Déployer un modèle en tant que point de terminaison en ligne
S’APPLIQUE À :  Kit de développement logiciel (SDK) Python azure-ai-ml v2 (actuelle)
Kit de développement logiciel (SDK) Python azure-ai-ml v2 (actuelle)
Découvrez comment déployer un modèle sur un point de terminaison en ligne à l’aide du Kit de développement logiciel (SDK) Python Azure Machine Learning v2.
Dans ce tutoriel, vous déployez et utilisez un modèle qui prédit la probabilité de défaut de paiement par carte de crédit d’un client.
Voici les étapes à suivre :
- Inscrire votre modèle
- Créer un point de terminaison et un premier déploiement
- Déployer une version d’évaluation
- Envoyer manuellement des données de test au déploiement
- Obtenir les détails du déploiement
- Créer un deuxième déploiement
- Mettre manuellement à l’échelle le deuxième déploiement
- Mettre à jour l’allocation du trafic de production entre les deux déploiements
- Obtenir les détails du deuxième déploiement
- Déployer le nouveau déploiement et supprimer le premier
Cette vidéo montre comment bien démarrer dans Azure Machine Learning Studio pour pouvoir suivre les étapes du tutoriel. La vidéo montre comment créer un notebook, créer une instance de calcul et cloner le notebook. Les étapes sont également décrites dans les sections suivantes.
Prérequis
-
Vous avez besoin d’un espace de travail pour utiliser Azure Machine Learning. Si vous n’en avez pas, suivez la procédure Créer les ressources nécessaires pour commencer pour créer un espace de travail et en savoir plus sur son utilisation.
Important
Si votre espace de travail Azure Machine Learning est configuré avec un réseau virtuel managé, vous devrez peut-être ajouter des règles de trafic sortant pour autoriser l’accès aux référentiels publics de packages Python. Pour plus d’informations, consulter Scénario : accéder aux packages Machine Learning publics.
-
Connectez-vous au studio et sélectionnez votre espace de travail s’il n’est pas déjà ouvert.
-
Ouvrez ou créez un notebook dans votre espace de travail :
- Si vous souhaitez copier et coller du code dans des cellules, créez un notebook.
- Sinon, ouvrez tutorials/get-started-notebooks/deploy-model.ipynb dans la section Exemples du studio. Sélectionnez ensuite Cloner pour ajouter le notebook à vos fichiers. Pour trouver des exemples de notebooks, consultez Apprendre avec des exemples de notebooks.
Vérifiez si votre quota de machines virtuelles est suffisant pour créer des déploiements en ligne. Dans ce tutoriel, vous avez besoin d’au moins 8 cœurs
STANDARD_DS3_v2et 12 cœursSTANDARD_F4s_v2. Pour vérifier le quota de machines virtuelles que vous utilisez et demander éventuellement des augmentations de quota, consultez Gérer les quotas de ressources.
Définir votre noyau et ouvrir dans Visual Studio Code (VS Code)
Dans la barre supérieure au-dessus de votre notebook ouvert, créez une instance de calcul si vous n’en avez pas déjà une.

Si l’instance de calcul est arrêtée, sélectionnez Démarrer le calcul et attendez qu’elle s’exécute.

Attendez que l’instance de calcul soit en cours d’exécution. Vérifiez ensuite que le noyau, situé en haut à droite, est
Python 3.10 - SDK v2. Si ce n’est pas le cas, utilisez la liste déroulante pour sélectionner ce noyau.
Si vous ne voyez pas ce noyau, vérifiez que votre instance de calcul est en cours d’exécution. S’il est présent, sélectionnez le bouton Actualiser en haut à droite du notebook.
Si une bannière vous indique que vous devez être authentifié, sélectionnez Authentifier.
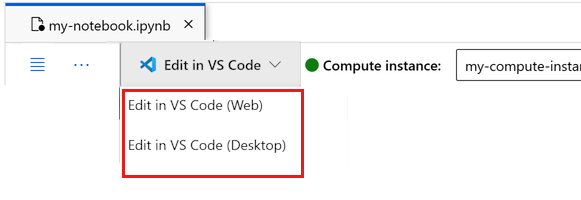
Vous pouvez exécuter le notebook ici, ou l’ouvrir dans VS Code pour un environnement de développement intégré (IDE) complet avec la puissance des ressources Azure Machine Learning. Sélectionnez Ouvrir dans VS Code, puis l’option web ou de bureau. Lors d’un tel lancement, VS Code est attaché à votre instance de calcul, au noyau et au système de fichiers de l’espace de travail.




Important
Le reste de ce tutoriel contient des cellules du notebook du tutoriel. Copiez-les et collez-les dans votre nouveau notebook, ou accédez maintenant au notebook si vous l’avez cloné.
Remarque
- Le calcul Serverless Spark n’a pas
Python 3.10 - SDK v2installé par défaut. Nous vous recommandons de créer une instance de calcul et de la sélectionner avant de poursuivre le tutoriel.
Créer un descripteur vers l’espace de travail
Avant de vous lancer dans la rédaction du code, il faut trouver un moyen de référencer l’espace de travail. Créez un ml_client pour un descripteur dans l’espace de travail et utilisez le ml_client pour gérer les ressources et les tâches.
Dans la cellule suivante, entrez votre ID d’abonnement, le nom du groupe de ressources et le nom de l’espace de travail. Pour rechercher ces valeurs :
- Dans la barre d’outils supérieure droite d’Azure Machine Learning Studio, sélectionnez le nom de votre espace de travail.
- Copiez la valeur de l’espace de travail, du groupe de ressources et de l’ID d’abonnement dans le code.
- Vous devez copier une valeur, fermer la zone et coller, puis revenir pour la suivante.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Remarque
Le fait de créer MLClient n’établit pas de connexion à l’espace de travail. L’initialisation du client est tardive et intervient la première fois qu’il doit passer un appel (ce qui arrive dans la prochaine cellule de code).
Inscrire le modèle
Si vous avez déjà effectué le précédent tutoriel sur la formation, Effectuer l’apprentissage d’un modèle, vous avez inscrit un modèle MLflow dans le script de formation. Vous pouvez donc passer à la section suivante.
Si vous n’avez pas effectué le tutoriel sur la formation, vous devez inscrire le modèle. Inscrire le modèle avant le déploiement est une bonne pratique que nous recommandons.
Le code suivant spécifie le path (l’emplacement à partir duquel charger les fichiers) inclus. Si vous avez cloné le dossier tutorials, exécutez le code suivant en l’état. Sinon, téléchargez les fichiers et les métadonnées du modèle à partir du dossier credit_defaults_model. Enregistrez les fichiers téléchargés dans une version locale du dossier credit_defaults_model sur votre ordinateur et mettez à jour dans le code suivant le chemin d’accès vers l’emplacement des fichiers téléchargés.
Le SDK charge automatiquement les fichiers et inscrit le modèle.
Pour plus d’informations sur l’enregistrement de votre modèle en tant que ressource, consultez Enregistrer votre modèle en tant que ressource dans Machine Learning à l’aide du SDK.
# Import the necessary libraries
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
# Provide the model details, including the
# path to the model files, if you've stored them locally.
mlflow_model = Model(
path="./deploy/credit_defaults_model/",
type=AssetTypes.MLFLOW_MODEL,
name="credit_defaults_model",
description="MLflow Model created from local files.",
)
# Register the model
ml_client.models.create_or_update(mlflow_model)
Vérifier que le modèle est inscrit
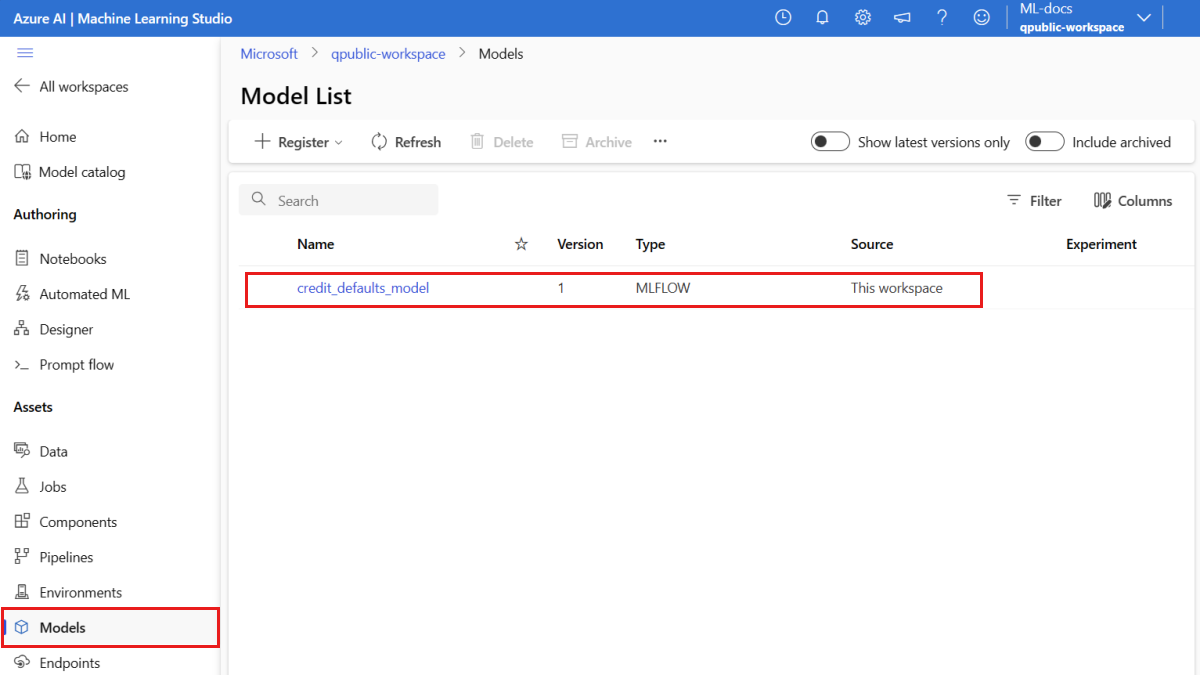
Vous pouvez consulter la page Modèles dans Azure Machine Learning studio pour identifier la dernière version du modèle inscrit.
En guise d’alternative, le code suivant récupère le numéro de la version la plus récente à utiliser.
registered_model_name = "credit_defaults_model"
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(latest_model_version)
Maintenant que vous avez un modèle inscrit, vous pouvez créer un point de terminaison et un déploiement. La section suivante aborde brièvement quelques points clés sur ces sujets.
Points de terminaison et déploiements
Après avoir entraîné un modèle Machine Learning, vous devez le déployer pour que d’autres utilisateurs puissent s’en servir pour l’inférence. À cette fin, Azure Machine Learning vous permet de créer des points de terminaison et d’y ajouter des déploiements.
Dans ce contexte, un point de terminaison est un chemin HTTPS qui fournit une interface qui permet aux clients d’envoyer des requêtes (données d’entrée) à un modèle formé et de recevoir les résultats d’inférence (scoring) du modèle. Un point de terminaison fournit :
- Authentification basée sur la méthode « clé ou jeton »
- Terminaison TLS(SSL)
- Un URI de scoring stable (nom-point-de-terminaison.region.inference.ml.azure.com)
Un déploiement est un ensemble de ressources nécessaires pour héberger le modèle qui effectue l’inférence réelle.
Un point de terminaison unique peut contenir plusieurs déploiements. Les points de terminaison et les déploiements sont des ressources Azure Resource Manager indépendantes présentées dans le portail Azure.
Azure Machine Learning vous permet d’implémenter des points de terminaison en ligne pour effectuer une inférence en temps réel sur des données clientes, et des points de terminaison de traitement par lots pour effectuer une inférence sur de grands volumes de données sur une période donnée.
Dans ce tutoriel, vous suivez les étapes d’implémentation d’un point de terminaison en ligne managé. Les points de terminaison en ligne managés fonctionnent de manière scalable et complètement managée avec des machines équipées de processeurs et de GPU puissants dans Azure, lequel vous libère des contraintes de configuration et de gestion de l’infrastructure de déploiement sous-jacente.
Créez un point de terminaison en ligne
Maintenant que vous avez un modèle inscrit, le moment est venu de créer votre point de terminaison en ligne. Le nom du point de terminaison doit être unique dans toute la région Azure. Pour ce tutoriel, vous créez un nom unique en utilisant un identificateur unique universel UUID. Pour obtenir plus d’informations sur les règles d’affectation de noms des points de terminaison, consultez les limites de point de terminaison.
import uuid
# Create a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Tout d’abord, définissez le point de terminaison en utilisant la classe ManagedOnlineEndpoint.
Conseil
auth_mode: utilisezkeypour l’authentification basée sur une clé. Utilisezaml_tokenpour l’authentification Azure Machine Learning basée sur les jetons.keyn’expire pas, maisaml_tokenexpire. Pour plus d’informations sur l’authentification, consultez Authentifier les clients pour les points de terminaison en ligne.Vous pouvez éventuellement ajouter une description et des étiquettes à votre point de terminaison.
from azure.ai.ml.entities import ManagedOnlineEndpoint
# define an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
},
)
En utilisant le MLClient créé précédemment, créez le point de terminaison dans l’espace de travail. Cette commande lance la création du point de terminaison et retourne une réponse de confirmation, pendant que la création du point de terminaison se poursuit.
Remarque
Attendez-vous à ce que la création du point de terminaison prenne environ 2 minutes.
# create the online endpoint
# expect the endpoint to take approximately 2 minutes.
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Une fois le point de terminaison créé, vous pouvez le récupérer comme suit :
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Compréhension des déploiements en ligne
Les principaux aspects d’un déploiement sont les suivants :
-
name- Nom du déploiement. -
endpoint_name– Nom du point de terminaison qui contiendra le déploiement. -
model- Modèle à utiliser pour le déploiement. Cette valeur peut être une référence à un modèle versionné existant dans l’espace de travail ou une spécification de modèle inline. -
environment– Environnement à utiliser pour le déploiement (ou pour exécuter le modèle). Cette valeur peut être une référence à un environnement versionné existant dans l’espace de travail ou une spécification d’environnement inline. L’environnement peut être une image Docker avec des dépendances Conda ou un Dockerfile. -
code_configuration– Configuration du code source et du script de scoring.-
path– Chemin du répertoire du code source pour le scoring du modèle. -
scoring_script– Chemin relatif du fichier de scoring dans le répertoire du code source. Ce script exécute le modèle à l’occasion d’une demande d’entrée donnée. Pour obtenir un exemple de script de scoring, consultez Comprendre le script de scoring dans l’article « Déployer un modèle ML avec un point de terminaison en ligne ».
-
-
instance_type- Taille de machine virtuelle à utiliser pour le déploiement. Pour obtenir la liste des tailles prises en charge, consultez la liste des références SKU des points de terminaison en ligne managés. -
instance_count– Nombre d’instances à utiliser pour le déploiement.
Déploiement à l’aide d’un modèle MLflow
Azure Machine Learning prend en charge le déploiement sans code d’un modèle créé et journalisé avec MLflow. Cela signifie que vous n’avez pas besoin de fournir de script de scoring ou d’environnement pendant le déploiement du modèle, car le script de scoring et l’environnement sont générés automatiquement pendant l’entraînement d’un modèle MLflow. Cependant, si vous utilisiez un modèle personnalisé, vous devriez spécifier l’environnement et le script de scoring pendant le déploiement.
Important
Si vous déployez généralement des modèles en utilisant des scripts de scoring et des environnements personnalisés et que vous souhaitez aboutir à la même fonctionnalité en utilisant des modèles MLflow, nous vous recommandons de lire Instructions pour déployer des modèles MLflow.
Déployer le modèle sur le point de terminaison
Commencez par créer un déploiement unique qui traite 100 % du trafic entrant. Choisissez un nom de couleur arbitraire (bleu) pour le déploiement. Pour créer le déploiement du point de terminaison, utilisez la classe ManagedOnlineDeployment.
Remarque
Il n’est pas nécessaire de spécifier un environnement ou un script de scoring, car le modèle à déployer est un modèle MLflow.
from azure.ai.ml.entities import ManagedOnlineDeployment
# Choose the latest version of the registered model for deployment
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
En utilisant le MLClient créé précédemment, créez maintenant le déploiement dans l’espace de travail. Cette commande lance la création du déploiement et retourne une réponse de confirmation pendant que la création du déploiement se poursuit.
# create the online deployment
blue_deployment = ml_client.online_deployments.begin_create_or_update(
blue_deployment
).result()
# blue deployment takes 100% traffic
# expect the deployment to take approximately 8 to 10 minutes.
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Vérifiez l’état du point de terminaison
Vous pouvez examiner l’état du point de terminaison pour vérifier si le modèle a été déployé sans erreur :
# return an object that contains metadata for the endpoint
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
# print a selection of the endpoint's metadata
print(
f"Name: {endpoint.name}\nStatus: {endpoint.provisioning_state}\nDescription: {endpoint.description}"
)
# existing traffic details
print(endpoint.traffic)
# Get the scoring URI
print(endpoint.scoring_uri)
Tester le point de terminaison avec des exemples de données
Maintenant que le modèle est déployé sur le point de terminaison, vous pouvez exécuter l’inférence avec celui-ci. Commencez par créer un exemple de fichier de requête qui suit la conception attendue dans la méthode d’exécution trouvée dans le script de scoring.
import os
# Create a directory to store the sample request file.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
À présent, créez le fichier dans le répertoire « deploy ». La cellule de code suivante utilise IPython magic pour écrire le fichier dans le répertoire que vous venez de créer.
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
En utilisant le MLClient créée précédemment, obtenez un descripteur vers le point de terminaison. Vous pouvez appeler le point de terminaison à l’aide de la commande invoke avec les paramètres suivants :
-
endpoint_name- Nom du point de terminaison -
request_file- Fichier avec des données de requête -
deployment_name- Nom du déploiement spécifique à tester dans un point de terminaison
Testez le déploiement « bleu » avec les exemples de données.
# test the blue deployment with the sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="blue",
request_file="./deploy/sample-request.json",
)
Obtenir les journaux du déploiement
Vérifiez les journaux pour déterminer si le point de terminaison/le déploiement a été appelé avec succès. Si vous rencontrez des erreurs, consultez Résolution des problèmes de déploiement des points de terminaison en ligne.
logs = ml_client.online_deployments.get_logs(
name="blue", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Créer un deuxième déploiement
Déployez le modèle sous la forme d’un deuxième déploiement appelé green. Dans la pratique, vous pouvez créer plusieurs déploiements et comparer leur niveau de performance. Ces déploiements pourraient reposer sur une version différente du même modèle, un modèle différent ou une instance de calcul plus puissante.
Dans cet exemple, vous déployez la même version du modèle en utilisant une instance de calcul plus puissante susceptible d’améliorer le niveau de performance.
# pick the model to deploy. Here you use the latest version of the registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment using a more powerful instance type
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
green_deployment = ManagedOnlineDeployment(
name="green",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_F4s_v2",
instance_count=1,
)
# create the online deployment
# expect the deployment to take approximately 8 to 10 minutes
green_deployment = ml_client.online_deployments.begin_create_or_update(
green_deployment
).result()
Mettre à l’échelle le déploiement pour gérer davantage de trafic
En utilisant le MLClient créé précédemment, vous pouvez obtenir un descripteur pour le déploiement green. Vous pouvez ensuite le mettre à l’échelle en augmentant ou en réduisant la valeur instance_count.
Dans le code suivant, vous augmentez manuellement l’instance de machine virtuelle. Cependant, il est également possible de mettre à l’échelle automatiquement les points de terminaison en ligne. La mise à l’échelle automatique exécute automatiquement la quantité appropriée de ressources pour gérer la charge sur votre application. Les points de terminaison en ligne managés prennent en charge la mise à l’échelle automatique via l’intégration à la fonctionnalité de mise à l’échelle automatique d’Azure Monitor. Pour configurer la mise à l’échelle automatique, consultez Mise à l’échelle automatique de points de terminaison en ligne.
# update definition of the deployment
green_deployment.instance_count = 2
# update the deployment
# expect the deployment to take approximately 8 to 10 minutes
ml_client.online_deployments.begin_create_or_update(green_deployment).result()
Mettre à jour l’allocation du trafic pour les déploiements
Vous pouvez répartir le trafic de production entre les déploiements. Dans un premier temps, vous pouvez tester le déploiement green avec des exemples de données, comme vous l’avez fait pour le déploiement blue. Une fois que vous avez testé votre déploiement « green », allouez à celui-ci un petit pourcentage de trafic.
endpoint.traffic = {"blue": 80, "green": 20}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Testez l’allocation de trafic en appelant le point de terminaison plusieurs fois :
# You can invoke the endpoint several times
for i in range(30):
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
)
Examinez les journaux du déploiement green pour vérifier qu’il y a eu des demandes entrantes et que le modèle a bien été scoré.
logs = ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Afficher les métriques avec Azure Monitor
Vous pouvez afficher diverses métriques (nombres de demandes, latence des demandes, octets réseau, utilisation de processeur/GPU/disque/mémoire, etc.) pour un point de terminaison en ligne et ses déploiements en suivant les liens de la page Détails du point de terminaison dans studio. En suivant l’un de ces liens, vous accédez à la page des métriques exactes dans le Portail Azure pour le point de terminaison ou le déploiement.

Si vous ouvrez les métriques pour le point de terminaison en ligne, vous pouvez configurer la page de sorte qu’elle affiche les métriques, telles que la latence moyenne des demandes, comme dans la figure suivante.

Pour plus d’informations sur l’affichage des métriques de point de terminaison en ligne, consultez Superviser les points de terminaison en ligne.
Envoyer l’ensemble du trafic vers le nouveau déploiement
Une fois que votre déploiement green vous donne entière satisfaction, basculez tout le trafic vers celui-ci.
endpoint.traffic = {"blue": 0, "green": 100}
ml_client.begin_create_or_update(endpoint).result()
Supprimer l’ancien déploiement
Supprimez l’ancien déploiement (« blue ») :
ml_client.online_deployments.begin_delete(
name="blue", endpoint_name=online_endpoint_name
).result()
Nettoyer les ressources
Si vous ne comptez pas utiliser le point de terminaison et le déploiement à l’issue de ce tutoriel, il est préférable de les supprimer.
Notes
Attendez-vous à ce que la suppression complète prenne environ 20 minutes.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name).result()
Tout supprimer
Utilisez ces étapes pour supprimer votre espace de travail Azure Machine Learning et toutes les ressources de calcul.
Important
Les ressources que vous avez créées peuvent être utilisées comme prérequis pour d’autres tutoriels d’Azure Machine Learning et des articles de procédure.
Si vous n’avez pas l’intention d’utiliser les ressources que vous avez créées, supprimez-les pour éviter des frais :
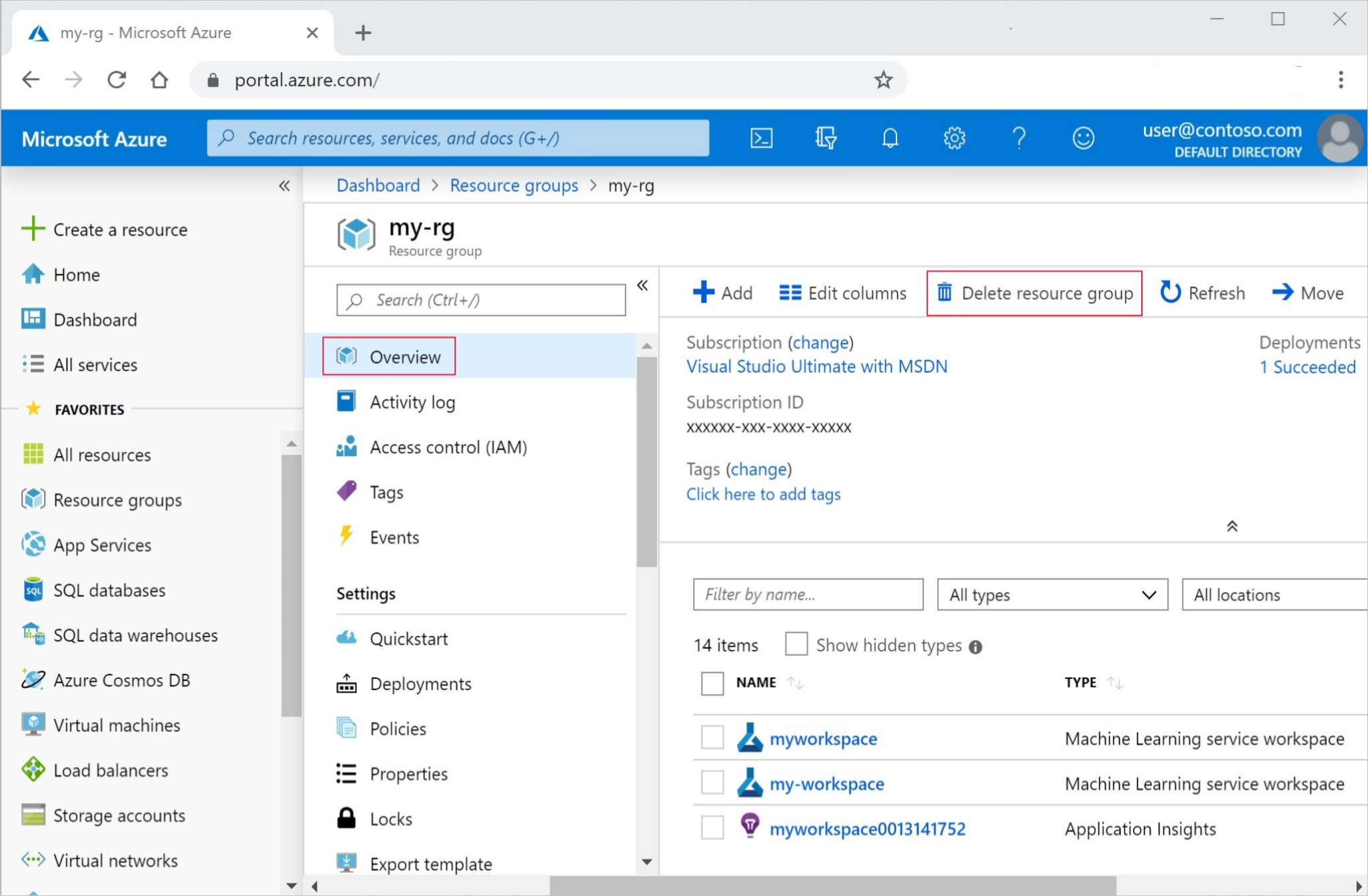
Dans la zone de recherche du Portail Azure, saisissez Groupes de ressources, puis sélectionnez-le dans les résultats.
Dans la liste, sélectionnez le groupe de ressources créé.
Dans la page Vue d’ensemble, sélectionnez Supprimer le groupe de ressources.
Entrez le nom du groupe de ressources. Puis sélectionnez Supprimer.