Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Microsoft Fabric Data Warehouse est un entrepôt relationnel à l’échelle de l’entreprise sur une base de lac de données, avec une architecture future, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'entreposage de données, commencez par Fabric Data Warehouse. Les charges de travail de pool SQL existantes dédicées peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Une table externe pointe vers des données situées dans Hadoop, Stockage Blob Azure ou Azure Data Lake Storage (ADLS).
Vous pouvez utiliser les tables externes pour lire des données à partir de fichiers ou écrire des données dans des fichiers dans Stockage Azure. Avec Azure Synapse SQL, vous pouvez utiliser des tables externes pour lire des données externes en utilisant le pool SQL dédié ou le pool SQL serverless.
Selon le type de la source de données externe, vous pouvez utiliser deux types de tables externes :
- Les tables externes Hadoop, qui vous permettent de lire et d’exporter des données dans divers formats de données, par exemple CSV, Parquet et ORC. Les tables externes Hadoop sont disponibles dans les pools SQL dédiés, mais pas dans les pools SQL serverless.
- Les tables externes natives, qui vous permettent de lire et d’exporter des données dans divers formats de données, par exemple CSV et Parquet. Les tables externes natives sont disponibles dans les pools SQL serverless et dans les pools SQL dédiés. L’écriture/l’exportation de données à l’aide de CETAS et des tables externes natives est disponible uniquement dans le pool SQL serverless, mais pas dans les pools SQL dédiés.
Principales différences entre les tables externes Hadoop et natives :
| Type de table externe | Hadoop | Natif |
|---|---|---|
| Pool SQL dédié | Disponible | Parquet uniquement |
| Pool SQL sans serveur | Non disponible | Disponible |
| Formats pris en charge | Délimité/CSV, Parquet, ORC, Hive RC et RC | Pool SQL serverless : Délimité/CSV, Parquet, et Delta Lake Pool SQL dédié : Parquet |
| Élimination des partitions de dossier | Non | L’élimination des partitions est disponible uniquement dans les tables partitionnées créées sur des formats Parquet ou CSV synchronisés à partir de pools Apache Spark. Vous pouvez créer des tables externes sur des dossiers partitionnés Parquet, mais les colonnes de partitionnement sont inaccessibles et ignorées. De plus, l’élimination des partitions ne sera pas appliquée. Ne créez pas de tables externes sur des dossiers Delta Lake, car elles ne sont pas prises en charge. Utilisez des vues partitionnées Delta si vous avez besoin d’interroger des données Delta Lake partitionnées. |
| Suppression de fichiers (predicate pushdown) | Non | Oui, dans un pool SQL serverless. Pour le pushdown de chaîne, vous devez utiliser un classement Latin1_General_100_BIN2_UTF8 sur les colonnes VARCHAR pour activer le pushdown. Pour plus d’informations sur les classements, consultez Prise en charge du classement de bases de données pour Synapse SQL dans Azure Synapse Analytics. |
| Format personnalisé pour l’emplacement | Non | Oui, en utilisant des caractères génériques comme /year=*/month=*/day=* pour les formats Parquet ou CSV. Les chemins de dossiers personnalisés ne sont pas disponibles dans Delta Lake. Dans le pool SQL serverless, vous pouvez également utiliser des caractères génériques récursifs /logs/** pour référencer des fichiers Parquet ou CSV dans n’importe quel sous-dossier du dossier référencé. |
| Analyse récursive des dossiers | Oui | Oui. Dans les pools SQL serverless, /** doit être spécifié à la fin du chemin d’accès d’emplacement. Dans le pool dédié, les dossiers sont toujours analysés de manière récursive. |
| Authentification du stockage | Clé d’accès au stockage (SAK), passthrough Microsoft Entra, identité managée, identité Microsoft Entra d’application personnalisée | Signature d’accès partagé (SAS), Authentification directe Microsoft Entra, Identité managée, Identité Microsoft Entra d’application personnalisée. |
| Mappage de colonnes | Ordinal : les colonnes de la définition de table externe sont mappées aux colonnes des fichiers Parquet sous-jacents par position. | Pool sans serveur : par nom. Les colonnes de la définition de table externe sont mappées aux colonnes des fichiers Parquet sous-jacents par correspondance de nom de colonne. Pool dédié : correspondance ordinale. Les colonnes de la définition de table externe sont mappées aux colonnes des fichiers Parquet sous-jacents par position. |
| CETAS (exportation/transformation) | Oui | CETAS avec les tables natives pour cible fonctionne uniquement dans le pool SQL serverless. Vous ne pouvez pas utiliser de pools SQL dédiés pour exporter des données à l’aide de tables natives. |
Remarque
Les tables externes natives représentent désormais la solution recommandée dans les pools où elles sont généralement disponibles. Si vous avez besoin d’accéder aux données externes, utilisez toujours les tables natives dans des pools serverless ou dédiés. Utilisez les tables Hadoop uniquement si vous devez accéder à certains types qui ne sont pas pris en charge dans les tables externes natives (par exemple, ORC, RC), ou si la version native n’est pas disponible.
Tables externes dans un pool SQL dédié et un pool SQL sans serveur
Vous pouvez utiliser des tables externes pour :
- Interroger Stockage Blob Azure et Azure Data Lake Storage Gen2 avec des instructions Transact-SQL.
- Stocker les résultats de requête dans des fichiers sur Stockage Blob Azure ou Azure Data Lake Storage à l’aide de CETAS avec Synapse SQL.
- Importer des données à partir du Stockage Blob Azure et d’Azure Data Lake Storage et les stocker dans un pool SQL dédié (tables Hadoop uniquement dans un pool dédié).
Remarque
Utilisée avec l’instruction CREATE TABLE AS SELECT, la sélection à partir d’une table externe permet d’importer des données dans une table du pool SQL dédié.
Si les performances des tables externes Hadoop dans les pools dédiés ne répondent pas à vos objectifs en matière de performances, envisagez de charger les données externes dans les tables de l’entrepôt de données à l’aide de l’instruction COPY.
Pour obtenir un tutoriel sur le chargement, consultez Utiliser PolyBase pour charger des données du Stockage Blob Azure.
Vous pouvez créer des tables externes dans des pools Synapse SQL en effectuant les étapes suivantes :
- CRÉEZ UNE SOURCE DE DONNÉES EXTERNE pour référencer un stockage Azure externe, puis spécifiez les informations d’identification à utiliser pour accéder au stockage.
- Utilisez CREATE EXTERNAL FILE FORMAT afin de décrire le format des fichiers CSV ou Parquet.
- CRÉEZ UNE TABLE EXTERNE en plus des fichiers placés dans la source de données avec le même format de fichier.
Élimination des partitions de dossier
Les tables externes natives dans les pools Synapse peuvent ignorer les fichiers placés dans les dossiers qui ne sont pas pertinents pour les requêtes. Si vos fichiers sont stockés dans une hiérarchie de dossiers (par exemple, /year=2020/month=03/day=16) et que les valeurs year, month et day sont exposées en tant que colonnes, les requêtes contenant des filtres tels que year=2020 lisent les fichiers uniquement à partir des sous-dossiers placés dans le dossier year=2020. Les fichiers et les dossiers placés dans d’autres dossiers (year=2021 ou year=2022) sont ignorés dans cette requête. Cette élimination est appelée élimination de partition.
L’élimination de partition de dossier est disponible dans les tables externes natives qui sont synchronisées à partir des pools Synapse Spark. Si vous avez partitionné le jeu de données et souhaitez utiliser l’élimination de partition avec les tables externes que vous créez, utilisez les vues partitionnées à la place des tables externes.
Élimination de fichiers
Certains formats de données tels que Parquet et Delta contiennent des statistiques de fichier pour chaque colonne (par exemple, des valeurs minimales/maximales pour chaque colonne). Les requêtes qui filtrent les données ne lisent pas les fichiers dans lesquelles les valeurs de colonne requises n’existent pas. La requête explorera d’abord les valeurs minimales/maximales pour les colonnes utilisées dans le prédicat de requête afin de rechercher les fichiers qui ne contiennent pas les données requises. Ces fichiers sont ignorés et éliminés du plan de requête.
Cette technique, également connue sous le nom de "filtrage par prédicat", peut améliorer les performances de vos requêtes. Le pushdown de filtre est disponible dans les pools SQL serverless sur les formats Parquet et Delta. Pour appliquer le pushdown de filtre aux types de chaînes, utilisez le type VARCHAR avec le classement Latin1_General_100_BIN2_UTF8. Pour plus d’informations sur les classements, consultez Prise en charge du classement de bases de données pour Synapse SQL dans Azure Synapse Analytics.
Sécurité
L’utilisateur doit disposer de l’autorisation SELECT sur une table externe pour lire les données.
Les tables externes accèdent au stockage Azure sous-jacent à l’aide des informations d’identification étendues à la base de données définies dans la source de données selon les règles suivantes :
- La source de données sans informations d’identification permet aux tables externes d’accéder aux fichiers en disponibilité publique sur le stockage Azure.
- La source de données peut comporter des informations d’identification permettant aux tables externes d’accéder uniquement aux fichiers sur le stockage Azure à l’aide d’un jeton SAP ou de l’identité managée de l’espace de travail. Pour voir des exemples, consultez l’article Développement du contrôle d’accès au stockage des fichiers de stockage.
Remarques
Pour garantir l’exécution fiable des requêtes, les fichiers et dossiers sources référencés par des tables externes doivent rester inchangés pendant toute la durée de l’opération.
- La modification, la suppression ou le remplacement de tous les fichiers ou dossiers référencés pendant l’exécution de la requête peut entraîner des échecs ou entraîner des résultats incohérents.
- Avant d’interroger des tables externes dans un pool SQL dédié, vérifiez que toutes les données sources sont stables et ne seront pas modifiées pendant l’exécution.
Exemple pour CREATE EXTERNAL DATA SOURCE
L’exemple suivant crée une source de données externe Hadoop dans un pool SQL dédié pour ADLS Gen2 pointant vers le jeu de données public New York :
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2022-11-02&ss=b&srt=co&sp=rl&se=2042-11-26T17:40:55Z&st=2024-11-24T09:40:55Z&spr=https&sig=DKZDuSeZhuCWP9IytWLQwu9shcI5pTJ%2Fw5Crw6fD%2BC8%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
L’exemple suivant crée une source de données externe pour ADLS Gen2 pointant vers le jeu de données New York en disponibilité publique :
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
Exemple pour CREATE EXTERNAL FILE FORMAT
L’exemple suivant crée un format de fichier externe pour des fichiers de recensement :
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
Exemple pour CREATE EXTERNAL TABLE
L’exemple suivant crée une table externe : Il retourne la première ligne :
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
Créer et interroger des tables externes à partir d’un fichier dans Azure Data Lake
Avec les fonctionnalités d’exploration lac de données de Synapse Studio, vous pouvez désormais créer et interroger une table externe à l’aide d’un pool Synapse SQL en cliquant avec le bouton droit sur le fichier. Le clic simple qui permet de créer des tables externes à partir d’un compte de stockage ADLS Gen2 est possible uniquement pour les fichiers Parquet.
Prérequis
Vous devez avoir accès à l’espace de travail en ayant au moins le rôle d’accès
Storage Blob Data Contributorau compte ADLS Gen2 ou aux listes de contrôle d’accès (ACL) qui vous permettent d’interroger les fichiers.Vous devez disposer au moins d’autorisations de créer une table externe et d’interroger des tables externes sur le pool Synapse SQL (dédié ou serverless).
Dans le panneau Données, sélectionnez le fichier à partir duquel vous souhaitez créer la table externe :

Une fenêtre de dialogue s’ouvre. Sélectionnez un pool SQL dédié ou un pool SQL serverless, donnez un nom à la table et sélectionnez Ouvrir le script :
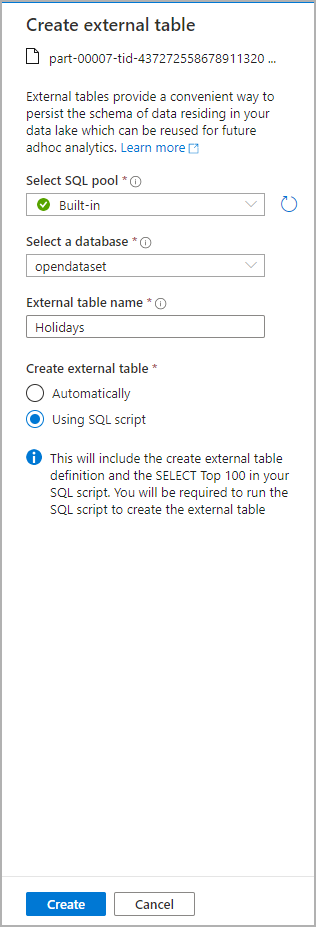
Le script SQL est généré automatiquement en déduisant le schéma à partir du fichier :

Exécutez le script. Le script exécutera automatiquement un SELECT TOP 100 * :

La table externe a désormais été créée. Vous pouvez maintenant interroger la table externe directement à partir du volet Données.
Contenu connexe
Consultez l’article CETAS pour découvrir comment enregistrer des résultats de requête dans une table externe dans Stockage Azure. Vous pouvez sinon commencer à interroger des Tables externes Apache Spark pour Azure Synapse.