Tutoriel : créer des pipelines Machine Learning de production
S’APPLIQUE À :  Kit de développement logiciel (SDK) Python azure-ai-mlv2 (préversion)
Kit de développement logiciel (SDK) Python azure-ai-mlv2 (préversion)
Notes
Pour obtenir un tutoriel qui utilise le SDK v1 pour générer un pipeline, consultez Tutoriel : Créer un pipeline Azure Machine Learning pour la classification d’images.
Le cœur d’un pipeline d’apprentissage automatique consiste à fractionner une tâche d’apprentissage automatique en un flux de travail de plusieurs étapes. Chaque étape est un composant gérable qui peut être développé, optimisé, configuré et automatisé individuellement. Les étapes sont connectées via des interfaces bien définies. Le service du pipeline Azure Machine Learning orchestre automatiquement toutes les dépendances entre les étapes du pipeline. Les avantages de l’utilisation d’un pipeline sont les pratiques MLOps normalisées, la collaboration d’équipe évolutive, l’efficacité de la formation et la réduction des coûts. Pour en savoir plus sur les avantages des pipelines, consultez Présentation des pipelines Azure Machine Learning.
Dans ce tutoriel, vous utilisez Azure Machine Learning pour créer un projet Machine Learning prêt pour la production, à l’aide du SDK Python Azure Machine Learning v2.
Cela signifie que vous serez en mesure de tirer parti du Kit de développement logiciel (SDK) Python Azure Machine Learning pour :
- Obtenir un handle dans votre espace de travail Azure Machine Learning
- Créer des ressources de données Azure Machine Learning
- Créer des composants Azure Machine Learning réutilisables
- Créer, valider et exécuter des pipelines Azure Machine Learning
Dans ce tutoriel, vous créez un pipeline Azure Machine Learning pour entraîner un modèle à des fins de prédiction de défaut de crédit. Le pipeline gère deux étapes :
- Préparation des données
- Entraînement et inscription du modèle entraîné
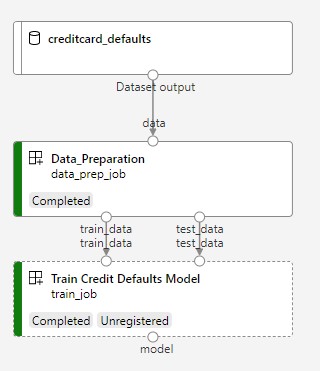
L’image suivante présente un pipeline simple tel qu’il apparaîtra dans le studio Azure une fois soumis.
Les deux étapes sont la préparation des données puis l’entraînement.
Cette vidéo montre comment bien démarrer dans Azure Machine Learning studio pour pouvoir suivre les étapes du tutoriel. La vidéo montre comment créer un notebook, créer une instance de calcul et cloner le notebook. Les étapes sont également décrites dans les sections suivantes.
Prérequis
-
Vous avez besoin d’un espace de travail pour utiliser Azure Machine Learning. Si vous n’en avez pas, suivez la procédure Créer les ressources nécessaires pour commencer pour créer un espace de travail et en savoir plus sur son utilisation.
Important
Si votre espace de travail Azure Machine Learning est configuré avec un réseau virtuel managé, vous devrez peut-être ajouter des règles de trafic sortant pour autoriser l’accès aux référentiels publics de packages Python. Pour plus d’informations, consulter Scénario : accéder aux packages Machine Learning publics.
-
Connectez-vous au studio et sélectionnez votre espace de travail s’il n’est pas déjà ouvert.
Suivez le didacticiel Charger, accéder et explorer vos données pour créer la ressource de données dont vous avez besoin dans ce didacticiel. Veillez à exécuter tout le code pour créer la ressource de données initiale. Explorez les données, puis révisez-les si vous le souhaitez, mais vous n’aurez besoin que des données initiales dans ce didacticiel.
-
Ouvrez ou créez un notebook dans votre espace de travail :
- Si vous souhaitez copier et coller du code dans des cellules, créez un notebook.
- Ou ouvrez tutorials/get-started-notebooks/pipeline.ipynb à partir de la section Exemples de studio. Sélectionnez ensuite Cloner pour ajouter le notebook à vos Fichiers. Pour trouver des exemples de notebooks, consultez Apprendre à partir d’exemples de notebooks.
Définir votre noyau et ouvrir dans Visual Studio Code (VS Code)
Dans la barre supérieure au-dessus de votre notebook ouvert, créez une instance de calcul si vous n’en avez pas déjà une.

Si l’instance de calcul est arrêtée, sélectionnez Démarrer le calcul et attendez qu’elle s’exécute.

Attendez que l’instance de calcul soit en cours d’exécution. Vérifiez ensuite que le noyau, situé en haut à droite, est
Python 3.10 - SDK v2. Si ce n’est pas le cas, utilisez la liste déroulante pour sélectionner ce noyau.
Si vous ne voyez pas ce noyau, vérifiez que votre instance de calcul est en cours d’exécution. S’il est présent, sélectionnez le bouton Actualiser en haut à droite du notebook.
Si une bannière vous indique que vous devez être authentifié, sélectionnez Authentifier.
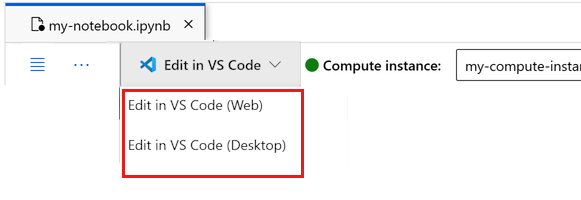
Vous pouvez exécuter le notebook ici, ou l’ouvrir dans VS Code pour un environnement de développement intégré (IDE) complet avec la puissance des ressources Azure Machine Learning. Sélectionnez Ouvrir dans VS Code, puis l’option web ou de bureau. Lors d’un tel lancement, VS Code est attaché à votre instance de calcul, au noyau et au système de fichiers de l’espace de travail.




Important
Le reste de ce tutoriel contient des cellules du notebook du tutoriel. Copiez-les et collez-les dans votre nouveau notebook, ou accédez maintenant au notebook si vous l’avez cloné.
Configurer les ressources de pipeline
Le framework Azure Machine Learning peut être utilisé à partir de l’interface CLI, du SDK Python ou de l’interface Studio. Dans cet exemple, vous utilisez le SDK Python Azure Machine Learning v2 pour créer un pipeline.
Avant de créer le pipeline, vous avez besoin des ressources suivantes :
- La ressource de données pour l’entraînement
- L’environnement logiciel pour exécuter le pipeline
- Une ressource de calcul où le travail s’exécute
Créer un handle vers l’espace de travail
Avant de se lancer dans la rédaction du code, il faut trouver un moyen de référencer l’espace de travail. Vous allez créer ml_client pour un descripteur vers l’espace de travail. Vous utiliserez ensuite ml_client pour gérer les ressources et les travaux.
Dans la cellule suivante, entrez votre ID d’abonnement, le nom du groupe de ressources et le nom de l’espace de travail. Pour rechercher ces valeurs :
- Dans la barre d’outils supérieure droite d’Azure Machine Learning Studio, sélectionnez le nom de votre espace de travail.
- Copiez la valeur de l’espace de travail, du groupe de ressources et de l’ID d’abonnement dans le code.
- Vous devez copier une valeur, fermer la zone et coller, puis revenir pour la suivante.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Notes
La création de MLClient n’établit pas de connexion à l’espace de travail. L’initialisation du client est lente, elle attendra la première fois qu’elle aura besoin de passer un appel (ce qui se produira dans la prochaine cellule de code).
Vérifiez la connexion en effectuant un appel à ml_client. Étant donné que c’est la première fois que vous effectuez un appel à l’espace de travail, vous serez peut-être invité à vous authentifier.
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
Accéder à la ressource de données inscrite
Commencez par obtenir les données que vous avez précédemment inscrites dans Tutoriel : Charger, accéder et explorer vos données dans Azure Machine Learning.
- Azure Machine Learning utilise un objet
Datapour inscrire une définition réutilisable des données et consommer des données dans un pipeline.
# get a handle of the data asset and print the URI
credit_data = ml_client.data.get(name="credit-card", version="initial")
print(f"Data asset URI: {credit_data.path}")
Créer un environnement de travail pour les étapes du pipeline
Jusqu’à présent, vous avez créé un environnement de développement sur l’instance de calcul, votre machine de développement. Vous avez également besoin d’un environnement pour chaque étape du pipeline. Chaque étape peut avoir son propre environnement, ou vous pouvez utiliser certains environnements courants pour plusieurs étapes.
Dans cet exemple, vous créez un environnement conda pour vos travaux à l’aide d’un fichier yaml conda. Tout d’abord, créez un répertoire dans lequel stocker le fichier.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
À présent, créez le fichier dans le répertoire des dépendances.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=0.24.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- xlrd==2.0.1
- mlflow== 2.4.1
- azureml-mlflow==1.51.0
La spécification contient certains packages habituels, que vous utilisez dans votre pipeline (numpy, pip), ainsi que certains packages propres à Azure Machine Learning (azureml-mlflow).
Les packages Azure Machine Learning ne sont pas obligatoires pour exécuter des travaux Azure Machine Learning. Toutefois, l’ajout de ces packages vous permet d’interagir avec Azure Machine Learning pour la journalisation des métriques et l’inscription des modèles, tout cela à l’intérieur du travail Azure Machine Learning. Vous les utilisez dans le script d’entraînement plus loin dans ce tutoriel.
Utilisez le fichier yaml pour créer et inscrire cet environnement personnalisé dans votre espace de travail :
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
pipeline_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults pipeline",
tags={"scikit-learn": "0.24.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
version="0.2.0",
)
pipeline_job_env = ml_client.environments.create_or_update(pipeline_job_env)
print(
f"Environment with name {pipeline_job_env.name} is registered to workspace, the environment version is {pipeline_job_env.version}"
)
Générer le pipeline d’entraînement
Maintenant que vous disposez de toutes les ressources nécessaires pour exécuter votre pipeline, il est temps de générer le pipeline lui-même.
Les pipelines Azure Machine Learning sont des workflows ML réutilisables généralement constitués de plusieurs composants. Le cycle de vie typique d’un composant est le suivant :
- Écrivez la spécification yaml du composant, ou créez-la par programmation à l’aide de
ComponentMethod. - Éventuellement, inscrivez le composant avec un nom et une version dans votre espace de travail pour le rendre réutilisable et partageable.
- Chargez ce composant à partir du code du pipeline.
- Implémentez le pipeline à l’aide des entrées, sorties et paramètres du composant.
- Envoyez le pipeline.
Il existe deux façons de créer un composant : la définition programmatique et la définition yaml. Les deux sections suivantes vous guident tout au long de la création d’un composant des deux façons. Vous pouvez créer les deux composants en essayant les deux options ou choisir votre méthode préférée.
Notes
Dans ce tutoriel, par souci de simplicité, nous utilisons le même calcul pour tous les composants. Toutefois, vous pouvez définir des calculs différents pour chaque composant, par exemple en ajoutant une ligne comme train_step.compute = "cpu-cluster". Pour voir un exemple de création d’un pipeline avec des calculs différents pour chaque composant, consultez la section Travail de pipeline de base dans le tutoriel sur le pipeline cifar-10.
Créer un composant 1 : Préparation des données (à l’aide d’une définition par programmation)
Commençons par créer le premier composant. Ce composant gère le prétraitement des données. La tâche de prétraitement est effectuée dans le fichier Python data_prep.py.
Tout d’abord, créez un dossier source pour le composant data_prep :
import os
data_prep_src_dir = "./components/data_prep"
os.makedirs(data_prep_src_dir, exist_ok=True)
Ce script effectue la tâche simple de fractionnement des données en jeux de données d’entraînement et de test. Azure Machine Learning monte les jeux de données en tant que dossiers dans les calculs. Par conséquent, nous avons créé une fonction select_first_file auxiliaire pour accéder au fichier de données à l’intérieur du dossier d’entrée monté.
MLFlow est utilisé pour consigner les paramètres et les métriques pendant l’exécution de notre pipeline.
%%writefile {data_prep_src_dir}/data_prep.py
import os
import argparse
import pandas as pd
from sklearn.model_selection import train_test_split
import logging
import mlflow
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
credit_train_df, credit_test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
# output paths are mounted as folder, therefore, we are adding a filename to the path
credit_train_df.to_csv(os.path.join(args.train_data, "data.csv"), index=False)
credit_test_df.to_csv(os.path.join(args.test_data, "data.csv"), index=False)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Maintenant que vous disposez d’un script qui peut effectuer la tâche souhaitée, créez un composant Azure Machine Learning à partir de ce script.
Utilisez le CommandComponent à usage général qui peut exécuter des actions de ligne de commande. Cette action de ligne de commande peut appeler directement des commandes système ou exécuter un script. Les entrées/sorties sont spécifiées sur la ligne de commande au moyen de la notation ${{ ... }}.
from azure.ai.ml import command
from azure.ai.ml import Input, Output
data_prep_component = command(
name="data_prep_credit_defaults",
display_name="Data preparation for training",
description="reads a .xl input, split the input to train and test",
inputs={
"data": Input(type="uri_folder"),
"test_train_ratio": Input(type="number"),
},
outputs=dict(
train_data=Output(type="uri_folder", mode="rw_mount"),
test_data=Output(type="uri_folder", mode="rw_mount"),
),
# The source folder of the component
code=data_prep_src_dir,
command="""python data_prep.py \
--data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} \
--train_data ${{outputs.train_data}} --test_data ${{outputs.test_data}} \
""",
environment=f"{pipeline_job_env.name}:{pipeline_job_env.version}",
)
Si vous le souhaitez, inscrivez le composant dans l’espace de travail pour une réutilisation ultérieure.
# Now we register the component to the workspace
data_prep_component = ml_client.create_or_update(data_prep_component.component)
# Create (register) the component in your workspace
print(
f"Component {data_prep_component.name} with Version {data_prep_component.version} is registered"
)
Créer le composant 2 : Entraînement (à l’aide de la définition yaml)
Le deuxième composant que vous créez consomme les données d’entraînement et de test, entraîne un modèle basé sur une arborescence et retourne le modèle de sortie. Utilisez les fonctionnalités de journalisation d’Azure Machine Learning pour enregistrer et visualiser la progression de l’entraînement.
Vous avez utilisé la classe CommandComponent pour créer votre premier composant. Cette fois, vous utilisez la définition yaml pour définir le deuxième composant. Chaque méthode a ses propres avantages. Une définition yaml peut en fait être archivée en même temps que le code, et fournirait un suivi d’historique lisible. La méthode programmatique utilisant CommandComponent peut être plus facile avec la documentation de classe intégrée et la complétion de code.
Créez le répertoire pour ce composant :
import os
train_src_dir = "./components/train"
os.makedirs(train_src_dir, exist_ok=True)
Créez le script d’entraînement dans le répertoire :
%%writefile {train_src_dir}/train.py
import argparse
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
import os
import pandas as pd
import mlflow
def select_first_file(path):
"""Selects first file in folder, use under assumption there is only one file in folder
Args:
path (str): path to directory or file to choose
Returns:
str: full path of selected file
"""
files = os.listdir(path)
return os.path.join(path, files[0])
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
os.makedirs("./outputs", exist_ok=True)
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
parser.add_argument("--model", type=str, help="path to model file")
args = parser.parse_args()
# paths are mounted as folder, therefore, we are selecting the file from folder
train_df = pd.read_csv(select_first_file(args.train_data))
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# paths are mounted as folder, therefore, we are selecting the file from folder
test_df = pd.read_csv(select_first_file(args.test_data))
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.model, "trained_model"),
)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Comme vous pouvez le voir dans ce script d’entraînement, une fois le modèle entraîné, le fichier de modèle est enregistré et inscrit auprès de l’espace de travail. Vous pouvez maintenant utiliser le modèle inscrit dans les points de terminaison d’inférence.
Pour l’environnement de cette étape, vous utilisez l’un des environnements Azure Machine Learning intégrés (organisés). L’étiquette azureml indique au système qu’il faut rechercher le nom dans les environnements organisés.
Tout d’abord, créez le fichier yaml décrivant le composant :
%%writefile {train_src_dir}/train.yml
# <component>
name: train_credit_defaults_model
display_name: Train Credit Defaults Model
# version: 1 # Not specifying a version will automatically update the version
type: command
inputs:
train_data:
type: uri_folder
test_data:
type: uri_folder
learning_rate:
type: number
registered_model_name:
type: string
outputs:
model:
type: uri_folder
code: .
environment:
# for this step, we'll use an AzureML curate environment
azureml://registries/azureml/environments/sklearn-1.0/labels/latest
command: >-
python train.py
--train_data ${{inputs.train_data}}
--test_data ${{inputs.test_data}}
--learning_rate ${{inputs.learning_rate}}
--registered_model_name ${{inputs.registered_model_name}}
--model ${{outputs.model}}
# </component>
À présent, créez et inscrivez le composant. Son inscription vous permet de le réutiliser dans d’autres pipelines. En outre, toute autre personne ayant accès à votre espace de travail peut utiliser le composant inscrit.
# importing the Component Package
from azure.ai.ml import load_component
# Loading the component from the yml file
train_component = load_component(source=os.path.join(train_src_dir, "train.yml"))
# Now we register the component to the workspace
train_component = ml_client.create_or_update(train_component)
# Create (register) the component in your workspace
print(
f"Component {train_component.name} with Version {train_component.version} is registered"
)
Créer le pipeline à partir de composants
Maintenant que vos deux composants sont définis et inscrits, vous pouvez commencer à implémenter le pipeline.
Ici, vous utilisez les données d’entrée, le ratio de fractionnement et le nom du modèle inscrit comme variables d’entrée. Appelez ensuite les composants et connectez-les par le biais de leurs identificateurs d’entrées/sorties. Les sorties de chaque étape sont accessibles via la propriété .outputs.
Les fonctions Python retournées par load_component() opèrent comme toutes les fonctions Python normales que nous utilisons dans un pipeline pour appeler chaque étape.
Pour coder le pipeline, vous utilisez un décorateur @dsl.pipeline spécifique qui identifie les pipelines Azure Machine Learning. Dans le décorateur, nous pouvons spécifier la description du pipeline et les ressources par défaut telles que le calcul et le stockage. Comme une fonction Python, les pipelines peuvent avoir des entrées. Vous pouvez alors créer plusieurs instances d’un même pipeline avec différentes entrées.
Ici, nous avons utilisé les données d’entrée, le ratio de fractionnement et le nom du modèle inscrit comme variables d’entrée. Nous appelons ensuite les composants et les connectons par le biais de leurs identificateurs d’entrées/sorties. Les sorties de chaque étape sont accessibles via la propriété .outputs.
# the dsl decorator tells the sdk that we are defining an Azure Machine Learning pipeline
from azure.ai.ml import dsl, Input, Output
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E data_perp-train pipeline",
)
def credit_defaults_pipeline(
pipeline_job_data_input,
pipeline_job_test_train_ratio,
pipeline_job_learning_rate,
pipeline_job_registered_model_name,
):
# using data_prep_function like a python call with its own inputs
data_prep_job = data_prep_component(
data=pipeline_job_data_input,
test_train_ratio=pipeline_job_test_train_ratio,
)
# using train_func like a python call with its own inputs
train_job = train_component(
train_data=data_prep_job.outputs.train_data, # note: using outputs from previous step
test_data=data_prep_job.outputs.test_data, # note: using outputs from previous step
learning_rate=pipeline_job_learning_rate, # note: using a pipeline input as parameter
registered_model_name=pipeline_job_registered_model_name,
)
# a pipeline returns a dictionary of outputs
# keys will code for the pipeline output identifier
return {
"pipeline_job_train_data": data_prep_job.outputs.train_data,
"pipeline_job_test_data": data_prep_job.outputs.test_data,
}
Utilisez maintenant votre définition de pipeline pour instancier un pipeline avec votre jeu de données, le ratio de fractionnement de votre choix et le nom que vous avez choisi pour votre modèle.
registered_model_name = "credit_defaults_model"
# Let's instantiate the pipeline with the parameters of our choice
pipeline = credit_defaults_pipeline(
pipeline_job_data_input=Input(type="uri_file", path=credit_data.path),
pipeline_job_test_train_ratio=0.25,
pipeline_job_learning_rate=0.05,
pipeline_job_registered_model_name=registered_model_name,
)
Envoi du travail
Il est maintenant temps de soumettre le travail à exécuter dans Azure Machine Learning. Cette fois, vous utilisez create_or_update sur ml_client.jobs.
Ici, vous allez également transmettre un nom d’expérience. Une expérience est un conteneur pour toutes les itérations que l’on effectue sur un certain projet. Tous les travaux soumis sous le même nom d’expérience sont listés les uns à côtés des autres dans Azure Machine Learning Studio.
Une fois terminé, le pipeline inscrit un modèle dans votre espace de travail suite à l’entraînement.
# submit the pipeline job
pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_registered_components",
)
ml_client.jobs.stream(pipeline_job.name)
Vous pouvez suivre la progression de votre pipeline à l’aide du lien généré dans la cellule précédente. Lorsque vous sélectionnez ce lien pour la première fois, vous pouvez voir que le pipeline est toujours en cours d’exécution. Une fois l’opération terminée, vous pouvez examiner les résultats de chaque composant.
Double-cliquez sur le composant Entraîner le modèle de défauts de crédit.
Il existe deux résultats importants que vous voudrez voir sur l’entraînement :
Affichez vos journaux :
- Sélectionnez l'onglet Sorties + journaux d'activité.
- Ouvrez les dossiers dans
user_logs>std_log.txtCette section affiche l’exécution du script stdout.
Afficher vos métriques : sélectionnez l’onglet Métriques. Cette section présente différentes métriques journalisées. Dans cet exemple, mlflow
autologging, a journalisé automatiquement les métriques d’entraînement.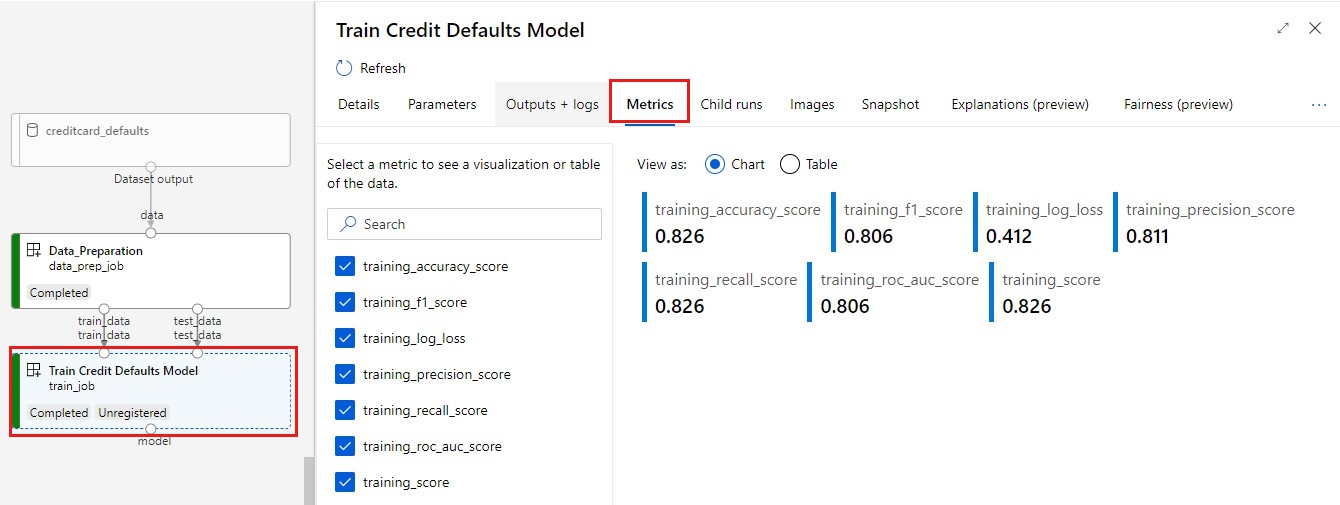


Déployer le modèle en tant que point de terminaison en ligne
Pour savoir comment déployer votre modèle sur un point de terminaison en ligne, consultez le tutoriel Déployer un modèle en tant que point de terminaison en ligne.
Nettoyer les ressources
Si vous comptez suivre d’autres tutoriels, passez aux Étapes suivantes.
Arrêter l’instance de calcul
Si vous ne comptez pas l’utiliser maintenant, arrêtez l’instance de calcul :
- Dans la zone de navigation gauche de Studio, sélectionnez Calculer.
- Sous les onglets supérieurs, sélectionnez Instances de calcul
- Sélectionnez l’instance de calcul dans la liste.
- Dans la barre d’outils supérieure, sélectionnez Arrêter.
Supprimer toutes les ressources
Important
Les ressources que vous avez créées peuvent être utilisées comme prérequis pour d’autres tutoriels d’Azure Machine Learning et des articles de procédure.
Si vous n’avez pas l’intention d’utiliser les ressources que vous avez créées, supprimez-les pour éviter des frais :
Dans la zone de recherche du Portail Azure, saisissez Groupes de ressources, puis sélectionnez-le dans les résultats.
Dans la liste, sélectionnez le groupe de ressources créé.
Dans la page Vue d’ensemble, sélectionnez Supprimer le groupe de ressources.
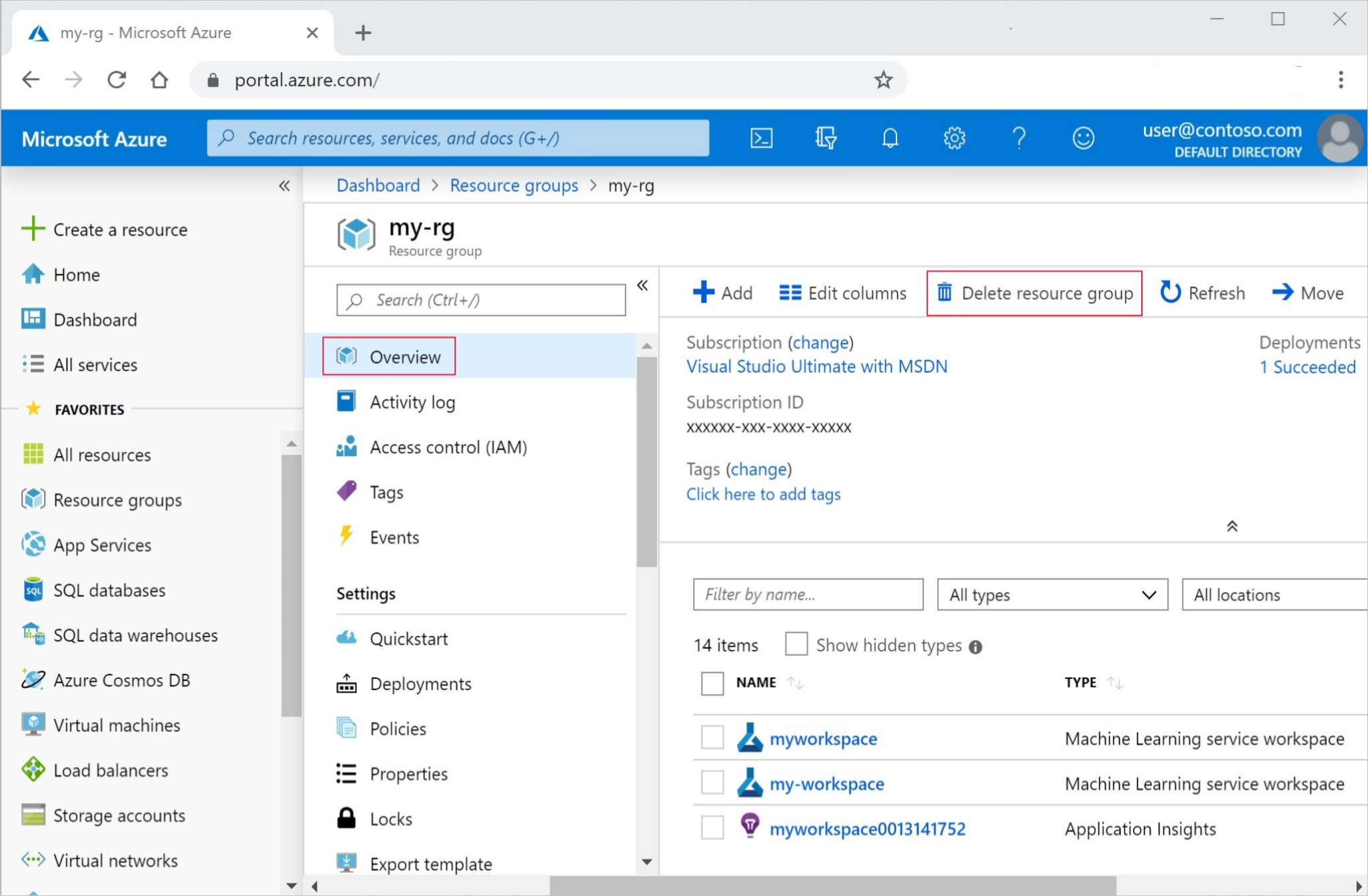
Entrez le nom du groupe de ressources. Puis sélectionnez Supprimer.
Étapes suivantes
Découvrez comment planifier des travaux de pipeline Machine Learning