Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Comme de nombreux autres services présents dans Azure, Stream Analytics trouve sa grande utilité lorsqu’il est associé à d’autres services pour créer une solution de bout en bout plus étendue. Cet article aborde les solutions Azure Stream Analytics simples ainsi que différents modèles d’architecture. Vous pouvez vous appuyer sur ces modèles pour développer des solutions plus complexes. Les modèles décrits dans cet article sont exploitables dans un large éventail de scénarios. Des exemples de modèles propres aux scénarios sont disponibles dans les Architectures de solution Azure.
Créer une tâche Stream Analytics pour optimiser l'expérience des tableaux de bord en temps réel
Avec Azure Stream Analytics, vous pouvez rapidement mettre en place des alertes et des tableaux de bord en temps réel. Une solution simple ingère des événements à partir d’Event Hubs ou d’IoT Hub, puis alimente le tableau de bord Power BI avec un jeu de données en streaming. Pour plus d’informations, consultez le tutoriel détaillé Analyser les données d’appel frauduleux avec Stream Analytics et visualiser les résultats dans un tableau de bord Power BI.
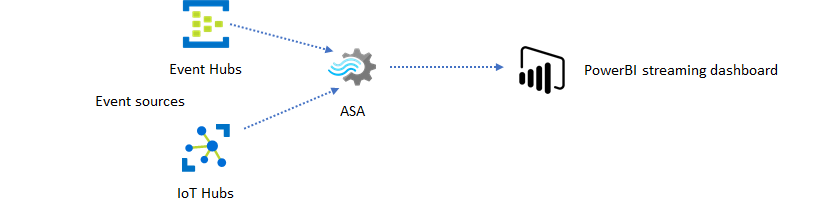
Vous pouvez générer cette solution en quelques minutes à l’aide du portail Azure. Vous n’avez pas besoin de beaucoup coder. Vous pouvez simplement utiliser le langage SQL pour exprimer la logique métier.
Ce modèle de solution offre la plus faible latence, de la source d’événements au tableau de bord Power BI dans un navigateur. Azure Stream Analytics est le seul service Azure comportant cette fonctionnalité intégrée.
Utiliser SQL pour le tableau de bord
Le tableau de bord Power BI offre une faible latence, mais il est inutilisable dans la production de rapports Power BI complets. Un modèle courant de création de rapports consiste d'abord à exporter vos données vers une base de données SQL. Ainsi, utilisez le connecteur SQL de Power BI pour interroger SQL sur les données les plus récentes.
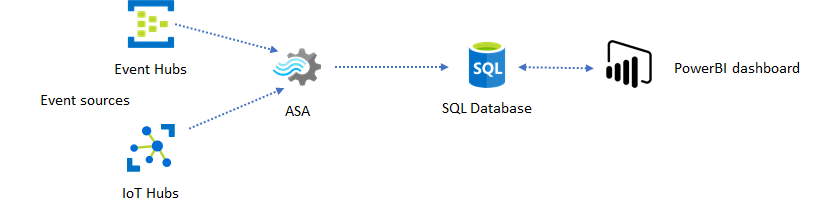
L’utilisation d’une base de données SQL vous offre plus de flexibilité, au détriment d’une latence légèrement plus élevée. Cette solution est optimale pour les travaux dont les exigences en termes de latence sont supérieures à une seconde. Avec cette méthode, vous pouvez augmenter les fonctionnalités de Power BI pour segmenter et traiter les données destinées aux rapports, et de nombreuses autres options de visualisation. Vous gagnez également en flexibilité avec l’utilisation d’autres solutions de tableau de bord, telles que Tableau.
SQL n’est pas une banque de données haut débit. Le débit maximal, vers une base de données SQL depuis Azure Stream Analytics, se situe actuellement autour de 24 Mo/s. Si les sources d’événements de votre solution produisent des données à un taux plus élevé, vous devez utiliser une logique de traitement dans Stream Analytics pour réduire le taux de sortie vers SQL. Vous pouvez utiliser des techniques telles que le filtrage, les agrégats fenêtrés, la correspondance de motifs avec des jointures temporelles et les fonctions analytiques. Vous pouvez optimiser le taux de sortie vers SQL en recourant aux techniques décrites dans l’article Sortie d’Azure Stream Analytics dans Azure SQL Database.
Incorporer des insights en temps réel dans votre application avec la messagerie d’événements
La deuxième utilisation la plus appréciée de Stream Analytics est la création d’alertes en temps réel. Dans ce modèle de solution, vous pouvez utiliser une logique métier dans Stream Analytics afin de détecter les modèles temporels et spatiaux ou les anomalies, et produire ensuite des signaux d’alerte. Toutefois, contrairement à la solution de tableau de bord dans laquelle Stream Analytics utilise Power BI comme point de terminaison par défaut, certains récepteurs de données intermédiaires peuvent être utilisés. Ces puits de données comprennent Hubs d'événements, Bus de Service et Fonctions Azure. Vous, en tant que créateur d’applications, devez décider quel récepteur de données convient le mieux à votre scénario.
Il faut implémenter la logique du consommateur d’événements en aval pour générer des alertes dans votre flux de travail existant. À partir du moment où vous pouvez implémenter une logique personnalisée dans Azure Functions, Azure Functions représente le moyen le plus rapide pour vous d’effectuer cette intégration. Un tutoriel sur l’utilisation d’Azure Functions en tant que sortie de tâche Stream Analytics est disponible dans la section Exécuter Azure Functions à partir des tâches Azure Stream Analytics. Azure Functions prend également en charge différents types de notifications, y compris le texte et les e-mails. Vous pouvez aussi utiliser Logic Apps pour ce genre d’intégration, en plaçant Event Hubs entre Stream Analytics et Logic Apps.
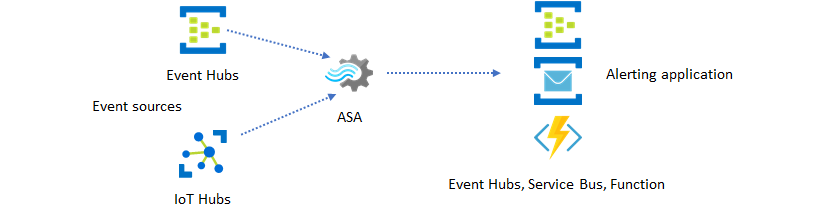
Le service Azure Event Hubs, par ailleurs, offre le point d’intégration le plus souple. De nombreux autres services, comme Azure Data Explorer, peuvent consommer des événements à partir d’Event Hubs. Des services peuvent être connectés directement au récepteur Event Hubs à partir d’Azure Stream Analytics pour terminer la solution. Event Hubs est également le répartiteur de messagerie au débit le plus élevé, disponible sur Azure pour de tels scénarios d’intégration.
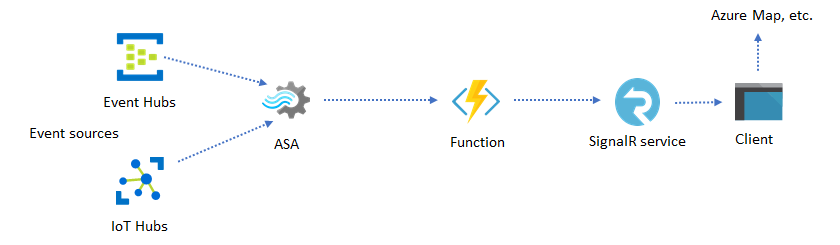
Sites web et applications dynamiques
Vous pouvez créer des visualisations en temps réel personnalisées, telles que la visualisation de tableaux de bord ou de cartes, avec Azure Stream Analytics et Azure SignalR Service. L’utilisation de SignalR permet la mise à jour des clients web et l’affichage du contenu dynamique en temps réel.
Incorporer à votre application des insights en temps réel par le biais de magasins de données
La plupart des services et applications web utilisent aujourd’hui un modèle de requête/réponse pour gérer la couche de présentation. Le modèle de requête/réponse est simple à créer et peut être facilement mis à l’échelle avec un temps de réponse faible, grâce à un front-end sans état et des magasins évolutifs tels qu'Azure Cosmos DB.
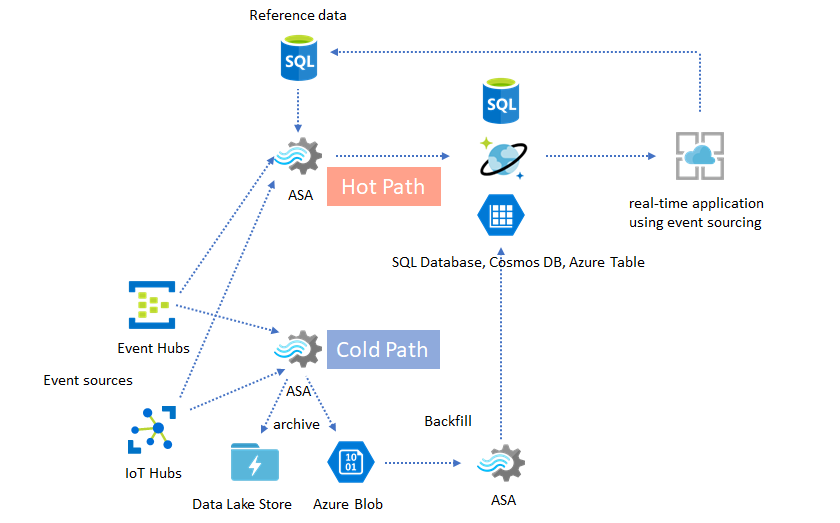
Les volumes importants de données génèrent souvent des goulots d’étranglement dans un système CRUD. Le modèle de solution de provisionnement en événements s’utilise pour résoudre les goulots d’étranglement au niveau des performances. Les modèles temporels et les insights sont également difficiles et peu efficaces à extraire d’un entrepôt de données classique. Les applications modernes basées sur les données volumineuses adoptent souvent une architecture basée sur les dataflows. Azure Stream Analytics, en tant que moteur de calcul pour les données en mouvement, est un élément central dans cette architecture.
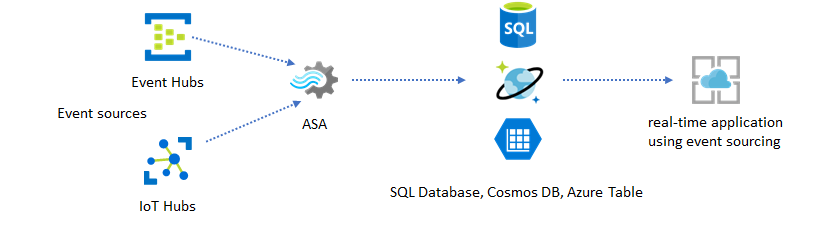
Dans ce modèle de solution, les événements sont traités et agrégés dans des magasins de données par Azure Stream Analytics. La couche d’application interagit avec les magasins de données par l’intermédiaire du modèle de requête/réponse classique. Du fait de la capacité de Stream Analytics à traiter un grand nombre d’événements en temps réel, l’application s’en trouve extrêmement évolutive, sans nécessiter la fourniture en bloc de la couche magasin de données. La couche magasin de données est avant tout une vue matérialisée dans le système. La sortie d’Azure Stream Analytics vers Azure Cosmos DB décrit l’utilisation d’Azure Cosmos DB en tant que sortie Stream Analytics.
Dans les applications réelles, où la logique de traitement est complexe et où il est nécessaire de mettre à niveau certaines parties de la logique séparément, plusieurs tâches Stream Analytics peuvent être combinées avec Event Hubs, en tant que répartiteur d’événements intermédiaire.
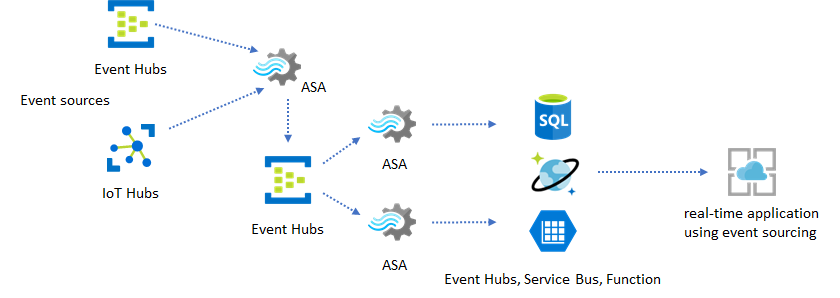
Ce modèle améliore la résilience et facilite la gestion du système. Cependant, même si Stream Analytics garantit le traitement en une seule et unique fois, il existe malgré tout une faible probabilité pour que les événements en double puissent se retrouver dans l’intermédiaire Event Hubs. Il est important pour la tâche Stream Analytics en aval de dédupliquer les événements en utilisant des clés logiques dans une fenêtre de rétrospection. Pour plus d’informations sur la livraison d’événements, consultez la référence de Garanties de livraison d’événements.
Utiliser les données de référence pour la personnalisation des applications
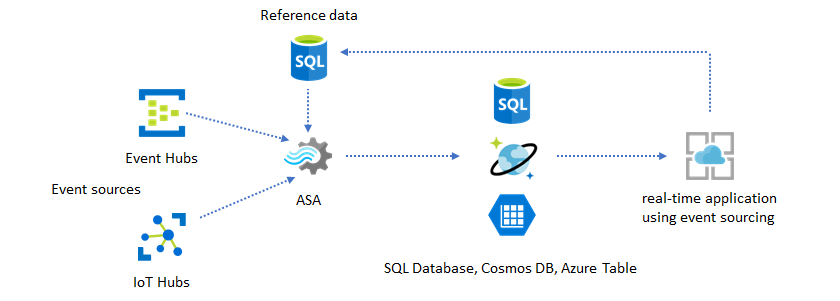
La fonctionnalité des données de référence Azure Stream Analytics est prévue plus particulièrement pour la personnalisation de l’utilisateur final, telles que le seuil d’alerte, les règles de traitement et les limites géographiques. La couche d’application peut accepter les modifications apportées aux paramètres et les stocker dans une base de données SQL. La tâche Stream Analytics interroge régulièrement la base de données pour détecter des modifications et rend les paramètres de personnalisation accessibles par le biais d'une jointure de référence. Pour plus d’informations sur l’utilisation des données de référence pour la personnalisation d’application, consultez Données de référence SQL et Jointure de données de référence.
Ce modèle peut être également utilisé pour implémenter un moteur de règles, où les seuils des règles sont définis à partir de données de référence. Pour plus d’informations sur les règles, consultez Traiter des règles configurables basées sur un seuil dans Azure Stream Analytics.
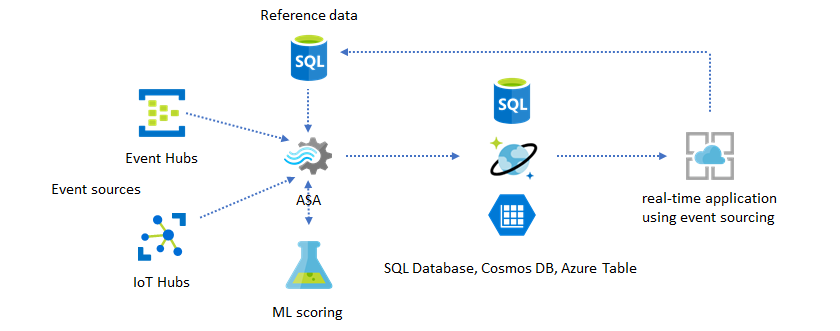
Ajouter Machine Learning à vos insights en temps réel
Le modèle de détection d’anomalie intégrée d’Azure Stream Analytics est un moyen pratique pour introduire Machine Learning dans votre application en temps réel. Pour un large éventail de besoins Machine Learning, vous pouvez déployer des modèles à partir de Azure Machine Learning et les appeler en tant que fonctions définies par l’utilisateur (UDF) dans vos requêtes Stream Analytics. Consultez Intégrer Azure Stream Analytics à Azure Machine Learning.
Pour les utilisateurs avancés qui souhaitent incorporer la formation en ligne et le scoring dans le même pipeline Stream Analytics, consultez cet exemple de procédure avec la régression linéaire.
Entreposage de données en temps réel
L’entreposage de données en quasi temps réel, également appelé entrepôt de données de streaming est un autre modèle courant. En plus des événements arrivant dans Event Hubs et IoT Hub depuis votre application, vous pouvez utiliser Azure Stream Analytics running on IoT Edge pour répondre aux besoins de nettoyage, de réduction ainsi que de stockage et transfert de données. Stream Analytics running on IoT Edge peut gérer convenablement les problèmes de connectivité et de limitation de la bande passante dans le système. Stream Analytics peut prendre en charge des débits allant jusqu’à 200 Mo/s lors de l’écriture dans Azure Synapse Analytics.
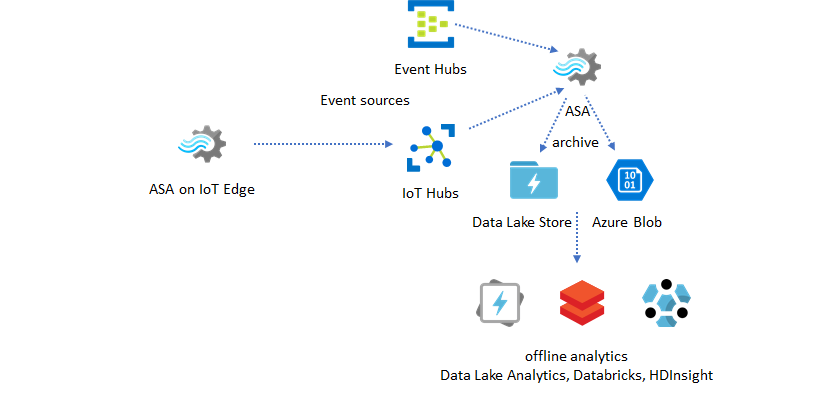
Diagramme montrant un entrepôt de données en temps réel comme destination pour un travail de Stream Analytics.
Archivage des données en temps réel pour l’analytique
La plupart des activités d’analytique et de science des données s’effectuent encore hors connexion. Les données peuvent être archivées sur Azure Stream Analytics via les formats de sortie Azure Data Lake Store Gen2 et Parquet. Cette fonctionnalité supprime les frictions pour alimenter les données directement dans Azure Synapse Analytics, Azure Databricks, Microsoft Fabric et Azure HDInsight. Azure Stream Analytics sert de moteur d'extraction, transformation et chargement (ETL) en quasi temps réel dans cette solution. Vous pouvez explorer des données archivées dans lac de données avec différents moteurs de calcul.
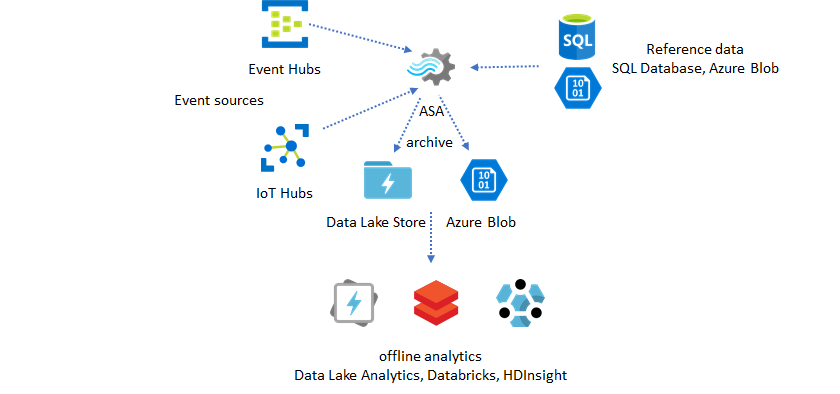
Utiliser les données de référence pour l’enrichissement
L’enrichissement des données constitue souvent une condition exigée pour les moteurs ETL. Azure Stream Analytics prend en charge l’enrichissement des données avec les données de référence provenant de la base de données SQL et du stockage Blob Azure. L’enrichissement des données peut être effectué pour l’arrivage de données dans Azure Data Lake et dans Azure Synapse Analytics.
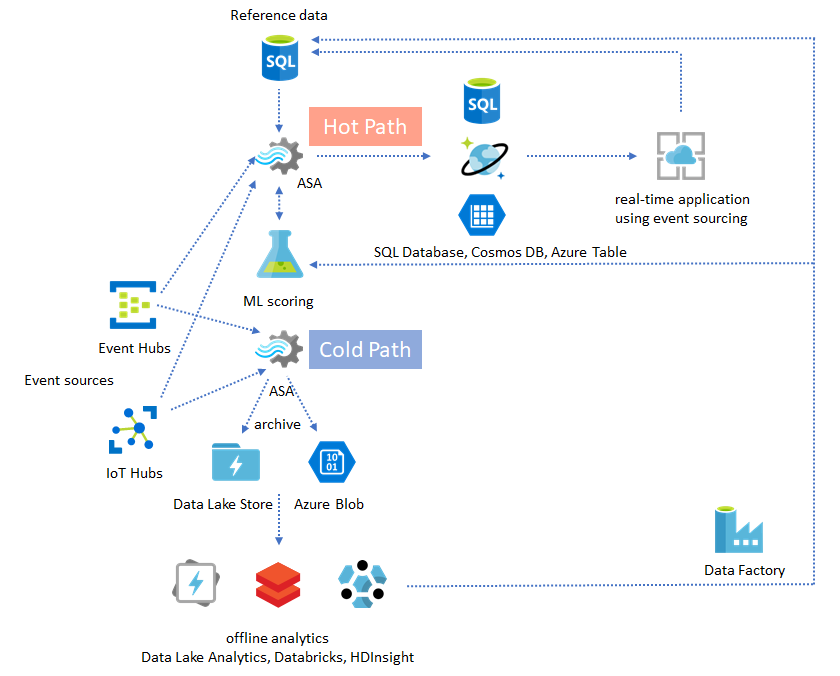
Rendre des insights opérationnels à partir de données archivées
Si vous combinez le modèle d’analytique hors connexion avec le modèle d’application en quasi temps réel, vous pouvez créer une boucle de rétroaction. La boucle de rétroaction permet à l’application de s’ajuster automatiquement aux modifications des modèles dans les données. Cette boucle de rétroaction peut se révéler aussi simple qu’une modification de la valeur du seuil d’alerte, ou aussi complexe que le réentraînement des modèles Machine Learning. La même architecture de solution peut être appliquée autant aux travaux ASA s’exécutant dans le cloud que sur IoT Edge.
Intégration d’Apache Kafka
Stream Analytics prend en charge Apache Kafka à la fois comme source de données et destination à travers Azure Event Hubs avec le point de terminaison Kafka. Ce modèle active :
- Migration à partir d’architectures kafka existantes vers Azure
- Scénarios hybrides de connexion de clusters Kafka locaux à Azure
- Intégration avec les outils et connecteurs de l’écosystème Apache Kafka
Sortie Delta Lake pour les architectures lakehouse
Pour les architectures lakehouse modernes, Stream Analytics peut écrire directement au format Delta Lake dans Azure Data Lake Storage Gen2. Delta Lake fournit :
- Transactions ACID pour l’ingestion de données fiables
- Mise en œuvre et évolution du schéma
- Fonctionnalités de déplacement du temps pour le contrôle de version des données
- Accès unifié aux données de traitement par lots et de diffusion en continu
Choix du modèle approprié
Utilisez ce tableau pour vous aider à sélectionner le modèle approprié pour votre scénario :
| Scénario | Modèle recommandé | Avantage clé |
|---|---|---|
| Tableaux de bord en temps réel | Jeu de données de streaming Power BI | Latence la plus faible |
| Rapports complexes | SQL Database + Power BI | Fonctionnalités de Business Intelligence Complètes |
| Alertes pilotées par les événements | Event Hubs + Azure Functions | Intégration flexible |
| Analyse des lacs de données | Sortie Delta Lake | Transactions ACID |
| Charges de travail Kafka | Point de terminaison Event Hubs Kafka | Compatibilité des protocoles |
Guide pratique pour superviser les travaux ASA
Un travail Azure Stream Analytics peut s’exécuter 24/24 7/7 pour traiter des événements entrants sans interruption en temps réel. Sa garantie de durée de fonctionnement est cruciale pour l’intégrité de l’application dans son ensemble. Même si Stream Analytics est le seul service d’analytique en streaming du secteur qui offre une garantie de disponibilité de 99,9 %, vous risquez tout de même de connaître quelque temps d’arrêt. Au fil des années, Stream Analytics a introduit les métriques, les journaux et les états des tâches pour refléter la santé des travaux. Tous sont exposés via le service Azure Monitor et peuvent être exportés vers un espace de travail Log Analytics pour une analyse plus approfondie. Pour plus d’informations, consultez Surveiller un travail Stream Analytics avec le portail Azure.
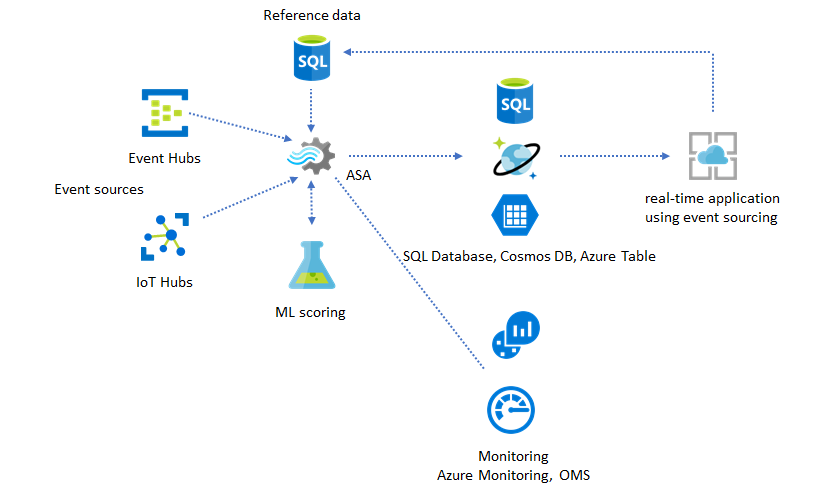
Il y a deux éléments clés à surveiller :
-
Avant toute chose, vous devez vous assurer que le travail est en cours d’exécution. Sans travail associé à un état en cours d’exécution, aucune nouvelle métrique et aucun journal n’est généré. Les travaux peuvent afficher un état d’échec pour diverses raisons, entre autres avoir un niveau élevé d’utilisation de SU (autrement dit, manquer de ressources).
Métrique du délai en filigrane
Cette métrique reflète le retard pris par votre pipeline de traitement en temps Horloge (secondes). Un certain délai est attribué à la logique de traitement inhérente. En conséquence, la supervision de la tendance croissante est beaucoup plus importante que la surveillance de la valeur absolue. Le délai de l’état stable devrait être corrigé par la conception de votre application, pas par la supervision ou les alertes.
Configurer des alertes et des tableaux de bord
Configurer des alertes Azure Monitor pour la surveillance proactive :
- Utilisation du SU - Alerte lorsqu'elle dépasse 80% de manière soutenue pour éviter des échecs de tâches
- Délai du marquage - Alerte sur les tendances croissantes qui indiquent un décalage dans le traitement
- Événements d’entrée/sortie - Surveiller les chutes soudaines indiquant les problèmes de connectivité
- Erreurs d’exécution - Suivre les échecs de désérialisation et de conversion de données
Pour une observabilité centralisée, exportez les métriques et journaux Stream Analytics vers un espace de travail Log Analytics. Cela active :
- Corrélation et analyse entre travaux
- Requêtes Kusto personnalisées pour les diagnostics approfondis
- Intégration à des tableaux de bord et classeurs Azure
En cas d’échec, les journaux d’activité et les journaux de diagnostic sont les meilleurs endroits où commencer à rechercher des erreurs.
Créer des applications stratégiques et résilientes
Quels que soient la garantie du contrat SLA d’Azure Stream Analytics utilisé et le soin que vous apportez à exécuter votre application de bout en bout, des pannes se produisent. Si votre application est critique pour la mission, vous devez être prêt à faire face aux interruptions afin d'assurer une récupération en douceur.
Pour les applications de génération d’alertes, le plus important est de détecter l’alerte suivante. Vous pouvez choisir de redémarrer la tâche à partir de l'heure actuelle lors de la récupération, ce qui vous permet d'ignorer les alertes précédentes. La sémantique de l’heure de début du travail s’établit en fonction de la première heure de sortie, pas de la première heure d’entrée. L’entrée est rembobinée vers l’arrière, jusqu’à une quantité appropriée de temps permettant de garantir que la première sortie à l’heure spécifiée est complète et correcte. En procédant ainsi, vous n’obtenez aucun agrégat partiel et ne déclenchez aucune alerte de façon inattendue.
Vous pouvez également choisir de démarrer la production à partir d’un certain moment dans le passé. Les stratégies de conservation des Event Hubs et des IoT Hub contiennent une quantité raisonnable de données permettant un traitement des données passées. Le compromis tient dans la rapidité avec laquelle vous pouvez rattraper le retard par rapport à l’heure actuelle, et commencer à générer de nouvelles alertes dans les délais. Les données perdent rapidement leur valeur au fil du temps, il est donc important de rattraper au plus vite l’heure actuelle. Il existe deux façons de rattraper rapidement un retard :
- Provisionner davantage de ressources (SU) lors du rattrapage du retard.
- Redémarrer à partir de l’heure actuelle.
Le redémarrage à l’heure actuelle est simple à réaliser, en acceptant le compromis de devoir laisser un intervalle vide lors du traitement. Le redémarrage par ce moyen peut accessoirement fonctionner pour les scénarios d’alerte, mais s’avérer problématique avec les scénarios de tableau de bord, et être voué à l’échec pour l’archivage et les scénarios d’entreposage de données.
Le provisionnement de ressources supplémentaires peut accélérer le processus, mais l’effet d’une augmentation brutale de la vitesse de traitement est complexe.
Vérifiez que votre travail est scalable sur un plus grand nombre de SUs. Les requêtes ne sont pas toutes adaptables. Vous devez vous assurer que votre requête est parallélisée.
Veillez à ce qu’il existe suffisamment de partitions en amont dans les services Event Hubs ou IoT Hub pour que vous puissiez ajouter plus d’unités de débit (TU) et ainsi mettre à l’échelle le débit d’entrée. N’oubliez pas, chaque TU d’"Event Hubs" atteint un débit maximal de 2 Mo/s.
Assurez-vous d’avoir approvisionné suffisamment de ressources dans les récepteurs de sortie (c’est-à-dire SQL Database, Azure Cosmos DB) afin qu’ils ne limitent pas l'augmentation soudaine du volume de sortie, qui peut parfois entraîner un verrouillage du système.
L'essentiel est d'anticiper le changement du taux de traitement, de tester ces scénarios avant la mise en production et d'être prêt à mettre le traitement à l'échelle correctement pendant la récupération après une défaillance.
Dans le scénario extrême où les événements entrants sont tous retardés, il est possible que tous les événements différés soient supprimés si vous avez appliqué une plage d’arrivée tardive à votre travail. La suppression des événements peut sembler étrange au début, mais si l’on considère que Stream Analytics est un moteur de traitement en temps réel, celui-ci s’attend donc à ce que les événements entrants soient proches de l’heure indiquée sur l’horloge. Il doit donc supprimer les événements qui violent ces contraintes.
Architectures lambda ou processus de renvoi
Heureusement, le modèle d’archivage de données précédent peut être utilisé pour traiter normalement ces événements tardifs. L’idée est que le travail d’archivage traite les événements entrants selon le moment de l'arrivée et archive les événements dans le compartiment temporel approprié au sein d'Azure Blob Storage ou Azure Data Lake Store, en utilisant leur heure d’événement. Peu importe l’heure tardive à laquelle un événement arrive, il n’est jamais supprimé. Il est toujours placé dans le compartiment du moment opportun. Lors de la récupération, il est possible de retraiter les événements archivés et de renvoyer les résultats dans le magasin voulu. Cela est similaire à la façon dont les modèles lambda sont implémentés.
Le processus de renvoi doit être effectué avec un système de traitement par lots hors connexion ; celui-ci a probablement un autre modèle de programmation qu’Azure Stream Analytics. Cela signifie que vous devez réimplémenter la logique de traitement complète.
Pour un renvoi, il demeure important de provisionner au moins temporairement plus de ressources sur les récepteurs de sortie, afin de gérer un débit plus élevé que les besoins du traitement de l’état stable.
| Scénarios | Redémarrer à partir de maintenant uniquement | Redémarrer à partir de l’heure du dernier arrêt | Redémarrer à partir de maintenant + renvoyer avec des événements archivés |
|---|---|---|---|
| Tableaux de bord | Crée un écart | D'accord pour une brève interruption | Utiliser pour une longue interruption |
| Alertes | Acceptable | D'accord pour une brève interruption | Pas nécessaire |
| Application de provisionnement en événements | Acceptable | D'accord pour une brève interruption | Utiliser pour une longue interruption |
| Entrepôt de données | Perte de données | Acceptable | Pas nécessaire |
| Analytique hors connexion | Perte de données | Acceptable | Pas nécessaire |
Mettre le tout ensemble
Évidemment, tous les modèles de solution mentionnés ci-dessus sont combinables entre eux, dans un système de bout en bout complexe. Le système composé peut inclure des fonctionnalités de tableaux de bord, d’alertes, d’application de provisionnement en événements, d’entreposage de données et d’analytique hors connexion.
L’essentiel est de concevoir votre système dans des modèles composables, de telle sorte que chaque sous-système peut être généré, testé, mis à niveau et récupéré séparément.
Étapes suivantes
Vous avez découvert différents modèles de solution à l’aide d’Azure Stream Analytics. Pour approfondir ces connaissances et créer votre premier travail Stream Analytics, consultez les articles suivants :