Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article fournit des instructions détaillées étape par étape pour créer une réplique de lecture d'une instance de serveur flexible de base de données Azure pour PostgreSQL.
Note
Lors du déploiement de réplicas de lecture pour des charges de travail principales persistantes et lourdes d’écriture intensive, le retard de réplication peut continuer à s’allonger et ne jamais rattraper le principal. Il peut également augmenter l’utilisation du stockage sur le serveur principal, car les fichiers WAL ne sont supprimés qu’une fois reçus sur le réplica.
Important
Passez en revue la section des considérations dans l’article de vue d’ensemble des réplicas en lecture.
Avant de modifier les valeurs des paramètres de serveur suivants sur le serveur principal, modifiez-les d’abord sur les réplicas en lecture. Ceci évite les problèmes lors de la promotion d’un réplica en lecture vers le réplica principal : max_connections, max_prepared_transactions, max_locks_per_transaction, max_wal_senders, max_worker_processes.
Avant de configurer un réplica en lecture pour votre instance de serveur flexible Azure Database pour PostgreSQL, vérifiez que le serveur principal est configuré pour répondre aux conditions préalables nécessaires. Des paramètres spécifiques sur le serveur principal peuvent influencer la possibilité de créer des réplicas.
Croissance automatique du stockage : les paramètres de croissance automatique du stockage sur le serveur principal et ses réplicas en lecture doivent respecter des instructions spécifiques pour garantir la cohérence et empêcher les interruptions de réplication. Reportez-vous à la croissance automatique du stockage pour obtenir des règles et des paramètres détaillés.
Type de stockage : les réplicas en lecture ne peuvent être créés que sur des serveurs configurés pour utiliser le type de stockage SSD Premium. Si votre charge de travail nécessite des réplicas en lecture, assurez-vous que le serveur principal est créé avec ce type de stockage.
Étapes de la création d’un réplica en lecture
Utilisation du portail Azure :
Sélectionnez l’instance de serveur flexible Azure Database pour PostgreSQL que vous souhaitez utiliser comme serveur principal.
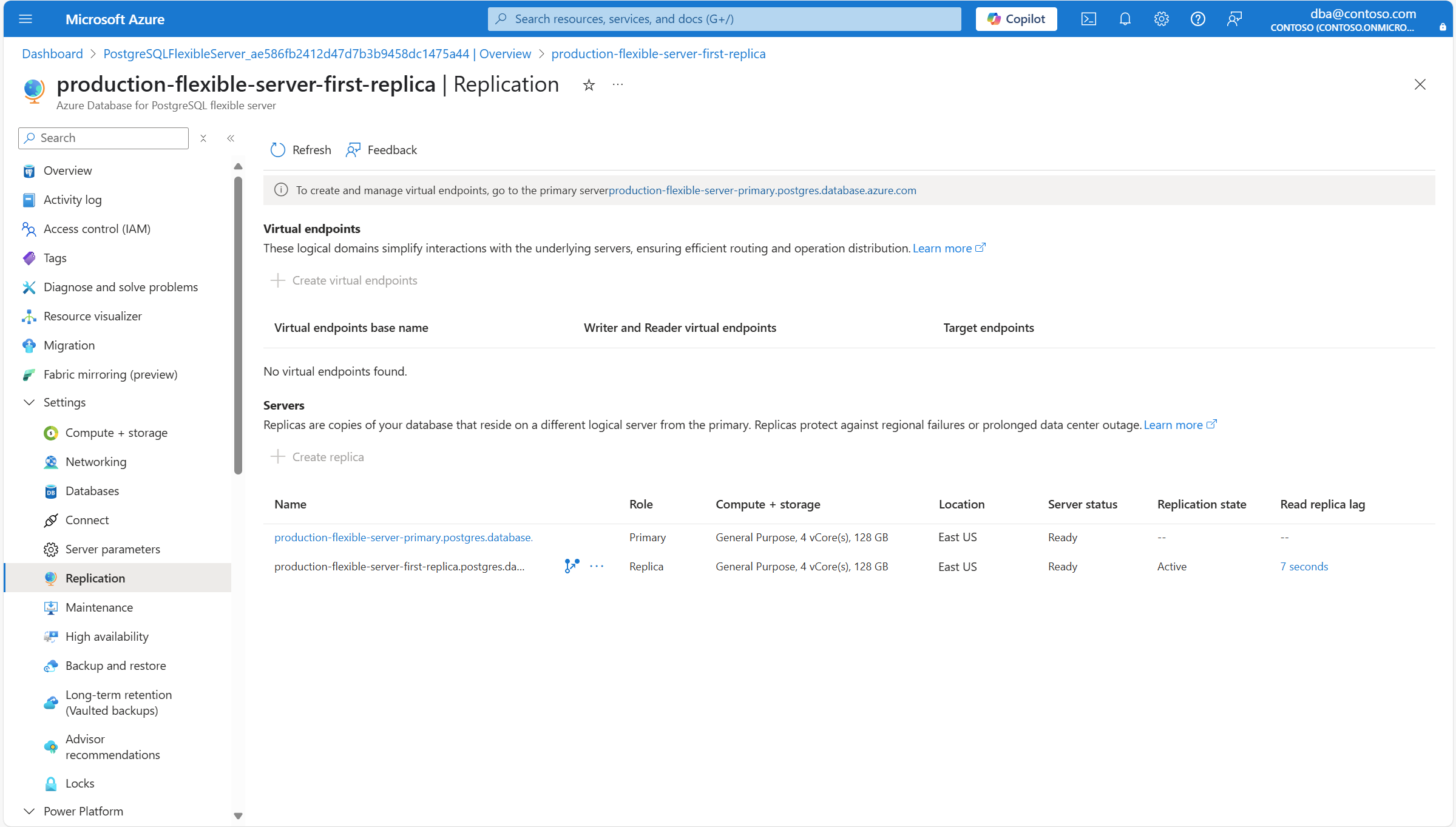
Dans le menu de la ressource, sous la section Paramètres , sélectionnez Réplication.
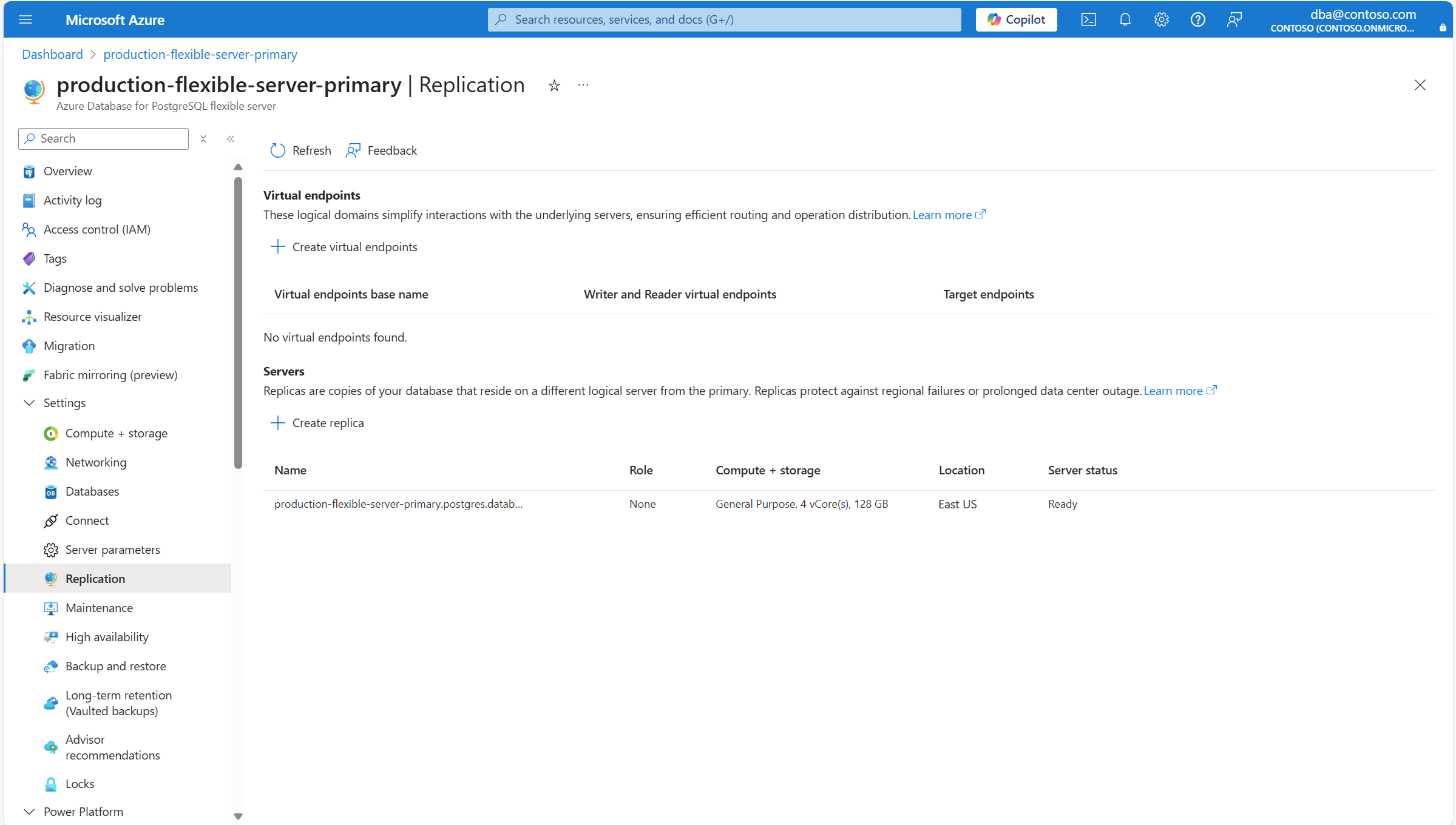
Dans la section Serveurs , sélectionnez Créer un réplica.
Vous êtes redirigé vers l'assistant Ajouter un réplica en lecture à Azure Database pour PostgreSQL, à partir duquel vous pouvez configurer certains paramètres pour le nouveau réplica en lecture créé.
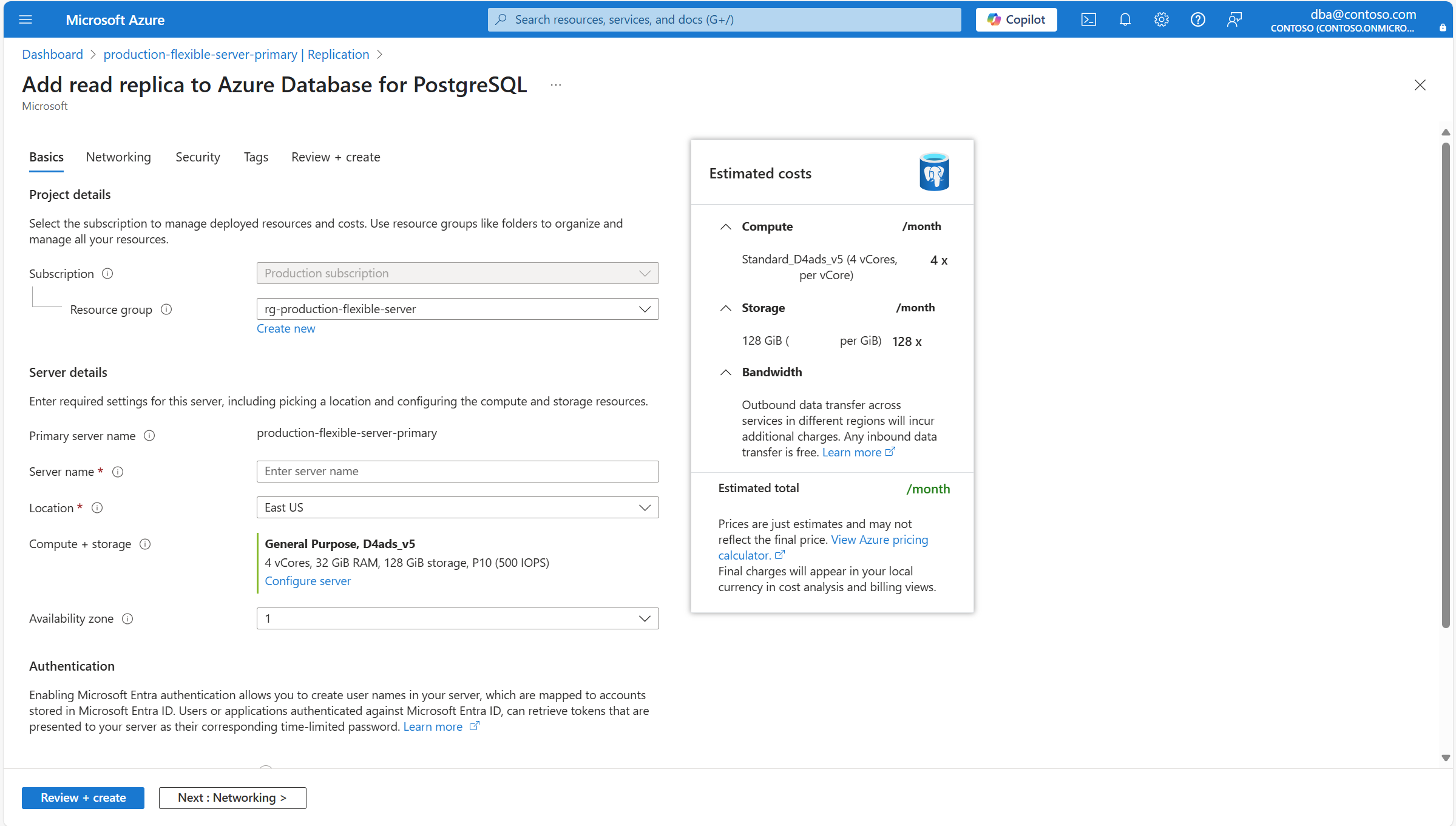
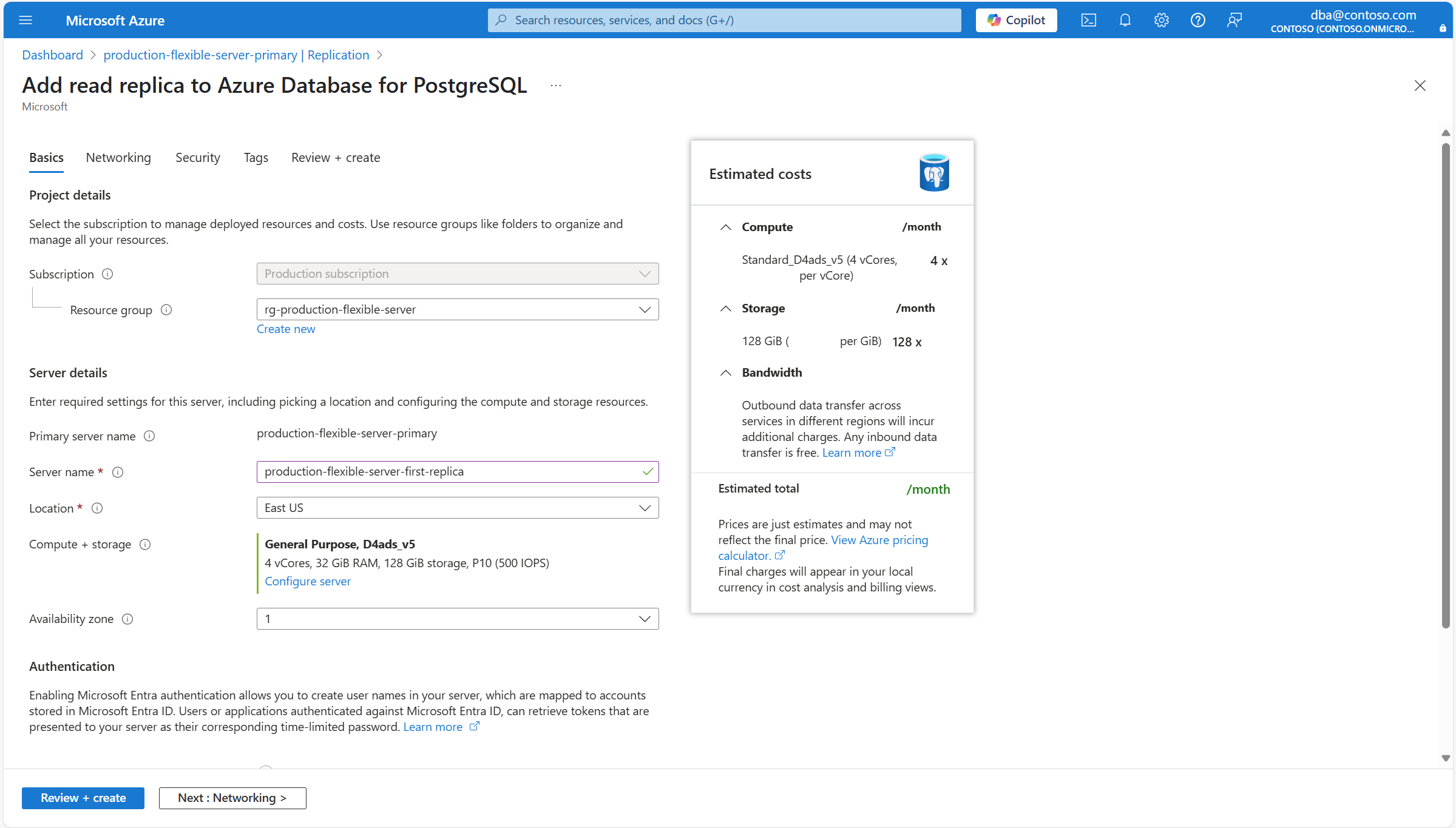
Utilisez le tableau suivant pour comprendre la signification des différents champs disponibles dans la page Informations de base et comme conseils pour remplir la page.
Section Réglage Valeur suggérée Descriptif Peut être modifié après la création de l’instance Détails du projet Subscription Le nom de l’abonnement dans lequel vous souhaitez créer la ressource. Un abonnement est un contrat passé avec Microsoft permettant d’utiliser une ou plusieurs plateformes ou services cloud Microsoft, dont les frais correspondants sont basés soit sur un tarif de licence par utilisateur soit sur la consommation de ressources cloud. Une instance de serveur flexible Azure Database pour PostgreSQL existante peut être déplacée vers un autre abonnement que celui dans lequel elle a été créée. Pour plus d’informations, consultez Déplacer des ressources Azure vers un nouveau groupe de ressources ou un nouvel abonnement. Groupe de ressources Le groupe de ressources dans l’abonnement sélectionné, dans lequel vous souhaitez créer la ressource. Il peut s’agir d’un groupe de ressources existant, ou vous pouvez sélectionner Créer et fournir un nom dans cet abonnement qui est unique parmi les noms de groupes de ressources existants. Un groupe de ressources est un conteneur réunissant les ressources associées d’une solution Azure. Le groupe de ressources peut inclure toutes les ressources de la solution, ou uniquement celles que vous souhaitez gérer en tant que groupe. Pour déterminer comment allouer des ressources aux groupes de ressources, choisissez l’approche la plus pertinente pour votre organisation. En règle générale, il convient de regrouper des ressources qui partagent le même cycle de vie dans un même groupe de ressources afin de pouvoir facilement les déployer, les mettre à jour et les supprimer en tant que groupe Une instance de serveur flexible Azure Database pour PostgreSQL existante peut être déplacée vers un autre abonnement que celui dans lequel elle a été créée. Pour plus d’informations, consultez Déplacer des ressources Azure vers un nouveau groupe de ressources ou un nouvel abonnement. Détails du serveur Nom du serveur principal Nom du serveur principal pour lequel vous essayez de créer un réplica en lecture. Nom unique qui identifie votre instance de serveur flexible Azure Database pour PostgreSQL. Le nom de domaine postgres.database.azure.comest ajouté au nom du serveur que vous fournissez pour respecter le nom d’hôte complet par lequel vous pouvez utiliser un serveur DNS pour résoudre l’adresse IP de votre instance.Nom du serveur Nom que vous souhaitez affecter au nouveau réplica en lecture. Nom unique qui identifie votre instance de serveur flexible Azure Database pour PostgreSQL. Le nom de domaine postgres.database.azure.comest ajouté au nom du serveur que vous fournissez pour respecter le nom d’hôte complet par lequel vous pouvez utiliser un serveur DNS pour résoudre l’adresse IP de votre instance.Bien que le nom du serveur ne puisse pas être modifié après la création du serveur, vous pouvez utiliser la fonctionnalité de récupération ponctuelle pour restaurer le serveur sous un autre nom. Une autre approche pour continuer à utiliser le serveur existant, mais en y faisant référence en utilisant un autre nom de serveur, consisterait à utiliser les points de terminaison virtuels pour créer un point de terminaison d'écriture avec le nouveau nom souhaité. Cette approche vous permet de faire référence à l’instance par son nom d’origine ou par le nom affecté au point de terminaison virtuel d’écriture. Lieu Le nom d'une des régions dans lesquelles le service est pris en charge. La restauration ponctuelle ne prend en charge que le déploiement du nouveau serveur dans la même région que celle où se trouve le serveur source. Lorsque vous choisissez la région, tenez compte de la conformité, la résidence des données, la tarification, la proximité de vos utilisateurs ou la disponibilité d’autres services dans la même région. Le service n’offre pas de fonctionnalité permettant de déplacer automatiquement et de manière transparente une instance vers une autre région. Calcul + stockage Attribue le même type et la même taille de calcul et la même taille de stockage que ceux utilisés par le serveur source au moment de la restauration de la sauvegarde. Toutefois, si vous sélectionnez le lien Configurer le serveur, vous pouvez modifier le type de stockage alloué au nouveau serveur et indiquer s'il doit ou non être doté de sauvegardes géo-redondantes. Une fois le nouveau serveur déployé, ses options de calcul peuvent être augmentées ou réduites. Zone de disponibilité Votre zone de disponibilité préférée. Vous pouvez choisir dans quelle zone de disponibilité déployer votre serveur. Vous pouvez choisir la zone de disponibilité dans laquelle votre instance est déployée, ce qui est utile pour la colocaliser avec votre application. Si vous choisissez Aucune préférence, une zone de disponibilité par défaut est automatiquement affectée à votre instance lors de sa création. Bien que la zone de disponibilité où une instance est déployée ne puisse pas être modifiée après sa création, vous pouvez utiliser la fonctionnalité de récupération à un instant donné pour restaurer le serveur sous un autre nom sur une autre zone de disponibilité. Authentification Ces paramètres sont uniquement informatifs. Tous les paramètres liés à l’authentification utilisée par le réplica en lecture sont hérités du serveur principal. Peut être modifié sur le serveur principal et tous les réplicas en lecture existants. Si vous souhaitez modifier le niveau de calcul, le processeur ou la taille automatiquement attribué au nouveau serveur, ou si vous souhaitez modifier certains des paramètres de stockage du réplica en lecture, sélectionnez Configurer le serveur.
Le calcul + stockage s’ouvre pour afficher les options de calcul et de stockage du nouveau serveur.
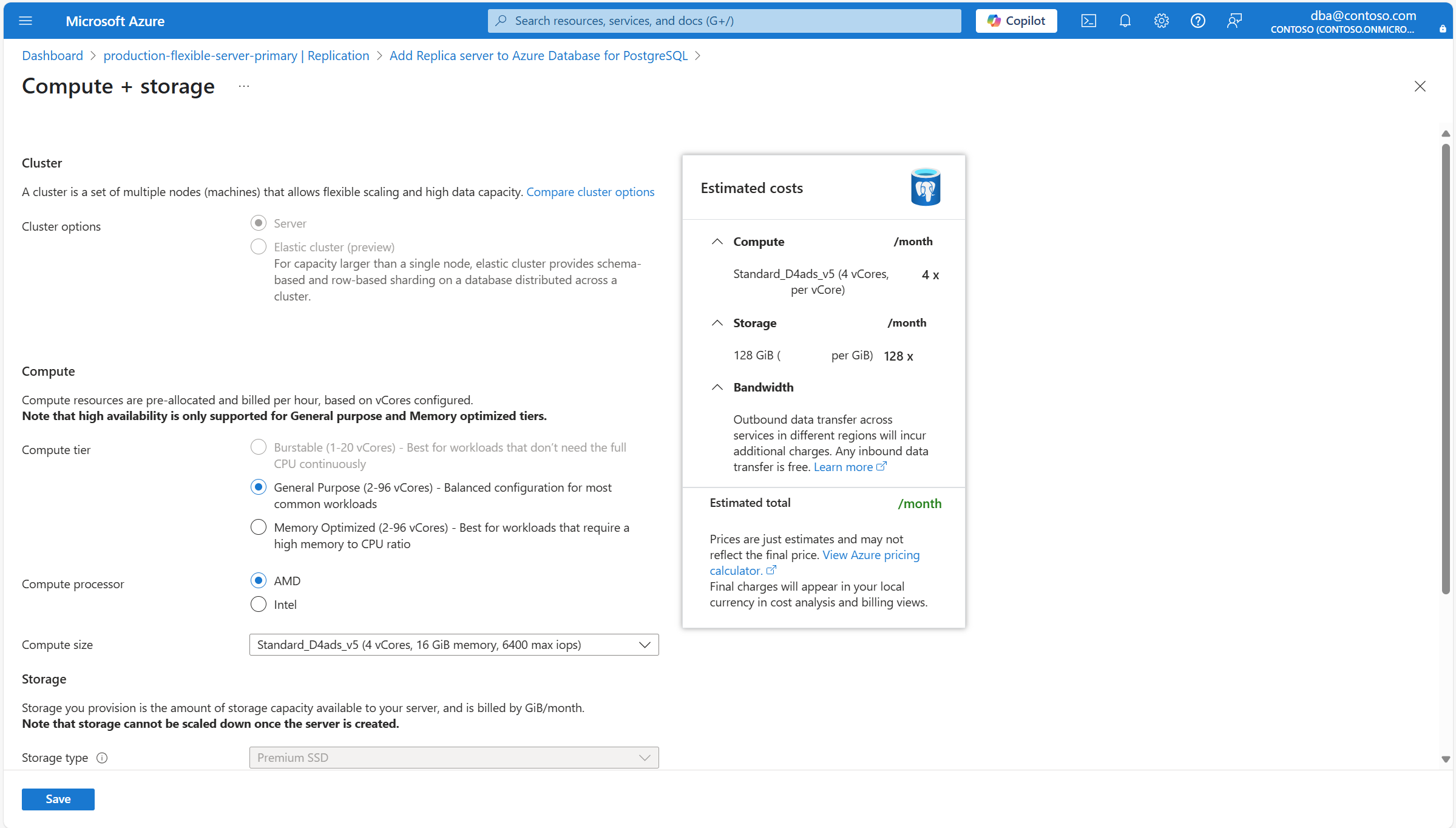
Utilisez le tableau suivant pour comprendre la signification des différents champs disponibles dans la page Calcul + stockage , et comme conseils pour remplir la page.
Section Réglage Valeur suggérée Descriptif Peut être modifié après la création du réplica en lecture Calculer Niveau de calcul Par défaut, il est automatiquement défini sur le même niveau affecté au serveur principal. Toutefois, vous pouvez le définir sur n’importe quel autre niveau de calcul sur lequel les réplicas en lecture sont pris en charge. Les valeurs possibles sont usage général (généralement utilisées pour les environnements de production avec les charges de travail les plus courantes) et optimisées en mémoire (généralement utilisées pour les environnements de production exécutant des charges de travail nécessitant un ratio mémoire/processeur élevé). Pour plus d’informations, consultez les options de calcul dans Azure Database pour PostgreSQL. Peut être modifié une fois le réplica en lecture créé. Toutefois, si vous utilisez certaines fonctionnalités qui sont uniquement prises en charge sur certains niveaux et que vous remplacez le niveau actuel par un niveau dans lequel la fonctionnalité n’est pas prise en charge, la fonctionnalité cesse d’être disponible ou est désactivée. Taille de calcul Par défaut, elle est automatiquement définie sur la même taille de calcul affectée au serveur principal. Toutefois, vous pouvez la définir sur n’importe quelle autre taille de calcul, tant qu’elle a le même ou un nombre supérieur de vCores que le serveur principal. Notez que la liste des valeurs prises en charge peut varier d’une région à l’autre, en fonction du matériel disponible sur chaque région. Pour plus d’informations, consultez les options de calcul dans Azure Database pour PostgreSQL. Peut être modifié une fois le réplica en lecture créé. Stockage Type de stockage Laissez-le tel qu’il est configuré SSD Premium. La définition du type de stockage sur une valeur différente de celle du serveur principal n’est pas prise en charge. L’Assistant définit automatiquement cette propriété pour qu’elle corresponde au type de stockage affecté au serveur principal. Impossible à modifier une fois le réplica en lecture créé. Taille du stockage Par défaut, elle est définie sur la même valeur que la taille de stockage du serveur principal. Toutefois, elle peut être définie sur n’importe quelle valeur plus élevée. Peut être modifié après la création de l’instance de réplica en lecture. Il peut uniquement être augmenté. La réduction manuelle ou automatique du stockage n’est pas prise en charge. Niveau de performance Par défaut, elle est automatiquement définie sur la même valeur que le serveur principal. Toutefois, elle peut être modifiée en une autre valeur. Les performances des disques SSD Premium sont définies à la création du disque, sous la forme de leur niveau de performance. Lorsque vous définissez la taille approvisionnée de votre disque, un niveau de performance est sélectionné automatiquement. Ce niveau de performance détermine les IOPS et le débit de votre disque managé. Pour les disques SSD Premium, vous pouvez modifier ce niveau au moment du déploiement ou par la suite, sans changer de taille de disque et sans temps d’arrêt. La modification du niveau vous permet de vous préparer et de répondre à une demande plus importante sans utiliser la capacité de bursting de votre disque. Il peut être plus rentable de changer de niveau de performance plutôt que de recourir au bursting, selon la durée pendant laquelle la performance supplémentaire est nécessaire. C'est la solution idéale pour les événements qui nécessitent temporairement un niveau de performance plus élevé. Des événements tels que les achats de Noël, les tests de performance ou la mise en place d'un environnement de formation. Pour traiter ces événements, vous pouvez basculer un disque vers un niveau de performance plus élevé sans temps d’arrêt, tant que vous avez besoin de performance supplémentaire. Vous pouvez ensuite revenir au niveau d’origine sans temps d’arrêt quand vous n’avez plus besoin de performance supplémentaire. Peut être modifié après la création de l’instance. Croissance automatique de stockage Ne peut être modifié et est automatiquement fixé à la même valeur que le serveur source. Il est possible que cette option ne soit pas prise en charge pour certains types de stockage et ne soit pas honorée pour certaines tailles de stockage. Pour plus d’informations, consultez Configurer la croissance automatique du stockage. Peut être modifié après la création de l’instance, tant que le type de stockage prend en charge cette fonctionnalité. Passez aux onglets Réseau, Sécurité ou Balises , si vous devez modifier l’un des paramètres autorisés à différer du serveur principal. Une fois que le nouveau serveur est configuré selon vos besoins, sélectionnez Vérifier + créer.
Vérifiez que toutes les configurations du nouveau déploiement sont correctement définies, puis sélectionnez Créer.
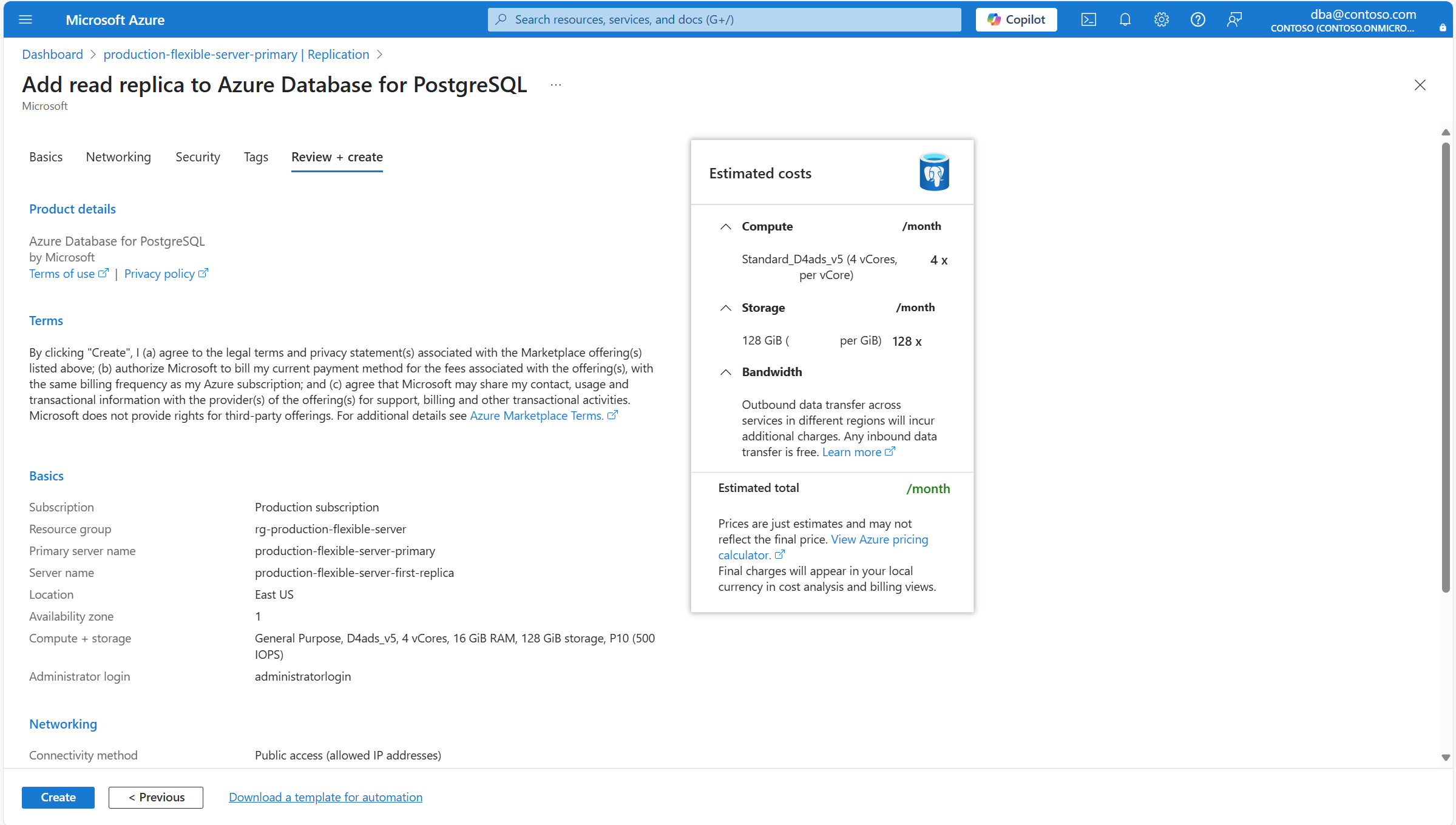
Un nouveau déploiement est lancé pour créer votre instance de serveur flexible de base de données Azure pour PostgreSQL et en faire une réplique en lecture du serveur principal.
Une fois le déploiement terminé, vous pouvez sélectionner Accéder à la ressource pour commencer à utiliser votre nouvelle instance de serveur flexible Azure Database pour PostgreSQL.
Vous accédez à la page Vue d’ensemble du serveur réplica.
Dans le menu de la ressource, sous la section Paramètres , sélectionnez Réplication. Sous Serveurs, recherchez la liste des serveurs conformes au jeu de réplication et le rôle que chacun d’entre eux prend.