Transformer des données à l’aide d’une activité Hadoop Pig dans Azure Data Factory ou Synapse Analytics
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
L’activité HDInsight Pig d’un pipeline Data Factory exécute des requêtes Pig sur votre propre cluster ou cluster à la demande HDInsight. Cet article s'appuie sur l'article Activités de transformation des données qui présente une vue d'ensemble de la transformation des données et les activités de transformation prises en charge.
Pour en savoir plus, avant de lire cet article, consultez l’introduction à Azure Data Factory ou Synapse Analytics, puis suivez le didacticiel Transformer des données.
Ajouter une activité HDInsight Pig à un pipeline avec l’interface utilisateur
Pour utiliser une activité de HDInsight Pig dans un pipeline, procédez comme suit :
Recherchez Pig dans le volet Activités du pipeline, puis faites glisser une activité Pig vers le canevas du pipeline.
Sélectionnez la nouvelle activité Pig sur le canevas si elle n’est pas déjà sélectionnée.
Sélectionnez l’onglet Cluster HDI pour sélectionner ou créer un nouveau service lié à un cluster HDInsight qui sera utilisé pour exécuter l’activité MapReduce.
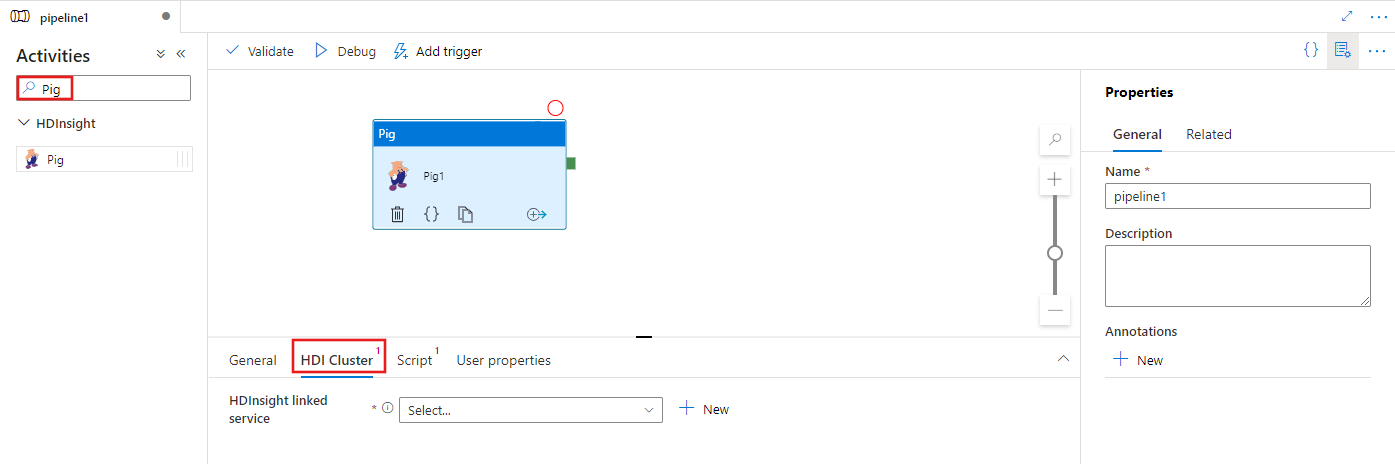
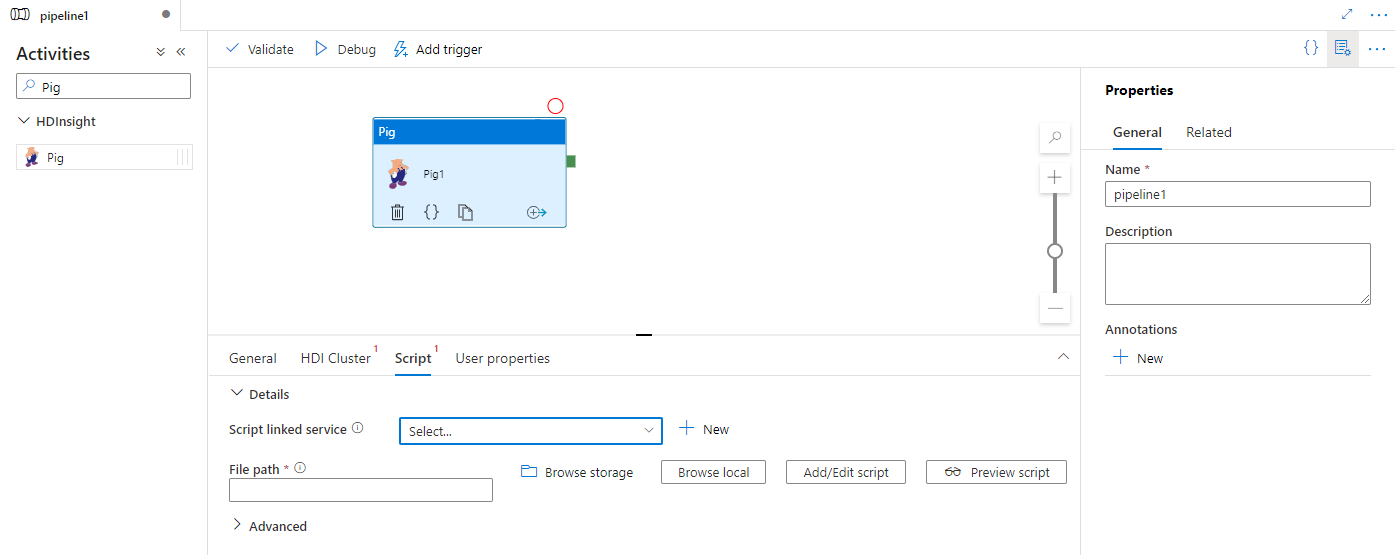
Sélectionnez l’onglet Script pour sélectionner ou créer un service lié à un script à un compte de stockage Azure qui hébergera votre script. Spécifiez un nom de classe à exécuter ici, ainsi qu’un chemin d’accès au fichier dans l’emplacement de stockage. Vous pouvez également configurer des détails avancés, notamment une configuration de débogage, ainsi que des arguments et des paramètres à transmettre au script.
Syntaxe
{
"name": "Pig Activity",
"description": "description",
"type": "HDInsightPig",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"scriptPath": "MyAzureStorage\\PigScripts\\MyPigSript.pig",
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
Détails de la syntaxe
| Propriété | Description | Obligatoire |
|---|---|---|
| name | Nom de l’activité | Oui |
| description | Texte décrivant la raison motivant l’activité. | Non |
| type | Pour l’activité Hive, le type d’activité est HDinsightPig. | Oui |
| linkedServiceName | Référence au cluster HDInsight enregistré en tant que service lié. Pour en savoir plus sur ce service lié, consultez l’article Services liés de calcul. | Oui |
| scriptLinkedService | Référence à un service lié de stockage Azure utilisé pour stocker le script Pig à exécuter. Seuls les services liés Stockage Blob Azure et ADLS Gen2 sont pris en charge ici. Si vous ne spécifiez pas ce service lié, le service lié Stockage Azure défini dans le service lié HDInsight est utilisé. | Non |
| scriptPath | Indiquez le chemin du fichier de script stocké dans le stockage Azure référencé par scriptLinkedService. Le nom de fichier respecte la casse. | Non |
| getDebugInfo | Spécifie quand les fichiers journaux sont copiés vers le stockage Azure utilisé par le cluster HDInsight (ou) spécifié par scriptLinkedService. Valeurs autorisées : None, Always ou Failure. Valeur par défaut : Aucun. | Non |
| arguments | Spécifie un tableau d’arguments pour un travail Hadoop. Les arguments sont passés sous la forme d’arguments de ligne de commande à chaque tâche. | Non |
| defines | Spécifier les paramètres sous forme de paires clé/valeur pour le référencement au sein du script Pig. | Non |
Contenu connexe
Consultez les articles suivants qui expliquent comment transformer des données par d’autres moyens :