Transformation de jointure dans le flux de données de mappage
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Les flux de données sont disponibles à la fois dans les pipelines Azure Data Factory et Azure Synapse. Cet article s’applique aux flux de données de mappage. Si vous débutez dans le domaine des transformations, consultez l’article d’introduction Transformer des données avec un flux de données de mappage.
Utilisez la transformation de jointure pour combiner des données de deux sources ou flux dans un flux de données de mappage. Le flux de sortie inclut toutes les colonnes des deux sources correspondantes en fonction d’une condition de jointure.
Types de jointure
Le mappage de flux de données prend actuellement en charge cinq types de jointures différents.
Jointure interne (Inner)
La jointure interne génère uniquement les lignes possédant des valeurs correspondantes dans les deux tables.
Externe gauche
La jointure externe gauche renvoie toutes les lignes du flux de données gauche et les enregistrements correspondants du flux de droite. Si une ligne du flux de gauche n’a pas de correspondance, les colonnes de sortie du flux de droite ont pour valeur NULL. La sortie contient les lignes renvoyées par la jointure interne ainsi que les lignes sans correspondance du flux de gauche.
Notes
Le moteur Spark utilisé par les flux de données échouera parfois en raison d’éventuels produits cartésiens dans vos conditions de jointure. Le cas échéant, vous pouvez basculer vers une jointure croisée personnalisée et entrer manuellement votre condition de jointure. Cela peut entraîner un ralentissement des performances dans vos flux de données, car le moteur d’exécution peut avoir besoin de calculer toutes les lignes des deux côtés de la relation, puis filtrer les lignes.
Externe droite
La jointure externe droite retourne toutes les lignes du flux de données de droite et les enregistrements correspondants du flux de données de gauche. Si une ligne du flux de droite n’a pas de correspondance, les colonnes de sortie du flux de gauche ont pour valeur NULL. La sortie contient les lignes renvoyées par la jointure interne ainsi que les lignes sans correspondance du flux de droite.
Externe entière
La jointure externe complète génère toutes les colonnes et les lignes des deux côtés avec des valeurs NULL pour les colonnes sans correspondance.
Jointure croisée personnalisée
La jointure croisée génère le produit croisé des deux flux en fonction d’une condition. Si vous utilisez une condition qui n’est pas une égalité, spécifiez une expression personnalisée comme condition de jointure croisée. Le flux de sortie correspond à toutes les lignes qui répondent à la condition de jointure.
Vous pouvez utiliser ce type de jointure pour les jointures différentes et les conditions de OR.
Si vous souhaitez générer explicitement un produit cartésien complet, utilisez la transformation de colonne dérivée dans chacun des deux flux indépendants avant la jointure pour créer une clé synthétique à faire correspondre. Par exemple, créez une colonne dans la colonne dérivée de chaque flux nommé SyntheticKey et affectez-lui la valeur 1. Utilisez ensuite a.SyntheticKey == b.SyntheticKey comme expression de jointure personnalisée.
Notes
Veillez à inclure au moins une colonne de chaque côté de votre relation (gauche et droite) dans une jointure croisée personnalisée. L’exécution de jointures croisées avec des valeurs statiques plutôt que des colonnes de chaque côté entraîne des analyses complètes de l’ensemble du jeu de données, provoquant un fonctionnement médiocre du flux de données.
Jointure approximative
Vous pouvez choisir de joindre en fonction de la logique de jointure approximative au lieu de la correspondance exacte de la valeur de colonne en activant l’option de case à cocher « Utiliser la correspondance approximative ».
- Combiner des parties de texte : utilisez cette option pour rechercher des correspondances en supprimant l’espace entre les mots. Par exemple, Data Factory est mis en correspondance avec DataFactory si cette option est activée.
- Colonne de score de similarité : vous pouvez éventuellement choisir de stocker le score correspondant pour chaque ligne d’une colonne en entrant un nouveau nom de colonne ici pour stocker cette valeur.
- Seuil de similarité : choisissez une valeur comprise entre 60 et 100 sous la forme d’une correspondance de pourcentage entre les valeurs dans les colonnes que vous avez sélectionnées.

Remarque
La correspondance approximative fonctionne actuellement uniquement avec les types de colonnes de chaîne et avec les types internes, externes gauches et de jointure externe entière. Vous devez désactiver l’optimisation de la diffusion lors de l’utilisation de jointures de correspondances approximatives.
Configuration
- Dans la liste déroulante Flux de droite, choisissez le flux de données que vous joignez.
- Sélectionner votre Type de jointure
- Choisissez les colonnes clés pour lesquelles vous souhaitez faire correspondre la condition de jointure. Par défaut, le flux de données recherche l’équivalence entre une colonne d’un flux et une colonne de l’autre flux. Pour effectuer une comparaison à l’aide d’une valeur calculée, pointez sur la liste déroulante de la colonne, puis sélectionnez Colonne calculée.

Jointures différentes
Pour utiliser un opérateur conditionnel tel que « différent de » (!=) ou « supérieur à » (>) dans vos conditions de jointure, modifiez la liste déroulante des opérateurs entre les deux colonnes. Des jointures différentes nécessitent qu’au moins l’un des deux flux soit diffusés en utilisant la diffusion fixe dans l’onglet Optimiser.

Optimisation des performances de jointure
Contrairement à la jointure de fusion dans les outils tels que SSIS, la transformation de jointure n’est pas une opération de jointure de fusion obligatoire. Les clés de jointure ne nécessitent pas de tri. L’opération de jointure se produit en fonction de l’opération de jointure optimale dans Spark : soit la jointure de diffusion, soit la jointure côté mappage.

Dans les transformations de jointure, de recherche et d’existence, si l’un des flux de données ou les deux tiennent dans la mémoire de nœud Worker, vous pouvez optimiser les performances en activant la diffusion. Par défaut, le moteur Spark détermine automatiquement s’il faut diffuser un côté. Pour choisir manuellement le côté à diffuser, sélectionnez Fixe.
Il n’est pas recommandé de désactiver la diffusion à l’aide de l’option Désactivé à moins que vos jointures ne rencontrent des erreurs de délai d’attente.
Jointure réflexive
Pour joindre automatiquement un flux de données à lui-même, associez un alias à un flux existant à l’aide d’une transformation Select. Créez une branche en cliquant sur l’icône plus (+) en regard d’une transformation et en sélectionnant Nouvelle branche. Ajoutez une transformation SELECT pour créer un alias du flux d’origine. Ajoutez une transformation de jointure et choisissez le flux d’origine comme flux de gauche et la transformation SELECT comme flux de droite.

Test des conditions de jointure
Lorsque vous testez les transformations de jointure avec l’aperçu des données en mode débogage, utilisez un jeu de données connues peu volumineux. Lors de l’échantillonnage de lignes à partir d’un jeu de données volumineux, vous ne pouvez pas prédire quelles lignes et quelles clés seront lues dans le cadre du test. Le résultat n’est pas déterministe, ce qui signifie que vos conditions de jointure peuvent ne renvoyer aucun résultat.
Script de flux de données
Syntaxe
<leftStream>, <rightStream>
join(
<conditionalExpression>,
joinType: { 'inner'> | 'outer' | 'left_outer' | 'right_outer' | 'cross' }
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <joinTransformationName>
Exemple de jointure interne
L’exemple ci-dessous illustre une transformation de jointure nommée JoinMatchedData, qui utilise le flux de gauche TripData et le flux de droite TripFare. La condition de jointure est l’expression hack_license == { hack_license} && TripData@medallion == TripFare@medallion && vendor_id == { vendor_id} && pickup_datetime == { pickup_datetime} qui retourne true si les colonnes hack_license, medallion, vendor_id et pickup_datetime de chaque flux correspondent. Le joinType est 'inner'. Nous activons la diffusion uniquement dans le flux de gauche afin que broadcast ait pour valeur 'left'.
Dans l’IU, cette transformation se présente comme dans l’image ci-dessous :
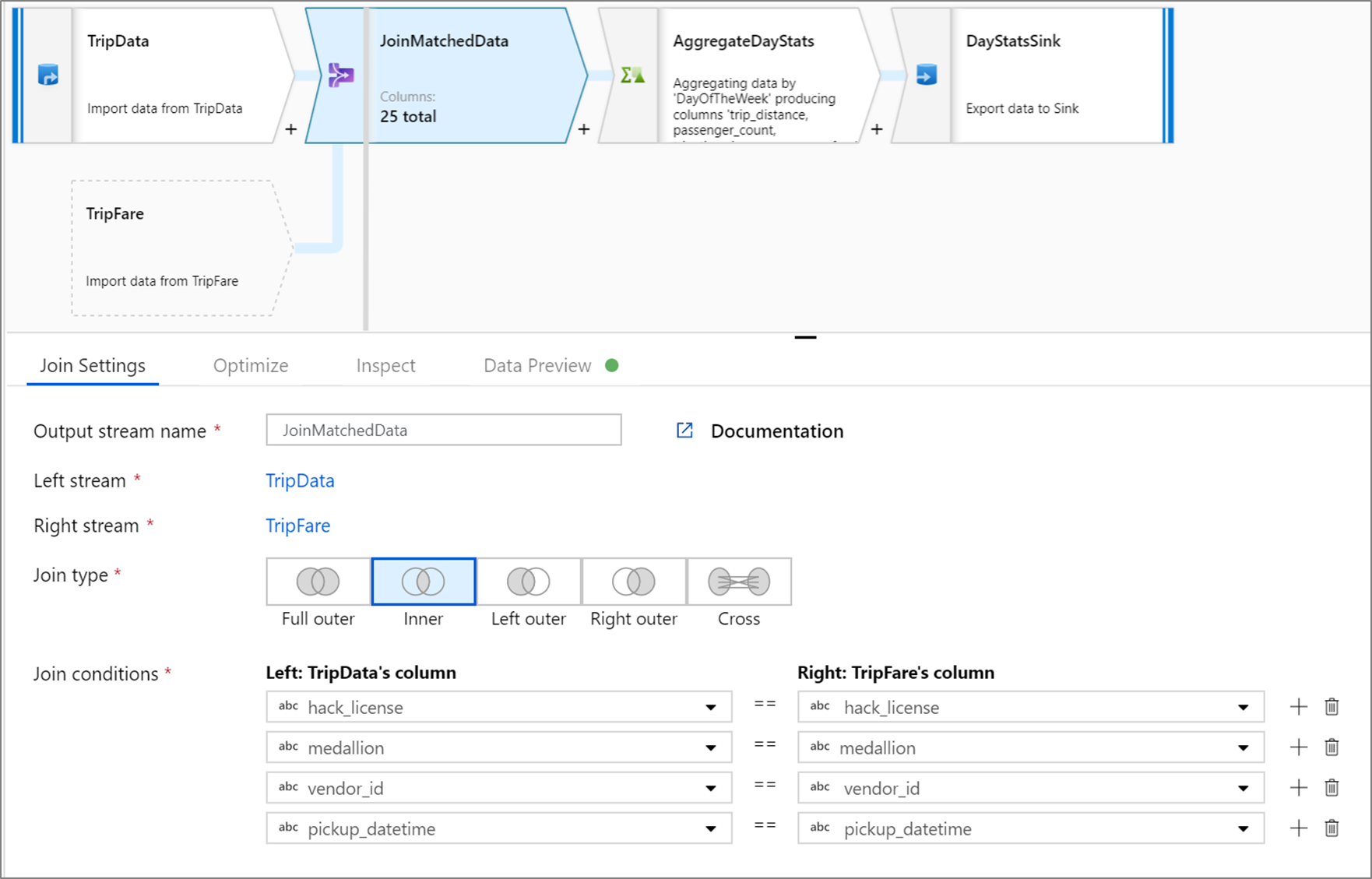
Le script de flux de données pour cette transformation se trouve dans l’extrait de code ci-dessous :
TripData, TripFare
join(
hack_license == { hack_license}
&& TripData@medallion == TripFare@medallion
&& vendor_id == { vendor_id}
&& pickup_datetime == { pickup_datetime},
joinType:'inner',
broadcast: 'left'
)~> JoinMatchedData
Exemple de jointure croisée personnalisée
L’exemple ci-dessous illustre une transformation de jointure nommée JoiningColumns, qui utilise le flux de gauche LeftStream et le flux de droite RightStream. Cette transformation prend deux flux et joint toutes les lignes où la colonne leftstreamcolumn est supérieure à la colonne rightstreamcolumn. Le joinType est cross. La diffusion n’est pas activée broadcast a la valeur 'none'.
Dans l’IU, cette transformation se présente comme dans l’image ci-dessous :

Le script de flux de données pour cette transformation se trouve dans l’extrait de code ci-dessous :
LeftStream, RightStream
join(
leftstreamcolumn > rightstreamcolumn,
joinType:'cross',
broadcast: 'none'
)~> JoiningColumns
Contenu connexe
Après avoir joint les données, créez une colonne dérivée et réceptionnez vos données dans un magasin de données de destination.