtenez la chaîne de connexion de la ressource Application Insights liée (Projet > Suivi > Gérer la source de données > Chaîne de connexion) :
from azure.ai.projects import AIProjectClient from azure.identity import DefaultAzureCredential project_client = AIProjectClient( credential=DefaultAzureCredential(), endpoint="https://<your-resource>.services.ai.azure.com/api/projects/<your-project>", ) connection_string = project_client.telemetry.get_application_insights_connection_string()Configurez Azure Monitor et instrumentez le Kit de développement logiciel (SDK) OpenAI :
from azure.monitor.opentelemetry import configure_azure_monitor from opentelemetry.instrumentation.openai_v2 import OpenAIInstrumentor configure_azure_monitor(connection_string=connection_string) OpenAIInstrumentor().instrument()Envoyez une requête :
client = project_client.get_openai_client() response = client.chat.completions.create( model="gpt-4o-mini", messages=[{"role": "user", "content": "Write a short poem on open telemetry."}], ) print(response.choices[0].message.content)Revenez au traçage dans le portail pour afficher les nouvelles traces.
Il pourrait être utile de capturer des sections de votre code qui combinent une logique métier avec des modèles lors du développement d’applications complexes. OpenTelemetry utilise le concept d’étendues pour capturer les sections qui vous intéressent. Pour commencer à générer vos propres étendues, obtenez une instance de l’objet de suivi en cours.
from opentelemetry import trace tracer = trace.get_tracer(__name__)Ensuite, utilisez des décorateurs dans votre méthode pour capturer des scénarios spécifiques utiles dans votre code. Ces décorateurs génèrent automatiquement des intervalles. L’exemple de code suivant instrumente une méthode appelée
assess_claims_with_contextqui itère sur une liste de revendications et vérifie si la revendication est prise en charge par le contexte en utilisant un LLM. Tous les appels effectués dans cette méthode sont capturés dans la même étendue :def build_prompt_with_context(claim: str, context: str) -> str: return [{'role': 'system', 'content': "I will ask you to assess whether a particular scientific claim, based on evidence provided. Output only the text 'True' if the claim is true, 'False' if the claim is false, or 'NEE' if there's not enough evidence."}, {'role': 'user', 'content': f""" The evidence is the following: {context} Assess the following claim on the basis of the evidence. Output only the text 'True' if the claim is true, 'False' if the claim is false, or 'NEE' if there's not enough evidence. Do not output any other text. Claim: {claim} Assessment: """}] @tracer.start_as_current_span("assess_claims_with_context") def assess_claims_with_context(claims, contexts): responses = [] for claim, context in zip(claims, contexts): response = client.chat.completions.create( model="gpt-4.1", messages=build_prompt_with_context(claim=claim, context=context), ) responses.append(response.choices[0].message.content.strip('., ')) return responsesLes résultats de la trace se présentent comme suit :
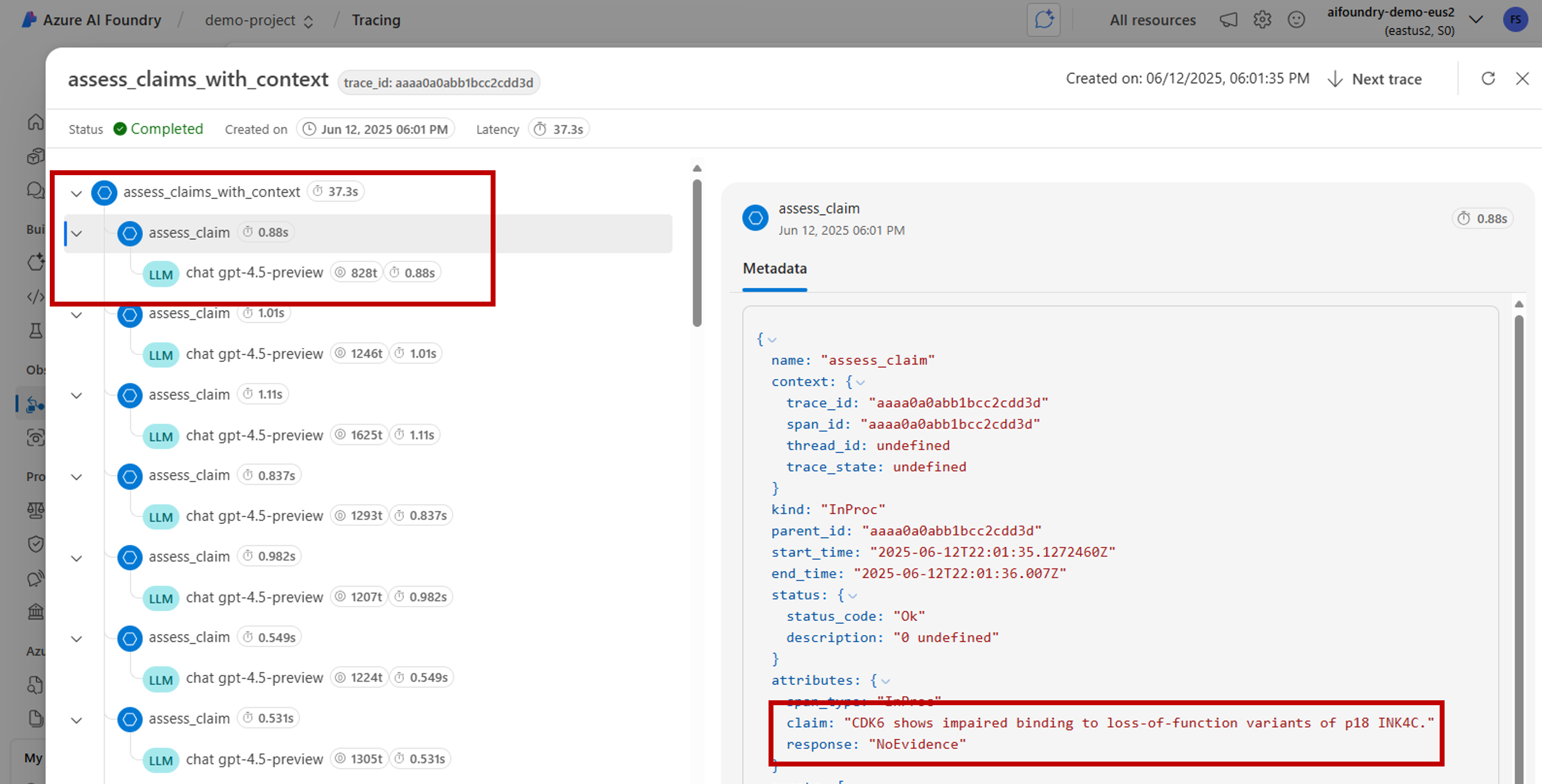
Vous pouvez également ajouter des informations supplémentaires à l’intervalle actuel. OpenTelemetry utilise le concept des attributs pour cela. Utilisez l’objet
tracepour accéder à ceux-ci et à inclure des informations supplémentaires. Découvrez comment laassess_claims_with_contextméthode a été modifiée pour inclure un attribut :@tracer.start_as_current_span("assess_claims_with_context") def assess_claims_with_context(claims, contexts): responses = [] current_span = trace.get_current_span() current_span.set_attribute("operation.claims_count", len(claims)) for claim, context in zip(claims, contexts): response = client.chat.completions.create( model="gpt-4.1", messages=build_prompt_with_context(claim=claim, context=context), ) responses.append(response.choices[0].message.content.strip('., ')) return responses


Suivi de la console
Il pourrait être utile de tracer également votre application et d’envoyer les traces à la console d’exécution locale. Il est possible que cette approche soit utile lors de l’exécution de tests unitaires ou de tests d’intégration dans votre application en tirant parti d’un pipeline CI/CD automatisé. Les traces peuvent être envoyées à la console et capturées par votre outil CI/CD pour obtenir une analyse plus approfondie.
Configurez le suivi comme suit :
Instrumentez le Kit de développement logiciel (SDK) OpenAI comme d’habitude :
from opentelemetry.instrumentation.openai_v2 import OpenAIInstrumentor OpenAIInstrumentor().instrument()Configurez OpenTelemetry pour envoyer des traces à la console :
from opentelemetry import trace from opentelemetry.sdk.trace import TracerProvider from opentelemetry.sdk.trace.export import SimpleSpanProcessor, ConsoleSpanExporter span_exporter = ConsoleSpanExporter() tracer_provider = TracerProvider() tracer_provider.add_span_processor(SimpleSpanProcessor(span_exporter)) trace.set_tracer_provider(tracer_provider)Utilisez le Kit de développement logiciel (SDK) OpenAI comme d’habitude :
response = client.chat.completions.create( model="deepseek-v3-0324", messages=[ {"role": "user", "content": "Write a short poem on open telemetry."}, ], ){ "name": "chat deepseek-v3-0324", "context": { "trace_id": "0xaaaa0a0abb1bcc2cdd3d", "span_id": "0xaaaa0a0abb1bcc2cdd3d", "trace_state": "[]" }, "kind": "SpanKind.CLIENT", "parent_id": null, "start_time": "2025-06-13T00:02:04.271337Z", "end_time": "2025-06-13T00:02:06.537220Z", "status": { "status_code": "UNSET" }, "attributes": { "gen_ai.operation.name": "chat", "gen_ai.system": "openai", "gen_ai.request.model": "deepseek-v3-0324", "server.address": "my-project.services.ai.azure.com", "gen_ai.response.model": "DeepSeek-V3-0324", "gen_ai.response.finish_reasons": [ "stop" ], "gen_ai.response.id": "aaaa0a0abb1bcc2cdd3d", "gen_ai.usage.input_tokens": 14, "gen_ai.usage.output_tokens": 91 }, "events": [], "links": [], "resource": { "attributes": { "telemetry.sdk.language": "python", "telemetry.sdk.name": "opentelemetry", "telemetry.sdk.version": "1.31.1", "service.name": "unknown_service" }, "schema_url": "" } }
Trace localement avec AI Toolkit
AI Toolkit offre un moyen simple de suivre localement dans VS Code. Il utilise un collecteur compatible OTLP local, ce qui le rend parfait pour le développement et le débogage sans avoir besoin de access cloud.
Le kit de ressources prend en charge le Kit de développement logiciel (SDK) OpenAI et d’autres frameworks IA via OpenTelemetry. Vous pouvez voir instantanément les traces dans votre environnement de développement.
Pour obtenir des instructions d’installation détaillées et des exemples de code spécifiques au Kit de développement logiciel (SDK), consultez Suivi dans AI Toolkit.