Vous voulez en savoir plus sur Service Fabric ?
Azure Service Fabric est une plateforme de systèmes distribués qui permet d’empaqueter, de déployer et de gérer facilement des microservices scalables et fiables. Service Fabric dispose d’une grande surface d’exposition et il y a beaucoup d’informations à découvrir. Cet article fournit une synthèse de Service Fabric et décrit les concepts fondamentaux, les modèles de programmation, le cycle de vie d’application, les tests, les clusters et la surveillance de l’intégrité. Consultez Vue d’ensemble et Que sont les microservices ? pour obtenir une présentation et savoir comment utiliser Service Fabric pour créer des microservices. Cet article ne donne pas la liste complète du contenu, mais fournit un lien vers des articles de présentation et de prise en main pour chaque zone de Service Fabric.
Principaux concepts
Les articles Terminologie Service Fabric, Modèle d’application et Modèles de programmation pris en charge contiennent des concepts et des descriptions supplémentaires, mais voici les informations de base.
- Cluster Service Fabric : Consultez ce lien pour voir une vidéo de formation présentant l’architecture Service Fabric et ses principaux concepts, et explorer les nombreuses fonctionnalités de Service Fabric.
- Concepts d’exécution : Consultez ce lien pour voir une vidéo de formation expliquant les concepts d’exécution et les bonnes pratiques de Service Fabric.
- Concepts de type de conception : Consultez ce lien pour voir une vidéo de formation expliquant l’application, l’empaquetage et le déploiement, ainsi que la terminologie, les abstractions et les concepts clés de Service Fabric.
Au moment du design : type de service, package et manifeste de service, type d’application, package et manifeste d’application
Un type de service est le nom/la version affectés aux packages de code, aux packages de données et aux packages de configuration d’un service. Il est défini dans un fichier ServiceManifest.xml. Ce type de service comprend les paramètres de configuration du service et le code exécutable, qui sont chargés lors de l’exécution, ainsi que les données statiques qui sont consommées par le service.
Un package de service est un répertoire de disque contenant le fichier ServiceManifest.xml du type de service, qui fait référence au code, aux données statiques et aux packages de configuration pour le type de service. Par exemple, un package de services peut faire référence au code, aux données statiques et aux packages de configuration qui composent un service de base de données.
Un type d’application est le nom/la version affectés à un ensemble de types de service. Il est défini dans un fichier ApplicationManifest.xml.
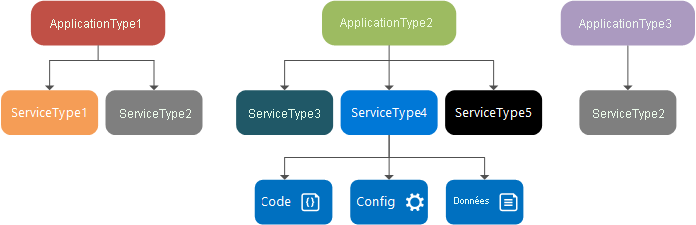
Le package d’application est un répertoire de disque contenant le fichier ApplicationManifest.xml du type d’application, qui fait référence aux packages de service de chaque type de service qui constitue le type d’application. Par exemple, un package d’un type d’application de messagerie peut contenir des références à un package de services de File d’attente, un package de services frontaux et un package de services de base de données.
Les fichiers du répertoire de package d’application sont copiés dans le magasin d’images du cluster Service Fabric. Vous pouvez ensuite créer une application nommée à partir de ce type d’application et l’exécuter au sein du cluster. Après avoir créé une application nommée, vous pouvez créer un service nommé à partir d’un des types de service du type d’application.
En cours d’exécution : clusters et nœuds, applications nommées, services nommés, partitions et réplicas
Un cluster Service Fabric est un groupe de machines virtuelles ou physiques connectées au réseau, sur lequel vos microservices sont déployés et gérés. Les clusters peuvent être mis à l’échelle pour des milliers de machines.
Une machine ou une machine virtuelle appartenant à un cluster est appelée « nœud ». Un nom (chaîne) est affecté à chaque nœud. Les nœuds présentent des caractéristiques, telles que des propriétés de placement. Chaque machine ou machine virtuelle a un service Windows à démarrage automatique, FabricHost.exe, qui commence à s’exécuter dès le démarrage, puis démarre deux exécutables : Fabric.exe et FabricGateway.exe. Ces deux exécutables constituent le nœud. Pour développer des scénarios de test, vous pouvez héberger plusieurs nœuds sur une seule et même machine ou machine virtuelle en exécutant plusieurs instances de Fabric.exe et de FabricGateway.exe.
Une application nommée est un ensemble de services nommés qui exécute une ou plusieurs fonctions. Un service exécute une fonction complète et autonome (il peut démarrer et s'exécuter indépendamment des autres services) et est composé de code, d’une configuration et de données. Une fois qu’un package d’application est copié dans le magasin d’images, vous créez une instance de l’application au sein du cluster en spécifiant le type d’application du package d’application (à l’aide de son nom/sa version). Chaque instance de type d’application se voit affecter un nom d’URI ressemblant à ceci : fabric:/MonApplicationNommée. Dans un cluster, vous pouvez créer plusieurs applications nommées à partir d’un seul type d’application. Vous pouvez également en créer à partir de différents types d’application. Chaque application nommée est gérée, et sa version est gérée indépendamment.
Après avoir créé une application nommée, vous pouvez créer une instance de l’un de ses types de service (un service nommé) au sein du cluster en spécifiant le type de service (à l’aide de son nom/sa version). Chaque instance du type de service reçoit un nom d’URI inclus dans l’étendue de l’URI de son application nommée. Par exemple, si vous créez un service nommé « MaBaseDeDonnées » dans une application nommée « MonApplicationNommée », l’URI ressemble à ceci : fabric:/MonApplicationNommée/MaBaseDeDonnées. Dans une application nommée, vous pouvez créer un ou plusieurs services nommés. Chaque service nommé peut posséder son propre schéma de partition et son propre nombre d’instances/réplicas.
Il existe deux types de services : sans état et avec état. Les services sans état ne stockent pas l’état au sein du service. Les services sans état n’ont aucun stockage persistant ou sont stockés à l’état persistant dans un service de stockage externe tel que Stockage Azure, Azure SQL Database ou Azure Cosmos DB. Un service avec état stocke à l’état au sein du service et utilise des modèles de programmation collections fiables ou Reliable Actors pour gérer l’état de votre service.
Lors de la création d’un service nommé, vous indiquez un schéma de partition. Les services comportant de grandes quantités d’état fractionnent les données entre les partitions. Chaque partition est responsable d’une partie de l’état complet du service, répartie entre les nœuds du cluster.
Le diagramme suivant montre la relation entre les applications et les instances de service, les partitions et les réplicas.
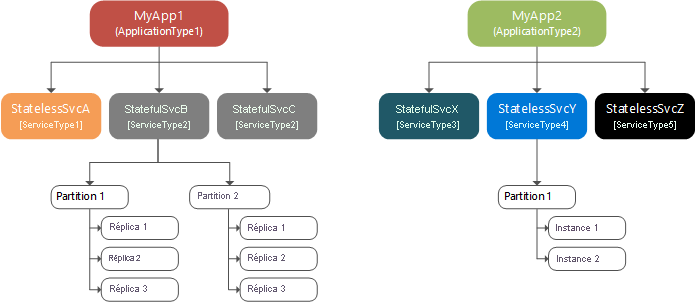
Partitionnement, mise à l’échelle et disponibilité
Le partitionnement n’est pas propre à Service Fabric. Le partitionnement des données constitue une forme bien connue de partitionnement. Les services avec état comportant de grandes quantités d’état fractionnent les données entre les partitions. Chaque partition est responsable d’une partie de l’état complet du service.
Les réplicas de chaque partition sont répartis entre les nœuds du cluster, ce qui permet à l’état de votre service nommé d’être mis à l’échelle. En même temps que les besoins en matière de données augmentent, les partitions augmentent aussi et Service Fabric rééquilibre les partitions entre les nœuds pour une utilisation efficace des ressources matérielles. Si vous ajoutez des nœuds au cluster, Service Fabric rééquilibrera les réplicas de partition sur le nombre de nœuds augmenté. Les performances globales de l’application s’améliorent tandis que le conflit d’accès à la mémoire diminue. Si les nœuds du cluster ne sont pas utilisés efficacement, vous pouvez diminuer le nombre de nœuds dans le cluster. Service Fabric rééquilibre à nouveau les réplicas de partition sur le nombre réduit de nœuds afin de mieux utiliser le matériel sur chaque nœud.
Dans une partition, les services nommés sans état ont des instances tandis que les services nommés avec état ont des réplicas. En règle générale, les services nommés sans état ne possèdent qu’une partition puisqu’ils sont dépourvus d’état interne, bien qu’il existe des exceptions. Les instances de partition prévoient la disponibilité. Si une instance échoue, les autres continuent à fonctionner normalement et Service Fabric crée ensuite une nouvelle instance. Les services nommés avec état conservent leur état dans les réplicas, et chaque partition possède son propre jeu de réplicas. Les opérations de lecture et d’écriture sont effectuées sur un seul réplica (appelé réplica principal). Les modifications de l’état en raison des opérations d’écriture sont répliquées sur plusieurs autres réplicas (appelés réplicas secondaires actifs). En cas d’échec d’un réplica, Service Fabric en génère un nouveau à partir des réplicas existants.
Microservices avec et sans état pour Service Fabric
Service Fabric permet de créer des applications composées de microservices ou de conteneurs. Les microservices sans état (tels que les passerelles de protocole et les proxys web) ne conservent pas un état mutable en dehors d’une demande du service et de sa réponse. Les rôles de travail Azure Cloud Services sont un exemple de service sans état. Les microservices avec état (tels que les comptes d’utilisateur, les bases de données, les appareils, les paniers d’achat et les files d’attente) conservent un état mutable faisant autorité au-delà de la demande et la réponse. Actuellement, les applications Internet sont constituées d’une combinaison de microservices avec et sans état.
La principale différence avec Service Fabric est sa préférence marquée pour la création de services avec état, que ce soit avec les modèles de programmation intégrés ou avec des services avec état conteneurisés. Les scénarios d’application décrivent les scénarios dans lesquels les services avec état sont utilisés.
Pourquoi utiliser des microservices avec état et sans état ? Voici les deux principales raisons :
- Vous pouvez créer des services de traitement transactionnel en ligne (OLTP) à débit élevé, faible latence et tolérance de panne en conservant le code proche des données sur le même ordinateur. Quelques exemples : vitrines interactives, recherche, systèmes Internet des objets (IoT), systèmes commerciaux, systèmes de détection des fraudes et de traitement des cartes de crédit et gestion des enregistrements personnels.
- Vous pouvez simplifier la conception d’applications. Les microservices avec état permettent de supprimer les caches et files d’attente supplémentaires, jusque-là indispensables pour répondre aux exigences de disponibilité et de latence d’une application purement sans état. Les services avec état sont naturellement hautement disponibles et à faible latence, ce qui réduit le nombre d’éléments mobiles à gérer au sein de votre application.
Modèles de programmation pris en charge
Service Fabric offre plusieurs méthodes pour écrire et gérer vos services. Les services peuvent utiliser les API Service Fabric pour tirer pleinement parti des infrastructures d’application et des fonctionnalités de la plateforme. Les services peuvent être n’importe quel programme exécutable compilé, écrit dans n’importe quel langage et hébergé sur un cluster Service Fabric. Pour plus d’informations, consultez Vue d’ensemble des modèles de programmation Service Fabric.
Containers
Par défaut, Service Fabric déploie et active les services en tant que processus. Service Fabric permet également de déployer les services dans des conteneurs. Important : dans les conteneurs, vous pouvez combiner des processus et des services au sein de la même application. Service Fabric prend en charge le déploiement de conteneurs Linux et de conteneurs Windows sur Windows Server 2016. Vous pouvez déployer des applications, des services sans état ou des services avec état dans des conteneurs.
Services fiables (Reliable Services)
Reliable Services est une infrastructure légère permettant de créer des services qui s’intègrent dans la plateforme Service Fabric et exploitent l’ensemble de ses fonctionnalités. Ces services Reliable Services peuvent être sans état (comme la plupart des plateformes de service, par exemple les serveurs web ou les rôles de travail dans Azure Cloud Services). L’état est alors conservé dans une solution externe, telle qu’Azure DB ou Stockage Table Azure. Les services Reliable Services peuvent également être avec état, auquel cas l’état est conservé directement dans le service lui-même à l’aide de Reliable Collections. L’état est hautement disponible grâce à la réplication et distribué grâce au partitionnement, l’ensemble étant géré automatiquement par Service Fabric.
Acteurs fiables (Reliable Actors)
Reposant sur Reliable Services, l’infrastructure Reliable Actor est une infrastructure d’application qui implémente le modèle Virtual Actor, selon le modèle de conception des acteurs. L'infrastructure Reliable Actor utilise des unités indépendantes d'état et de calcul avec exécution monothread, nommées acteurs. L'infrastructure Reliable Actor fournit une communication intégrée aux acteurs, ainsi que des configurations prédéfinies de persistance d’état et de montée en charge.
ASP.NET Core
Service Fabric s’intègre à ASP.NET Core comme un modèle de programmation de premier ordre pour la création d’applications web et API. L’infrastructure ASP.NET Core peut être utilisée de deux manières dans Service Fabric :
- Hébergée en tant qu’exécutable invité. Cette méthode est principalement utilisée pour exécuter des applications ASP.NET Core existantes sur Service Fabric sans modification de code.
- Exécutée dans un service fiable. Cette méthode permet des services ASP.NET Core avec état ainsi qu’une meilleure intégration au runtime Service Fabric.
Exécutables invités
Un exécutable d’invité est un exécutable existant quelconque (écrit dans n’importe quel langage) qui est hébergé sur un cluster Service Fabric avec d’autres services. Les exécutables invités ne s’intègrent pas directement dans les API Service Fabric. Cependant, ils bénéficient toujours des fonctionnalités offertes par la plateforme, comme la création de rapports d’intégrité et de chargement personnalisés et la détectabilité des services par le biais d’un appel aux API REST. Ils prennent également en charge le cycle de vie complet des applications.
Cycle de vie des applications
Comme pour les autres plateformes, une application sur Service Fabric passe généralement par les phases suivantes : conception, développement, test, déploiement, mise à niveau, maintenance et suppression. Service Fabric offre une excellente prise en charge du cycle de vie complet des applications cloud : du développement au retrait éventuel, en passant par le déploiement, la gestion quotidienne et la maintenance. Le modèle de service permet à différents rôles de participer indépendamment au cycle de vie des applications. L’article Cycle de vie des applications Service Fabric fournit une vue d'ensemble des API et de la façon dont elles sont utilisées par les différents rôles pendant les phases du cycle de vie des applications Service Fabric.
L’intégralité du cycle de vie des applications peut être gérée avec des cmdlets PowerShell, des commandes CLI, des API C#, des API Java et des API REST. Vous pouvez également configurer des pipelines d’intégration continue ou de développement continu à l’aide d’outils tels que Azure Pipelines ou Jenkins.
Tester des applications et services
Pour créer des services véritablement cloud, il est primordial de vérifier que vos applications et services peuvent résister à des défaillances réalistes. Le service d’analyse des erreurs est conçu pour tester les services qui s’appuient sur Service Fabric. Avec le service d’analyse des erreurs, vous pouvez provoquer des erreurs significatives et exécuter des scénarios de test complets sur vos applications. Ces erreurs et scénarios exercent et valident les nombreux états et transitions qu’un service connaît tout au long de sa durée de vie, le tout de manière contrôlée, sécurisée et cohérente.
Les actions ciblent un service à tester à l’aide d’erreurs isolées. Un développeur de services peut les utiliser en tant blocs de constructions afin d’écrire des scénarios compliqués. Exemples d’erreurs simulées :
- Redémarrez un nœud pour simuler différentes situations dans lesquelles une machine ou une machine virtuelle est redémarrée.
- Déplacez un réplica de votre service avec état pour simuler l’équilibrage de charge, le basculement ou la mise à niveau de l’application.
- Appelez la perte de quorum sur votre service avec état afin de créer une situation où les opérations d’écriture sont interrompues en raison d’un nombre insuffisant de réplicas de sauvegarde ou secondaire pour l’acceptation des nouvelles données.
- Appelez la perte des données sur un service avec état pour créer une situation où l’intégralité de l’état en mémoire est effacé.
Les scénarios sont des opérations complexes composées d’une ou plusieurs actions. Le service d’analyse des erreurs fournit deux scénarios complets intégrés :
- Scénario de chaos : au sein du cluster, le chaos simule des erreurs entrelacées en continu (avec et sans perte de données) sur des périodes prolongées.
- Scénario de basculement : une version du test chaos qui cible une partition de service spécifique sans affecter les autres services.
Clusters
Un cluster Service Fabric est un groupe de machines virtuelles ou physiques connectées au réseau, sur lequel vos microservices sont déployés et gérés. Les clusters peuvent être mis à l’échelle pour des milliers de machines. Une machine ou machine virtuelle faisant partie d’un cluster est appelée un nœud de cluster. Un nom (chaîne) est affecté à chaque nœud. Les nœuds présentent des caractéristiques, telles que des propriétés de placement. Chaque machine ou machine virtuelle est dotée d’un service à démarrage automatique, FabricHost.exe, qui s’exécute au démarrage, puis lance deux exécutables : Fabric.exe et FabricGateway.exe. Ces deux exécutables constituent le nœud. Pour les scénarios de test, vous pouvez héberger plusieurs nœuds sur une seule et même machine ou sur une seule et même machine virtuelle en exécutant plusieurs instances de Fabric.exe et FabricGateway.exe.
Les clusters Service Fabric peuvent être créés sur des machines virtuelles ou physiques exécutant Windows Server ou Linux. Vous pouvez ainsi déployer et exécuter des applications Service Fabric dans n’importe quel environnement dans lequel des ordinateurs Windows Server ou Linux sont interconnectés, que ce soit en local, sur Microsoft Azure ou via un fournisseur cloud.
Clusters sur Azure
L’exécution de clusters Service Fabric dans Azure permet d’intégrer d’autres fonctionnalités et services Azure qui rendent l’exploitation et la gestion du cluster plus simple et plus fiable. Comme un cluster est une ressource Azure Resource Manager, vous pouvez modéliser des clusters comme n’importe quelle autre ressource dans Azure. En outre, le Gestionnaire des ressources facilite la gestion de toutes les ressources utilisées par le cluster comme une seule unité. Les clusters dans Azure sont intégrés aux journaux Diagnostics Azure et Log Analytics. Les types de nœuds de cluster sont des groupes de machines virtuelles identiques : la fonctionnalité de mise à l’échelle automatique est donc intégrée.
Vous pouvez créer un cluster dans Azure via le portail Azure, à partir d’un modèle ou à partir de Visual Studio.
Service Fabric sous Linux permet de créer, de déployer et de gérer des applications hautement disponibles et extensibles sous Linux de la même manière que sous Windows. Les frameworks Service Fabric (Reliable Services et Reliable Actors) sont disponibles dans Java sous Linux, en plus de C# (.NET Core). Vous pouvez également créer des services exécutables invités via tous les langages ou frameworks. L’orchestration de conteneurs Docker est également prise en charge. Les conteneurs Docker peuvent lancer des exécutables invités ou des services Service Fabric natifs, qui ont recours à des frameworks Service Fabric. Pour plus d’informations, consultez la page Service Fabric sous Linux.
Certaines fonctionnalités sont prises en charge sous Windows, mais pas sous Linux. Pour en savoir plus, consultez Différences entre Service Fabric sur Linux et Windows.
Clusters autonomes
Service Fabric fournit un package d’installation vous permettant de créer des clusters Service Fabric sur site ou sur n’importe que fournisseur cloud. Les clusters autonomes vous offrent la possibilité d’héberger un cluster où vous le souhaitez. Si vos données sont soumises à des contraintes réglementaires ou de conformité, ou si vous souhaitez que vos données restent locales, vous pouvez héberger votre propre cluster et vos propres applications. Comme les applications Service Fabric peuvent s’exécuter dans plusieurs environnements d’hébergement sans aucune modification, vos connaissances en matière de génération d’applications s’appliquent d’un environnement d’hébergement à un autre.
Créer votre premier cluster Service Fabric autonome
Les clusters autonomes Linux ne sont pas encore pris en charge.
Sécurité des clusters
Les clusters doivent être sécurisés pour empêcher les utilisateurs non autorisés de se connecter à votre cluster, surtout quand des charges de travail sont en cours d’exécution sur ce dernier. Bien qu’il soit possible de créer un cluster non sécurisé, cela permet à tout utilisateur anonyme de s’y connecter si les points de terminaison de gestion sont exposés sur l’Internet public. Il n’est pas possible d’activer ultérieurement la sécurité sur un cluster non sécurisée : la sécurité du cluster est activée au moment de la création du cluster.
Les scénarios de sécurité des clusters sont les suivants :
- Sécurité nœud à nœud
- Sécurité client à nœud
- Contrôle d’accès en fonction du rôle Service Fabric
Pour plus d’informations, consultez Sécuriser un cluster.
Mise à l'échelle
Si vous ajoutez des nœuds au cluster, Service Fabric rééquilibrera les réplicas de partition et les instances sur le nombre de nœuds augmenté. Les performances globales de l’application s’améliorent tandis que le conflit d’accès à la mémoire diminue. Si les nœuds du cluster ne sont pas utilisés efficacement, vous pouvez diminuer le nombre de nœuds dans le cluster. Service Fabric rééquilibre à nouveau les réplicas de partition et les instances sur le nombre réduit de nœuds afin de mieux utiliser le matériel sur chaque nœud. Vous pouvez mettre à l’échelle des clusters dans Azure manuellement ou par programmation. Les clusters autonomes peuvent être mis à l’échelle manuellement.
Mise à niveau des clusters
De nouvelles versions du runtime Service Fabric sont régulièrement publiées. Effectuez des mises à niveau de runtime, ou de structure, sur votre cluster afin de toujours utiliser une version prise en charge. En plus des mises à niveau de structure, vous pouvez également mettre à jour la configuration du cluster telle que les certificats ou les ports de l’application.
Un cluster Service Fabric est une ressource que vous possédez mais qui est en partie gérée par Microsoft. Microsoft est responsable de la mise à jour corrective du système d’exploitation sous-jacent et des mises à niveau de structure sur votre cluster. Vous pouvez définir votre cluster de façon à recevoir des mises à niveau de structure automatiques, lorsque Microsoft publie une nouvelle version, ou opter pour la sélection de la version de structure prise en charge de votre choix. Les mises à niveau de structure et de configuration peuvent être définies via le portail Azure ou via le Gestionnaire des ressources. Pour plus d’informations, consultez Mettre à niveau un cluster Service Fabric.
Un cluster autonome est une ressource que vous possédez entièrement. Vous êtes responsable de la mise à jour corrective du système d’exploitation sous-jacent et des mises à niveau de structure. Si votre cluster peut se connecter à https://www.microsoft.com/download, vous pouvez le définir de façon à se qu’il télécharge et approvisionne automatiquement le nouveau package runtime Service Fabric. Vous devrez ensuite lancer la mise à niveau. Si votre cluster ne peut pas accéder à https://www.microsoft.com/download, vous pouvez télécharger manuellement le nouveau package runtime à partir d’une machine connectée à Internet puis lancer la mise à niveau. Pour plus d’informations, consultez Mettre à niveau un cluster Service Fabric autonome.
Surveillance de l’intégrité
Service Fabric introduit un modèle d’intégrité conçu pour signaler des conditions de cluster et d’application défectueuses sur des entités spécifiques (telles que des nœuds de cluster et des réplicas de service). Le modèle d’intégrité utilise des rapporteurs d’intégrité (composants système et agents de surveillance). L’objectif consiste en un diagnostic et une réparation simples et rapides. Les enregistreurs de service doivent penser en amont à l’intégrité et comment concevoir des rapports d’intégrité. Toute condition pouvant avoir une incidence sur l’intégrité doit être signalée, surtout si cela peut aider à signaler des problèmes proches de la racine. Les informations sur l’intégrité peuvent vous permettre d’économiser beaucoup de temps et d’efforts en termes de débogage et d’enquête lorsque le service est en cours d’exécution à l’échelle dans la production.
Les rapporteurs Service Fabric surveillent les conditions identifiées qui présentent un intérêt. Ils dressent un rapport sur ces conditions en fonction de leur vue locale. Le magasin d’intégrité agrège les données d’intégrité envoyées par tous les rapporteurs pour déterminer si les entités sont globalement intègres. Le modèle doit être riche, flexible et facile à utiliser. La qualité des rapports d’intégrité détermine la précision de la vue d’intégrité du cluster. Des faux positifs qui indiquent erronément des problèmes d’intégrité peuvent avoir une incidence négative sur les mises à niveau ou autres services utilisant des données d’intégrité. Les services de réparation et mécanismes d’alertes sont des exemples de services de ce type. Par conséquent, une réflexion est nécessaire pour générer des rapports qui capturent des conditions pertinentes de la meilleure façon possible.
La création de rapports peut être effectuée à partir des éléments suivants :
- L’instance ou le réplica de service Service Fabric surveillé.
- Les agents de surveillance internes déployés en tant que services Service Fabric (par exemple, un service Service Fabric sans état, qui surveille des conditions et émet des rapports). Les agents de surveillance peuvent être déployés sur tous les nœuds ou apparentés au service surveillé.
- Les agents de surveillance internes qui s’exécutent sur les nœuds Service Fabric, mais qui ne sont pas implémentés en tant que services de Service Fabric.
- Les agents de surveillance externes qui sondent la ressource à partir de l’extérieur du cluster Service Fabric (par exemple, un service de surveillance de type Gomez).
Sans configuration préalable, les composants Service Fabric signalent l'intégrité de toutes les entités du cluster. Les rapports d’intégrité du système procurent une visibilité sur les fonctionnalités du cluster et des applications, et signalent les problèmes d’intégrité. Pour les applications et services, les rapports d’intégrité du système vérifient que les entités sont implémentées et qu’elles se comportent correctement du point de vue du runtime Service Fabric. Les rapports ne fournissent aucune information sur l’intégrité de la logique métier du service ni sur la détection des processus qui ont cessé de répondre. Pour ajouter des informations de contrôle d’intégrité spécifiques à la logique de votre service, mettez en œuvre la création de rapports d’intégrité personnalisée dans vos services.
Service Fabric offre plusieurs façons d’afficher des rapports d’intégrité qui sont regroupées dans le magasin d’intégrité :
- Service Fabric Explorer ou autres outils de visualisation.
- Requêtes d’intégrité (par l’intermédiaire de PowerShell, de l’interface CLI, des API FabricClient C# et des API FabricClient Java, ou des API REST).
- Requêtes générales renvoyant une liste d’entités qui possèdent une propriété d’intégrité (par l’intermédiaire de PowerShell, de l’interface CLI, des API ou de REST).
Surveillance et diagnostics
La surveillance et les diagnostics sont essentiels au développement, au test et au déploiement d’applications et de services dans tout environnement. Les solutions Service Fabric conviennent mieux pour planifier et implémenter une surveillance et des diagnostics afin de s’assurer que les applications et services fonctionnent comme prévu dans un environnement de développement local ou de production.
Les principaux objectifs de la surveillance et des diagnostics sont de :
- Détecter et diagnostiquer les problèmes de matériel et d’infrastructure
- Détecter les problèmes des logiciels et applications, et réduire les temps d’arrêt de service
- Comprendre la consommation des ressources et aider aux prises de décision relatives aux opérations
- Optimiser les performances des applications, des services et de l’infrastructure
- Générer des connaissances professionnelles et identifier les domaines d’amélioration
Le flux de travail global de la surveillance et des diagnostics se compose de trois étapes :
- Génération d’événements : il s’agit d’événements (journaux d’activité, traces, événements personnalisés) au niveau de l’infrastructure (cluster), de la plateforme et de l’application/du service.
- Agrégation d’événements : les événements générés doivent être collectés et agrégés pour pouvoir être affichés.
- Analyse : les événements doivent être visualisés et accessibles dans un certain format pour permettre l’analyse et l’affichage souhaités.
Plusieurs produits couvrant ces trois domaines sont disponibles, et vous êtes libre de choisir des technologies différentes pour chacun d’eux. Pour plus d’informations, lisez Monitoring et diagnostics pour Azure Service Fabric.
Étapes suivantes
- Apprenez à créer un cluster dans Azure ou un cluster autonome sur Windows.
- Essayez de créer un service en utilisant les modèles de programmation Reliable Services ou Reliable Actors.
- Découvrez comment migrer à partir de Services cloud.
- Apprenez à surveiller et diagnostiquer les services.
- Apprenez à tester vos applications et services.
- Apprenez à gérer et orchestrer les ressources de cluster.
- Examinez les exemples Service Fabric.
- Découvrez les options de support de Service Fabric.
- Lisez le blog de l’équipe pour des articles et annonces.