Utilisation d’Apache Kafka® sur HDInsight avec Apache Flink® sur HDInsight sur AKS
Important
Azure HDInsight sur AKS a été mis hors service le 31 janvier 2025. En savoir plus avec cette annonce.
Vous devez migrer vos charges de travail vers Microsoft Fabric ou un produit Azure équivalent pour éviter l’arrêt brusque de vos charges de travail.
Important
Cette fonctionnalité est actuellement en préversion. Les Conditions d’utilisation supplémentaires pour les préversions Microsoft Azure incluent des termes juridiques supplémentaires qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou qui ne sont pas encore publiées en disponibilité générale. Pour plus d’informations sur cette préversion spécifique, consultez les informations sur la préversion d'Azure HDInsight sur AKS . Pour des questions ou des suggestions de fonctionnalités, envoyez une demande sur AskHDInsight avec les détails et suivez-nous pour plus de mises à jour sur Communauté Azure HDInsight.
Un cas d’usage bien connu pour Apache Flink est l’analytique de flux. Le choix populaire par de nombreux utilisateurs d’utiliser les flux de données, qui sont ingérés à l’aide d’Apache Kafka. Les installations classiques de Flink et Kafka commencent par l'envoi de flux d'événements à Kafka, qui peuvent être consommés par les tâches Flink.
Cet exemple utilise HDInsight sur des clusters AKS exécutant Flink 1.17.0 pour traiter des flux de données consommés et produits par un sujet Kafka.
Note
FlinkKafkaConsumer est déconseillé et sera supprimé avec Flink 1.17, utilisez KafkaSource à la place. FlinkKafkaProducer est déconseillé et sera supprimé avec Flink 1.15, utilisez KafkaSink à la place.
Conditions préalables
Kafka et Flink doivent se trouver dans le même réseau virtuel ou il doit y avoir un peering de réseaux virtuels entre les deux clusters.
Créer un cluster Kafka dans le même réseau virtuel. Vous pouvez choisir Kafka 3.2 ou 2.4 sur HDInsight en fonction de votre utilisation actuelle.
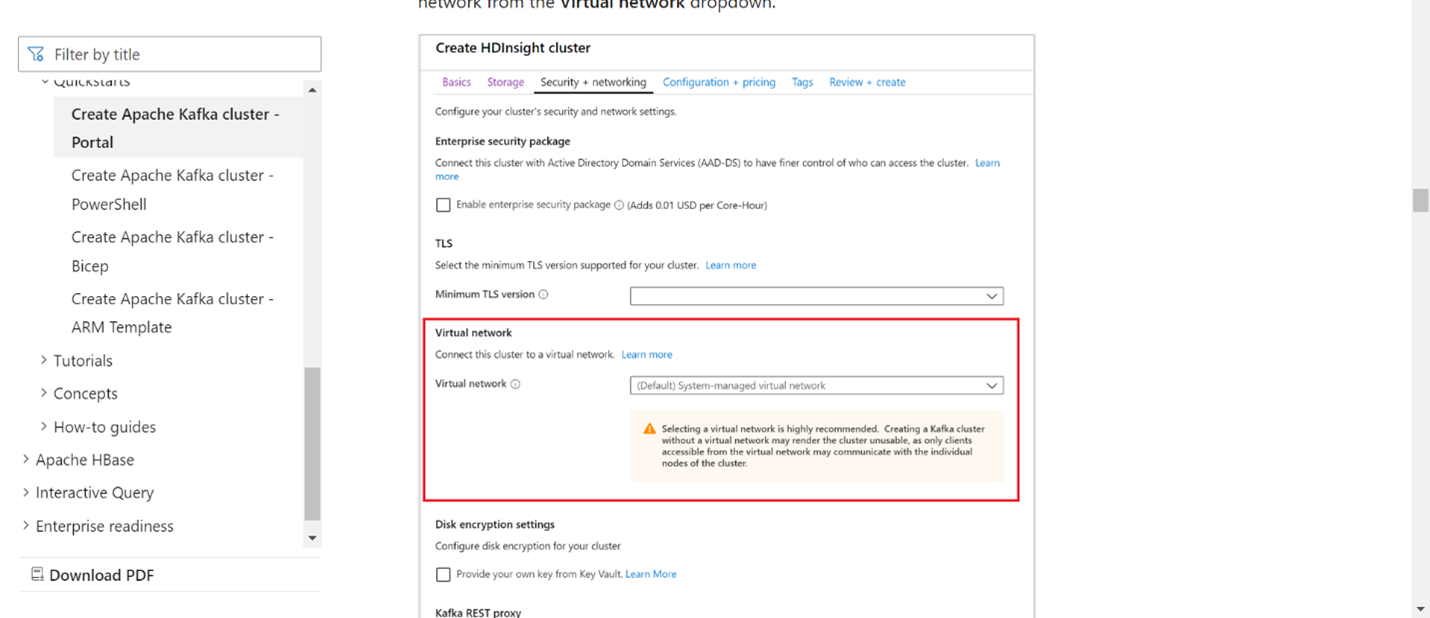
Ajoutez les détails du réseau virtuel dans la section du réseau virtuel.
Créez un HDInsight sur un cluster AKS pool avec le même VNet.
Créez un cluster Flink dans le pool de clusters créé.

Connecteur Apache Kafka
Flink fournit un Connecteur Apache Kafka pour lire des données et écrire des données dans des rubriques Kafka avec exactement une seule garantie.
Dépendance Maven
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.0</version>
</dependency>
Génération d’un récepteur Kafka
Le KafkaSink fournit une classe 'Builder' permettant de construire une instance de KafkaSink. Nous utilisons le même pour construire notre puits et l'utiliser avec le cluster Flink fonctionnant sur HDInsight sur AKS
SinKafkaToKafka.java
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SinKafkaToKafka {
public static void main(String[] args) throws Exception {
// 1. get stream execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. read kafka message as stream input, update your broker IPs below
String brokers = "X.X.X.X:9092,X.X.X.X:9092,X.X.X.X:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("clicks")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3. transformation:
// https://www.taobao.com,1000 --->
// Event{user: "Tim",url: "https://www.taobao.com",timestamp: 1970-01-01 00:00:01.0}
SingleOutputStreamOperator<String> result = stream.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim())).toString();
}
});
// 4. sink click into another kafka events topic
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(brokers)
.setProperty("transaction.timeout.ms","900000")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("events")
.setValueSerializationSchema(new SimpleStringSchema())
.build())
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.build();
result.sinkTo(sink);
// 5. execute the stream
env.execute("kafka Sink to other topic");
}
}
Écriture d’un programme Java Event.java
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user,String url,Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString(){
return "Event{" +
"user: \"" + user + "\"" +
",url: \"" + url + "\"" +
",timestamp: " + new Timestamp(timestamp) +
"}";
}
}
Empaqueter le fichier jar et envoyer le travail à Flink
Sur Webssh, chargez le fichier jar et envoyez le fichier jar

Sur l’interface utilisateur du tableau de bord Flink

Produire la rubrique - clics sur Kafka

Consommer le sujet - événements sur Kafka

Référence
- connecteur Apache Kafka
- Apache, Apache Kafka, Kafka, Apache Flink, Flink et les noms de projet open source associés sont marques déposées de la Apache Software Foundation (ASF).