Tutoriel : Créer un modèle de clustering dans R avec le Machine Learning SQL
S’applique à : ![]() SQL Server 2016 (13.x) et versions ultérieures
SQL Server 2016 (13.x) et versions ultérieures ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Dans la troisième partie de cette série de quatre tutoriels, vous allez créer un modèle K-moyennes dans R pour effectuer le clustering. Dans la prochaine partie de cette série, vous déploierez ce modèle dans une base de données avec SQL Server Machine Learning Services ou sur des clusters Big Data.
Dans la troisième partie de cette série de quatre tutoriels, vous allez créer un modèle K-moyennes dans R pour effectuer le clustering. Dans la prochaine partie de cette série, vous déploierez ce modèle dans une base de données avec SQL Server Machine Learning Services.
Dans la troisième partie de cette série de quatre tutoriels, vous allez créer un modèle K-moyennes dans R pour effectuer le clustering. Dans la prochaine partie de cette série, vous déploierez ce modèle dans une base de données avec SQL Server R Services.
Dans la troisième partie de cette série de quatre tutoriels, vous allez créer un modèle K-moyennes dans R pour effectuer le clustering. Dans la partie suivante de cette série, vous déploierez ce modèle dans une base de données avec Azure SQL Managed Instance Machine Learning Services.
Dans cet article, vous allez apprendre à :
- Définir le nombre de clusters pour un algorithme K-moyennes
- Effectuer le clustering
- Analyser les résultats
Dans la première partie, vous avez installé les prérequis et restauré l’exemple de base de données.
Dans la deuxième partie, vous avez préparé les données d’une base de données pour effectuer le clustering.
Dans la quatrième partie, vous apprendrez à créer une procédure stockée dans une base de données permettant d’effectuer un clustering en R en fonction de nouvelles données.
Prérequis
- La troisième partie de cette série de tutoriels part du principe que vous avez satisfait les prérequis de la première partie et effectué les étapes décrites dans la deuxième partie.
Définir le nombre de clusters
Pour regrouper vos données client en cluster, vous allez utiliser l’algorithme de clustering K-moyennes, l’un des moyens les plus simples et les plus connus de regrouper des données. Pour plus d’informations sur K-moyennes, consultez A complete guide to K-means clustering algorithm.
L’algorithme accepte deux entrées : les données elles-mêmes et un nombre prédéfini « k » représentant le nombre de clusters à générer. En sortie, vous obtenez k clusters et les données d’entrée sont partitionnées entre les clusters.
Pour déterminer le nombre de clusters que doit utiliser l’algorithme, utilisez un tracé de la somme des carrés intra groupe (« within groups sum of squares ») par rapport au nombre de clusters extraits. Le nombre approprié de clusters à utiliser se trouve au niveau de la courbe ou du « coude » du tracé.
# Determine number of clusters by using a plot of the within groups sum of squares,
# by number of clusters extracted.
wss <- (nrow(customer_data) - 1) * sum(apply(customer_data, 2, var))
for (i in 2:20)
wss[i] <- sum(kmeans(customer_data, centers = i)$withinss)
plot(1:20, wss, type = "b", xlab = "Number of Clusters", ylab = "Within groups sum of squares")
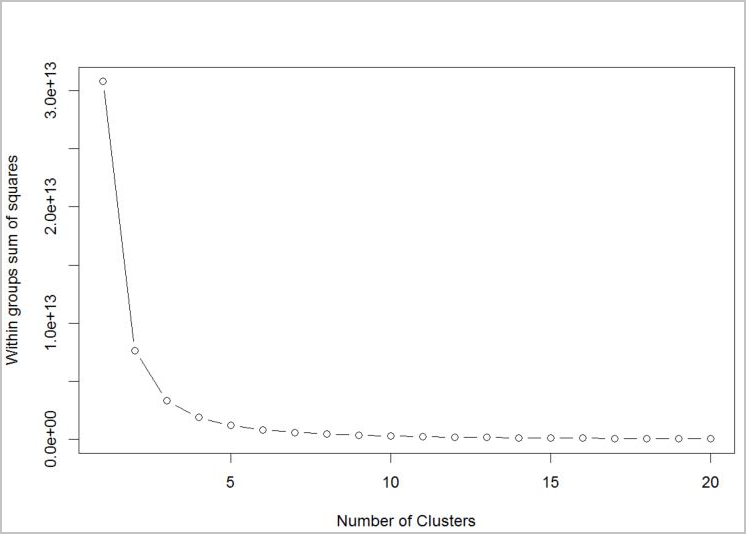
D’après le graphique, il semble que k = 4 serait une bonne valeur à tester. Cette valeur k regroupe les clients dans quatre clusters.
Effectuer le clustering
Dans le script R suivant, vous allez utiliser la fonction kmeans pour effectuer le clustering.
# Output table to hold the customer group mappings.
# Generate clusters using Kmeans and output key / cluster to a table
# called return_cluster
## create clustering model
clust <- kmeans(customer_data[,2:5],4)
## create clustering output for table
customer_cluster <- data.frame(cluster=clust$cluster,customer=customer_data$customer,orderRatio=customer_data$orderRatio,
itemsRatio=customer_data$itemsRatio,monetaryRatio=customer_data$monetaryRatio,frequency=customer_data$frequency)
## write cluster output to DB table
sqlSave(ch, customer_cluster, tablename = "return_cluster")
# Read the customer returns cluster table from the database
customer_cluster_check <- sqlFetch(ch, "return_cluster")
head(customer_cluster_check)
Analyser les résultats
Maintenant que vous avez terminé le clustering à l’aide de l’algorithme k-moyennes, l’étape suivante consiste à analyser les résultats afin de voir s’ils contiennent des informations exploitables.
#Look at the clustering details to analyze results
clust[-1]
$centers
orderRatio itemsRatio monetaryRatio frequency
1 0.621835791 0.1701519 0.35510836 1.009025
2 0.074074074 0.0000000 0.05886575 2.363248
3 0.004807692 0.0000000 0.04618708 5.050481
4 0.000000000 0.0000000 0.00000000 0.000000
$totss
[1] 40191.83
$withinss
[1] 19867.791 215.714 660.784 0.000
$tot.withinss
[1] 20744.29
$betweenss
[1] 19447.54
$size
[1] 4543 702 416 31675
$iter
[1] 3
$ifault
[1] 0
Les moyennes des quatre clusters sont fournies à partir des variables définies dans la deuxième partie :
- orderRatio = retourne le taux de commandes (nombre total de commandes partiellement ou entièrement retournées par rapport au nombre total de commandes)
- itemsRatio = retourne le taux d’éléments (nombre total d’éléments retournés par rapport au nombre d’éléments achetés)
- monetaryRatio = retourne le taux des montants (montant monétaire total des éléments retournés par rapport au montant acheté)
- frequency = fréquence de retour
L’exploration de données avec K-moyennes demande souvent une analyse plus approfondie des résultats ainsi que des étapes supplémentaires pour mieux comprendre chaque cluster, mais cela peut donner de bonnes pistes. Voici différentes interprétations possibles de ces résultats :
- Le cluster 1 (le plus grand cluster) semble correspondre à un groupe de clients inactifs (toutes les valeurs sont à zéro).
- Le cluster 3 semble être un groupe qui se distingue pour ce qui est des retours.
Nettoyer les ressources
Si vous ne poursuivez pas ce tutoriel, supprimez la base de données tpcxbb_1gb.
Étapes suivantes
Dans la troisième partie de cette série de tutoriels, vous avez appris à effectuer les tâches suivantes :
- Définir le nombre de clusters pour un algorithme K-moyennes
- Effectuer le clustering
- Analyser les résultats
Pour déployer le modèle de Machine Learning que vous avez créé, suivez la quatrième partie de cette série de tutoriels :