Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
S'applique à :✅base de données SQL dans Microsoft Fabric
Dans ce tutoriel, vous allez apprendre à utiliser votre base de données SQL dans Fabric à l’aide du contrôle de code source d’intégration Git fabric.
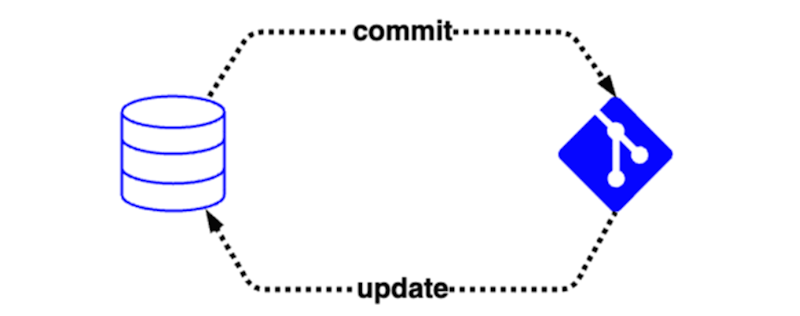
Une base de données SQL dans Microsoft Fabric dispose d’une intégration de contrôle de code source ou d’une « intégration git », afin que les utilisateurs puissent suivre les définitions de leurs objets de base de données au fil du temps. Cette intégration permet à une équipe de :
- Validez la base de données dans le contrôle de code source, qui convertit automatiquement la base de données dynamique en code dans le référentiel de contrôle de code source configuré (par exemple, Azure DevOps).
- Mettre à jour les objets de base de données à partir du contenu du contrôle de code source, qui valide le code dans le référentiel de contrôle de code source avant d’appliquer une modification différentielle à la base de données.
Si vous ne connaissez pas Git, voici quelques ressources recommandées :
- Qu’est-ce que Git ?
- Module de formation : présentation de Git
- Tutoriel : Gestion du cycle de vie dans Fabric
Cet article présente une série de scénarios utiles que vous pouvez utiliser individuellement ou conjointement pour gérer votre processus de développement avec une base de données SQL dans Fabric :
- Convertir une base de données SQL en code dans le contrôle de code source de Fabric
- Mettre à jour la base de données SQL à partir du contrôle de code source dans Fabric
- Créer un espace de travail de branche
- Fusionner les modifications d’une branche vers une autre
- Gérer des données statiques avec un script de post-déploiement
Les scénarios de cet article sont abordés dans un épisode de Data Exposed. Regardez la vidéo pour obtenir une vue d’ensemble de l’intégration du contrôle de code source dans Fabric :
Remarque
Les paramètres au niveau de la base de données, tels que le classement et le niveau de compatibilité, ne sont pas inclus dans l’intégration des pipelines de contrôle de code source et de déploiement pour l’instant. Pour les paramètres de base de données que vous pouvez définir à l’aide de T-SQL après la création de la base de données, vous pouvez modifier la base de données avec des scripts après le déploiement.
Prérequis
- Vous avez besoin d'une capacité existante Fabric. Si ce n’est pas le cas, démarrez une version d’évaluation de Fabric.
- Veillez à activer les paramètres d’intégration Git du locataire.
- Créer un espace de travail ou utiliser un espace de travail Fabric existant.
- Créez ou utilisez une base de données SQL existante dans Fabric. Si vous n’en avez pas déjà une, créez une base de données SQL dans Fabric.
- Facultatif : installez Visual Studio Code, l’extension MSSQL et les projets SQL pour VS Code.
Programme d’installation
Cette connexion de référentiel s’applique au niveau de l’espace de travail, de sorte qu’une branche unique dans le référentiel est associée à cet espace de travail. Le référentiel peut avoir plusieurs branches, mais seul le code de la branche sélectionnée dans les paramètres de l’espace de travail affecte directement l’espace de travail.
Pour connaître les étapes de connexion de votre espace de travail à un référentiel de contrôle de code source, consultez Prise en main de l’intégration Git. Votre espace de travail peut être connecté à un dépôt distant Azure DevOps ou GitHub.
Ajouter une base de données SQL de Fabric au contrôle de code source
Dans ce scénario, vous validez les objets de base de données dans le contrôle de code source. Vous développez peut-être une application dans laquelle vous créez des objets directement dans une base de données de test et effectuez le suivi de cette base de données dans le contrôle de code source, tout comme votre code d’application. Par conséquent, vous avez accès à l’historique de vos définitions d’objets de base de données et pouvez utiliser des concepts Git tels que la branche et la fusion pour personnaliser votre processus de développement.
- Connectez-vous à votre base de données SQL dans l'éditeur SQL de Fabric, SQL Server Management Studio, l'extension MSSQL pour Visual Studio Code ou d'autres outils externes.
- Créez une table, une procédure stockée ou un autre objet dans la base de données.
- Sélectionnez le bouton Contrôle de code source pour ouvrir le volet de contrôle de code source.
- Cochez la case attenante à la base de données souhaitée. Sélectionnez Valider. Le service Fabric lit les définitions d’objets de la base de données et les écrit dans le référentiel distant.
- Vous pouvez maintenant afficher l’historiquedes objets de base de données dans la vue source du référentiel de code.
Lorsque vous continuez à modifier la base de données, y compris la modification d’objets existants, validez ces modifications dans le contrôle de code source en suivant les étapes précédentes.
Fichier projet SQL
Le fichier projet SQL dans le référentiel de contrôle de code source contient des métadonnées sur la base de données. L’intégration du contrôle de code source fabric utilise ce fichier pour apporter davantage de fonctionnalités dans les pipelines de contrôle de code source et de déploiement. L’intégration du contrôle de code source fabric génère et met à jour automatiquement le fichier projet. Évitez les modifications manuelles dans le fichier projet, car vos modifications dans le fichier projet sont remplacées par l’intégration du contrôle de code source Fabric sur la validation suivante de Fabric. Toutefois, si vous souhaitez créer un projet SQL localement à l’aide d’outils SQL tels que SQL Server Management Studio ou l’extension de projets SQL pour Visual Studio Code, vous pouvez ajouter une référence au master.dacpac fichier dans votre fichier projet.
L’intégration de Fabric à des projets SQL ajoute ces propriétés de métadonnées au fichier projet :
- Exclut le dossier
.sharedQueriesde la compilation du projet de base de données. Cette exclusion vous permet de suivre les scripts dans le contrôle de code source sans avoir d’impact sur la validation du modèle de base de données. - Scripts de prédéploiement et de post-déploiement à partir du dossier .sharedQueries
- Références d’objet système en tant que référence de package au fichier master.dacpac
La fonctionnalité référence d’objet système est configurée automatiquement sans aucune action requise. L’éditeur de requête Fabric fournit des scripts de prédéploiement et de post-déploiement sous le dossier Requêtes partagées .
Mettre à jour la base de données SQL à partir du contrôle de code source dans Fabric
Dans ce scénario, vous créez des objets de base de données en tant que code dans l’extension de projets SQL dans Visual Studio Code, puis validez les fichiers dans le contrôle de code source avant de mettre à jour la base de données SQL Fabric à partir de l’intégration du contrôle de code source. Ce scénario est destiné aux développeurs qui préfèrent travailler dans Visual Studio Code, ont des applications existantes à l’aide de projets SQL ou ont des exigences de pipeline CI/CD plus avancées.
- Veillez à installer la dernière version de Visual Studio Code et les extensions de projets MSSQL et SQL pour Visual Studio Code.
- Créez une base de données SQL dans votre espace de travail et validez-la dans le contrôle de code source sans ajouter d’objets. Cette étape ajoute les métadonnées du projet SQL vide et de l'élément base de données SQL au référentiel.
- Clonez le référentiel de contrôle de code source sur votre ordinateur local.
- Si vous utilisez Azure DevOps, sélectionnez le menu contextuel
...pour le projet de contrôle de code source. Sélectionnez Clone pour copier votre dépôt Azure DevOps sur votre ordinateur local. Si vous débutez avec Azure DevOps, consultez le guide Code avec git pour Azure DevOps. - Si vous utilisez GitHub, sélectionnez le bouton Code dans le référentiel et copiez l'URL pour cloner le référentiel sur votre ordinateur local. Si vous débutez avec GitHub, consultez le guide cloner un dépôt.
- Si vous utilisez Azure DevOps, sélectionnez le menu contextuel
- Ouvrez le dossier cloné dans Visual Studio Code. La branche associée à votre espace de travail n’est peut-être pas la branche par défaut. Vous devriez voir un dossier nommé
<yourdatabase>.SQLDatabasedans Visual Studio Code après avoir changé de branche. - Créez un
.sqlfichier pour au moins une table que vous souhaitez créer dans la base de données dans la structure de dossiers de votre base de données. Le fichier doit contenir l’instructionCREATE TABLEpour cette table. Par exemple, créez un fichier nomméMyTable.sqldans le dossierdbo/Tablesavec le contenu suivant :CREATE TABLE dbo.MyTable ( Id INT PRIMARY KEY, ExampleColumn NVARCHAR(50) ); - Pour vérifier que la syntaxe est valide, validez le modèle de base de données avec le projet SQL. Après avoir ajouté les fichiers, utilisez la vue Projets de base de données dans Visual Studio Code pour générer le projet.
- Après une génération réussie, validez les fichiers dans le contrôle de code source à l’aide de la vue contrôle de code source dans Visual Studio Code ou de votre interface git locale préférée.
- Envoyez/synchronisez votre validation vers le référentiel distant. Vérifiez que vos nouveaux fichiers apparaissent dans Azure DevOps ou GitHub.
- Revenez à l’interface web de Fabric et ouvrez le panneau de gestion du code source dans l’espace de travail. Vous aurez peut-être déjà une alerte indiquant que « vous avez des modifications en attente provenant de Git ». Sélectionnez le bouton Mettre à jour (Tout mettre à jour) pour appliquer le code de votre projet SQL à la base de données.
- Vous pouvez voir la base de données immédiatement indiquée comme étant « Non validée » après la mise à jour. Cet état se produit parce que la fonctionnalité d’intégration Git effectue une comparaison directe de tout le contenu de fichier généré pour une définition d’élément, et certaines différences involontaires sont possibles. Un exemple est les attributs inline sur les colonnes. Dans ces cas, vous devez revenir au contrôle de code source dans l’interface web Fabric pour synchroniser la définition avec ce qui est généré dans le cadre d’une opération de validation.
- Une fois la mise à jour terminée, utilisez un outil de votre choix pour vous connecter à la base de données. Les objets que vous avez ajoutés au projet SQL sont visibles dans la base de données.
Remarque
Lorsque vous apportez des modifications au projet SQL local, en cas d’erreur de syntaxe ou d’utilisation de fonctionnalités non prises en charge dans Fabric, la mise à jour de la base de données échoue. Vous devez rétablir manuellement la modification du contrôle de code source avant de pouvoir continuer.
La mise à jour d’une base de données SQL dans Fabric à partir du contrôle de code source combine une génération de projet SQL et une opération de publication SqlPackage. Le projet SQL valide la syntaxe des fichiers SQL et génère un fichier .dacpac. L’opération de publication SqlPackage détermine les modifications nécessaires pour mettre à jour la base de données pour qu’elle corresponde au .dacpac fichier. En raison de la nature simplifiée de l’interface Fabric, les options suivantes sont appliquées à l’opération de publication SqlPackage :
/p:ScriptDatabaseOptions = false/p:DoNotAlterReplicatedObjects = false/p:IncludeTransactionalScripts = true/p:GenerateSmartDefaults = true
Vous pouvez également cloner le projet SQL contrôlé par la source sur votre ordinateur local pour modification dans Visual Studio Code, SQL Server Management Studio ou d’autres outils de projet SQL. Générez le projet SQL localement pour valider les modifications avant de les valider dans le contrôle de code source.
Créer un espace de travail de branche
Dans ce scénario, vous configurez un nouvel environnement de développement dans Fabric en créant un ensemble de ressources en double en fonction de la définition du contrôle de code source. La base de données en double inclut les objets de base de données que vous avez archivés dans le contrôle de code source. Ce scénario concerne les développeurs qui continuent leur cycle de vie de développement d’applications dans Fabric et utilisent l’intégration du contrôle de code source à partir de Fabric.
- Terminez le scénario consistant à convertir la base de données SQL Fabric en code dans le contrôle de version.
- Vous devez disposer d’une branche dans un référentiel de contrôle de code source avec un projet SQL et les métadonnées d’objet Fabric.
- Dans l’espace de travail Fabric, ouvrez le panneau de contrôle de code source. Sous l’onglet Branches du menu Contrôle de code source, sélectionnez Créer une branche vers un nouvel espace de travail.
- Spécifiez les noms de la branche et de l’espace de travail à créer. La branche est créée dans le référentiel de contrôle de code source et est remplie avec le contenu validé de la branche associée à l’espace de travail à partir duquel vous effectuez la branche. L’espace de travail est créé dans Fabric.
- Accédez à l’espace de travail nouvellement créé dans Fabric. Une fois la création de la base de données terminée, la base de données nouvellement créée contient désormais les objets spécifiés dans votre référentiel de code. Si vous ouvrez l’éditeur de requête Fabric et naviguez dans l’Explorateur d’objets, votre base de données a de nouvelles tables (vides) et d’autres objets.
Fusionner les modifications d'une branche dans une autre
Dans ce scénario, vous utilisez le référentiel de contrôle de code source pour passer en revue les modifications de base de données avant qu’elles ne soient disponibles pour le déploiement. Ce scénario concerne les développeurs qui travaillent dans un environnement d’équipe et qui utilisent le contrôle de code source pour gérer leurs modifications de base de données.
Créez deux espaces de travail avec des branches associées dans le même référentiel, comme décrit dans le scénario précédent.
- Avec la base de données sur la branche secondaire, apportez des modifications aux objets de base de données.
- Par exemple, modifiez une procédure stockée existante ou créez une table.
- Vérifiez ces modifications apportées au contrôle de code source à l’aide du bouton Valider dans le panneau de configuration de code source dans Fabric.
- Dans Azure DevOps ou GitHub, créez une pull request depuis la branche secondaire vers la branche principale.
- Dans le "pull request", vous pouvez voir les modifications apportées au code de la base de données entre l’espace de travail principal et l’espace de travail secondaire.
- Une fois le pull request terminé, le gestionnaire de code source est mis à jour, mais la base de données de Fabric sur l'espace de travail principal n'est pas modifiée. Pour modifier la base de données primaire, mettez à jour l’espace de travail principal à partir du contrôle de code source à l’aide du bouton Mettre à jour du panneau de configuration de code source dans Fabric.
Gérer des données statiques avec un script de post-déploiement
Dans ce scénario, vous contrôlez les lignes d’une table de recherche dans votre base de données avec contrôle de code source. La fonctionnalité qui permet cette fonctionnalité, les scripts de prédéploiement et de post-déploiement s’applique également aux pipelines de déploiement. Vous pouvez donc utiliser les mêmes scripts pour gérer les données statiques dans les deux scénarios.
À partir d’une base de données SQL dans Fabric connectée au contrôle de code source, identifiez ou créez une table pour laquelle vous souhaitez gérer des données statiques. Par exemple, vous pouvez avoir une
dbo.Colorstable qui est utilisée par votre application et qui a un ensemble connu de valeurs qui ne changent pas fréquemment.Créez une requête dans l’éditeur de base de données SQL dans Fabric. Dans l’éditeur de requête, ajoutez une
MERGEinstruction pour gérer le contenu de laColorstable. Par exemple:MERGE dbo.Colors AS target USING (VALUES (1, 'Red'), (2, 'Green'), (3, 'Blue') ) AS source (Id, Name) ON target.Id = source.Id WHEN MATCHED THEN UPDATE SET Name = source.Name WHEN NOT MATCHED BY TARGET THEN INSERT (Id, Name) VALUES (source.Id, source.Name) WHEN NOT MATCHED BY SOURCE THEN DELETE;Renommez la requête et
Post-Deployment-StaticData.sqldéplacez-la vers des requêtes partagées.Une fois dans les requêtes partagées, sélectionnez le menu ... de la requête, puis sélectionnez Définir comme script post-déploiement.
Cette requête s’exécute automatiquement dans le cadre de n’importe quelle mise à jour à partir du déploiement du contrôle de code source ou du pipeline de déploiement. Vous pouvez donc gérer les données statiques dans la table à l’aide Colors du contrôle de code source. Vous pouvez modifier la requête dans l’éditeur de requête Fabric et valider les modifications apportées au contrôle de code source pour gérer les modifications apportées aux données statiques au fil du temps. En outre, étant donné que les scripts de prédéploiement et de post-déploiement sont inclus dans le projet SQL, vous pouvez également modifier la requête à partir de votre ordinateur local à l’aide de Visual Studio Code ou d’autres outils de projet SQL, puis valider ces modifications dans le contrôle de code source. En savoir plus sur les scripts de prédéploiement et de post-déploiement dans la documentation des projets SQL.