Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Les clusters Big Data Microsoft SQL Server 2019 sont mis hors service. La prise en charge des clusters Big Data SQL Server 2019 a pris fin le 28 février 2025. Pour plus d’informations, consultez le billet de blog d’annonce et les options Big Data sur la plateforme Microsoft SQL Server.
Étant donné que les clusters Big Data SQL Server se trouvent sur Kubernetes en tant qu’applications conteneurisées et qu’ils utilisent des fonctionnalités telles que des ensembles avec état et un stockage persistant, cette infrastructure intègre le contrôle d’intégrité, la détection des défaillances et les mécanismes de basculement que les composants de cluster exploitent pour maintenir l’intégrité du service. Pour une fiabilité accrue, vous pouvez également configurer l’instance principale SQL Server et/ou le nœud de nom HDFS et les services partagés Spark à déployer avec des réplicas supplémentaires dans une configuration à haute disponibilité. La supervision, la détection des défaillances et le basculement automatique sont gérés par le service de gestion de cluster Big Data, à savoir le service de contrôle. Ce service assure toutes les opérations, sans intervention de l’utilisateur, de la configuration du groupe de disponibilité jusqu’à l’ajout de bases de données au groupe de disponibilité et à la coordination du basculement et des mises à niveau, en passant par la configuration des points de terminaison de mise en miroir de bases de données.
L’image suivante illustre le déploiement d’un groupe de disponibilité dans un cluster Big Data SQL Server :
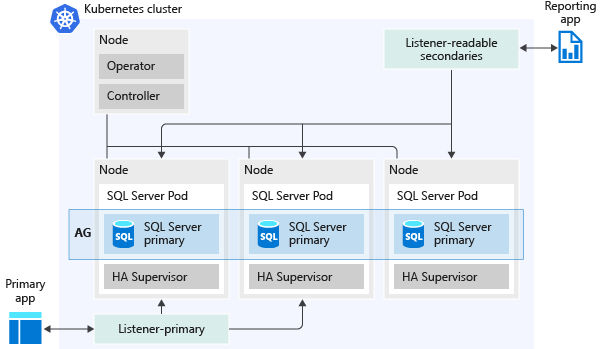
Voici quelques-unes des fonctionnalités favorisées par les groupes de disponibilité :
Si les paramètres de haute disponibilité sont spécifiés dans le fichier de configuration de déploiement, un seul groupe de disponibilité nommé
containedagest créé. Par défaut,containedaga trois réplicas, y compris un réplica principal. Toutes les opérations CRUD pour le groupe de disponibilité sont gérées en interne, y compris la création du groupe de disponibilité ou la jonction des réplicas au groupe de disponibilité créé. Des groupes de disponibilité supplémentaires ne peuvent pas être créés dans l’instance principale SQL Server d’un cluster Big Data.Toutes les bases de données sont automatiquement ajoutées au groupe de disponibilité, y compris toutes les bases de données utilisateur et système telles que
masteretmsdb. Cette fonctionnalité fournit une vue monosystème sur les réplicas des groupes de disponibilité. Les bases de données de modèle supplémentaires (model_replicatedmasteretmodel_msdb) sont utilisées pour alimenter la partie répliquée des bases de données système. En plus de ces bases de données, vous verrez les bases de donnéescontainedag_masteretcontainedag_msdbsi vous vous connectez directement à l’instance. Les bases de donnéescontainedagreprésententmasteretmsdbau sein du groupe de disponibilité.Important
Les bases de données créées sur l’instance par des workflows comme l’attachement de base de données ne sont pas ajoutées automatiquement au groupe de disponibilité. Les administrateurs de Clusters Big Data SQL Server doivent effectuer cette opération manuellement. Pour découvrir comment activer un point de terminaison temporaire pour la base de données maître de l’instance SQL Server, consultez Se connecter à une instance SQL Server. Avant SQL Server 2019 CU2, les bases de données créées à la suite d’une instruction RESTORE avaient le même comportement et devaient être ajoutées manuellement au groupe de disponibilité contenu.
Les bases de données de configuration PolyBase ne sont pas incluses dans le groupe de disponibilité, car elles incluent des métadonnées au niveau des instances qui sont spécifiques à chaque réplica.
Un point de terminaison externe est automatiquement provisionné pour la connexion aux bases de données au sein du groupe de disponibilité. Ce point de terminaison
master-svc-externaljoue le rôle de l’écouteur du groupe de disponibilité.Un deuxième point de terminaison externe est provisionné pour les connexions en lecture seule aux réplicas secondaires afin d’effectuer un scale-out des charges de travail de lecture.
Deploy
Pour déployer une instance principale SQL Server dans un groupe de disponibilité :
- Activez la fonctionnalité
hadr - Spécifiez le nombre de réplicas pour le groupe de disponibilité (3 au minimum)
- Configurez les détails du deuxième point de terminaison externe créé pour les connexions aux réplicas secondaires en lecture seule
Vous pouvez utiliser les profils de configuration intégrés aks-dev-test-ha ou kubeadm-prod pour commencer à personnaliser votre cluster Big Data. Ces profils incluent les paramètres requis pour les ressources ; vous pouvez configurer une haute disponibilité supplémentaire. Par exemple, la section ci-dessous du fichier de configuration bdc.json se rapporte à l’activation des groupes de disponibilité pour l’instance principale SQL Server.
{
...
"spec": {
"type": "Master",
"replicas": 3,
"endpoints": [
{
"name": "Master",
"serviceType": "LoadBalancer",
"port": 31433
},
{
"name": "MasterSecondary",
"serviceType": "LoadBalancer",
"port": 31436
}
],
"settings": {
"sql": {
"hadr.enabled": "true"
}
}
}
...
}
Les étapes suivantes vous guident dans un exemple de démarrage du profil aks-dev-test-ha et de personnalisation de la configuration de votre déploiement de cluster Big Data. Pour un déploiement sur un cluster kubeadm, des étapes similaires s’appliquent, mais veillez à utiliser NodePort pour le serviceType dans la section endpoints.
Clonez le profil que vous ciblez
azdata bdc config init --source aks-dev-test-ha --target custom-aks-haÉventuellement, apportez des modifications au profil personnalisé si nécessaire.
Commencez le déploiement du cluster en utilisant le profil de configuration de cluster créé ci-dessus
azdata bdc create --config-profile custom-aks-ha --accept-eula yes
Se connecter aux bases de données SQL Server dans le groupe de disponibilité
Selon le type de charge de travail que vous souhaitez exécuter sur l’instance principale SQL Server, vous pouvez vous connecter au réplica principal pour les charges de travail en lecture-écriture ou aux bases de données des réplicas secondaires pour le type de charges de travail en lecture seule. Une description de chaque type de connexion est fournie ci-dessous :
Se connecter aux bases de données sur le réplica principal
Pour les connexions au réplica principal, utilisez le point de terminaison sql-server-master. Ce point de terminaison est également l’écouteur pour le groupe de disponibilité. Lors de l’utilisation de ce point de terminaison, toutes les connexions figurent dans le contexte des bases de données au sein du groupe de disponibilité. Par exemple, une connexion par défaut utilisant ce point de terminaison entraînera la connexion à la base de données master au sein du groupe de disponibilité, et non pas à la base de données master de l’instance SQL Server. Exécutez cette commande pour rechercher le point de terminaison :
azdata bdc endpoint list -e sql-server-master -o table
Description Endpoint Name Protocol
------------------------------------ ------------------- ----------------- ----------
SQL Server Master Instance Front-End 11.11.111.111,11111 sql-server-master tds
Note
Des événements de basculement peuvent se produire lors de l’exécution d’une requête distribuée qui accède aux données à partir de sources de données distantes telles que le pool de données ou HDFS. En guise de bonne pratique, les applications doivent être conçues de manière à disposer d’une logique de déclenchement de nouvelles tentatives de connexion en cas de déconnexions causées par le basculement.
Se connecter aux bases de données sur les réplicas secondaires
Pour une connexion en lecture seule aux bases de données figurant sur les réplicas secondaires, utilisez le point de terminaison sql-server-master-readonly. Ce point de terminaison agit comme un équilibreur de charge sur l’ensemble des réplicas secondaires. Lors de l’utilisation de ce point de terminaison, toutes les connexions figurent dans le contexte des bases de données au sein du groupe de disponibilité. Par exemple, une connexion par défaut utilisant ce point de terminaison entraînera la connexion à la base de données master au sein du groupe de disponibilité, et non pas à la base de données master de l’instance SQL Server.
azdata bdc endpoint list -e sql-server-master-readonly -o table
Description Endpoint Name Protocol
--------------------------------------------- ------------------ -------------------------- ----------
SQL Server Master Readable Secondary Replicas 11.11.111.11,11111 sql-server-master-readonly tds
Se connecter à une instance SQL Server
Pour certaines opérations telles que la définition de configurations au niveau serveur ou l’ajout manuel d’une base de données dans le groupe de disponibilité, vous devez vous connecter à l’instance SQL Server. Avant SQL Server 2019 CU2, les opérations comme sp_configure, RESTORE DATABASE ou n’importe quelle DDL des groupes de disponibilité nécessitent ce type de connexion. Par défaut, le cluster Big Data n’inclut pas de point de terminaison permettant la connexion de l’instance et vous devez exposer manuellement ce point de terminaison.
Important
Le point de terminaison exposé pour les connexions d’instance SQL Server prend uniquement en charge l’authentification SQL, même dans les clusters où Active Directory est activé. Par défaut, au cours d’un déploiement de cluster Big Data, la connexion sa est désactivée et une nouvelle connexion sysadmin est provisionnée en fonction des valeurs fournies au moment du déploiement pour les variables d’environnement AZDATA_USERNAME et AZDATA_PASSWORD.
Important
Le DDL du groupe de disponibilité contenu est autogéré exclusivement dans le BDC. Toute tentative de la part d'un utilisateur externe de supprimer la disponibilité contenue ou le point de terminaison de mise en miroir de bases de données n’est pas prise en charge et peut entraîner un état BDC irrécupérable.
Voici un exemple illustrant comment exposer ce point de terminaison, puis ajouter la base de données créée avec un workflow de restauration dans le groupe de disponibilité. Des instructions similaires pour la configuration d’une connexion à l’instance principale SQL Server s’appliquent lorsque vous souhaitez modifier les configurations de serveur avec sp_configure.
Note
À compter de SQL Server 2019 CU2, les bases de données créées par un workflow RESTORE sont ajoutées automatiquement au groupe de disponibilité contenu.
Déterminez le pod qui héberge le réplica principal en vous connectant au point de terminaison
sql-server-masteret exécutez :SELECT @@SERVERNAMEExposez le point de terminaison externe en créant un nouveau service Kubernetes
Pour un cluster
kubeadm, exécutez la commande ci-dessous. RemplacezpodNamepar le nom du serveur retourné à l’étape précédente,serviceNamepar le nom par défaut du service Kubernetes créé etnamespaceName* par le nom de votre cluster Big Data.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortPour l’exécution d’un cluster AKS, exécutez la même commande, si ce n’est que le type du service créé sera
LoadBalancer. For example:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerVoici un exemple de cette commande exécutée sur AKS, où le pod hébergeant le réplica principal est
master-0:kubectl -n mssql-cluster expose pod master-0 --port=1533 --name=master-sql-0 --type=LoadBalancerObtenez l’adresse IP du service Kubernetes créé :
kubectl get services -n <namespaceName>
Important
En guide de bonne pratique, vous devez effectuer un nettoyage en supprimant le service Kubernetes créé ci-dessus en exécutant la commande suivante :
kubectl delete svc master-sql-0 -n mssql-cluster
Ajoutez la base de données au groupe de disponibilité.
Pour que la base de données soit ajoutée au groupe de disponibilité, elle doit s’exécuter en mode de récupération complète et une sauvegarde de fichier journal doit être effectuée. Utilisez l’adresse IP du service Kubernetes créé ci-dessus et connectez-vous à l’instance SQL Server, puis exécutez les instructions T-SQL comme indiqué ci-dessous.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>L’exemple suivant ajoute une base de données nommée
salesqui a été restaurée sur l’instance :ALTER DATABASE sales SET RECOVERY FULL; BACKUP DATABASE sales TO DISK='/var/opt/mssql/data/sales.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE sales
Known limitations
Voici les limitations et problèmes connus avec les groupes de disponibilité autonomes pour l’instance principale SQL Server dans un cluster Big Data :
- La configuration de la haute disponibilité doit être créée lors du déploiement du cluster Big Data. Vous ne pouvez pas activer la configuration de la haute disponibilité avec les groupes de disponibilité après le déploiement. Pour l’instant, la seule configuration activée concerne les réplicas de validation synchrone.
Warning
Quand le mode de synchronisation est mis à jour sur la validation asynchrone pour l’un des réplicas de la validation du quorum, la configuration de la haute disponibilité n’est plus valide. Cette configuration présente un risque de perte de données, car en cas de défaillance du réplica principal, aucun basculement automatique n’est déclenché et l’utilisateur doit tenir compte du risque de perte de données lors d’un basculement manuel.
- Pour restaurer correctement une base de données compatible TDE à partir d’une sauvegarde créée sur un autre serveur, vous devez vérifier que les certificats nécessaires sont restaurés sur l’instance maître SQL Server et le maître AG contenu. Vous trouverez ici un exemple de sauvegarde et de restauration de certificats.
- Certaines opérations comme l’exécution de paramètres de configuration de serveur avec
sp_configurenécessitent une connexion à la base de donnéesmasterde l’instance SQL Server, et non pas au groupe de disponibilitémaster. Vous ne pouvez pas utiliser le point de terminaison principal correspondant. Suivez ces instructions pour exposer un point de terminaison et vous connecter à l’instance SQL Server, et exécutezsp_configure. Vous pouvez uniquement utiliser l’authentification SQL lors de l’exposition manuelle du point de terminaison pour vous connecter à la base de donnéesmasterde l’instance SQL Server. - Alors que la base de données msdb autonome est incluse dans le groupe de disponibilité et que les tâches SQL Agent sont répliquées, les tâches ne s’exécutent qu’en fonction de la planification du réplica principal.
- La fonctionnalité de réplication n’est pas prise en charge pour les groupes de disponibilité autonomes. Les instances SQL Server membres d’un groupe de disponibilité autonome ne peuvent pas fonctionner comme bases de données du serveur de distribution ou de publication, que ce soit au niveau de l’instance ou au niveau du groupe.
- Il n’est pas possible d’ajouter des groupes de fichiers lors de la création de la base de données. Pour contourner ce problème, vous pouvez commencer par créer la base de données, puis émettre une instruction ALTER DATABASE pour ajouter des groupes de fichiers.
- Avant SQL Server 2019 CU2, les bases de données créées par des workflows autres que
CREATE DATABASEetRESTORE DATABASE, commeCREATE DATABASE FROM SNAPSHOT, ne sont pas automatiquement ajoutées au groupe de disponibilité. Connectez-vous à l’instance et ajoutez manuellement la base de données au groupe de disponibilité. - Service Broker et Database Mail ne sont actuellement pas pris en charge sur les Clusters Big Data déployés avec une haute disponibilité.
Next steps
- Pour plus d’informations sur l’utilisation de fichiers de configuration dans le déploiement de clusters Big Data, consultez Guide pratique pour déployer des Clusters Big Data SQL Server sur Kubernetes.
- Pour plus d’informations sur la fonctionnalité Groupes de disponibilité pour SQL Server, consultez Vue d’ensemble des groupes de disponibilité AlwaysOn (SQL Server).