Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article explique comment configurer l’accès à des ressources externes et privées depuis les points de terminaison de déploiement de modèles. Model Serving prend en charge les variables d’environnement en texte brut et les variables d’environnement basées sur les secrets à l’aide des secrets Databricks.
Spécifications
Pour les variables d’environnement basées sur des secrets :
- Le créateur du point de terminaison doit disposer de l’accès READ aux secrets Databricks référencés dans les configurations.
- Vous devez stocker les informations d’identification telles que votre clé API ou d’autres jetons en tant que secret Databricks.
Ajouter des variables d’environnement en texte brut
Utilisez des variables d’environnement de texte brut pour définir des variables qui n’ont pas besoin d’être masquées. Vous pouvez définir des variables dans l’interface utilisateur de service, l’API REST ou le Kit de développement logiciel (SDK) lorsque vous créez ou mettez à jour un point de terminaison.
Interface utilisateur de mise en service
Dans l’interface utilisateur Service, vous pouvez ajouter une variable d’environnement dans Configurations avancées :
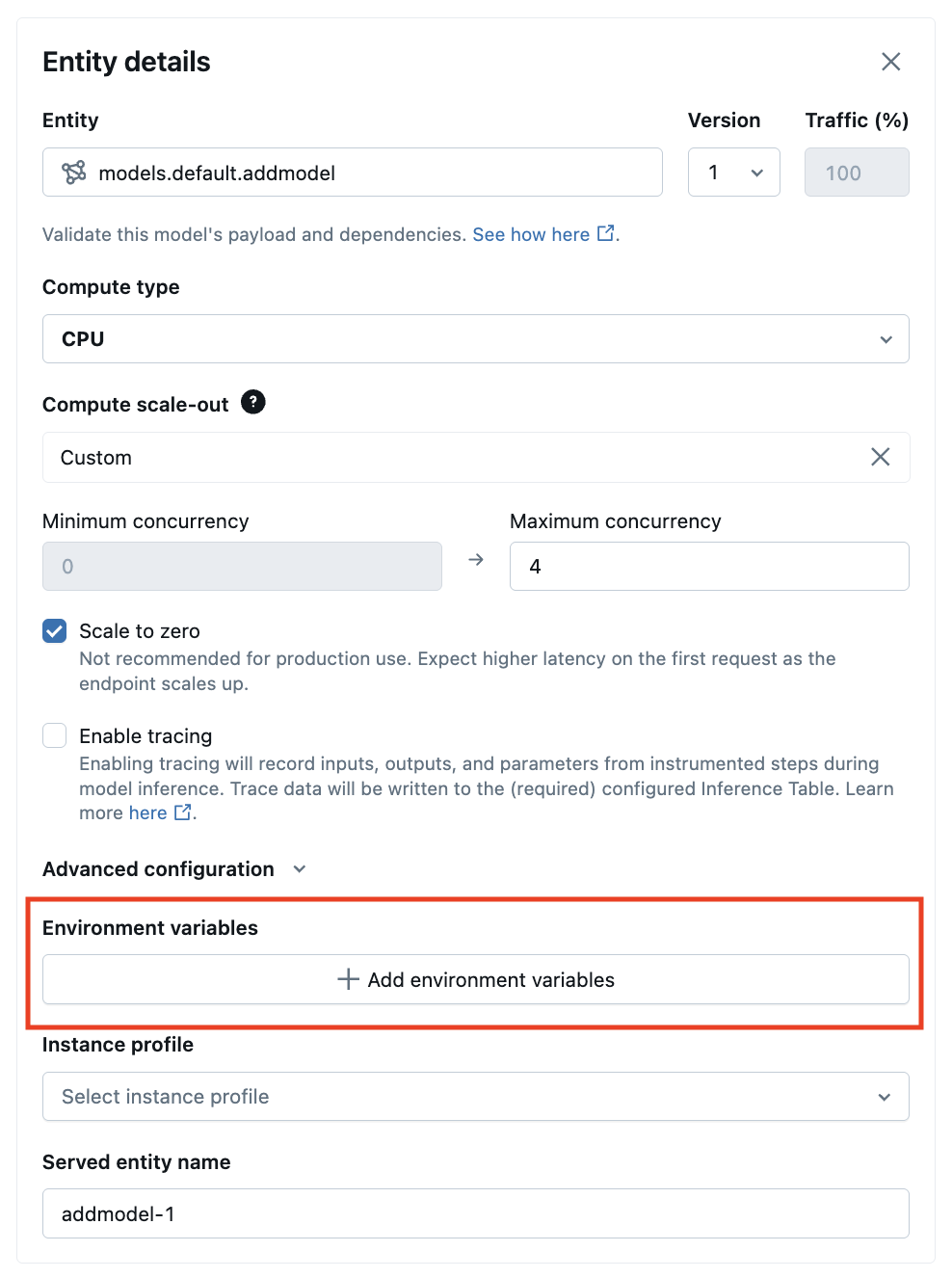
REST API
Voici un exemple de création d’un point de terminaison de service utilisant l’API REST POST /api/2.0/serving-endpoints et le champ environment_vars pour configurer votre variable d’environnement.
{
"name": "endpoint-name",
"config": {
"served_entities": [
{
"entity_name": "model-name",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": "true",
"environment_vars": {
"TEXT_ENV_VAR_NAME": "plain-text-env-value"
}
}
]
}
}
WorkspaceClient SDK
Voici un exemple de création d’un point de terminaison de service à l’aide du Kit de développement logiciel (SDK) WorkspaceClient et du environment_vars champ pour configurer votre variable d’environnement.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ServedEntityInput, EndpointCoreConfigInput, ServingModelWorkloadType
w = WorkspaceClient()
endpoint_name = "example-add-model"
model_name = "main.default.addmodel"
w.serving_endpoints.create_and_wait(
name=endpoint_name,
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name = model_name,
entity_version = "2",
workload_type = ServingModelWorkloadType("CPU"),
workload_size = "Small",
scale_to_zero_enabled = False,
environment_vars = {
"MY_ENV_VAR": "value_to_be_injected",
"ADS_TOKEN": "abcdefg-1234"
}
)
]
)
)
Kit de développement logiciel (SDK) de déploiements MLflow
Voici un exemple de création d’un point de terminaison de service à l’aide du Kit de développement logiciel (SDK) Mlflow Deployments et du environment_vars champ pour configurer votre variable d’environnement.
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": True,
"environment_vars": {
"MY_ENV_VAR": "value_to_be_injected",
"ADS_TOKEN": "abcdefg-1234"
}
}
]
}
)
Journaliser les DataFrames de recherche de fonctionnalités dans les tables d'inférence
Si vous avez activé les tables d’inférence sur votre point de terminaison, vous pouvez enregistrer votre trame de données de recherche automatique de caractéristiques sur cette table d’inférence à l’aide de ENABLE_FEATURE_TRACING. Cela nécessite MLflow 2.14.0 ou version ultérieure.
Définissez ENABLE_FEATURE_TRACING comme variable d’environnement dans l’interface utilisateur de service, l’API REST ou le SDK lorsque vous créez ou mettez à jour un point de terminaison.
Interface utilisateur de mise en service
- Dans configurations avancées, sélectionnez ** + Ajouter des variables d’environnement**.
- Tapez le nom de l’environnement
ENABLE_FEATURE_TRACING. - Dans le champ à droite, tapez
true.
REST API
Voici un exemple de création d’un point de terminaison de service à l’aide de l’API POST /api/2.0/serving-endpoints REST et du environment_vars champ pour configurer la variable d’environnement ENABLE_FEATURE_TRACING .
{
"name": "endpoint-name",
"config": {
"served_entities": [
{
"entity_name": "model-name",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": "true",
"environment_vars": {
"ENABLE_FEATURE_TRACING": "true"
}
}
]
}
}
WorkspaceClient SDK
Voici un exemple de création d’un point de terminaison de service à l’aide du Kit de développement logiciel (SDK) WorkspaceClient et du environment_vars champ pour configurer la variable d’environnement ENABLE_FEATURE_TRACING .
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ServedEntityInput, EndpointCoreConfigInput, ServingModelWorkloadType
w = WorkspaceClient()
endpoint_name = "example-add-model"
model_name = "main.default.addmodel"
w.serving_endpoints.create_and_wait(
name=endpoint_name,
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name = model_name,
entity_version = "2",
workload_type = ServingModelWorkloadType("CPU"),
workload_size = "Small",
scale_to_zero_enabled = False,
environment_vars = {
"ENABLE_FEATURE_TRACING": "true"
}
)
]
)
)
Kit de développement logiciel (SDK) de déploiements MLflow
Voici un exemple de création d’un point de terminaison de service à l’aide du Kit de développement logiciel (SDK) Mlflow Deployments et du environment_vars champ pour configurer la variable d’environnement ENABLE_FEATURE_TRACING .
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": True,
"environment_vars": {
"ENABLE_FEATURE_TRACING": "true"
}
}
]
}
)
Ajouter des variables d’environnement basées sur des secrets
Vous pouvez stocker de façon sécurisée des informations d’identification en utilisant des secrets Databricks et référencer ces secrets dans le service de modèle en utilisant des variables d’environnement basées sur des secrets. Ceci permet de récupérer les informations d’identification auprès des points de terminaison de service de modèle au moment du service.
Par exemple, vous pouvez transmettre des informations d'identification pour appeler OpenAI et d'autres points de terminaison de modèle externes ou accéder à des emplacements de stockage de données externes directement à partir du service de modèle.
Databricks recommande cette fonctionnalité pour déployer les versions de modèle OpenAI et LangChain MLflow pour le service. Il s'applique également à d'autres modèles SaaS nécessitant des informations d'identification, étant entendu que le modèle d'accès est basé sur l'utilisation de variables d'environnement et de clés et jetons API.
Étape 1 : Créer un périmètre de secrets
Lors de la mise en service du modèle, les secrets sont récupérés depuis Databricks Secrets à l’aide de la portée de secret et de la clé. Ceux-ci sont attribués aux noms de variables d'environnement secrètes qui peuvent être utilisées dans le modèle.
Tout d’abord, créez une portée de secret. Consultez Gérer les portées des secrets.
Voici les commandes CLI :
databricks secrets create-scope my_secret_scope
Vous pouvez ensuite ajouter votre secret à la portée et à la clé du secret souhaité, comme indiqué ci-dessous :
databricks secrets put-secret my_secret_scope my_secret_key
Les informations secrètes et le nom de la variable d'environnement peuvent ensuite être transmises à la configuration de votre point de terminaison lors de la création du point de terminaison ou sous forme de mise à jour de la configuration d'un point de terminaison existant.
Étape 2 : Ajouter des portées de secrets à la configuration du point de terminaison
Vous pouvez ajouter la portée du secret à une variable d’environnement, puis transmettre cette variable à votre point de terminaison lors de la création du point de terminaison ou des mises à jour de sa configuration. Consultez Créer un modèle personnalisé servant des points de terminaison.
Interface utilisateur de mise en service
Dans l’interface utilisateur Service, vous pouvez ajouter une variable d’environnement dans Configurations avancées. La variable d’environnement basée sur des secrets doit être fournie en utilisant la syntaxe suivante : {{secrets/scope/key}}. Sinon, la variable d’environnement est considérée comme une variable d’environnement en texte brut.
REST API
Voici un exemple de création d’un point de terminaison de service en utilisant l’API REST. Lors de la création du point de terminaison de diffusion du modèle et des mises à jour de la configuration, vous pouvez fournir une liste de spécifications de variables d'environnement secrètes pour chaque modèle servi dans le champ d'utilisation de la requête d'API environment_vars.
L'exemple suivant attribue la valeur du secret créé dans le code fourni à la variable d'environnement OPENAI_API_KEY.
{
"name": "endpoint-name",
"config": {
"served_entities": [
{
"entity_name": "model-name",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": "true",
"environment_vars": {
"OPENAI_API_KEY": "{{secrets/my_secret_scope/my_secret_key}}"
}
}
]
}
}
Vous pouvez également mettre à jour un point de terminaison de service, comme dans l’PUT /api/2.0/serving-endpoints/{name}/config exemple d’API REST suivant :
{
"served_entities": [
{
"entity_name": "model-name",
"entity_version": "2",
"workload_size": "Small",
"scale_to_zero_enabled": "true",
"environment_vars": {
"OPENAI_API_KEY": "{{secrets/my_secret_scope/my_secret_key}}"
}
}
]
}
WorkspaceClient SDK
Voici un exemple de création d’un point de terminaison de service à l’aide du Kit de développement logiciel (SDK) WorkspaceClient. Lors de la création du point de terminaison de diffusion du modèle et des mises à jour de la configuration, vous pouvez fournir une liste de spécifications de variables d'environnement secrètes pour chaque modèle servi dans le champ d'utilisation de la requête d'API environment_vars.
L'exemple suivant attribue la valeur du secret créé dans le code fourni à la variable d'environnement OPENAI_API_KEY.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ServedEntityInput, EndpointCoreConfigInput, ServingModelWorkloadType
w = WorkspaceClient()
endpoint_name = "example-add-model"
model_name = "main.default.addmodel"
w.serving_endpoints.create_and_wait(
name=endpoint_name,
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name = model_name,
entity_version = "2",
workload_type = ServingModelWorkloadType("CPU"),
workload_size = "Small",
scale_to_zero_enabled = False,
environment_vars = {
"OPENAI_API_KEY": "{{secrets/my_secret_scope/my_secret_key}}"
}
)
]
)
)
Kit de développement logiciel (SDK) de déploiements MLflow
Voici un exemple de création d’un point de terminaison de service à l’aide du Kit de développement logiciel (SDK) Mlflow Deployments. Lors de la création du point de terminaison de diffusion du modèle et des mises à jour de la configuration, vous pouvez fournir une liste de spécifications de variables d'environnement secrètes pour chaque modèle servi dans le champ d'utilisation de la requête d'API environment_vars.
L'exemple suivant attribue la valeur du secret créé dans le code fourni à la variable d'environnement OPENAI_API_KEY.
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": True,
"environment_vars": {
"OPENAI_API_KEY": "{{secrets/my_secret_scope/my_secret_key}}"
}
}
]
}
)
Une fois le point de terminaison créé ou mis à jour, le service de modèles récupère automatiquement la clé secrète dans le périmètre de secrets Databricks et renseigne la variable d’environnement que votre code d’inférence de modèle peut utiliser.
Exemple de Notebook
Consultez le notebook suivant pour obtenir un exemple de configuration d'une clé API OpenAI pour une chaîne d'assurance qualité de récupération LangChain déployée derrière le modèle servant des points de terminaison avec des variables d'environnement basées sur des secrets.