Qu’est-ce qu’Apache Hadoop dans Azure HDInsight ?
Apache Hadoop était l’infrastructure open source d’origine de traitement et d’analyse distribués des jeux de données volumineuses sur des clusters. L’écosystème Hadoop comprend des logiciels et des utilitaires associés, notamment Apache Hive, Apache HBase, Spark, Kafka et bien d’autres encore.
Azure HDInsight est un service cloud d’analytique complètement managé, exhaustif et open source pour les entreprises. Le type de cluster Apache Hadoop dans Azure HDInsight vous permet d’utiliser Apache Hadoop Distributed File System (HDFS), la gestion des ressources Apache Hadoop YARN ainsi qu’un modèle de programmation MapReduce simple pour traiter et analyser des lots de données en parallèle. Les clusters Hadoop dans HDInsight sont compatibles avec Azure Data Lake Storage Gen2.
Pour voir les piles de composants de technologie Hadoop disponibles sur HDInsight, consultez Composants et versions disponibles avec HDInsight. Pour plus d’informations sur Hadoop dans HDInsight, consultez la rubrique Page de fonctionnalités Azure pour HDInsight.
Présentation de MapReduce
Apache Hadoop MapReduce est une infrastructure logicielle qui permet d’écrire des tâches traitant d’importantes quantités de données. Les données d’entrée sont fractionnées en blocs indépendants. Chaque bloc est traité en parallèle sur les nœuds de votre cluster. Une tâche MapReduce se compose de deux fonctions :
Mappeur: il consomme les données d'entrée, les analyse (généralement avec les opérations de tri et de filtre) et émet des tuples (paires clé-valeur)
Raccord de réduction: il consomme les tuples émis par le Mappeur et effectue une opération de synthèse qui crée un résultat plus petit, combiné à partir des données du Mappeur
Un exemple de tâche MapReduce de comptage de mots de base est illustré dans le diagramme suivant :
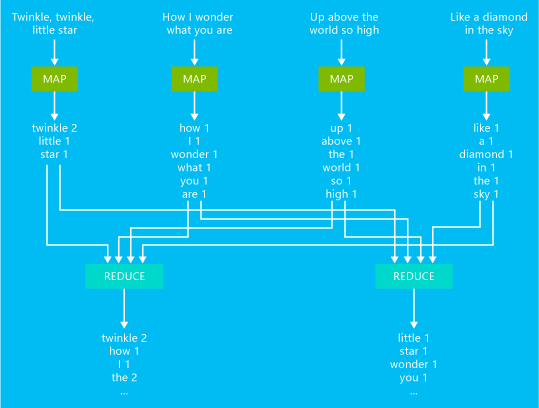
Le résultat de ce travail indique le nombre d’occurrences de chaque mot dans le texte.
- Le mappeur prend chaque ligne du texte saisi en tant qu'entrée, et la divise en mots. Il émet une paire clé/valeur pour chaque occurrence de mot ou si le mot est suivi d’un 1. Le résultat est trié avant d'être envoyé au raccord de réduction.
- Ce dernier calcule la somme du compte de mots, puis émet une seule paire clé/valeur contenant le mot défini, suivi par la somme de ses occurrences.
MapReduce peut être implémenté dans plusieurs langues. Java est l'implémentation la plus courante. Ce langage est utilisé à titre d’exemple dans ce document.
Langues de développement
Les langages ou frameworks basés sur Java et la Machine virtuelle Java peuvent être directement exécutés comme une tâche MapReduce. L’exemple utilisé dans ce document est une application Java MapReduce. Les langages autres que Java, comme C#, Python ou des exécutables autonomes, doivent utiliser la diffusion en continu Hadoop.
La diffusion en continu Hadoop communique avec le mappeur et le raccord de réduction via STDIN et STDOUT. Le mappeur et le raccord de réduction lisent les données ligne par ligne depuis STDIN et écrivent la sortie dans STDOUT. Chaque ligne lue ou émise par le mappeur et le raccord de réduction doit être au format d’une paire clé / valeur, délimitée par un caractère de tabulation :
[key]\t[value]
Pour plus d’informations, consultez Diffusion en continu Hadoop.
Pour obtenir des exemples d’utilisation de diffusion en continu Hadoop avec HDInsight, consultez le document suivant :
Par où commencer ?
- Démarrage rapide : créer un cluster Apache Hadoop dans Azure HDInsight à l’aide du portail Azure
- Tutoriel : Envoyer des tâches Apache Hadoop dans HDInsight
- Développer des programmes MapReduce Java pour Apache Hadoop sur HDInsight
- Utiliser Apache Hive comme un outil d’extraction, de transformation et de chargement (ETL)
- Extraire, transformer et charger (ETL) à l’échelle
- Rendre un pipeline d’analytique de données opérationnel