Planification de la capacité pour les clusters HDInsight
Avant de déployer un cluster HDInsight, planifiez la capacité de cluster souhaitée en déterminant les performances et la mise à l’échelle requises. Cette planification aide à optimiser les coûts et accroît la facilité d’utilisation. Certaines décisions relatives à la capacité du cluster ne peuvent pas être changées après le déploiement. Si les paramètres de performances changent, vous pouvez démonter et recréer un cluster sans perdre les données stockées.
Les principales questions à se poser pour la planification de la capacité sont les suivantes :
- Dans quelle région géographique devez-vous déployer votre cluster ?
- De quelle quantité de stockage avez-vous besoin ?
- Quel type de cluster devez-vous déployer ?
- Quels taille et type de machine virtuelle vos nœuds de cluster doivent-ils utiliser ?
- Combien de nœuds worker votre cluster doit-il avoir ?
Choisir une région Azure
La région Azure détermine où votre cluster est physiquement configuré. Pour réduire la latence de lecture et d’écriture, le cluster doit être proche de vos données.
HDInsight est disponible dans de nombreuses régions Azure. Pour trouver la région la plus proche, consultez Disponibilité des produits par région.
Choisir la taille et l’emplacement du stockage
Emplacement du stockage par défaut
Le stockage par défaut (soit un compte Stockage Azure, soit Azure Data Lake Storage) doit être au même emplacement que votre cluster. Le stockage Azure est disponible à tous les emplacements. Data Lake Storage est disponible dans certaines régions. Consultez la disponibilité de Data Lake Storage actuelle.
Emplacement des données existantes
Si vous souhaitez utiliser un compte de stockage ou un Azure Data Lake Storage existants comme espace de stockage par défaut pour votre cluster, vous devez déployer votre cluster au même emplacement.
Taille de stockage
Sur un cluster déployé, vous pouvez joindre des comptes de stockage Azure supplémentaires ou accéder à un autre Data Lake Storage. Tous vos comptes de stockage doivent résider dans le même emplacement que votre cluster. Un Data Lake Storage peut se trouver dans un emplacement différent, mais cela risque d’entraîner une latence.
Le Stockage Azure présente certaines limites de capacité, tandis que Data Lake Storage est quasiment illimité. Un cluster peut accéder à une combinaison de différents comptes de stockage. Voici quelques exemples classiques :
- Quand la quantité de données est susceptible de dépasser la capacité de stockage d’un conteneur de stockage blob.
- Quand le taux d’accès au conteneur blob peut dépasser le seuil où la limitation se produit.
- Quand vous souhaitez rendre accessibles au cluster des données déjà chargées dans un conteneur blob.
- Quand vous souhaitez isoler différentes parties du stockage pour des raisons de sécurité ou pour simplifier l’administration.
Pour de meilleures performances, utilisez un seul conteneur par compte de stockage.
Choisir un type de cluster
Le type de cluster détermine la charge de travail pour l’exécution de laquelle votre cluster HDInsight est configuré. Les types sont les suivants : Apache Hadoop, Apache Storm ou Apache Kafka. Pour obtenir une description détaillée des types de clusters disponibles, consultez Présentation d’Azure HDInsight. Chaque type de cluster a une topologie de déploiement spécifique qui inclut des exigences en matière de taille et de quantité de nœuds.
Choisir la taille et le type de machine virtuelle
Chaque type de cluster a un ensemble de types de nœuds, et chaque type de nœud a des options spécifiques pour la taille et le type de machine virtuelle.
Pour déterminer la taille de cluster optimale pour votre application, vous pouvez évaluer la capacité de cluster et augmenter la taille comme indiqué. Vous pouvez par exemple utiliser une charge de travail simulée ou une requête canary. Exécutez vos charges de travail simulées sur des clusters de tailles différentes. Augmentez progressivement la taille jusqu’à obtenir les performances souhaitées. Vous pouvez insérer régulièrement une requête canary parmi les autres requêtes de production pour voir si le cluster a suffisamment de ressources.
Pour savoir plus en détails comment choisir la bonne famille de machines virtuelles pour votre charge de travail, consultez Sélectionner la taille de machine virtuelle adaptée à votre cluster.
Choix de l’échelle du cluster
L’échelle d’un cluster est déterminée par la quantité de ses nœuds de machine virtuelle. Pour tous les types de clusters, il existe certains types de nœuds qui ont une échelle spécifique et d’autres qui prennent en charge la montée en puissance parallèle. Par exemple, un cluster peut nécessiter exactement trois nœuds Apache ZooKeeper ou deux nœuds principaux. Les nœuds Worker qui effectuent le traitement des données de manière distribuée bénéficient des nœuds Worker supplémentaires.
Selon votre type de cluster, l’augmentation du nombre de nœuds Worker ajoute de la capacité de calcul (comme l’ajout de cœurs). L’ajout de nœuds augmente la mémoire totale requise pour l’ensemble du cluster pour prendre en charge le stockage en mémoire des données en cours de traitement. Comme pour le choix de la taille et du type de machine virtuelle, la sélection de l’échelle de cluster appropriée est généralement effectuée de manière empirique. Utilisez des charges de travail simulées ou des requêtes canary.
Vous pouvez effectuer un scale-out de votre cluster pour répondre aux pics de charge. Ensuite, lorsque ces nœuds supplémentaires ne sont plus nécessaires, opérez une descente en puissance. La fonctionnalité Mise à l’échelle automatique vous permet de mettre automatiquement à l’échelle votre cluster en fonction de mesures et de minutages prédéterminés. Pour plus d’informations sur la mise à l’échelle manuelle de vos clusters, consultez Mettre à l’échelle des clusters HDInsight.
Cycle de vie du cluster
Vous êtes facturé pour la durée de vie d’un cluster. Si vous n’avez besoin de votre cluster qu’à des moments spécifiques, vous pouvez créer des clusters à la demande à l’aide d’Azure Data Factory. Vous pouvez également créer des scripts PowerShell qui approvisionnent et suppriment votre cluster, puis planifier ces scripts à l’aide de Azure Automation.
Notes
Quand un cluster est supprimé, son metastore Hive par défaut est également supprimé. Si vous souhaitez rendre persistant le metastore pour la recréation du cluster suivant, utilisez un magasin de métadonnées externe tel qu’Azure Database ou Apache Oozie.
Isoler les erreurs de travaux de cluster
Parfois, des erreurs peuvent se produire en raison de l’exécution parallèle de plusieurs mappages et réduire les composants sur un cluster à plusieurs nœuds. Pour isoler le problème, essayez le test distribué. Exécutez plusieurs travaux simultanés sur un seul cluster de nœuds Worker. Ensuite, développez cette approche pour exécuter plusieurs travaux simultanément sur des clusters contenant plusieurs nœuds. Pour créer un cluster HDInsight à nœud unique dans Azure, utilisez l’option Custom(size, settings, apps) et la valeur 1 pour Nombre de nœuds Worker dans la section Taille du cluster lors de l’approvisionnement d’un nouveau cluster dans le portail.
Afficher la gestion des quotas pour HDInsight
Affichez un niveau granulaire et une catégorisation du quota d’une machine virtuelle de niveau famille. Affichez le quota actuel et le quota restant pour une région au niveau de la famille de la machine virtuelle.
Notes
Cette fonctionnalité est actuellement disponible sur HDInsight 4.x et 5.x pour la région USA Est EUAP. Les autres régions vont suivre par la suite.
Afficher le quota actuel :
Consultez le quota actuel et le quota restant pour une région au niveau famille de la machine virtuelle.
Depuis le Portail Azure, dans la barre de recherche supérieure, recherchez et sélectionnez Quotas.
Dans la page Quota, sélectionnez Azure HDInsight

Dans la liste déroulante, sélectionnez votre abonnement et votre région


Demander de nouveaux quotas par famille de machines virtuelles et par région
- Cliquez sur la ligne pour laquelle vous souhaitez afficher les détails du quota.
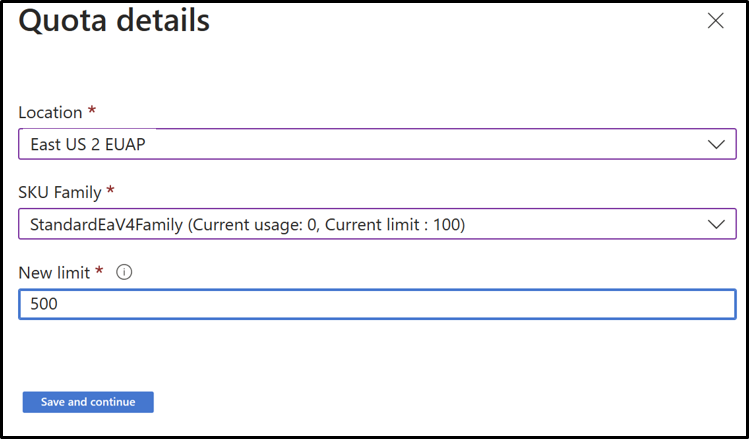




Quotas
Pour plus d’informations sur la gestion des quotas d’abonnement, consultez La demande de quota augmente.
Étapes suivantes
- Configurer des clusters dans HDInsight avec Apache Hadoop, Spark, Kafka et plus encore: En savoir plus sur l’installation et la configuration de clusters dans HDInsight.
- Analyser les performances d’un cluster: En savoir plus sur les principaux scénarios à analyser pour votre cluster HDInsight pouvant affecter sa capacité.