Tutoriel 2 : Former des modèles de risque de crédit - Machine Learning Studio (classique)
S’APPLIQUE À  Machine Learning Studio (classique)
Machine Learning Studio (classique)  Azure Machine Learning
Azure Machine Learning
Important
Le support de Machine Learning Studio (classique) prend fin le 31 août 2024. Nous vous recommandons de passer à Azure Machine Learning avant cette date.
À partir du 1er décembre 2021, vous ne pourrez plus créer de nouvelles ressources Machine Learning Studio (classique). Jusqu’au 31 août 2024, vous pouvez continuer à utiliser les ressources Machine Learning Studio (classique) existantes.
- Consultez les informations sur le déplacement des projets de machine learning de ML Studio (classique) à Azure Machine Learning.
- En savoir plus sur Azure Machine Learning
La documentation ML Studio (classique) est en cours de retrait et ne sera probablement plus mise à jour.
Dans ce tutoriel, vous étudiez de manière approfondie le processus de développement d’une solution d’analyse prédictive. Vous développez un modèle simple dans Machine Learning Studio (classique). Vous déployez ensuite le modèle en tant que service web Machine Learning. Ce modèle déployé peut effectuer des prédictions à l’aide de nouvelles données. Ce tutoriel est la deuxième partie d’une série de tutoriels qui en compte trois.
Supposons que vous deviez prédire le risque lié à l'octroi d'un crédit à un individu sur la base des informations fournies lors d'une demande de crédit.
L’évaluation du risque de crédit est un problème complexe, mais ce tutoriel va le simplifier un peu. Vous allez l’utiliser comme exemple de création d’une solution d’analyse prédictive à l’aide de Machine Learning Studio (classique). Vous allez utiliser Machine Learning Studio (classique) et un service web Machine Learning pour cette solution.
Dans ce tutoriel en trois parties, vous commencez avec des données de risque crédit disponibles publiquement. Ensuite, vous développez et entraînez un modèle prédictif. Enfin, vous déployez le modèle en tant que service web.
Dans la première partie du tutoriel, vous avez créé un espace de travail Machine Learning Studio (classique), chargé des données et créé une expérience.
Dans cette partie du tutoriel, vous allez effectuer les opérations suivantes :
- Entraîner plusieurs modèles
- Notation et évaluation des modèles
Dans la troisième partie du tutoriel, vous allez déployer le modèle en tant que service web.
Prérequis
Effectuez la première partie du tutoriel.
Entraîner plusieurs modèles
Un des avantages de l’utilisation de Machine Learning Studio (classique) pour créer des modèles Machine Learning est la possibilité d’essayer simultanément plusieurs types de modèle dans une expérience et de comparer les résultats. Ce type d’expérimentation vous aide à trouver la meilleure solution à votre problème.
Dans l’expérience développée au fil de ce tutoriel, vous allez créer deux types de modèles différents, puis comparer les résultats de la notation afin de choisir l’algorithme que vous voulez utiliser dans votre expérience finale.
Vous avez le choix entre différents modèles. Pour connaître les modèles disponibles, développez le nœud Machine Learning dans la palette des modules, puis développez Initialiser le modèle et les nœuds inférieurs. Pour cette expérience, vous allez sélectionner les modules Machines à vecteurs de support à deux classes et Arbre de décision optimisé à deux classes.
Vous allez ajouter le module Arbre de décision optimisé à deux classes et le module Machines à vecteurs de support à deux classes dans cette expérience.
Arbre de décision optimisé à deux classes
Configurez d’abord le modèle d’arbre de décision optimisé.
Recherchez le module Arbre de décision optimisé à deux classes dans la palette des modules et faites-le glisser sur le canevas.
Recherchez le module Former le modèle, faites-le glisser sur la zone de dessin et connectez la sortie du module Arbre de décision optimisé à deux classes au port d’entrée de gauche du module Former le modèle.
Le module Arbre de décision optimisé à deux classes initialise le modèle générique, tandis que le module Former le modèle utilise les données d’apprentissage pour former le modèle.
Connectez la sortie de gauche du module Exécuter un script R de gauche au port d’entrée de droite du module Entraîner le modèle (dans ce tutoriel, vous avez utilisé les données provenant du côté gauche du module Fractionner les données pour l’entraînement).
Conseil
Pour cette expérience, vous n’avez pas besoin de deux des entrées et de l’une des sorties du module Exécuter un script R. Vous pouvez donc les laisser détachées.
Cette partie de l'expérience ressemble alors à ce qui suit :
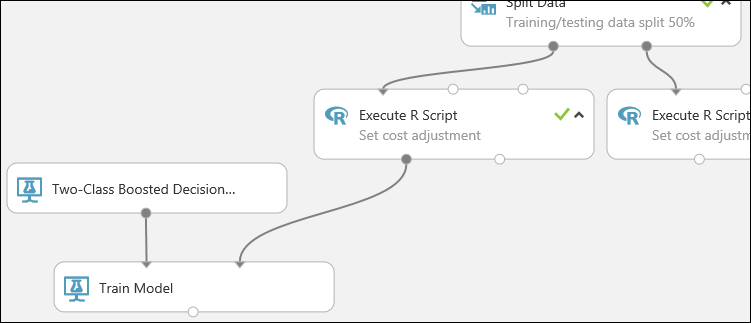
Maintenant, vous devez indiquer au module Former le modèle que vous voulez utiliser le modèle pour prédire la valeur Risque de crédit.
Sélectionnez le module Entraîner le modèle. Dans le volet Propriétés, cliquez sur Lancer le sélecteur de colonne.
Dans la boîte de dialogue Sélectionner une seule colonne, tapez « risque de crédit » dans le champ de recherche sous Colonnes disponibles, sélectionnez « Risque de crédit » ci-dessous et cliquez sur la flèche droite ( > ) pour déplacer « Risque de crédit » vers Colonnes sélectionnées.
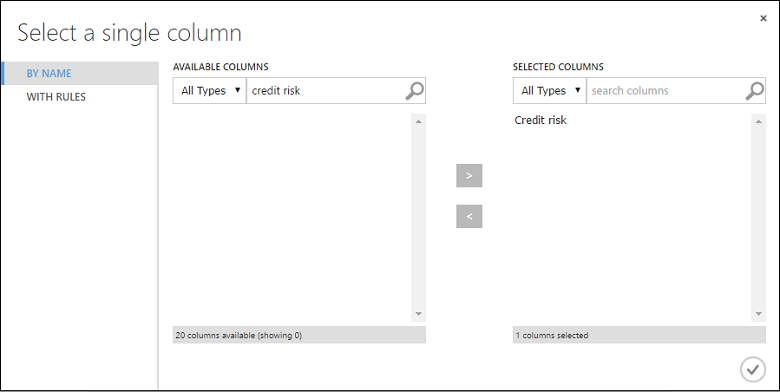
Cliquez sur la coche OK.
Machine à vecteurs de support à deux classes
Vous configurez ensuite le modèle SVM.
Tout d’abord, une petite explication sur SVM. Les arbres de décision optimisés fonctionnent bien avec tout type de caractéristique. Toutefois, le module SVM générant un classifieur linéaire, le modèle qu'il génère obtient la meilleure erreur de test quand toutes les caractéristiques numériques sont à la même échelle. Pour convertir toutes les fonctions numériques à la même échelle, vous utilisez une transformation « Tanh » (avec le module Normaliser les données). Cette opération transforme les nombres en plage [0,1]. Le module SVM convertit les fonctionnalités de chaîne en fonctionnalités catégorielles, puis en fonctionnalités 0/1 binaires. Il est donc inutile de les transformer manuellement. De même, vous ne voulez pas transformer la colonne Risque du crédit (colonne 21). Elle est numérique, mais elle contient la valeur de prédiction pour laquelle vous entraînez le modèle ; vous devez donc la laisser seule.
Pour configurer le modèle SVM, procédez comme suit :
Recherchez le module Machine à vecteurs de support à deux classes dans la palette des modules et faites-le glisser sur le canevas.
Cliquez avec le bouton droit sur le module Former le modèle, sélectionnez Copier, puis cliquez avec le bouton droit sur le canevas et sélectionnez Coller. La copie du module Former le modèle contient les mêmes colonnes que l’original.
Connectez la sortie du module Machines à vecteurs de support à deux classes au port d’entrée de gauche du deuxième module Former le modèle.
Trouvez le module Normaliser les données et faites-le glisser vers le canevas.
Connectez la sortie de gauche du module Exécuter le script R de gauche à l’entrée de ce module (notez que le port de sortie d’un module peut être connecté à plusieurs autres modules).
Connectez le port de sortie de gauche du module Normaliser les données au port d’entrée de droite du deuxième module Former le modèle.
Cette partie de l'expérience ressemble alors à ceci :
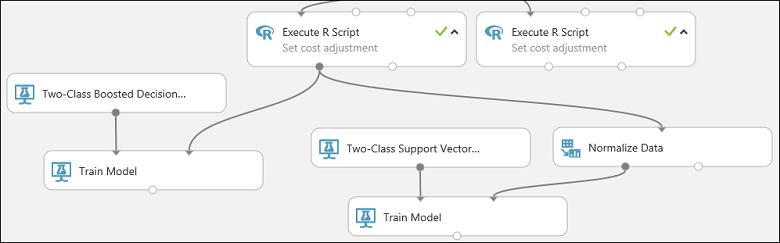
Configurez maintenant le module Normaliser les données :
Cliquez pour sélectionner le module Normaliser les données. Dans le volet Propriétés, sélectionnez Tanh comme paramètre de la Méthode de transformation.
Cliquez sur Lancer le sélecteur de colonne, sélectionnez « Aucune colonne » pour Commencer par, sélectionnez Inclure dans la première liste déroulante, Type de colonne dans la deuxième, puis Numérique dans la troisième. Cette action spécifie que toutes les colonnes numériques (et elles seules) sont transformées.
Cliquez sur le signe plus (+) à droite de cette ligne. Cette opération crée une ligne de listes déroulantes. Sélectionnez Exclure dans la première liste déroulante, sélectionnez des noms de colonne dans la deuxième liste déroulante et entrez « Risque de crédit » dans le champ textuel. Cette opération indique que la colonne Risque de crédit doit être ignorée (en effet, celle-ci étant numérique, elle serait transformée).
Cliquez sur la coche OK.
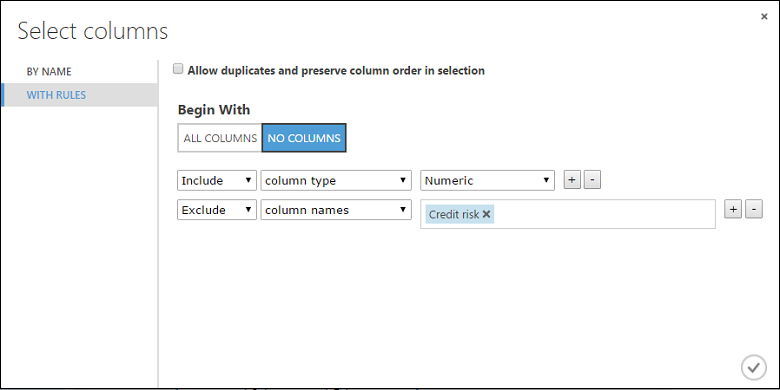
Le module Normaliser les données est maintenant configuré pour effectuer une transformation Tanh sur toutes les colonnes numériques, à l’exception de la colonne Risque de crédit.
Notation et évaluation des modèles
Vous utilisez les données de test exclues par le module Fractionner les données pour noter nos modèles formés. Vous pouvez ensuite comparer les résultats des deux modèles pour savoir lequel donne les meilleurs résultats.
Ajouter les modules Noter le modèle
Recherchez le module Noter le modèle et faites-le glisser sur le canevas.
Connectez le module Former le modèle relié au module Arbre de décision optimisé à deux classes, au port d’entrée de gauche du module Noter le modèle.
Connectez le module Exécuter le script R (nos données de test) au port d’entrée de droite du module Noter le modèle.
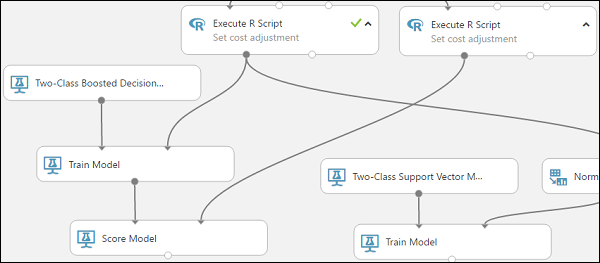
Le module Noter le modèle peut maintenant récupérer les informations sur le crédit dans les données de test, les traiter à l’aide du modèle et comparer les prévisions générées par le modèle à la colonne Risque de crédit dans les données de test.
Copiez et collez le module Noter le modèle pour créer une deuxième copie.
Connectez la sortie du modèle SVM (c’est-à-dire le port de sortie du module Former le modèle relié au module Arbre de décision optimisé à deux classes) au port d’entrée du deuxième module Noter le modèle.
Pour le modèle SVM, vous devez effectuer la même transformation pour tester les données comme vous l’avez fait pour les données d’entraînement. Donc, copiez et collez le module Normaliser les données pour créer une autre copie et connectez-la au moduleExécuter le script R de droite.
Connectez la sortie de gauche du deuxième module Normaliser les données au port d’entrée de droite du deuxième module Noter le modèle.
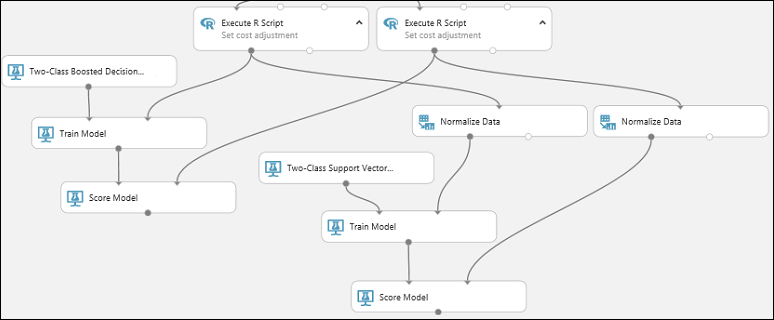
Ajouter le module Évaluer le modèle
Pour évaluer les deux résultats de notation et les comparer, vous utilisez un module Évaluer le modèle.
Recherchez le module Évaluer le modèle et faites-le glisser vers le canevas.
Connectez le port de sortie du module Noter le modèle associé au modèle Arbre de décision optimisé, au port d’entrée gauche du module Évaluer le modèle.
Connectez l’autre module Noter le modèle au port d’entrée de droite.
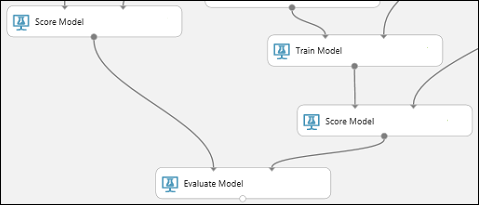
Exécuter l’expérience et vérifier les résultats
Pour exécuter l’expérience, cliquez sur le bouton EXÉCUTER sous le canevas. Cette opération peut prendre quelques minutes. Un indicateur rotatif sur chaque module indique que l’exécution est en cours. Puis une coche verte s’affiche pour signaler que l’exécution du module est terminée. Lorsque tous les modules comportent une coche, l'exécution de l'expérience est terminée.
L'expérience doit ressembler à ceci :
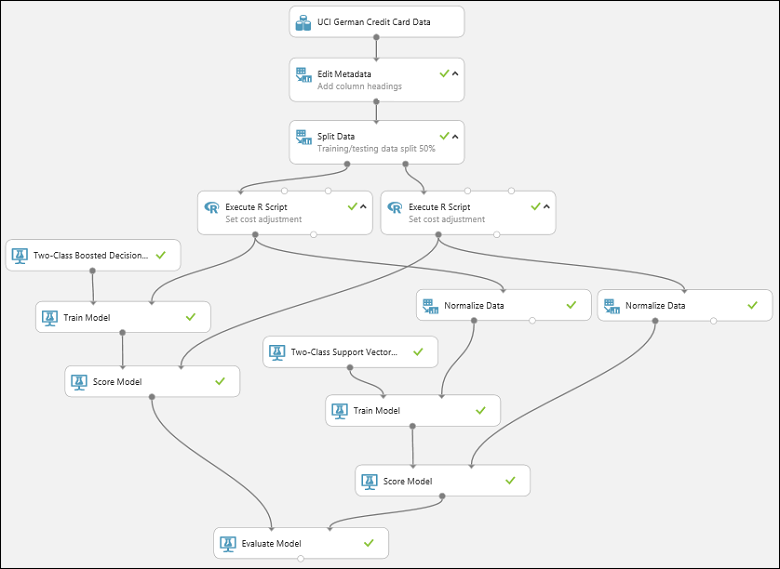
Pour vérifier les résultats, cliquez sur le port de sortie du module Évaluer le modèle et sélectionnez Visualiser.
Le module Évaluer le modèle produit une paire de courbes et de mesures qui vous permettent de comparer les résultats des deux modèles notés. Vous pouvez afficher les résultats sous forme de courbes Receiver Operator Characteristic (ROC), Precision/Recall ou Lift. Les données supplémentaires affichées comprennent une matrice de confusion, les valeurs cumulées pour l’aire sous la courbe (ASC) et d’autres mesures. Vous pouvez modifier la valeur du seuil en déplaçant le curseur vers la gauche ou la droite et voir son influence sur l'ensemble des mesures.
À droite du graphique, cliquez sur Jeu de données noté ou Jeu de données noté à comparer pour mettre en surbrillance la courbe associée et afficher les mesures associées en dessous. Dans la légende des courbes, « Jeu de données noté » correspond au port d’entrée de gauche du module Évaluer le modèle (en l’occurrence, le modèle Arbre de décision optimisé). « Jeu de données noté à comparer » correspond au port d’entrée de droite, le modèle SVM dans notre cas. Lorsque vous cliquez sur une de ces étiquettes, la courbe de ce modèle apparaît en surbrillance ainsi que les mesures correspondantes, comme dans le graphique suivant.
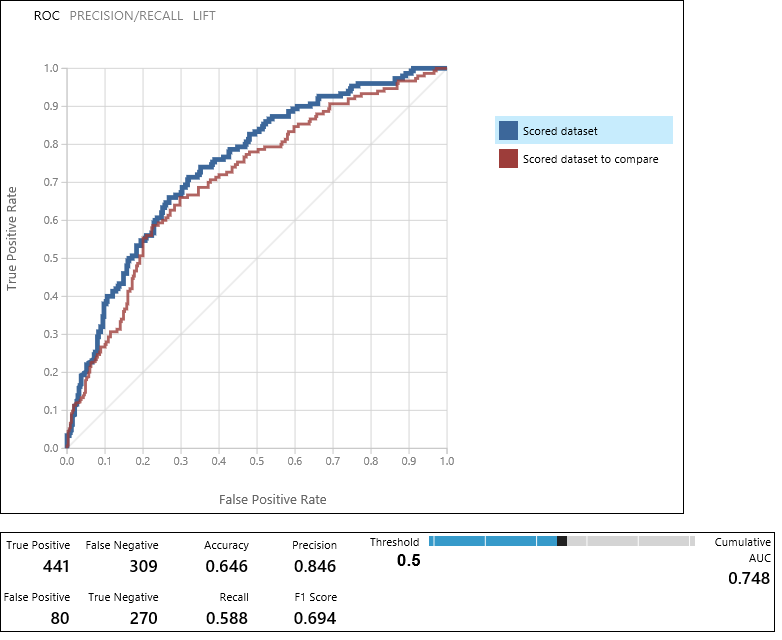
En examinant ces valeurs, vous pouvez déterminer quel modèle est le plus susceptible de fournir les résultats que vous recherchez. Vous pouvez revenir en arrière et relancer votre expérience en modifiant les valeurs des différents modèles.
Ce tutoriel n’explique pas comment interpréter ces résultats et optimiser les performances du modèle. Pour en savoir plus, consultez les articles suivants :
- Évaluation des performances d’un modèle dans Machine Learning Studio (classique)
- Choisir les paramètres permettant d’optimiser des algorithmes dans Machine Learning Studio (classique)
- Interpréter les résultats de modèle dans Machine Learning Studio (classique)
Conseil
À chaque exécution de l’expérience, un enregistrement de cet essai est conservé dans l’historique d’exécution. Vous pouvez afficher tous les essais de votre expérience (et y revenir) en cliquant sur AFFICHER L'HISTORIQUE D'EXÉCUTION , sous le canevas. Vous pouvez également cliquer sur Exécution précédente dans le volet Propriétés pour revenir à l’exécution précédant immédiatement celle que vous avez ouverte.
Vous pouvez faire une copie d’un essai de votre expérience en cliquant sur ENREGISTRER SOUS sous le canevas. Utilisez les propriétés Résumé et Description de l’expérience pour conserver un enregistrement de vos essais dans les itérations de l’expérience.
Pour plus d’informations, voir Gestion des itérations d’expériences dans Azure Machine Learning Studio (classique).
Nettoyer les ressources
Si vous n’avez plus besoin des ressources que vous avez créées dans le cadre de cet article, supprimez-les pour éviter des frais inutiles. Découvrez comment faire dans l’article Exporter et supprimer des données utilisateur intégrées dans le produit.
Étapes suivantes
Dans ce tutoriel, vous avez effectué les étapes suivantes :
- Créer une expérience
- Entraîner plusieurs modèles
- Notation et évaluation des modèles
Vous êtes maintenant prêt à déployer des modèles pour ces données.