Utiliser la vue Apache Ambari Hive avec Apache Hadoop dans HDInsight
Découvrez comment exécuter des requêtes Hive avec la vue Apache Ambari Hive. L’affichage Hive vous permet de créer, d’optimiser et d’exécuter des requêtes Hive à partir du navigateur web.
Prérequis
Un cluster Hadoop sur HDInsight. Consultez Bien démarrer avec HDInsight sur Linux.
Exécution d'une tâche Hive
Dans le Portail Azure, sélectionnez votre cluster. Pour obtenir des instructions, consultez la page Énumération et affichage des clusters. Le cluster est ouvert dans un nouvel affichage du portail.
Dans Tableaux de bord du cluster, sélectionnez Vues Ambari. Lorsque vous êtes invité à vous authentifier, utilisez le nom de compte et le mot de passe de connexion de cluster (
adminpar défaut) que vous avez fournis lors de la création du cluster. Vous pouvez également accéder àhttps://CLUSTERNAME.azurehdinsight.net/#/main/viewsdans votre navigateur, oùCLUSTERNAMEest le nom de votre cluster.Dans la liste des vues, sélectionnez Affichage Hive.
L’affiche Hive est similaire à ceci :
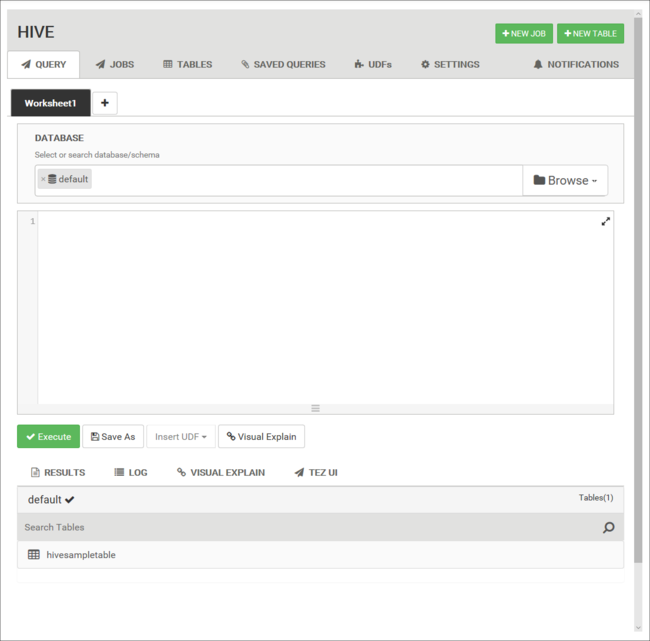
Dans l’onglet Requête , collez les instructions HiveQL suivantes dans la feuille de calcul :
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS loglevel, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' GROUP BY t4;Ces instructions effectuent les opérations suivantes :
. Description DROP TABLE Supprime la table et le fichier de données, si la table existe déjà. CREATE EXTERNAL TABLE Crée une nouvelle table « externe » dans Hive. Les tables externes stockent uniquement la définition de table dans Hive. Les données restent à l'emplacement d'origine. ROW FORMAT Montre la mise en forme des données. Dans ce cas, les champs de chaque journal sont séparés par un espace. STORED AS TEXTFILE LOCATION Montre où sont stockées les données, et qu’elles sont stockées sous forme de texte. SELECT Sélectionne toutes les lignes où la colonne t4 contient la valeur [ERROR]. Important
Conservez la sélection Base de données par défaut. Les exemples de ce document utilisent la base de données par défaut incluse avec HDInsight.
Pour démarrer la requête, sélectionnez Exécuter au-dessous de la feuille de calcul. Ce bouton devient orange et le texte affiche Stop (Arrêter).
Lorsque la requête est terminée, l’onglet Results (Résultats) affiche les résultats de l’opération. Le texte suivant est le résultat de la requête :
loglevel count [ERROR] 3Vous pouvez utiliser l’onglet JOURNAL pour afficher les informations de journalisation que le travail a créées.
Conseil
Téléchargez ou enregistrez les résultats de la boîte de dialogue à liste déroulante Actions sous l’onglet Résultats.
Explications visuelles
Pour afficher une visualisation du plan de requête, sélectionnez l’onglet Explications visuelles sous la feuille de calcul.
La vue Explications visuelles de la requête peut être utile pour comprendre le flux des requêtes complexes.
Interface utilisateur Tez
Sélectionnez l’onglet Tez UI (IU Tez) au-dessous de la feuille de calcul afin d’afficher l’interface utilisateur Tez pour la requête.
Important
Tez n’est pas utilisé pour résoudre toutes les requêtes. Vous pouvez résoudre de nombreuses requêtes sans utiliser Tez.
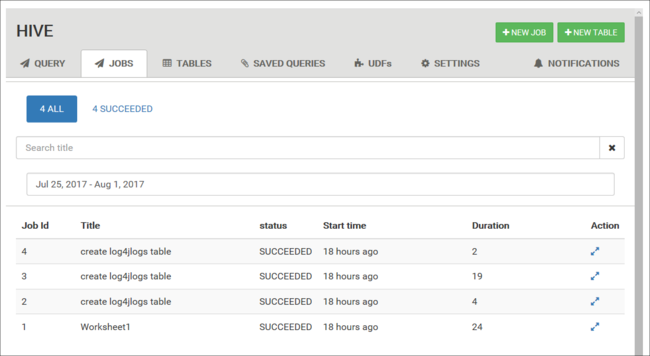
Afficher l’historique des travaux
L’onglet Travaux affiche un historique des requêtes Hive.
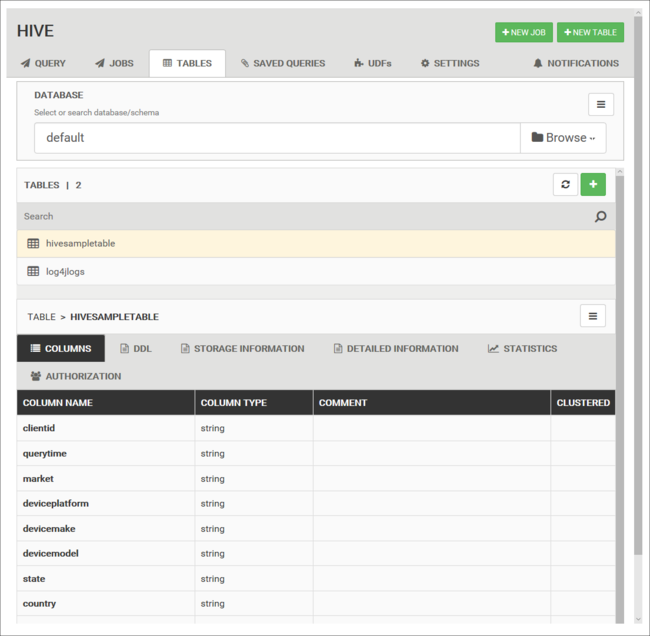
Tables de base de données
Vous pouvez utiliser l’onglet Tables onglet pour travailler avec des tables dans une base de données Hive.
Requêtes enregistrées
À partir de l’onglet Query (Requête), vous pouvez éventuellement enregistrer des requêtes. Après avoir enregistré une requête, vous pouvez la réutiliser à partir de l’onglet Saved Queries (Requêtes enregistrées).
Conseil
Les requêtes enregistrées sont stockées dans le stockage en cluster par défaut. Vous pouvez rechercher les requêtes enregistrées sous le chemin /user/<username>/hive/scripts. Ces fichiers sont stockés en tant que fichiers .hql en texte brut.
Si vous supprimez le cluster, tout en conservant le stockage, vous pouvez employer un utilitaire tel que l’Explorateur Stockage Azure ou l’Explorateur de stockage Data Lake (à partir du portail Azure) pour récupérer les requêtes.
Fonctions définies par l’utilisateur
Vous pouvez étendre Hive par l’intermédiaire de fonctions définies par l’utilisateur. Utilisez une fonction définie par l’utilisateur pour implémenter une fonctionnalité ou une logique qui n’est pas facilement modélisée en HiveQL.
Déclarez et enregistrez un ensemble de fonctions définies par l’utilisateur en utilisant l’onglet UDF en haut de l’affichage Hive. Ces UDF peuvent être utilisés avec les l’éditeur de requête.
Un bouton Insérer des UDF apparaît au bas de l’éditeur de requête. Cette entrée affiche une liste déroulante des UDF définies dans l’affichage Hive. La sélection d’une fonction UDF ajoute des instructions HiveQL à votre requête pour activer l’UDF.
Par exemple, si vous avez défini une fonction UDF avec les propriétés suivantes :
Nom de ressource : myudfs
Chemin d’accès à la ressource : /myudfs.jar
Nom de la fonction UDF : myawesomeudf
Nom de la classe UDF : com.myudfs.Awesome
L’utilisation du bouton Insert udfs (Insérer des fonctions définies par l’utilisateur) affiche une entrée nommée myudfs avec une autre liste déroulante pour chaque fonction définie par l’utilisateur qui est paramétrée pour cette ressource. Dans le cas présent, il s’agit de myawesomeudf. La sélection de cette entrée ajoute le code suivant au début de la requête :
add jar /myudfs.jar;
create temporary function myawesomeudf as 'com.myudfs.Awesome';
Vous pouvez ensuite utiliser la fonction UDF dans votre requête. Par exemple : SELECT myawesomeudf(name) FROM people;.
Pour plus d’informations sur l’utilisation des fonctions définies par l’utilisateur avec Hive sur HDInsight, consultez les articles suivants :
- Utilisation de Python UDF avec Apache Hive et Apache Pig dans HDInsight
- Utiliser une fonction UDF Java avec Apache Hive dans HDInsight
Paramètres Hive
Vous pouvez modifier différents paramètres Hive, par exemple pour passer du moteur d’exécution Tez (par défaut) à MapReduce pour Hive.
Étapes suivantes
Pour obtenir des informations générales sur Hive dans HDInsight :