Utilisation de modèles de colonne dans les flux de données de mappage
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Plusieurs transformations de flux de données de mappage vous permettent de référencer des colonnes de modèles, en fonction des modèles plutôt que des noms de colonnes codés en dur. Cette correspondance est connue sous le nom de modèles de colonne. Vous pouvez définir des modèles pour faire correspondre des colonnes en fonction du nom, du type de données, du flux, de l’origine ou de la position au lieu de demander des noms de champ précis. Il existe deux scénarios dans lesquels les modèles de colonne sont utiles :
- Si les champs source entrants sont souvent modifiés, comme dans le cas de modifications de colonnes dans les fichiers texte ou les bases de données NoSQL. Ce scénario est appelé dérive de schéma.
- Si vous souhaitez effectuer une opération commune sur un grand groupe de colonnes. Par exemple, si vous voulez caster en double chaque colonne contenant « total » dans son nom de colonne.
Modèles de colonne dans une colonne dérivée et une agrégation
Pour ajouter un modèle de colonne dans une transformation de colonne, agrégation ou fenêtre dérivée, cliquez sur Ajouter au-dessus de la liste des colonnes ou sur l’icône plus en regard d’une colonne dérivée existante. Choisissez Ajouter un modèle de colonne.

Utilisez le Générateur d’expressions pour entrer la condition de correspondance. Créez une expression booléenne correspondant aux colonnes basée sur les valeurs name, type, stream, origin et position de la colonne. Le modèle affecte toute colonne, dérivée ou définie, où la condition retourne la valeur true.

Le modèle de colonne ci-dessus associe chaque colonne de type double et crée une colonne dérivée par correspondance. En indiquant $$ comme champ de nom de colonne, chaque colonne correspondante est mise à jour avec le même nom. La valeur de chaque colonne correspond à la valeur existante arrondie à deux décimales.
Pour vérifier que votre condition de correspondance est correcte, vous pouvez valider le schéma de sortie des colonnes définies dans l’onglet Inspecter, ou obtenir une capture instantanée des données dans l’onglet Aperçu des données.

Critères spéciaux hiérarchiques
Vous pouvez également créer des critères spéciaux au sein de structures hiérarchiques complexes. Développez la section Each MoviesStruct that matches où vous serez invité à spécifier chacune des hiérarchies de votre flux de données. Vous pourrez ensuite générer des critères spéciaux pour les propriétés au sein de la hiérarchie choisie.

Aplanissement de structures
Lorsque vos données comportent des structures complexes telles que des tableaux, des structures hiérarchiques et des mappages, vous pouvez utiliser la transformation Aplanir pour dérouler des tableaux et dénormaliser vos données. Pour les structures et les mappages, utilisez la transformation de colonne dérivée avec des modèles de colonne pour former votre table relationnelle aplanie à partir des hiérarchies. Vous pouvez utiliser les modèles de colonne qui ressemblent à cet exemple, ce qui aplanit la hiérarchie Geography en une forme de table relationnelle :

Mappage basé sur les règles dans la sélection et le récepteur
Lorsque vous mappez des colonnes dans les transformations de source et de sélection, vous pouvez ajouter au choix un mappage fixe ou des mappages basés sur les règles. Correspondance basée sur les valeurs name, type, stream, origin et position de colonnes. Vous pouvez réaliser n’importe quelle combinaison de mappage fixe et basé sur des règles. Par défaut, toutes les projections contenant plus de 50 colonnes ont comme valeur par défaut un mappage basé sur des règles qui correspond à chaque colonne et génère le nom entré.
Pour ajouter un mappage basé sur les règles, cliquez sur Ajouter un mappage et sélectionnez Mappage basé sur les règles.

Chaque mappage basé sur des règles nécessite deux entrées : la condition à rechercher et le nom de chaque colonne mappée. Les deux valeurs sont entrées par l’intermédiaire du générateur d’expressions. Dans la zone d’expression de gauche, entrez votre condition de correspondance booléenne. Dans la zone d’expression de droite, indiquez ce à quoi la colonne correspondante sera mappée.

Utilisez la syntaxe $$ pour référencer le nom d’entrée d’une colonne correspondante. Prenons l’image ci-dessus comme exemple et imaginons qu’un utilisateur souhaite faire correspondre toutes les colonnes de chaîne dont les noms ont moins de six caractères. Si une colonne entrante a été nommée test, l’expression $$ + '_short' renomme la colonne en test_short. Si c’est le seul mappage qui existe, toutes les colonnes qui ne répondent pas à la condition sont supprimées des données générées.
Les modèles correspondent à la fois aux colonnes dérivées et définies. Pour voir les colonnes définies qui sont mappées par une règle, cliquez sur l’icône de lunettes à côté de la règle. Vérifiez votre sortie à l’aide de l’aperçu des données.
Mappage Regex
Si vous cliquez sur l’icône du chevron pointant vers le bas, vous pouvez spécifier une condition de mappage regex. Une condition de mappage regex correspond à tous les noms de colonne qui correspondent à la condition regex spécifiée. Elle peut être utilisée en association avec les mappages standard basés sur des règles.

L’exemple ci-dessus correspond au modèle regex (r) ou à tout nom de colonne qui contient un r minuscule. À l’instar du mappage standard basé sur des règles, toutes les colonnes correspondantes sont modifiées par la condition à droite à l’aide de la syntaxe $$.
Hiérarchies basées sur des règles
Si votre projection définie a une hiérarchie, vous pouvez utiliser le mappage basé sur des règles pour mapper les sous-colonnes de hiérarchies. Spécifiez une condition de correspondance et la colonne complexe dont vous souhaitez mapper les sous-colonnes. Chaque sous-colonne correspondante est générée à l’aide de la règle « Nommer » spécifiée à droite.
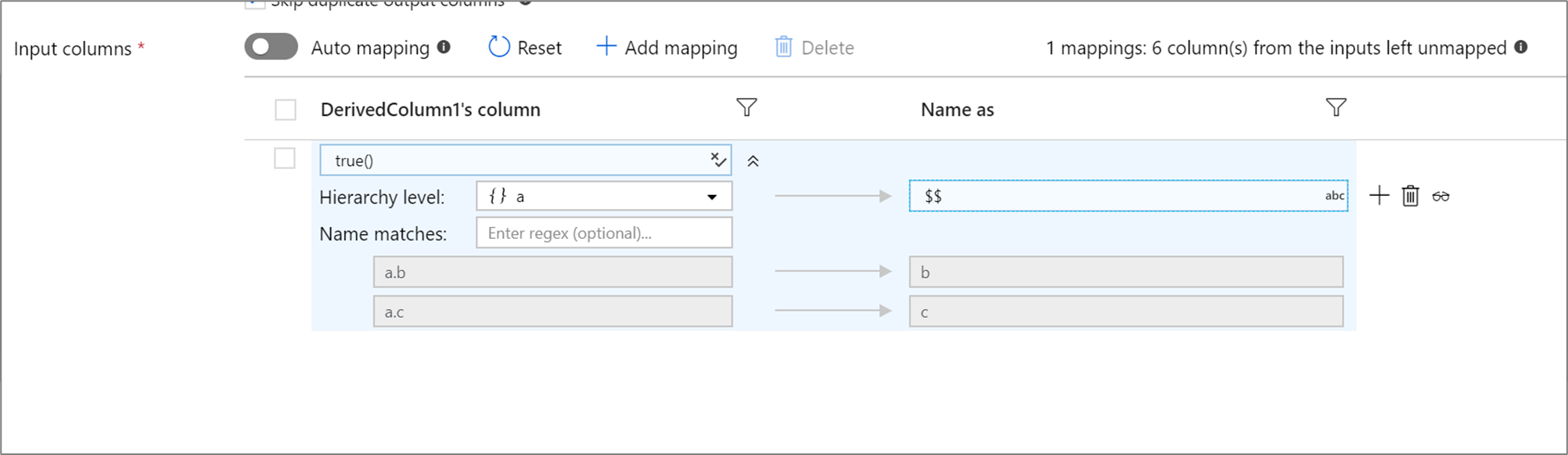
L’exemple ci-dessus correspond à toutes les sous-colonnes de la colonne complexe a. a contient deux sous-colonnes b et c. Le schéma de sortie inclut deux colonnes b et c, car la condition « Nommer » est $$.
Valeurs des expressions de critères spéciaux
$$correspond au nom ou à la valeur de chaque correspondance au moment de l'exécution Considérez$$comme l’équivalent dethis.$0se traduit par le nom de colonne actuel qui correspond au moment de l’exécution pour les types scalaires. Pour les types hiérarchiques,$0représente le chemin d’accès actuel de la hiérarchie de colonne.namereprésente le nom de chaque colonne entrantetypereprésente le type de données de chaque colonne entrante. Vous trouverez la liste des types de flux de données dans le système de type de transmission de données ici.streamreprésente le nom associé à chaque flux ou transformation dans votre fluxpositionest la position ordinale des colonnes dans votre flux de donnéesoriginest la transformation dans laquelle une colonne a trouvé son origine ou a été mise à jour pour la dernière fois
Contenu connexe
- En savoir plus sur le langage d’expression des flux de données de mappage pour les transformations de données
- Utiliser des modèles de colonne dans la transformation de récepteur et la transformation de sélection avec un mappage basé sur les règles