Haute disponibilité (fiabilité) dans Azure Database pour PostgreSQL Serveur flexible
S’APPLIQUE À :  Azure Database pour PostgreSQL : serveur flexible
Azure Database pour PostgreSQL : serveur flexible
Cet article décrit la haute disponibilité dans Azure Database pour PostgreSQL Serveur flexible, qui inclut zones de disponibilité ainsi que la récupération inter-régions et la continuité d’activité. Pour obtenir une vue d’ensemble plus détaillée de la fiabilité dans Azure, consultez Fiabilité Azure.
Azure Database pour PostgreSQL – Serveur flexible offre une prise en charge haute disponibilité en approvisionnant un réplica principal et de secours physiquement distincts dans la même zone de disponibilité (zonal) ou entre les zones de disponibilité (redondant interzone). Ce modèle de haute disponibilité est conçu pour s’assurer que les données commitées ne sont jamais perdues en cas de défaillances. Le modèle est également conçu pour que la base de données ne constitue pas un point de défaillance unique dans votre architecture logicielle. Si vous souhaitez en savoir plus sur la haute disponibilité et la prise en charge des zones de disponibilité, consultez Prise en charge des zones de disponibilité.
Prise en charge des zones de disponibilité
Les zones de disponibilité Azure sont au moins trois groupes physiquement distincts de centres de données dans chaque région Azure. Les centres de données de chaque zone sont équipés d’une infrastructure réseau, de refroidissement et d’alimentation indépendante. En cas de défaillance de zone locale, les zones de disponibilité sont conçues de telle sorte que si une zone est affectée, les services, la capacité et la haute disponibilité de la région sont pris en charge par les deux autres zones.
Les défaillances sont aussi bien des défaillances logicielles et matérielles que des événements de type tremblements de terre, inondations et incendies. La tolérance aux défaillances est obtenue par la redondance et l’isolation logique des services Azure. Pour obtenir des informations détaillées sur les zones de disponibilité dans Azure, consultez Régions et zones de disponibilité.
Les services Azure compatibles avec les zones de disponibilité sont conçus pour fournir le niveau approprié de fiabilité et de flexibilité. Ils peuvent être configurés de deux façons. Un service peut être redondant interzone, avec une réplication automatique entre les zones, ou zonal, avec des instances épinglées à une zone spécifique. Vous pouvez également combiner ces approches. Pour plus d’informations sur l’architecture zonale et redondante interzone, consultez Recommandations relatives à l’utilisation de zones de disponibilité et de régions.
Azure Database pour PostgreSQL Serveur flexible prend en charge les modèles redondants interzones et zonaux pour les configurations de haute disponibilité. Les deux configurations de haute disponibilité permettent une fonctionnalité de basculement automatique sans perte de données pendant les événements planifiés et non planifiés.
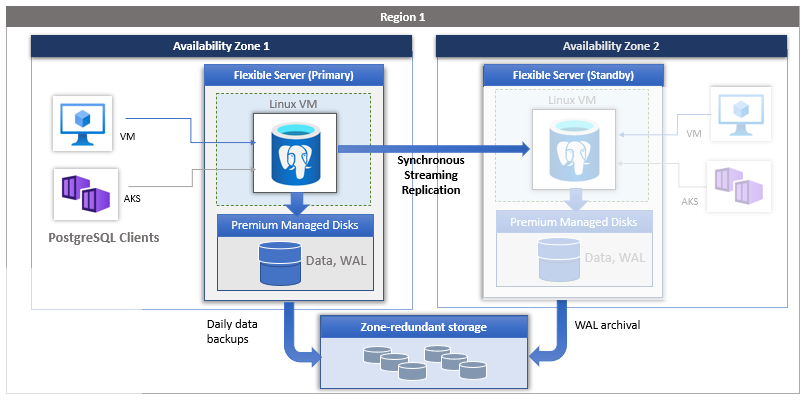
Instances redondantes interzones. La haute disponibilité avec redondance interzone déploie un réplica de secours dans une zone différente avec une fonctionnalité de basculement automatique. La redondance de zone offre le niveau de disponibilité le plus élevé, mais vous oblige à configurer la redondance des applications entre zones. Pour cette raison. choisissez la redondance de zone quand vous voulez une protection en cas de défaillances au niveau des zones de disponibilité et quand la latence entre les zones de disponibilité est acceptable.
Vous pouvez choisir la région et les zones de disponibilité pour le serveur principal et le serveur de secours. Le serveur réplica de secours est approvisionné dans la zone de disponibilité choisie dans la même région, avec une configuration de calcul, de stockage et de réseau similaire à celle du serveur principal. Les fichiers de données et les fichiers journaux des transactions (journaux avec écriture anticipée, WAL) sont stockés sur un stockage localement redondant (LRS) au sein de chaque zone de disponibilité, en stockant automatiquement trois copies des données. Une configuration redondante interzone permet d’isoler physiquement l’ensemble de la pile entre le serveur principal et le serveur de secours.
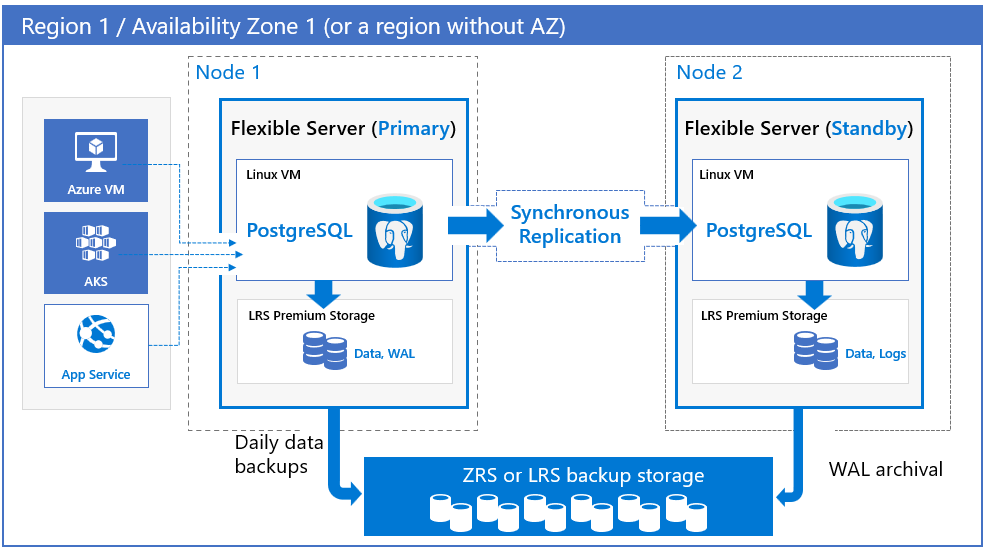
Instances zonales. Choisissez un déploiement zonal quand vous voulez obtenir le niveau de disponibilité le plus élevé au sein d’une même zone de disponibilité avec la latence réseau la plus faible. Vous pouvez choisir la région et la zone de disponibilité pour déployer votre serveur de base de données primaire. Un serveur réplica de secours est automatiquement provisionné et géré dans la même zone de disponibilité, avec une configuration de calcul, de stockage et de réseau similaire à celle du serveur principal. Une configuration zonale protège vos bases de données contre les défaillances au niveau du nœud, et permet de réduire les temps d’arrêt d’applications pendant les temps d’arrêt planifiés et non planifiés. Les données du serveur primaire sont répliquées vers le serveur réplica de secours en mode synchrone. En cas d’interruption du serveur primaire, le serveur est automatiquement basculé vers le réplica de secours.


Remarque
Les modèles de déploiement redondant interzone et zonal se comportent de la même façon d’un point de vue architectural. Les différentes discussions des sections suivantes s’appliquent aux deux, sauf indication contraire.
Prérequis
Redondance de zone :
La redondance interzone est disponible uniquement dans les régions qui prennent en charge les zones de disponibilité.
La redondance de zone n’est pas prise en charge pour :
- Référence SKU Azure Database pour PostgreSQL Serveur unique.
- Niveau de calcul burstable.
- Régions avec disponibilité à zone unique.
Zonal :
- L’option de déploiement zonal est disponible dans toutes les régions Azure où vous pouvez déployer le serveur flexible.
Fonctionnalités de haute disponibilité
Un réplica de secours est déployé dans la même configuration de machine virtuelle que le serveur primaire, incluant les cœurs virtuels, le stockage et les paramètres réseau.
Vous pouvez ajouter la prise en charge des zones de disponibilité pour un serveur de base de données existant.
Vous pouvez supprimer le réplica de secours en désactivant la haute disponibilité.
Vous pouvez choisir les zones de disponibilité pour vos serveurs de base de données primaire et de secours pour la disponibilité redondante interzone.
Les opérations comme l’arrêt, le démarrage et le redémarrage sont effectuées simultanément sur le serveur de base de données principal et sur le serveur de base de données de secours.
Dans les modèles redondants interzones et zonaux, des sauvegardes automatiques sont effectuées périodiquement à partir du serveur de base de données primaire. En même temps, les journaux des transactions sont archivés en continu dans le stockage de sauvegarde à partir du réplica de secours. Si la région prend en charge les zones de disponibilité, les données de sauvegarde sont stockées sur un stockage redondant interzone (ZRS). Dans les régions qui ne prennent pas en charge les zones de disponibilité, les données de sauvegarde sont stockées sur un stockage localement redondant (LRS).
Les clients se connectent toujours au nom d’hôte du serveur de base de données primaire.
Toute modification apportée aux paramètres du serveur sont également appliquées au réplica de secours.
Possibilité de redémarrer le serveur pour intégrer toute modification de paramètre du serveur statique.
Les activités de maintenance périodiques telles que les mises à niveau de version mineures se produisent en premier et, pour réduire les temps d’arrêt, le serveur de secours est promu vers le serveur principal afin que les charges de travail puissent continuer, tandis que les tâches de maintenance sont appliquées sur le nœud restant.
Limitations liées à la haute disponibilité
En raison de la réplication synchrone sur le serveur de secours, en particulier avec une configuration redondante interzone, les applications peuvent faire face à une latence d’écriture et de commit élevée.
Un réplica de secours ne peut pas être utilisé pour des requêtes de lecture.
En fonction de la charge de travail et de l’activité sur le serveur primaire, le processus de basculement pourrait prendre plus de 120 secondes en raison de la récupération nécessaire au niveau du réplica de secours avant que celui-ci puisse être promu.
Le serveur de secours récupère généralement les fichiers WAL à 40 Mo/s. Si votre charge de travail dépasse cette limite, il se peut que la récupération soit plus longue pendant le basculement ou après avoir établi un nouveau serveur de secours.
La configuration des zones de disponibilité entraîne une certaine latence pour les écritures et les validations, alors qu’elle ne produit aucun impact sur la lecture des requêtes. L’impact sur les performances varie en fonction de votre charge de travail. En règle générale, l’impact des écritures et des validations peut être d’environ 20 à 30 %.
Le redémarrage du serveur de base de données primaire redémarre également le réplica de secours.
La configuration d’un serveur de secours supplémentaire n’est pas prise en charge.
La configuration des tâches de gestion lancées par le client ne peut pas être planifiée pendant la fenêtre de maintenance gérée.
Des événements planifiés, tels que la mise à l’échelle du calcul et du stockage, se produisent d’abord sur le serveur de secours, puis sur le serveur primaire. Actuellement, le serveur n’est pas basculé pour ces opérations planifiées.
Si le décodage logique ou la réplication logique sont configurés avec un serveur flexible configuré pour la disponibilité, en cas de basculement vers le serveur de secours, les emplacements de réplication logique ne sont pas copiés sur le serveur de secours. Pour maintenir les emplacements de réplication logique et garantir la cohérence des données après un basculement, il est recommandé d’utiliser l’extension PG Failover Slots. Pour plus d’informations sur l’activation de cette extension, reportez-vous à la documentation.
La configuration des zones de disponibilité entre l’accès privé (réseau virtuel) et l’accès public avec des points de terminaison privés n’est pas prise en charge. Vous devez configurer les zones de disponibilité au sein d’un réseau virtuel (étendu sur plusieurs zones de disponibilité dans une région) ou l’accès public avec des points de terminaison privés.
Les zones de disponibilité sont configurées uniquement dans une seule région. Les zones de disponibilité ne peuvent pas être configurées entre plusieurs régions.
SLA
Le modèle zonal offre une durée de fonctionnement par SLA de 99,95 %.
Le modèle avec redondance de zone offre une durée de fonctionnement par SLA de 99,99 %.
Créer un serveur flexible Azure Database pour PostgreSQL avec une zone de disponibilité activée
Pour savoir comment créer un serveur flexible Azure Database pour PostgreSQL pour la haute disponibilité avec des zones de disponibilité, consultez Démarrage rapide : Cr serveur flexible Azure Database pour PostgreSQL sur le portail Azure.
Redéploiement et migration des zones de disponibilité
Pour découvrir comment activer ou désactiver la configuration de haute disponibilité dans votre serveur flexible dans des modèles de déploiement redondants interzones et zonaux, consultez Gérer la haute disponibilité dans Serveur flexible.
Composants haute disponibilité et flux de travail
Fin de la transaction
Les écritures et validations déclenchées par les transactions d’application sont enregistrées pour la première fois dans WAL sur le serveur primaire. Elles sont ensuite diffusées sur le serveur de secours à l’aide du protocole de streaming Postgres. Une fois les journaux conservés sur le stockage du serveur de secours, le serveur primaire est reconnu comme étant terminé en écriture. Ce n’est qu’après cela que l’application confirme la valider de sa transaction. Cet aller-retour supplémentaire ajoute plus de latence à votre application. Le pourcentage d’impact dépend de l’application. Ce processus d’accusé de réception n’attend pas que les journaux soient appliqués au serveur de secours. Le serveur de secours est définitivement en mode de récupération jusqu’à ce qu’il soit promu.
Contrôle d’intégrité
Le monitoring de l’intégrité du serveur flexible vérifie régulièrement l’intégrité du serveur primaire et du serveur de secours. Après plusieurs tests ping, si le monitoring de l’intégrité détecte qu’un serveur primaire n’est pas accessible, le service lance alors un basculement automatique vers le serveur de secours. L’algorithme de monitoring de l’intégrité est basé sur plusieurs points de données pour éviter toute situation de faux positif.
Modes de basculement
Le serveur flexible prend en charge deux modes de basculement : Basculement planifié et Basculement non planifié. Dans les deux modes, une fois la réplication supprimée, le serveur de secours exécute la récupération avant d’être promu comme serveur primaire et ouvre les lectures/écritures. Avec les entrées DNS automatiques mises à jour avec le nouveau point de terminaison de serveur primaire, les applications peuvent se connecter au serveur à l’aide du même point de terminaison. Un nouveau serveur de secours est établi en arrière-plan, pour que votre application maintienne la connectivité.
État de haute disponibilité
L’intégrité du serveur primaire et du serveur de secours est surveillée en permanence et les actions appropriées sont prises pour résoudre les problèmes, notamment le déclenchement d’un basculement vers le serveur de secours. Le tableau ci-dessous répertorie les états de haute disponibilité possibles :
| État | Description |
|---|---|
| En cours d’initialisation | Le processus de création d’un serveur de secours est en cours. |
| Réplication des données | Une fois le serveur de secours créé, il rattrape le serveur primaire. |
| Healthy | La réplication est dans un état stable et intègre. |
| Basculement | Le serveur de base de données est en cours de basculement vers le serveur de secours. |
| Suppression du serveur de secours | Lors du processus de suppression du serveur de secours. |
| Non activé | La haute disponibilité n’est pas activée. |
Remarque
Vous pouvez activer la haute disponibilité lors de la création du serveur ou ultérieurement. Si vous activez ou désactivez la haute disponibilité pendant la phase post-création, il est recommandé d’effectuer l’opération quand l’activité du serveur primaire est faible.
Opérations à l’état stable
Les applications clientes PostgreSQL sont connectées au serveur primaire à l’aide du nom du serveur BDD. Les lectures d’application sont traitées directement à partir du serveur primaire. En même temps, les commits et les écritures sont confirmés à l’application seulement une fois les données enregistrées à la fois sur le serveur primaire et sur le réplica de secours. En raison de cet aller-retour supplémentaire, les applications peuvent s’attendre à une latence élevée pour les écritures et les commits. Vous pouvez surveiller l’intégrité de la haute disponibilité sur le portail.
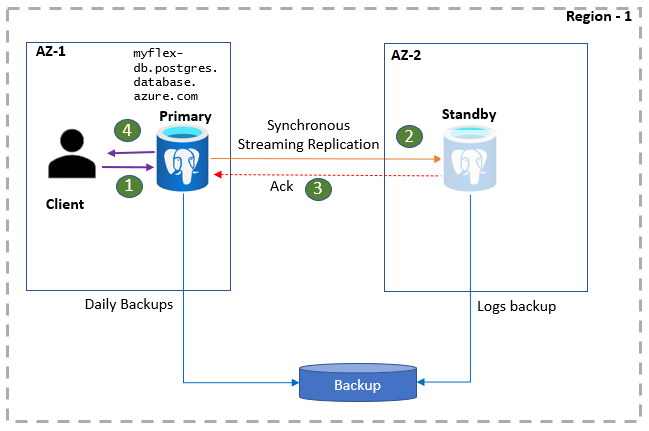
- Les clients se connectent au serveur flexible et effectuent des opérations d’écriture.
- Les modifications sont répliquées sur le site de secours.
- Le serveur primaire reçoit un accusé de réception.
- Les écritures/validations font l’objet d’un accusé de réception.
Restauration à un instant dans le passé des serveurs à haute disponibilité
Pour les serveurs flexibles configurés avec une haute disponibilité, les données des journaux sont répliquées en temps réel sur le serveur de secours. Toute erreur d’un utilisateur sur le serveur principal, par exemple la suppression accidentelle d’une table ou une mise à jour incorrecte des données, est répliquée sur le réplica de secours. Par conséquent, vous ne pouvez pas utiliser le serveur de secours pour récupérer de telles erreurs logiques. Pour récupérer de telles erreurs, vous devez effectuer une restauration à un instant dans le passé à partir de la sauvegarde. La fonctionnalité de restauration à un instant dans le passé du serveur flexible vous permet d’opérer une récupération jusqu’à une date et heure antérieures à la survenance de l’erreur. Un nouveau serveur de base de données est restauré en tant que serveur flexible dans une seule zone avec un nouveau nom de serveur fourni par l’utilisateur pour les bases de données configurées avec une haute disponibilité. Vous pouvez utiliser le serveur restauré dans quelques cas d’usage :
Vous pouvez utiliser le serveur restauré pour la production et éventuellement activer la haute disponibilité avec un réplica de secours sur la même zone ou une autre zone dans la même région.
Si vous voulez restaurer un objet, exportez-le à partir du serveur de base de données restauré et importez-le sur votre serveur de base de données de production.
Si vous voulez cloner votre serveur de base de données à des fins de test et de développement, ou si vous voulez effectuer une restauration pour n’importe quelle autre raison, vous pouvez effectuer une restauration à un instant dans le passé.
Pour savoir comment effectuer une restauration à un instant dans le passé d’un serveur flexible, consultez Restauration à un instant dans le passé d’un serveur flexible.
Prise en charge du basculement
Basculement planifié
Les événements de temps d’arrêt planifiés incluent des mises à jour logicielles périodiques planifiées Azure et des mises à niveau de version mineure. Vous pouvez également utiliser un basculement planifié pour renvoyer le serveur primaire à une zone de disponibilité préférée. Configurées en mode haute disponibilité, ces opérations sont d’abord appliquées au réplica de secours, tandis que les applications continuent d’accéder au serveur primaire. Une fois le réplica de secours mis à jour, les connexions au serveur primaire sont purgées et un basculement est déclenché, qui a pour effet d’activer le réplica de secours en tant que serveur primaire portant le même nom de serveur de base de données. Les applications clientes doivent se reconnecter avec le même nom de serveur de base de données au nouveau serveur primaire, et peuvent reprendre leurs opérations. Un nouveau serveur de secours est établi dans la même zone que l’ancien serveur principal.
Pour les autres opérations initiées par l’utilisateur, telles que la mise à l’échelle du calcul ou du stockage, les modifications sont appliquées d’abord au serveur réplica de secours, puis au serveur primaire. Actuellement, le service n’est pas basculé sur le serveur de secours et par conséquent, pendant que l’opération de mise à l’échelle est effectuée sur le serveur primaire, les applications subissent un court temps d’arrêt.
Vous pouvez également utiliser cette fonctionnalité pour basculer vers le serveur de secours avec un temps d’arrêt réduit. Par exemple, votre serveur primaire peut se trouver sur une zone de disponibilité différente de celle de l’application après un basculement non planifié. Vous souhaitez ramener le serveur primaire à la zone précédente pour qu’il se trouve sur la même zone que votre application.
Lors de l’exécution de cette fonctionnalité, le serveur de secours est d’abord préparé de façon à intégrer les transactions récentes, ce qui permet à l’application de continuer à effectuer des lectures/écritures. Le serveur de secours est ensuite promu et les connexions au serveur primaire sont interrompues. Votre application peut continuer à écrire sur le serveur principal, un nouveau serveur de secours étant établi en arrière-plan. Voici les étapes impliquées dans le basculement planifié :
| Étape | Description | Temps d’arrêt de l’application attendu ? |
|---|---|---|
| 1 | Attendez que le serveur de secours se mette au niveau du serveur primaire. | Non |
| 2 | Le système de surveillance interne lance le flux de travail de basculement. | Non |
| 3 | Les écritures de l’application sont bloquées quand le serveur de secours est proche du numéro séquentiel dans le journal (LSN) du serveur primaire. | Oui |
| 4 | Le serveur de secours est promu en tant que serveur indépendant. | Oui |
| 5 | L’enregistrement DNS est mis à jour avec l’adresse IP du nouveau serveur de secours. | Oui |
| 6 | L’application se reconnecte et reprend ses lectures/écritures sur le nouveau serveur principal. | Non |
| 7 | Un nouveau serveur de secours est établi dans une autre zone. | Non |
| 8 | Le serveur de secours commence à récupérer les journaux (à partir du Stockage Blob Azure) qu’il a manqués pendant la période nécessaire à son établissement. | Non |
| 9 | Un état stable entre le serveur primaire et le serveur de secours est établi. | Non |
| 10 | Le processus de basculement planifié est terminé. | Non |
Le temps d’arrêt de l’application commence à l’étape #3 et son fonctionnement peut reprendre après l’étape #5. Les autres étapes se produisent en arrière-plan sans impact sur les écritures et les commits de l’application.
Conseil
Avec le serveur flexible, vous pouvez si vous le souhaitez planifier des activités de maintenance lancées par Azure en choisissant une fenêtre de 60 minutes un jour de votre choix, où les activités sur les bases de données devraient être faibles. Les tâches de maintenance Azure, telles que les mises à jour correctives ou les mises à niveau de version mineure, seront effectuées dans cette fenêtre. Si vous ne choisissez pas une fenêtre personnalisée, une fenêtre d’une heure allouée par le système entre 23h00 et 7h00 (heure locale) est sélectionnée pour votre serveur. Ces activités de maintenance lancées par Azure sont effectuées sur le réplica de secours pour les serveurs flexibles configurés avec des zones de disponibilité.
Pour obtenir la liste des événements de temps d’arrêt planifiés possibles, consultez Événements de temps d’arrêt planifiés.
Basculement non planifié
Des temps d’arrêt non planifiés peuvent se produire suite à des interruptions imprévues, telles qu’une panne matérielle sous-jacente, des problèmes de mise en réseau et des bogues logiciels. Si le serveur de base de données configuré avec une haute disponibilité tombe en panne de façon inattendue, le serveur réplica de secours est activé et les clients peuvent reprendre leurs opérations. S’il n’est pas configuré avec une haute disponibilité (HA), si la tentative de redémarrage échoue, un nouveau serveur de base de données est automatiquement approvisionné. Bien qu’il ne soit pas possible d’éviter les temps d’arrêt non planifiés, un serveur flexible permet de réduire les temps d’arrêt en effectuant automatiquement des opérations de récupération sans nécessiter d’intervention humaine.
Pour plus d’informations sur les basculements non planifiés et les temps d’arrêt, y compris les scénarios possibles, consultez Atténuation des temps d’arrêt non planifiés.
Tests de basculement (basculement forcé)
Avec un basculement forcé, vous pouvez simuler un scénario de panne non planifiée tout en exécutant votre charge de travail de production et observer le temps d’arrêt de votre application. Vous pouvez également utiliser un basculement forcé lorsque votre serveur primaire ne répond plus.
Un basculement forcé arrête le serveur primaire et lance le flux de travail de basculement dans lequel l’opération de promotion du serveur de secours est effectuée. Une fois que le serveur de secours a terminé le processus de récupération jusqu’aux dernières données commitées, il est promu en tant que serveur primaire. Les enregistrements DNS sont mis à jour et votre application peut se connecter au serveur primaire promu. Votre application peut continuer à écrire sur le serveur primaire, tandis qu’un nouveau serveur de secours est établi en arrière-plan, ce qui n’a pas d’impact sur la durée de bon fonctionnement.
Voici les étapes à suivre lors du basculement forcé :
| Étape | Description | Temps d’arrêt de l’application attendu ? |
|---|---|---|
| 1 | Le serveur primaire est arrêté peu après la réception de la demande de basculement. | Oui |
| 2 | L’application subit un temps d’arrêt au moment où le serveur principal est arrêté. | Oui |
| 3 | Le système de surveillance interne détecte la défaillance et lance un basculement vers le serveur de secours. | Oui |
| 4 | Le serveur de secours passe en mode de récupération avant d’être promu entièrement en tant que serveur indépendant. | Oui |
| 5 | Le processus de basculement attend la fin de la récupération de secours. | Oui |
| 6 | Une fois le serveur opérationnel, l’enregistrement DNS est mis à jour avec le même nom d’hôte, mais en utilisant l’adresse IP du serveur de secours. | Oui |
| 7 | L’application peut se reconnecter au nouveau serveur principal et reprendre son fonctionnement. | Non |
| 8 | Un serveur de secours est étable dans la zone préférée. | Non |
| 9 | Le serveur de secours commence à récupérer les journaux (à partir du Stockage Blob Azure) qu’il a manqués pendant la période nécessaire à son établissement. | Non |
| 10 | Un état stable entre le serveur primaire et le serveur de secours est établi. | Non |
| 11 | Le processus de basculement forcé est terminé. | Non |
Le temps d’arrêt de l’application doit normalement commencer après l’étape #1 et persister jusqu’à ce que l’étape #6 soit terminée. Les autres étapes se produisent en arrière-plan sans affecter les écritures et les commits de l’application.
Important
Le processus de basculement de bout en bout comprend (a) le basculement vers le serveur de secours après défaillance du serveur primaire et (b) l’établissement d’un nouveau serveur de secours dans un état stable. Étant donné que votre application subit un temps d’arrêt jusqu’à la fin du basculement vers le serveur de secours, veuillez mesurer le temps d’arrêt du point de vue de votre application/client au lieu du processus de basculement global de bout en bout.
Considérations sur l’exécution de basculements forcés
La durée d’ensemble de l’opération peut être plus longue que le temps d’arrêt réel subi par l’application.
Important
Observez toujours temps d’arrêt du point de vue de l’application.
N’effectuez pas de basculements consécutifs sans pause. Attendez au moins 15 à 20 minutes entre chaque basculement, ce qui permet au nouveau serveur de secours d’être entièrement établi.
Il est recommandé d’effectuer un basculement forcé pendant une période de faible activité pour réduire les temps d’arrêt.
Meilleures pratiques pour les statistiques PostgreSQL après basculement
Après un basculement PostgreSQL, le mécanisme principal permettant de maintenir les performances optimales de la base de données implique la compréhension des rôles distincts de pg_statistic et les tables pg_stat_*. La table pg_statistic héberge des statistiques d’optimiseur, qui sont cruciales pour le planificateur de requêtes. Ces statistiques comprennent la distribution des données dans les tables et restent intactes après un basculement, ce qui permet au planificateur de requêtes de continuer à optimiser efficacement l'exécution des requêtes sur la base d'informations historiques et précises sur la distribution des données.
En revanche, les tables pg_stat_*, qui enregistrent des statistiques d’activité telles que le nombre d’analyses, de tuples lus et de mises à jour, sont réinitialisées lors du basculement. Un exemple de cette table est pg_stat_user_tables, qui suit l’activité pour les tables définies par l’utilisateur. Cette réinitialisation est conçue pour refléter avec précision l'état opérationnel du nouveau primaire, mais elle signifie également la perte des mesures d'activité historiques qui pourraient informer le processus d'auto-aspiration et d'autres efficacités opérationnelles.
Étant donné cette distinction, la meilleure pratique qui suit un basculement PostgreSQL consiste à exécuter ANALYZE. Cette action met à jour les tables pg_stat_*, par exemple pg_stat_user_tables, avec de nouvelles statistiques d’activité, aidant le processus de nettoyage automatique et garantissant que les performances de la base de données restent optimales dans son nouveau rôle. Cette étape proactive permet de combler le fossé entre la préservation des statistiques essentielles de l'optimiseur et l'actualisation des mesures d'activité pour les aligner sur l'état actuel de la base de données.
Expérience en cas de panne de zone
Zonal : pour effectuer une récupération après un échec au niveau de la zone, vous pouvez effectuer une restauration à un instant dans le passé à l’aide de la sauvegarde. Vous pouvez choisir un point de restauration personnalisé avec la dernière heure pour restaurer les données les plus récentes. Un nouveau serveur flexible sera déployé dans une autre zone non affectée. Le temps que prend la restauration dépend de la sauvegarde précédente et du volume des journaux des transactions à récupérer.
Pour plus d’informations sur la restauration à un instant dans le passé, consultez Sauvegarde et restauration dans Azure Database pour PostgreSQL Serveur flexible.
Redondant interzone : un serveur flexible est automatiquement basculé vers le serveur de secours dans un délai de 60 à 120 secondes sans perte de données.
Configurations sans zones de disponibilité
Bien que cela ne soit pas recommandé, vous pouvez configurer votre serveur flexible sans haute disponibilité activée. Pour un serveur flexible configuré sans haute disponibilité, le service offre un stockage redondant local avec trois copies des données, une sauvegarde redondante interzone (dans les régions où celle-ci est prise en charge), ainsi qu’une résilience de serveur intégrée pour redémarrer automatiquement un serveur défaillant et même déplacer le serveur vers un autre nœud physique. Un contrat SLA de 99,9 % de durée de bon fonctionnement est proposé dans cette configuration. Lors des événements de basculement, qu’ils soient planifiés ou non, si le serveur tombe en panne, le service maintient la disponibilité des serveurs grâce à la procédure automatisée suivante :
- Une nouvelle machine virtuelle de calcul Linux est approvisionnée.
- Le stockage contenant les fichiers de données est mappé avec la nouvelle machine virtuelle.
- Le moteur de base de données PostgreSQL est mis en ligne sur la nouvelle machine virtuelle.
L’image ci-dessous montre la transition entre les machines virtuelles et l’échec de stockage.

Récupération d’urgence et continuité d’activité inter-région
Dans le cas d’incident à l’échelle régionale, Azure peut fournir une protection contre les sinistres affectant une région ou une grande zone géographique avec la récupération d’urgence en exploitant une autre région. Pour plus d’informations sur l’architecture de récupération d’urgence Azure, consultez Architecture de récupération d’urgence Azure vers Azure.
Le serveur flexible fournit des fonctionnalités qui protègent les données et atténuent les temps d’arrêt de vos bases de données stratégiques pendant les temps d’arrêt planifiés et non planifiés. S’appuyant sur l’infrastructure Azure qui offre une résilience et une disponibilité robustes, le serveur flexible intègre des fonctionnalités de continuité d’activité qui offrent une protection contre les pannes, qui répondent aux exigences de temps de récupération et réduisent les risques de perte de données. À mesure que vous architecturez vos applications, vous devez prendre en compte la tolérance aux temps d’arrêt, l’objectif de temps de récupération (RTO), et l’exposition à la perte de données, l’objectif de point de récupération (RPO). Par exemple, votre base de données vitale pour l’entreprise impose une durée de bon fonctionnement plus stricte qu’une base de données de test.
Récupération d’urgence dans la zone géographique multi-région
Sauvegarde et restauration géo-redondantes
La sauvegarde et la restauration géo-redondantes permettent de restaurer votre serveur dans une région différente en cas de sinistre. Il fournit également une durabilité d’au moins 99,99999999999999 % (16 neuf) des objets de sauvegarde sur une année.
La sauvegarde géo-redondante ne peut être configurée qu’au moment de la création du serveur. Lorsque le serveur est configuré avec une sauvegarde géo-redondante, les données de sauvegarde et journaux des transactions sont copiés de façon asynchrone dans la région appairée à l’aide de la réplication de stockage.
Pour plus d’informations sur la sauvegarde et la restauration géo-redondantes, consultez sauvegarde et restauration géo-redondantes.
Réplicas en lecture
Des réplicas de lecture inter-régions peuvent être déployés pour protéger vos bases de données contre les défaillances au niveau de la région. Les réplicas en lecture sont mis à jour de manière asynchrone à l’aide de la technologie de réplication physique de PostgreSQL et peuvent présenter un décalage avec le serveur primaire. Les réplicas en lecture sont pris en charge dans les niveaux de calcul à usage général et à mémoire optimisée.
Pour plus d’informations sur les fonctionnalités et considérations relatives aux réplicas en lecture, consultez Réplicas en lecture.
Détection, notification et gestion des pannes
Si votre serveur est configuré avec une sauvegarde géo-redondante, vous pouvez effectuer la géo-restauration dans la région appairée. Un nouveau serveur est approvisionné et récupéré jusqu’aux dernières données disponibles copiées dans cette région.
Vous pouvez également utiliser des réplicas en lecture entre régions. En cas de défaillance de la région, vous pouvez effectuer une opération de récupération d’urgence en faisant de votre réplica en lecture un serveur en lecture-écriture autonome. Le RPO devrait être jusqu’à 5 minutes (perte de données possible), sauf en cas de défaillance régionale grave lorsque le RPO peut être proche du retard de réplication au moment de la défaillance.
Pour plus d’informations sur l’atténuation des temps d’arrêt non planifiés et la récupération après une catastrophe régionale, consultez Atténuation des temps d’arrêt non planifiés.