Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :![]() SQL Server
SQL Server
Cet article présente les concepts relatifs aux groupes de disponibilité Always On essentiels pour configurer et gérer un ou plusieurs groupes de disponibilité dans l'Enterprise Edition de SQL Server. Pour l’édition Standard, consultez Groupes de disponibilité Always On de base pour une base de données unique.
La fonctionnalité Groupes de disponibilité Always On est une solution de haute disponibilité et de récupération d'urgence qui fournit une alternative au niveau de l'entreprise à la mise en miroir de bases de données. Les groupes de disponibilité Always On optimisent la disponibilité d’un ensemble de bases de données utilisateur pour une entreprise. Un groupe de disponibilité prend en charge un environnement de basculement pour un ensemble discret de bases de données utilisateur, appelées bases de données de disponibilité, qui basculent de concert. Un groupe de disponibilité prend en charge un ensemble de bases de données primaires en lecture-écriture et un à huit ensembles de bases de données secondaires correspondantes. Éventuellement, les bases de données secondaires peuvent être rendues disponibles pour l'accès en lecture seule et/ou certaines opérations de sauvegarde.
Avec SQL Server activé par Azure Arc, vous pouvez afficher les groupes de disponibilité dans le portail Azure.
Vue d’ensemble
Un groupe de disponibilité prend en charge un environnement répliqué pour un ensemble discret de bases de données utilisateur, appelées bases de données de disponibilité. Vous pouvez créer un groupe de disponibilité pour avoir un haut niveau de disponibilité ou pour une échelle lecture. Un groupe de disponibilité avec un haut niveau de disponibilité est un groupe de bases de données qui basculent en même temps. Un groupe de disponibilité avec échelle lecture est un groupe de bases de données copiées dans d’autres instances de SQL Server pour une charge de travail en lecture seule. Un groupe de disponibilité prend en charge un ensemble de bases de données principales et de un à huit ensembles de bases de données secondaires correspondantes. Les bases de données secondaires ne sont pas des sauvegardes. Continuez à sauvegarder vos bases de données et leurs journaux des transactions de manière régulière.
Conseil
Vous pouvez créer n'importe quel type de sauvegarde d'une base de données primaire. Vous pouvez également créer des sauvegardes de journaux et des sauvegardes complètes de copie uniquement des bases de données secondaires. Pour plus d’informations, consultez Décharger les sauvegardes prises en charge vers des réplicas secondaires d’un groupe de disponibilité.
Chaque ensemble de bases de données de disponibilité est hébergé par un réplica de disponibilité. Il existe deux types de réplicas de disponibilité : un réplica principal qui héberge les bases de données principales et un à huit réplicas secondaires qui hébergent un ensemble de bases de données secondaires et servent de cibles potentielles de basculement du groupe de disponibilité. Un groupe de disponibilité bascule au niveau d'un réplica de disponibilité. Un réplica de disponibilité apporte la redondance uniquement au niveau de la base de données, pour l’ensemble des bases de données d’un groupe de disponibilité. Les basculements ne sont pas dus à des problèmes de base de données, tels qu'une base de données devenant suspecte en raison de la perte d'un fichier de données ou de l'altération d'un journal des transactions.
Le réplica principal rend les bases de données primaires disponibles pour les connexions en lecture-écriture à partir des clients. Le réplica principal envoie les enregistrements du journal des transactions de chaque base de données primaire à chaque base de données secondaire. Ce processus (appelé synchronisation des données) se produit au niveau de la base de données. Chaque réplica secondaire met en cache les enregistrements du journal des transactions (renforce le journal) puis les applique à sa base de données secondaire correspondante. La synchronisation des données se produit entre la base de données primaire et chaque base de données secondaire connectée, indépendamment des autres bases de données. Par conséquent, une base de données secondaire peut échouer ou être suspendue sans affecter d’autres bases de données secondaires, et une base de données primaire peut échouer ou être suspendue sans affecter d’autres bases de données primaires.
Éventuellement, vous pouvez configurer un ou plusieurs réplicas secondaires pour prendre en charge l'accès en lecture seule aux bases de données secondaires, et vous pouvez configurer tout réplica secondaire pour permettre des sauvegardes sur des bases de données secondaires.
SQL Server 2017 (14.x) a introduit deux architectures différentes pour les groupes de disponibilité. Les groupes de disponibilité Always On permettent un haut niveau de disponibilité, la récupération d'urgence et l’équilibrage de charge en lecture. Ces groupes de disponibilité nécessitent un gestionnaire de cluster. Dans Windows, la fonctionnalité de clustering de basculement fournit le gestionnaire du cluster. Dans Linux, vous pouvez utiliser Pacemaker. L’autre architecture est un groupe de disponibilité avec échelle lecture. Un groupe de disponibilité avec échelle lecture fournit des réplicas pour les charges de travail en lecture seule, mais pas de haut niveau de disponibilité. Dans un groupe de disponibilité avec échelle lecture, il n’existe pas de gestionnaire de cluster, car le basculement ne peut pas être automatique.
Le déploiement de Groupes de disponibilité Always On pour une haute disponibilité sur Windows nécessite un cluster de basculement Windows Server (WSFC). Chaque réplica de disponibilité d'un groupe de disponibilité donné doit résider sur un nœud différent du même cluster WSFC. La seule exception survient lors de la migration vers un autre cluster WSFC : un groupe de disponibilité peut temporairement chevaucher deux clusters.
Note
Pour plus d’informations sur les groupes de disponibilité sur Linux, consultez Groupes de disponibilité Always On pour SQL Server sur Linux.
Dans une configuration à haut niveau de disponibilité, un rôle de cluster est créé pour chaque groupe de disponibilité que vous créez. Le cluster WSFC surveille ce rôle pour évaluer l'intégrité du réplica principal. Le quorum pour Groupes de disponibilité Always On est basé sur tous les nœuds du cluster WSFC, indépendamment du fait qu'un nœud de cluster donné héberge des réplicas de disponibilité. Contrairement à la mise en miroir de bases de données, il n'existe aucun rôle de témoin dans Groupes de disponibilité Always On.
Note
Pour plus d’informations sur la relation entre les composants SQL Server Always On et le cluster WSFC, consultez Clustering de basculement Windows Server (SQL) avec SQL Server.
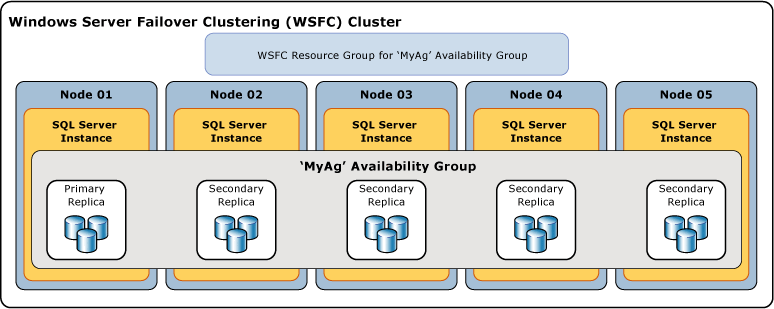
L'illustration suivante montre un groupe de disponibilité qui contient un réplica principal et quatre réplicas secondaires. Jusqu'à huit réplicas secondaires sont pris en charge, notamment un réplica principal et quatre réplicas secondaires avec validation synchrone.
Configurer le chiffrement TLS 1.3
SQL Server 2025 (17.x) introduit la prise en charge du flux de données tabulaire 8.0, qui vous permet d’appliquer le chiffrement TLS 1.3 pour la communication entre le cluster de basculement Windows Server et vos réplicas de groupe de disponibilité Always On.
Pour plus d’informations, consultez la prise en charge TDS 8 dans SQL Server 2025 plus loin dans cet article.
Pour commencer, passez en revue Connect avec un chiffrement strict.
Termes et définitions
| Terme | Descriptif |
|---|---|
| groupe de disponibilité | Conteneur d’un ensemble de bases de données ( bases de données de disponibilité) qui basculent ensemble. |
| base de données de disponibilité | Base de données qui appartient à un groupe de disponibilité. Pour chaque base de données de disponibilité, le groupe de disponibilité conserve une seule copie en lecture-écriture (la base de données primaire) et une à huit copies en lecture seule (lesbases de données secondaires). |
| base de données principale | Copie en lecture-écriture d'une base de données de disponibilité. |
| base de données secondaire | Copie en lecture seule d'une base de données de disponibilité. |
| réplica de disponibilité | Une instance spécifique de SQL Server héberge et gère une copie locale de chaque base de données de disponibilité appartenant à un groupe de disponibilité qu'elle instancie. Il existe deux types de réplicas de disponibilité : un seul réplica principal et un à huit réplicas secondaires. |
| réplica principal | Réplica de disponibilité qui rend les bases de données primaires disponibles pour les connexions en lecture-écriture à partir des clients et envoie également des enregistrements du journal des transactions pour chaque base de données primaire à chaque réplica secondaire. |
| réplica secondaire | Réplica de disponibilité qui conserve une copie secondaire de chaque base de données de disponibilité, et sert de cible potentielle d'un basculement du groupe de disponibilité. Éventuellement, un réplica secondaire peut prendre en charge l'accès en lecture seule et la création de sauvegardes sur des bases de données secondaires. |
| écouteur de groupe de disponibilité | Nom du serveur auquel les clients peuvent se connecter afin d’accéder à une base de données sur un réplica principal ou secondaire d’un groupe de disponibilité. Les écouteurs de groupe de disponibilité dirigent les connexions entrantes vers un réplica principal ou un réplica secondaire en lecture seule. |
Bases de données de disponibilité
Pour ajouter une base de données à un groupe de disponibilité, la base de données doit être une base de données en ligne en lecture-écriture qui existe sur l'instance de serveur qui héberge le réplica principal. Lorsque vous ajoutez une base de données, elle joint le groupe de disponibilité comme base de données primaire, tout en restant disponible aux clients. Aucune base de données secondaire correspondante n’existe tant que vous ne restaurez pas les sauvegardes de la nouvelle base de données primaire sur l’instance de serveur qui héberge le réplica secondaire (à l’aide de RESTORE WITH NORECOVERY). La nouvelle base de données secondaire est dans l’état RESTORING jusqu’à ce qu’elle soit jointe au groupe de disponibilité. Pour plus d’informations, consultez Démarrer un déplacement de données sur une base de données secondaire Always On (SQL Server).
La jointure place la base de données secondaire dans l’état ONLINE et lance la synchronisation des données avec la base de données primaire correspondante. La synchronisation des données correspond au processus par lequel les modifications apportées à une base de données principale sont reproduites sur une base de données secondaire. La synchronisation des données implique l'envoi par la base de données primaire d'enregistrements de journal des transactions à la base de données secondaire.
Importante
Une base de données de disponibilité est parfois appelée réplica de base de données dans Transact-SQL, PowerShell et les noms SMO (SQL Server Management Objects). Par exemple, le terme « réplica de base de données » est utilisé dans les noms des vues de gestion dynamique Always On qui retournent des informations sur les bases de données de disponibilité : sys.dm_hadr_database_replica_states et sys.dm_hadr_database_replica_cluster_states. Toutefois, dans la documentation en ligne de SQL Server, le terme « réplica » fait généralement référence aux réplicas de disponibilité. Par exemple, les termes « réplica principal » et « réplica secondaire » font toujours référence aux réplicas de disponibilité.
Réplicas de disponibilité
Chaque groupe de disponibilité définit un ensemble de deux partenaires de basculement ou plus, appelés réplicas de disponibilité. Les réplicas de disponibilité sont des composants du groupe de disponibilité. Chaque réplica de disponibilité héberge une copie des bases de données de disponibilité dans le groupe de disponibilité. Pour un groupe de disponibilité donné, des instances distinctes de SQL Server résidant sur différents nœuds d’un cluster WSFC doivent héberger les réplicas de disponibilité. Chacune de ces instances de serveur doit être activée pour Always On.
SQL Server 2019 (15.x) augmente le nombre maximal de réplicas synchrones à 5, contre 3 dans SQL Server 2017 (14.x). Vous pouvez configurer ce groupe de cinq réplicas de manière à instaurer le basculement automatique en son sein. Il existe un seul réplica principal, plus quatre réplicas secondaires synchrones.
Un instance donnée ne peut héberger qu'un seul réplica de disponibilité par groupe de disponibilité. Toutefois, vous pouvez utiliser chaque instance pour de nombreux groupes de disponibilité. Une instance donnée peut être une instance autonome ou une instance de cluster de basculement SQL Server (FCI). Si vous avez besoin d'une redondance au niveau serveur, utilisez des instances de cluster de basculement.
Chaque réplica de disponibilité est affecté à un rôle initial : le rôle principal ou le rôle secondaire, que les bases de données de disponibilité de ce réplica héritent. Le rôle d'un réplica donné détermine s'il héberge les bases de données en lecture-écriture ou les bases de données en lecture seule. Un réplica, appelé réplica principal, se voit attribuer le rôle principal et héberge les bases de données en lecture-écriture, qui sont appelées bases de données primaires. Au moins un autre réplica, appelé réplica secondaire, se voit attribuer le rôle secondaire. Un réplica secondaire héberge les bases de données en lecture seule, appelées bases de données secondaires.
Note
Lorsque le rôle d’un réplica de disponibilité est indéterminé, par exemple lors d’un basculement, ses bases de données sont temporairement dans un état NOT SYNCHRONIZING. Leur rôle est défini à RESOLVING jusqu'à ce que le rôle du réplica de disponibilité soit terminé. Si un réplica de disponibilité est résolu en rôle principal, ses bases de données deviennent les bases de données primaires. Si un réplica de disponibilité est résolu en rôle secondaire, ses bases de données deviennent les bases de données secondaires.
Modes de disponibilité
Chaque réplica de disponibilité possède une propriété de mode de disponibilité. Le mode de disponibilité détermine si le réplica principal attend de valider les transactions sur une base de données jusqu’à ce qu’un réplica secondaire donné écrit les enregistrements du journal des transactions sur le disque (renforce le journal). Les groupes de disponibilité Always On prennent en charge deux modes de disponibilité : le mode de validation asynchrone et le mode de validation synchrone.
Mode de validation asynchrone.
Un réplica de disponibilité qui utilise ce mode de disponibilité est appelé réplica en validation asynchrone. En mode de validation asynchrone, le réplica principal valide les transactions sans attendre d’accusé de réception confirmant qu’un réplica secondaire avec validation asynchrone a renforcé les journaux des transactions. Le mode de validation asynchrone réduit la latence de transaction sur les bases de données secondaires, mais leur permet d'être antérieures aux bases de données primaires, ce qui rend possible la perte de données.
Mode de validation synchrone
Un réplica de disponibilité qui utilise ce mode de disponibilité est appelé réplica avec validation synchrone. En mode de validation synchrone, avant de valider des transactions, un réplica principal de validation synchrone attend qu’un réplica secondaire de validation synchrone reconnaisse qu’il a terminé de renforcer le journal. Le mode de validation synchrone garantit qu'une fois qu'une base de données secondaire particulière est synchronisée avec la base de données primaire, les transactions validées sont entièrement protégées. Cette protection se fait au prix d'une latence accrue des transactions. Si vous le souhaitez, SQL Server 2017 (14.x) a introduit une fonctionnalité secondaire synchronisée requise pour renforcer la sécurité au coût de la latence lorsque vous le souhaitez. La
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITfonctionnalité peut être activée pour exiger un nombre spécifié de réplicas synchrones pour valider une transaction avant qu’un réplica principal soit autorisé à valider.
Pour plus d’informations, consultez Différences entre les modes de disponibilité pour un groupe de disponibilité Always On.
Types de basculement
Dans le contexte d’une session entre le réplica principal et un réplica secondaire, les rôles principaux et secondaires peuvent basculer dans un processus appelé basculement. Pendant un basculement, la réplique secondaire cible passe au rôle principal et devient la nouvelle réplique principale. Le nouveau réplica principal met ses bases de données en ligne comme bases de données primaires, et les applications clientes peuvent se connecter à ces dernières. Lorsque l’ancien réplica principal est disponible, il passe au rôle secondaire et devient un réplica secondaire. Les bases de données primaires précédentes deviennent les bases de données secondaires et la synchronisation des données reprend.
Un groupe de disponibilité bascule au niveau d'un réplica de disponibilité. Les basculements ne se produisent pas en raison de problèmes de base de données tels qu’une base de données devenant suspecte en raison d’une perte d’un fichier de données, de la suppression d’une base de données ou d’une altération d’un journal des transactions.
Trois formes de basculement existent : automatique, manuel et forcé (avec perte de données possible). Les formes de basculement qu’un réplica secondaire donné prend en charge dépendent de son mode de disponibilité. Le mode de validation synchrone dépend également du mode de basculement sur le réplica principal et le réplica secondaire visé, comme suit.
Le mode de validation synchrone prend en charge deux formes de basculement : basculement manuel planifié et basculement automatique, si le réplica secondaire cible est actuellement synchronisé avec le réplica principal. Le paramètre de la propriété du mode de basculement sur les partenaires de basculement détermine le support de ces formes de basculement. Si vous définissez le mode de basculement sur manuel pour le réplica principal ou secondaire, le réplica secondaire prend uniquement en charge le basculement manuel. Si vous définissez le mode de basculement sur automatique à la fois sur le réplica principal et sur le réplica secondaire, alors le réplica secondaire prend en charge le basculement automatique et manuel.
Basculement manuel planifié (sans perte de données)
Un basculement manuel se produit après qu’un administrateur de base de données émet une commande de basculement. Il entraîne la transition d’un réplica secondaire synchronisé vers le rôle principal (avec garantie de protection des données) et la transition du réplica principal vers le rôle secondaire. Un basculement manuel nécessite que le réplica principal et le réplica secondaire cible s’exécutent en mode de validation synchrone, et que le réplica secondaire doit déjà être synchronisé.
Basculement automatique (sans perte de données)
Un basculement automatique se produit en réponse à une défaillance. Il entraîne la transition d’un réplica secondaire synchronisé vers le rôle principal (avec protection des données garantie). Lorsque l'ancienne réplique primaire devient disponible, elle passe au rôle secondaire. Le basculement automatique nécessite que le réplica principal et le réplica secondaire cible s’exécutent en mode de validation synchrone avec le mode de basculement défini sur Automatique. En outre, le réplica secondaire doit déjà être synchronisé, posséder le quorum WSFC et remplir les conditions spécifiées par la stratégie de basculement souple du groupe de disponibilité.
En mode de validation asynchrone, la seule forme de basculement est le basculement manuel forcé (avec perte de données possible), généralement appelé basculement forcé. Le basculement forcé est une forme de basculement manuel, car vous devez le lancer manuellement. Le basculement forcé est une option de récupération d'urgence. Il s’agit de la seule forme de basculement possible lorsque le réplica secondaire cible n’est pas synchronisé avec le réplica principal.
Pour plus d’informations, consultez Basculement et modes de basculement (groupes de disponibilité Always On).
Importante
- Les instances de cluster de basculement SQL Server ne prennent pas en charge le basculement automatique par groupes de disponibilité. Vous ne pouvez donc configurer que le basculement manuel pour tous les réplicas de disponibilité qu’un hôte FCI héberge.
- Si vous exécutez une commande de basculement forcé sur un réplica secondaire synchronisé, le réplica secondaire se comporte de la même manière que pour un basculement manuel planifié.
Avantages
Les groupes de disponibilité Always On offrent un large éventail d'options qui améliorent la disponibilité des bases de données et l'utilisation des ressources. Les composants clés sont les suivants :
Prend en charge jusqu'à neuf réplicas de disponibilité. Un réplique de disponibilité est une instanciation d’un groupe de disponibilité qu’une instance spécifique de SQL Server héberge. Il gère une copie locale de chaque base de données de disponibilité qui appartient au groupe de disponibilité. Chaque groupe de disponibilité prend en charge un réplica principal et jusqu'à huit réplicas secondaires. Pour plus d’informations, consultez Qu’est-ce qu’un groupe de disponibilité Always On ?
Importante
Chaque réplica de disponibilité doit résider sur un nœud différent d'un cluster de clustering de basculement Windows Server (WSFC). Pour plus d’informations sur les prérequis, les restrictions et les recommandations pour les groupes de disponibilité, consultez Prérequis, restrictions et recommandations pour les groupes de disponibilité Always On.
Prend en charge d'autres modes de disponibilité, comme suit :
Mode de validation asynchrone. Ce mode avec validation asynchrone est une solution de récupération d'urgence qui fonctionne bien lorsque les réplicas de disponibilité sont séparés par des distances considérables.
Mode de validation synchrone. Ce mode de disponibilité privilégie la haute disponibilité et la protection des données plutôt que les performances, au prix d'une latence accrue des transactions. Un groupe de disponibilité donné peut prendre en charge jusqu’à cinq réplicas de disponibilité avec validation synchrone, y compris le réplica principal actuel.
Pour plus d’informations, consultez Différences entre les modes de disponibilité pour un groupe de disponibilité Always On.
Prend en charge plusieurs formes de basculement de groupe de disponibilité : basculement automatique, basculement manuel planifié (généralement appelé basculement manuel) et basculement manuel forcé (généralement appelé basculement forcé). Pour plus d’informations, consultez Basculement et modes de basculement (groupes de disponibilité Always On).
Vous permet de configurer un réplica de disponibilité donné pour prendre en charge l'une des deux fonctions secondaires actives suivantes :
Accès en lecture seule, qui permet aux connexions en lecture seule au réplica d’accéder à ses bases de données et de les lire lorsqu'il s'exécute comme réplica secondaire. Pour plus d’informations, consultez Décharger une charge de travail en lecture seule vers un réplica secondaire d’un groupe de disponibilité Always On.
Exécution d'opérations de sauvegarde sur ses bases de données lorsqu'il s'exécute comme réplica secondaire. Pour plus d’informations, consultez Décharger les sauvegardes prises en charge vers des réplicas secondaires d’un groupe de disponibilité.
L'utilisation de fonctions secondaires actives améliore l'efficacité informatique et réduit les coûts grâce à une meilleure utilisation des ressources du matériel secondaire. En outre, le déchargement des applications de tentative de lecture et des travaux de sauvegarde vers des réplicas secondaires permet d'améliorer les performances au niveau du réplica principal.
Prend en charge un écouteur de groupe de disponibilité pour chaque groupe de disponibilité. Un écouteur de groupe de disponibilité est un nom de serveur auquel les clients peuvent se connecter afin d’accéder à une base de données sur un réplica principal ou secondaire d’un groupe de disponibilité Always On. Les écouteurs de groupe de disponibilité dirigent les connexions entrantes vers un réplica principal ou un réplica secondaire en lecture seule. L'écouteur fournit un basculement d'application rapide après le basculement d'un groupe de disponibilité. Pour plus d’informations sur SQL Always On, consultez Se connecter à un écouteur de groupe de disponibilité Always On.
Prend en charge une stratégie de basculement flexible pour un contrôle optimisé du basculement de cluster de disponibilité. Pour plus d’informations, consultez Basculement et modes de basculement (groupes de disponibilité Always On).
Prend en charge la réparation de page automatique pour éviter les pages endommagées. Pour plus d’informations, consultez Réparation de page automatique (Groupes de disponibilité : mise en miroir de bases de données).
Prend en charge le chiffrement et la compression, qui fournissent un transport sécurisé et efficace.
Fournit un jeu intégré d'outils pour simplifier le déploiement et la gestion de groupes de disponibilité, notamment :
Instructions DDL Transact-SQL pour créer et gérer les groupes de disponibilité. Pour plus d’informations, consultez Instructions Transact-SQL pour les groupes de disponibilité Always On.
SQL Server Management Studio , comme suit :
L' Assistant Nouveau groupe de disponibilité crée et configure un groupe de disponibilité. Dans certains environnements, cet Assistant peut également préparer automatiquement les bases de données secondaires et démarrer la synchronisation de données pour chacune d'elles. Pour plus d’informations, consultez Utiliser la boîte de dialogue Nouveau groupe de disponibilité (SQL Server Management Studio).
L'Assistant Ajouter une base de données au groupe de disponibilité ajoute une ou plusieurs bases de données primaires à un groupe de disponibilité existant. Dans certains environnements, cet Assistant peut également préparer automatiquement les bases de données secondaires et démarrer la synchronisation de données pour chacune d'elles. Pour en savoir plus, consultez Ajouter une base de données à un groupe de disponibilité Always On avec l’Assistant Groupe de disponibilité.
L' Assistant Ajouter un réplica au groupe de disponibilité ajoute un ou plusieurs réplicas secondaires à un groupe de disponibilité existant. Dans certains environnements, cet Assistant peut également préparer automatiquement les bases de données secondaires et démarrer la synchronisation de données pour chacune d'elles. Pour plus d’informations, consultez Ajouter un réplica à votre groupe de disponibilité Always On à l’aide de l’Assistant Groupe de disponibilité dans SQL Server Management Studio.
L'Assistant Basculer le groupe de disponibilité démarre un basculement manuel sur un groupe de disponibilité. En fonction de la configuration et de l'état du réplica secondaire que vous spécifiez comme cible de basculement, l'Assistant peut effectuer un basculement manuel planifié ou forcé. Pour plus d’informations, consultez Utiliser l’Assistant Basculer le groupe de disponibilité (SQL Server Management Studio).
Le Tableau de bord Always On surveille les groupes de disponibilité, les réplicas de disponibilité et les bases de données de disponibilité Always On, et évalue les résultats des stratégies Always On. Pour plus d’informations, consultez Utiliser le tableau de bord des groupes de disponibilité Always On (SQL Server Management Studio).
Le volet Détails de l'Explorateur d'objets affiche des informations de base à propos des groupes de disponibilité existants. Pour plus d’informations, consultez Utiliser le volet Détails de l’Explorateur d’objets pour surveiller les groupes de disponibilité.
Applets de commande PowerShell. Pour plus d’informations, consultez Vue d’ensemble des applets de commande PowerShell pour les groupes de disponibilité Always On.
Connexions clientes
Vous pouvez fournir la connectivité client au réplica principal d'un groupe de disponibilité donné en créant un écouteur de groupe de disponibilité. Un écouteur de groupe de disponibilité fournit un ensemble de ressources joint à un groupe de disponibilité donné pour diriger les connexions clientes vers le réplica de disponibilité approprié.
Un écouteur de groupe de disponibilité est associé à un nom DNS unique qui sert de nom de réseau virtuel (VNN), une ou plusieurs adresses IP virtuelles (VIP) et un numéro de port TCP. Pour plus d’informations sur SQL Always On, consultez Se connecter à un écouteur de groupe de disponibilité Always On.
Si un groupe de disponibilité n’a que deux réplicas de disponibilité et n’est pas configuré pour autoriser l’accès en lecture au réplica secondaire, les clients peuvent se connecter au réplica principal à l’aide d’une chaîne de connexion de mise en miroir de bases de données. Cette approche peut être utile temporairement après avoir migré une base de données de la mise en miroir de bases de données vers Groupes de disponibilité Always On. Avant d’ajouter des réplicas secondaires, vous devez créer un écouteur de groupe de disponibilité pour le groupe de disponibilité et mettre à jour vos applications afin qu’elles utilisent le nom réseau de l’écouteur.
Prise en charge TDS 8 dans SQL Server 2025
SQL Server 2025 (17.x) introduit la prise en charge de TDS 8.0, ce qui permet d’appliquer un chiffrement TLS 1.3 strict pour les connexions à vos réplicas et écouteurs de groupe de disponibilité Always On.
Configuration requise :
-
Nouveaux groupes de disponibilité : créez le groupe de disponibilité avec
Encrypt=Strictdans la clauseCLUSTER_CONNECTION_OPTIONSet effectuez le basculement pour appliquer les paramètres. -
Groupes de disponibilité existants : modifiez l'AG avec
CLUSTER_CONNECTION_OPTIONSla clause pour définirEncrypt=Strictet effectuez un basculement pour appliquer les paramètres. - Forcer le chiffrement strict : définissez cette option sur Oui dans le Gestionnaire de configuration SQL Server pour chaque réplica et redémarrez les réplicas SQL Server.
-
Exigences du certificat : lorsque
Encrypt=Strictest défini,TrustServerCertificateest ignoré.
Pour commencer, passez en revue Connect avec un chiffrement strict.
Réplicas secondaires actifs
Groupes de disponibilité Always On prend en charge les réplicas secondaires actifs. Les fonctions secondaires actives prennent en charge les opérations suivantes :
Exécution d'opérations de sauvegarde sur des réplicas secondaires
Les réplicas secondaires prennent en charge l’exécution de sauvegardes de journal et de sauvegardes en copie seule d’une base de données complète, de fichiers ou de groupes de fichiers. Vous pouvez configurer le groupe de disponibilité pour spécifier une préférence concernant l'emplacement où les sauvegardes doivent être effectuées. Il est important de comprendre que SQL Server n’applique pas la préférence. Il n’a donc aucun effet sur les sauvegardes ad hoc. La traduction de cette préférence dépend de la logique, le cas échéant, que vous avez écrite dans vos travaux de sauvegarde pour chacune des bases de données dans un groupe de disponibilité donné. Pour un réplica de disponibilité particulier, vous pouvez spécifier la priorité d'exécution des sauvegardes sur ce réplica par rapport aux autres réplicas dans le même groupe de disponibilité. Pour plus d’informations, consultez Décharger les sauvegardes prises en charge vers des réplicas secondaires d’un groupe de disponibilité.
Accès en lecture seule à un ou plusieurs réplicas secondaires (réplicas secondaires lisibles)
Vous pouvez configurer n’importe quel réplica de disponibilité secondaire pour autoriser uniquement l’accès en lecture seule à ses bases de données locales, bien que certaines opérations ne soient pas entièrement prises en charge. Cette configuration empêche les tentatives de connexion en lecture-écriture au réplica secondaire. Il est également possible d’empêcher les charges de travail en lecture seule sur le réplica principal en autorisant uniquement l’accès en lecture-écriture. Cette configuration empêche la création de connexions en lecture seule au réplica principal. Pour plus d’informations, consultez Décharger une charge de travail en lecture seule vers un réplica secondaire d’un groupe de disponibilité Always On.
Si un groupe de disponibilité possède actuellement un écouteur de groupe de disponibilité et un ou plusieurs réplicas secondaires lisibles, SQL Server peut acheminer les requêtes de connexion avec intention de lecture vers l'un d'eux (routage en lecture seule). Pour plus d’informations sur SQL Always On, consultez Se connecter à un écouteur de groupe de disponibilité Always On.
Période d’expiration de session
La période d’expiration de session est une propriété de réplica de disponibilité qui détermine la durée pendant laquelle une connexion avec un autre réplica de disponibilité peut rester inactive avant la fermeture de la connexion. Les réplicas primaire et secondaire exécutent réciproquement une commande ping pour signaler qu'ils sont toujours actifs. La réception d’une commande ping de l’autre réplica au cours de la période de délai d’attente indique que la connexion est toujours ouverte et que les instances de serveur communiquent. À la réception d'un ping, un réplica de disponibilité réinitialise son compteur de période d'expiration de session sur cette connexion.
La période d'expiration de session évite que l'un ou l'autre réplica attendent indéfiniment de recevoir un ping de l'autre réplica. Si aucun test ping n’est reçu de l’autre réplica pendant la période d’expiration de session, le réplica subit un délai d'expiration. Sa connexion se ferme et le réplica ayant expiré entre dans l’état DISCONNECTED. Même si un réplica déconnecté est configuré pour le mode de validation synchrone, les transactions n’attendront pas que ce réplica se reconnecte et se resynchronise.
La période d'expiration de session par défaut pour chaque réplica de disponibilité est de 10 secondes. Vous pouvez configurer cette valeur, avec un minimum de 5 secondes. En règle générale, conservez la période d’expiration à 10 secondes ou plus. En définissant une valeur inférieure à 10 secondes, vous permettez qu'un système surchargé déclare à tort un échec.
Note
Pour le rôle de résolution, la période d'expiration de session ne s'applique pas étant donné que la requête ping ne se produit pas.
Réparation de page automatique
Chaque réplica de disponibilité essaie d'effectuer une récupération automatiquement à partir de pages endommagées sur une base de données locale en résolvant certains types d'erreurs qui empêchent la lecture d'une page de données. Si un réplica secondaire ne peut pas lire une page, le réplica demande une nouvelle copie de la page au réplica principal. Si le réplica principal ne peut pas lire une page, le réplica diffuse une demande de nouvelle copie à tous les réplicas secondaires et obtient la page du premier qui y répond. Si cette demande aboutit, la page illisible est remplacée par la copie, ce qui permet généralement de résoudre l'erreur.
Pour plus d’informations, consultez Réparation de page automatique (Groupes de disponibilité : mise en miroir de bases de données).
Interopérabilité et coexistence avec d'autres fonctionnalités de moteur de base de données
Les groupes de disponibilité Always On fonctionnent avec les fonctionnalités ou composants suivants de SQL Server :
- Qu’est-ce que la capture des modifications de données (CDC) ?
- À propos du suivi des modifications (SQL Server)
- Bases de données contenues
- Chiffrement transparent des données (TDE)
- Captures instantanées de base de données avec des groupes de disponibilité Always On (SQL Server)
- FILESTREAM (SQL Server)
- FileTables (SQL Server)
- À propos de la copie des journaux de transaction (SQL Server)
- Magasin d'objets blob distants (RBS) (SQL Server)
- Réplication de SQL Server
- Service Broker
- SQL Server Agent
- Reporting Services avec les groupes de disponibilité Always On (SQL Server)
- Gouverneur de ressources
- TDS 8.0, à compter de SQL Server 2025 (17.x)
Tâches connexes
- Prérequis, restrictions et recommandations pour les groupes de disponibilité Always On
- Informations de référence sur la création et la configuration des groupes de disponibilité Always On
- Administration d’un groupe de disponibilité
- Outils pour monitorer les groupes de disponibilité AlwaysOn
- Décharger une charge de travail en lecture seule vers un réplica secondaire d’un groupe de disponibilité Always On
- Décharger les sauvegardes prises en charge vers des réplicas secondaires d’un groupe de disponibilité.
- Se connecter à un écouteur de groupe de disponibilité Always On
- Instructions Transact-SQL pour les groupes de disponibilité Always On
- Vue d’ensemble des applets de commande PowerShell pour les groupes de disponibilité Always On
- Blog SQL Server - Haute disponibilité
- Blog SQL Server
- Archive : Blogs de l’équipe SQL Server Always On : Blog officiel de l’équipe SQL Server Always On
- Archive : Blogs des ingénieurs du Service clients et du Support technique de SQL Server
- Guide des solutions Microsoft SQL Server Always On pour la haute disponibilité et la récupération d'urgence