Haute disponibilité d’IBM Db2 LUW sur les machines virtuelles Azure sur Red Hat Enterprise Linux Server
IBM Db2 pour Linux, UNIX et Windows (LUW) dans une configuration de haute disponibilité et reprise d’activité (HADR) est constitué d’un nœud qui exécute une instance de base de données primaire et d’au moins un nœud qui exécute une instance de base de données secondaire. Les modifications apportées à l’instance de base de données primaire sont répliquées vers une instance de base de données secondaire de façon synchrone ou asynchrone, selon votre configuration.
Remarque
Cet article contient des références à des termes que Microsoft n’utilise plus. Lorsque ces termes seront supprimés du logiciel, nous les supprimerons de cet article.
Cet article décrit comment déployer et configurer les machines virtuelles Azure, installer le framework de cluster, et installer IBM Db2 LUW avec la configuration HADR.
L’article n’explique pas comment installer et configurer IBM Db2 LUW avec l’installation des logiciels SAP ou HADR. Pour vous aider à accomplir ces tâches, nous fournissons des références aux manuels d’installation SAP et IBM. Cet article se concentre sur des composants qui sont spécifiques à l’environnement Azure.
Les versions IBM Db2 prises en charge sont 10.5 et ultérieures, comme décrit dans la note SAP 1928533.
Avant de commencer une installation, consultez les notes SAP suivantes et la documentation :
| Note SAP | Description |
|---|---|
| 1928533 | Applications SAP sur Azure : Produits et types de machines virtuelles pris en charge |
| 2015553 | SAP sur Azure : Prérequis pour la prise en charge |
| 2178632 | Métriques de supervision clés pour SAP sur Azure |
| 2191498 | SAP sur Linux avec Azure : Surveillance améliorée |
| 2243692 | Linux sur une machine virtuelle Azure (IaaS) : problèmes de licence SAP |
| 2002167 | Red Hat Enterprise Linux 7.x : installation et mise à niveau |
| 2694118 | Module complémentaire de haute disponibilité Red Hat Enterprise Linux sur Azure |
| 1999351 | Résolution des problèmes de la surveillance Azure améliorée pour SAP |
| 2233094 | DB6 : applications SAP sur Azure qui utilisent IBM Db2 pour Linux, UNIX et Windows - informations supplémentaires |
| 1612105 | DB6 : forum aux questions sur Db2 avec HADR |
Vue d’ensemble
Pour obtenir une haute disponibilité, IBM Db2 LUW avec HADR est installé sur au moins deux machines virtuelles Azure, qui sont déployées dans un groupe de machines virtuelles identiques avec une orchestration flexible sur des zones de disponibilité ou dans un groupe à haute disponibilité.
Les graphiques suivants illustrent une configuration de deux machines virtuelles Azure de serveur de base de données. Les deux machines virtuelles Azure de serveur de base de données sont associées à leur propre système de stockage et sont opérationnelles. Dans HADR, une instance de base de données dans l’une des machines virtuelles Azure a le rôle de l’instance primaire. Tous les clients sont connectés à une instance primaire. Toutes les modifications dans les transactions de base de données sont conservées localement dans le journal des transactions Db2. Comme les enregistrements du journal des transactions sont conservés localement, les enregistrements sont transférés via TCP/IP à l’instance de base de données sur le second serveur de base de données, le serveur de secours ou une instance de secours. L’instance de secours met à jour la base de données locale en restaurant par progression les enregistrements du journal des transactions transférés. De cette façon, le serveur de secours est synchronisé avec le serveur principal.
HADR est uniquement une fonctionnalité de réplication. Elle n’assure pas la détection des défaillances et n’a aucune fonction de prise de contrôle ou basculement automatique. Une prise de contrôle ou un transfert vers le serveur de secours doit être lancé manuellement par un administrateur de base de données. Pour obtenir une prise de contrôle automatique et une détection des défaillances, vous pouvez utiliser la fonctionnalité de clustering Linux Pacemaker. Pacemaker supervise les deux instances de serveur de base de données. Lorsque l’instance de serveur de base de données primaire plante, Pacemaker lance une prise de contrôle HADR automatique par le serveur de secours. Pacemaker garantit également que l’adresse IP virtuelle est affectée au nouveau serveur principal.
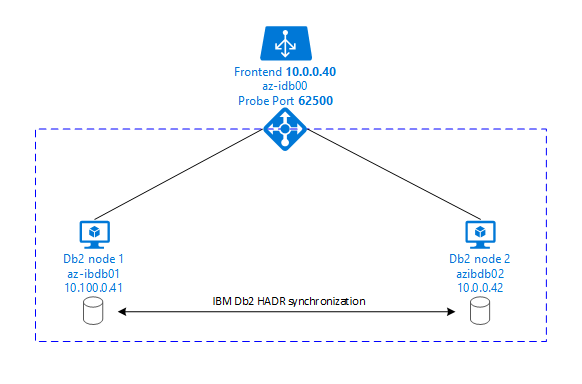
Pour que les serveurs d’applications SAP se connectent à la base de données primaire, vous avez besoin d’un nom d’hôte virtuel et d’une adresse IP virtuelle. Après un basculement, les serveurs d’applications SAP se connectent à la nouvelle instance de base de données primaire. Dans un environnement Azure, un équilibreur de charge Azure est nécessaire pour utiliser une adresse IP virtuelle de la façon requise pour HADR d’IBM Db2.
Pour vous aider à mieux comprendre comment IBM Db2 LUW avec HADR et Pacemaker s’adapte à une configuration de système SAP hautement disponible, l’image suivante présente une vue d’ensemble d’une configuration hautement disponible d’un système SAP basé sur une base de données IBM Db2. Cet article couvre uniquement IBM Db2, mais il fournit des références à d’autres articles sur la façon de configurer d’autres composants d’un système SAP.
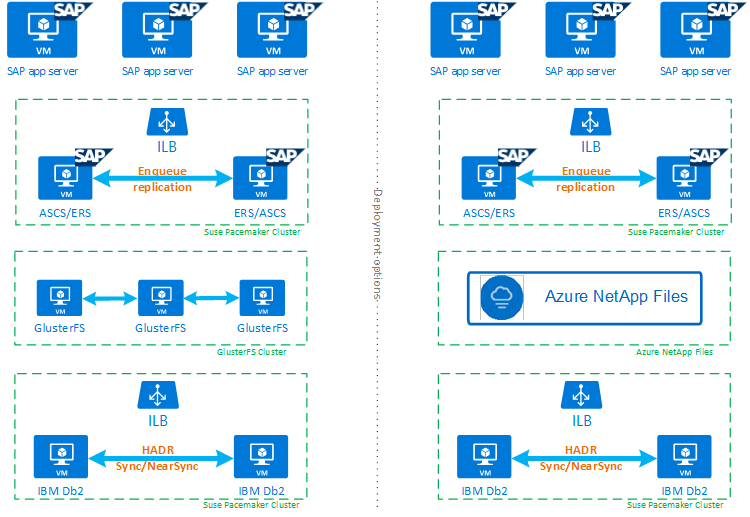
Vue d’ensemble globale des étapes à suivre
Pour déployer une configuration IBM Db2, vous devez procéder comme suit :
- Planifiez votre environnement.
- Déployez les machines virtuelles.
- Mettez à jour RHEL Linux et configurez des systèmes de fichiers.
- Installez et configurez Pacemaker.
- Configurer le cluster glusterfs ou Azure NetApp Files
- Installez ASCS/ERS sur un cluster séparé.
- Installez la base de données IBM Db2 avec l’option Distributed/High Availability (Distribué/Haute disponibilité) (SWPM).
- Installez et créez une instance et un nœud de base de données secondaire, et configurez HADR.
- Vérifiez que HADR fonctionne.
- Appliquez la configuration Pacemaker pour contrôler IBM Db2.
- Configurez Azure Load Balancer.
- Installez des serveurs d’applications principal et de boîte de dialogue.
- Vérifiez et adaptez la configuration des serveurs d’applications SAP.
- Effectuez des tests de basculement et de prise de contrôle.
Planifier l’infrastructure Azure pour l’hébergement d’IBM Db2 LUW avec HADR
Terminez le processus de planification avant d’exécuter le déploiement. La planification génère la base pour le déploiement d’une configuration de Db2 avec HADR dans Azure. Les éléments clés qui doivent faire partie de la planification d’IMB Db2 LUW (partie base de données de l’environnement SAP) sont listés dans le tableau suivant :
| Rubrique | Description courte |
|---|---|
| Définir des groupes de ressources Azure | Groupes de ressources sur lesquels vous déployez la machine virtuelle, le réseau virtuel, Azure Load Balancer et d’autres ressources. Ils peuvent être nouveaux ou existants. |
| Définition de sous-réseau/réseau virtuel | Endroit où des machines virtuelles pour IBM Db2 et Azure Load Balancer sont déployées. Elles peuvent être existantes ou récemment créées. |
| Machines virtuelles hébergeant IBM Db2 LUW | Taille de machine virtuelle, stockage, mise en réseau, adresse IP. |
| Nom d’hôte virtuel et adresse IP virtuelle pour la base de données IBM Db2 | Adresse IP virtuelle ou nom d’hôte utilisé pour la connexion des serveurs d’applications SAP. db-virt-hostname, db-virt-ip. |
| Délimitation Azure | La méthode permettant d’éviter les situations de Split-Brain est interdite. |
| Azure Load Balancer | Utilisation du niveau Standard (recommandé), port de la sonde pour la base de données Db2 (notre recommandation est 62500) probe-port. |
| Résolution de noms | Fonctionnement de la résolution de noms dans l’environnement. Le service DNS est fortement recommandé. Le fichier d’hôte local peut être utilisé. |
Pour plus d’informations sur Linux Pacemaker dans Azure, consultez Configurer Pacemaker sur Red Hat Enterprise Linux dans Azure.
Important
Pour db2 versions 11.5.6 et ultérieures, nous vous recommandons vivement d’utiliser la solution intégrée à l’aide de Pacemaker d’IBM.
Déploiement sur Red Hat Enterprise Linux
L’agent de ressource pour IBM DB2 LUW est inclus dans le module complémentaire de serveur HA Red Hat Enterprise Linux. Pour la configuration décrite dans ce document, vous devez utiliser Red Hat Enterprise Linux pour SAP. La Place de marché Azure contient une image de Red Hat Enterprise Linux 7.4 for SAP ou ultérieure que vous pouvez utiliser pour déployer de nouvelles machines virtuelles Azure. Soyez conscient des différents modèles de prise en charge ou service proposés par Red Hat via la Place de marché Azure quand vous choisissez une image de machine virtuelle dans la Place de marché de machines virtuelles Azure.
Hôtes : Mises à jour de DNS
Dressez la liste de tous les noms d’hôte, y compris les noms des hôtes virtuels, et mettez à jour vos serveurs DNS afin d’activer une adresse IP appropriée pour la résolution de nom d’hôte. S’il n’existe aucun serveur DNS ou que vous ne pouvez pas mettre à jour et créer des entrées DNS, vous devez utiliser les fichiers d’hôte local des machines virtuelles individuelles qui font partie de ce scénario. Si vous utilisez des entrées des fichiers d’hôte, assurez-vous que les entrées sont appliquées à toutes les machines virtuelles dans l’environnement du système SAP. Toutefois, nous vous recommandons d’utiliser votre serveur DNS qui, dans l’idéal, s’étend à Azure
Déploiement manuel
Vérifiez que le système d’exploitation sélectionné est pris en charge par IBM/SAP pour IBM Db2 LUW. La liste des versions de système d’exploitation prises en charge pour les machines virtuelles Azure et les versions Db2 est disponible dans la note SAP 1928533. La liste des versions de système d’exploitation par version Db2 individuelle est disponible dans le tableau de disponibilité des produits SAP. Nous vous recommandons vivement un minimum de Red Hat Enterprise Linux 7.4 pour SAP en raison des améliorations de performances liées à Azure dans cette version de Red Hat Enterprise Linux ou ultérieure.
- Créez ou sélectionnez un groupe de ressources.
- Créez ou sélectionnez un réseau virtuel et un sous-réseau.
- Choisissez un type de déploiement approprié pour des machines virtuelles SAP. Un groupes de machines virtuelles identiques à orchestration flexible en général.
- Créez la machine virtuelle 1.
- Utilisez Red Hat Enterprise Linux pour l’image SAP dans la Place de marché Azure.
- Sélectionnez le groupe identique, la zone de disponibilité ou le groupe à haute disponibilité créé à l’étape 3.
- Créez la machine virtuelle 2.
- Utilisez Red Hat Enterprise Linux pour l’image SAP dans la Place de marché Azure.
- Sélectionnez le groupe identique, la zone de disponibilité ou le groupe à haute disponibilité créé à l’étape 3 (zone différente de celle de l’étape 4).
- Ajoutez des disques de données aux machines virtuelles et vérifiez ensuite la suggestion sur la configuration d’un système de fichiers dans l’article Déploiement SGBD de machines virtuelles Azure IBM Db2 pour charge de travail SAP.
Installer l’environnement SAP et IBM Db2 LUW
Avant de commencer l’installation d’un environnement SAP basé sur IBM Db2 LUW, passez en revue la documentation suivante :
- Documentation Azure.
- Documentation SAP.
- Documentation IBM.
Des liens vers cette documentation sont fournis dans la section d’introduction de cet article.
Consultez les guides d’installation SAP sur l’installation d’applications basées sur NetWeaver sur IBM Db2 LUW. Vous pouvez trouver les guides dans le portail d’aide SAP à l’aide de SAP Installation Guide Finder.
Vous pouvez réduire le nombre de guides affichés dans le portail en définissant les filtres suivants :
- Je souhaite : installer un nouveau système.
- Ma base de données : IBM Db2 pour Linux, Unix et Windows.
- Filtres supplémentaires pour les versions SAP NetWeaver, la configuration de pile ou le système d’exploitation.
Règles de pare-feu Red Hat
Red Hat Enterprise Linux a un pare-feu activé par défaut.
#Allow access to SWPM tool. Rule is not permanent.
sudo firewall-cmd --add-port=4237/tcp
Conseils d’installation pour la configuration d’IBM Db2 LUW avec HADR
Pour configurer l’instance de base de données IBM Db2 LUW primaire :
- Utilisez l’option Distributed ou High Availability (Distribué ou Haute disponibilité).
- Installez SAP ASCS/ERS et l’instance de base de données.
- Effectuez une sauvegarde de la base de données nouvellement installée.
Important
Notez le « port de communication de la base de données » qui est défini lors de l’installation. Ce doit être le même numéro de port pour les deux instances de base de données.
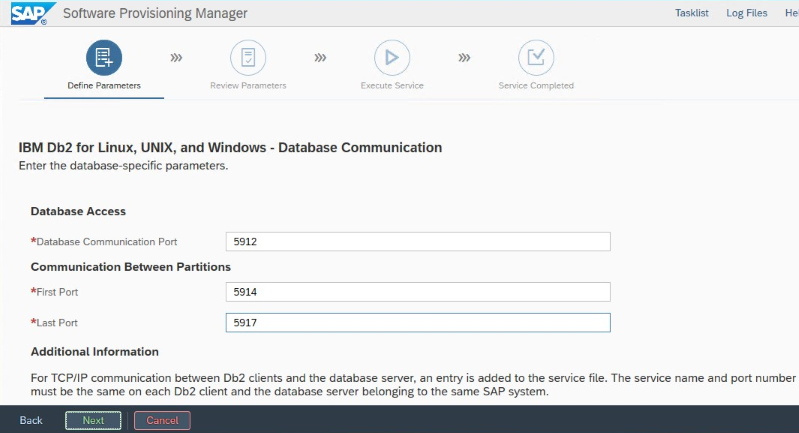
Paramètres de haute disponibilité et récupération d’urgence IBM DB2 pour Azure
Lorsque vous utilisez un agent de délimitation Azure Pacemaker, définissez les paramètres suivants :
- Durée de la fenêtre homologue de haute disponibilité et récupération d’urgence (secondes) (HADR_PEER_WINDOW) = 240
- Délai d’expiration de haute disponibilité et récupération d’urgence (HADR_TIMEOUT) = 45
Nous vous recommandons les paramètres précédents d’après les tests de basculement/prise de contrôle initiaux. Il est obligatoire de tester le bon fonctionnement du basculement et de la prise de contrôle avec ces paramètres. Étant donné que les configurations individuelles peuvent varier, les paramètres peuvent nécessiter un ajustement.
Notes
Propre à IBM Db2 avec une configuration HADR et un démarrage normal : l’instance de base de données secondaire ou de secours doit être opérationnelle avant de pouvoir démarrer l’instance de base de données primaire.
Notes
Pour une installation et une configuration spécifiques à Azure et Pacemaker : Au cours de la procédure d’installation via SAP Software Provisioning Manager, une question explicite se pose sur la haute disponibilité pour IBM Db2 LUW :
- Ne sélectionnez pas IBM Db2 pureScale.
- Ne sélectionnez pas Install IBM Tivoli System Automation for Multiplatforms (Installer IBM Tivoli System Automation pour plusieurs plateformes).
- Ne sélectionnez pas Generate cluster configuration files (Générer des fichiers de configuration de cluster).
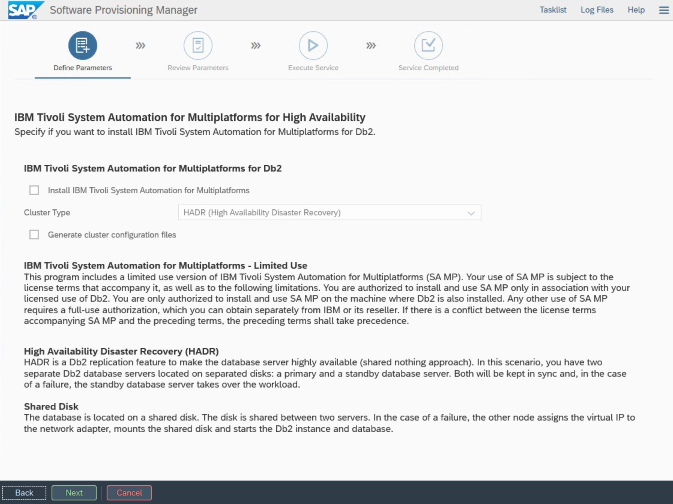
Pour configurer le serveur de base de données de secours à l’aide de la procédure de copie de système homogène SAP, exécutez ces étapes :
- Sélectionnez l’option System copy (Copie du système)>Target systems (Systèmes cibles) >Distributed (Distribué) >Database instance (Instance de base de données).
- Comme méthode de copie, sélectionnez Homogeneous System (Système homogène) afin que vous puissiez utiliser la copie de sauvegarde pour restaurer une sauvegarde sur l’instance de serveur de secours.
- Lorsque vous atteignez la dernière étape pour restaurer la base de données pour la copie de système homogène, quittez le programme d’installation. Restaurez la base de données à partir d’une sauvegarde de l’hôte principal. Toutes les phases d’installation suivantes ont déjà été exécutées sur le serveur de base de données principal.
Règles de pare-feu Red Hat pour haute disponibilité et récupération d’urgence DB2
Ajoutez des règles de pare-feu pour autoriser le trafic vers DB2 et entre DB2 pour que la haute disponibilité et récupération d’urgence fonctionne :
- Base de données de port de communication. Si vous utilisez des partitions, ajoutez ces ports également.
- Port HADR (valeur du paramètre DB2 HADR_LOCAL_SVC).
- Port de la sonde Azure.
sudo firewall-cmd --add-port=<port>/tcp --permanent
sudo firewall-cmd --reload
Vérification HADR IBM Db2
À des fins de démonstration et pour les procédures décrites dans cet article, l’ID de sécurité de la base de données est ID2.
Une fois que vous avez configuré HADR et que l’état est PEER et CONNECTED sur les nœuds principal et de secours, effectuez la vérification suivante :
Execute command as db2<sid> db2pd -hadr -db <SID>
#Primary output:
Database Member 0 -- Database ID2 -- Active -- Up 1 days 15:45:23 -- Date 2019-06-25-10.55.25.349375
HADR_ROLE = PRIMARY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 1
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS =
PRIMARY_MEMBER_HOST = az-idb01
PRIMARY_INSTANCE = db2id2
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = az-idb02
STANDBY_INSTANCE = db2id2
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 06/25/2019 10:55:05.076494 (1561460105)
HEARTBEAT_INTERVAL(seconds) = 7
HEARTBEAT_MISSED = 5
HEARTBEAT_EXPECTED = 52
HADR_TIMEOUT(seconds) = 30
TIME_SINCE_LAST_RECV(seconds) = 5
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 598.000027
LOG_HADR_WAIT_ACCUMULATED(seconds) = 598.000
LOG_HADR_WAIT_COUNT = 1
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 369280
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
HADR_LOG_GAP(bytes) = 132242668
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_REPLAY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_RECV_BUF_SIZE(pages) = 2048
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 1000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 300
PEER_WINDOW_END = 06/25/2019 11:12:03.000000 (1561461123)
READS_ON_STANDBY_ENABLED = N
#Secondary output:
Database Member 0 -- Database ID2 -- Standby -- Up 1 days 15:45:18 -- Date 2019-06-25-10.56.19.820474
HADR_ROLE = STANDBY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 0
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS =
PRIMARY_MEMBER_HOST = az-idb01
PRIMARY_INSTANCE = db2id2
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = az-idb02
STANDBY_INSTANCE = db2id2
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 06/25/2019 10:55:05.078116 (1561460105)
HEARTBEAT_INTERVAL(seconds) = 7
HEARTBEAT_MISSED = 0
HEARTBEAT_EXPECTED = 10
HADR_TIMEOUT(seconds) = 30
TIME_SINCE_LAST_RECV(seconds) = 1
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 598.000027
LOG_HADR_WAIT_ACCUMULATED(seconds) = 598.000
LOG_HADR_WAIT_COUNT = 1
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 367360
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
HADR_LOG_GAP(bytes) = 0
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_REPLAY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_RECV_BUF_SIZE(pages) = 2048
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 1000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 1000
PEER_WINDOW_END = 06/25/2019 11:12:59.000000 (1561461179)
READS_ON_STANDBY_ENABLED = N
Configurer Azure Load Balancer
Pendant la configuration de la machine virtuelle, vous avez la possibilité de créer ou de sélectionner un équilibreur de charge existant dans la section réseau. Suivez les étapes ci-dessous pour configurer l’équilibreur de charge standard pour la configuration de la haute disponibilité de la base de données DB2.
Suivez les étapes dans Créer un équilibreur de charge pour configurer un équilibreur de charge standard pour un système SAP à haute disponibilité à l’aide du portail Azure. Pendant la configuration de l’équilibreur de charge, tenez compte des points suivants :
- Configuration d’une adresse IP front-end : créez une adresse IP front-end. Sélectionnez le même nom de réseau virtuel et de sous-réseau que vos machines virtuelles de base de données.
- Pool back-end : créez un pool back-end et ajoutez des machines virtuelles de base de données.
- Règles de trafic entrant : créez une règle d’équilibrage de charge. Suivez les mêmes étapes pour les deux règles d’équilibrage de charge.
- Adresse IP front-end : sélectionnez une adresse IP front-end.
- Pool back-end : sélectionnez un pool back-end.
- Ports haute disponibilité : sélectionnez cette option.
- Protocole : sélectionnez TCP.
- Sonde d’intégrité : créez une sonde d’intégrité avec les détails suivants :
- Protocole : sélectionnez TCP.
- Port : par exemple, 625<numéro-instance>.
- Intervalle : entrez 5.
- Seuil de sonde : entrez 2.
- Délai d'inactivité (minutes) : entrez 30.
- Activer l’adresse IP flottante : sélectionnez cette option.
Remarque
La propriété de configuration de la sonde d’intégrité numberOfProbes, également appelée Seuil de défaillance sur le plan de l’intégrité dans le portail, n’est pas respectée. Pour contrôler le nombre de sondes consécutives qui aboutissent ou qui échouent, définissez la propriété probeThreshold sur 2. Il n’est actuellement pas possible de définir cette propriété à l’aide du portail Azure. Utilisez donc l’interface Azure CLI ou la commande PowerShell.
Remarque
Lorsque des machines virtuelles sans adresse IP publique sont placées dans le pool back-end d’une instance interne d’Azure Load Balancer Standard (sans adresse IP publique), il n’y a pas de connectivité Internet sortante à moins qu’une configuration supplémentaire soit effectuée pour permettre le routage vers des points de terminaison publics. Pour plus d’informations sur la façon de bénéficier d’une connectivité sortante, consultez Connectivité de point de terminaison public pour les machines virtuelles avec Azure Standard Load Balancer dans les scénarios de haute disponibilité SAP.
Important
N’activez pas les horodateurs TCP sur les machines virtuelles Azure placées derrière l’Équilibreur de charge Azure. L’activation de timestamps TCP peut entraîner l’échec des sondes d’intégrité. Affectez au paramètre net.ipv4.tcp_timestampsla valeur 0. Pour plus d’informations, consultez Sondes d’intégrité Load Balancer.
[A] Ajouter une règle de pare-feu pour le port de sondage :
sudo firewall-cmd --add-port=<probe-port>/tcp --permanent
sudo firewall-cmd --reload
Créez le cluster Pacemaker
Pour créer un cluster Pacemaker de base pour ce serveur IBM Db2, consultez Configurer Pacemaker sur Red Hat Enterprise Linux dans Azure.
Configuration Pacemaker de Db2
Lorsque vous utilisez Pacemaker pour le basculement automatique en cas de défaillance d’un nœud, vous devez configurer vos instances Db2 et Pacemaker en conséquence. Cette section décrit ce type de configuration.
Les éléments suivants sont précédés de :
- [A] : applicable à tous les nœuds
- [1] : applicable uniquement au nœud 1
- [2] : applicable uniquement au nœud 2
[A] Prérequis pour la configuration Pacemaker :
Arrêtez les deux serveurs de base de données avec l’utilisateur db2<sid> avec db2stop.
Remplacez l’environnement d’interpréteur de commandes pour l’utilisateur db2<sid> par /bin/ksh :
# Install korn shell: sudo yum install ksh # Change users shell: sudo usermod -s /bin/ksh db2<sid>
Configuration Pacemaker
[1] Configuration Pacemaker spécifique à HADR IBM Db2 :
# Put Pacemaker into maintenance mode sudo pcs property set maintenance-mode=true[1] Créez des ressources IBM Db2 :
Si vous générez un cluster sur RHEL 7.x, veillez à mettre à jour les agents de ressources du package vers une version ou une version
resource-agents-4.1.1-61.el7_9.15ou ultérieure. Utilisez les commandes suivantes pour créer les ressources de cluster :# Replace bold strings with your instance name db2sid, database SID, and virtual IP address/Azure Load Balancer. sudo pcs resource create Db2_HADR_ID2 db2 instance='db2id2' dblist='ID2' master meta notify=true resource-stickiness=5000 #Configure resource stickiness and correct cluster notifications for master resoruce sudo pcs resource update Db2_HADR_ID2-master meta notify=true resource-stickiness=5000 # Configure virtual IP - same as Azure Load Balancer IP sudo pcs resource create vip_db2id2_ID2 IPaddr2 ip='10.100.0.40' # Configure probe port for Azure load Balancer sudo pcs resource create nc_db2id2_ID2 azure-lb port=62500 #Create a group for ip and Azure loadbalancer probe port sudo pcs resource group add g_ipnc_db2id2_ID2 vip_db2id2_ID2 nc_db2id2_ID2 #Create colocation constrain - keep Db2 HADR Master and Group on same node sudo pcs constraint colocation add g_ipnc_db2id2_ID2 with master Db2_HADR_ID2-master #Create start order constrain sudo pcs constraint order promote Db2_HADR_ID2-master then g_ipnc_db2id2_ID2Si vous générez un cluster sur RHEL 8.x, veillez à mettre à jour les agents de ressources du package vers une version ou une version
resource-agents-4.1.1-93.el8ou ultérieure. Pour plus d’informations, consultez l’article de la base de connaissances Red Hat sur l’échec de la promotion de la ressourcedb2avec HADR avec l’étatPRIMARY/REMOTE_CATCHUP_PENDING/CONNECTED. Utilisez les commandes suivantes pour créer les ressources de cluster :# Replace bold strings with your instance name db2sid, database SID, and virtual IP address/Azure Load Balancer. sudo pcs resource create Db2_HADR_ID2 db2 instance='db2id2' dblist='ID2' promotable meta notify=true resource-stickiness=5000 #Configure resource stickiness and correct cluster notifications for master resoruce sudo pcs resource update Db2_HADR_ID2-clone meta notify=true resource-stickiness=5000 # Configure virtual IP - same as Azure Load Balancer IP sudo pcs resource create vip_db2id2_ID2 IPaddr2 ip='10.100.0.40' # Configure probe port for Azure load Balancer sudo pcs resource create nc_db2id2_ID2 azure-lb port=62500 #Create a group for ip and Azure loadbalancer probe port sudo pcs resource group add g_ipnc_db2id2_ID2 vip_db2id2_ID2 nc_db2id2_ID2 #Create colocation constrain - keep Db2 HADR Master and Group on same node sudo pcs constraint colocation add g_ipnc_db2id2_ID2 with master Db2_HADR_ID2-clone #Create start order constrain sudo pcs constraint order promote Db2_HADR_ID2-clone then g_ipnc_db2id2_ID2[1] Démarrez les ressources IBM Db2 :
Sortez Pacemaker du mode de maintenance.
# Put Pacemaker out of maintenance-mode - that start IBM Db2 sudo pcs property set maintenance-mode=false[1] Vérifiez que l’état du cluster est OK et que toutes les ressources sont démarrées. Le nœud sur lequel les ressources s’exécutent n’a aucune importance.
sudo pcs status 2 nodes configured 5 resources configured Online: [ az-idb01 az-idb02 ] Full list of resources: rsc_st_azure (stonith:fence_azure_arm): Started az-idb01 Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2] Masters: [ az-idb01 ] Slaves: [ az-idb02 ] Resource Group: g_ipnc_db2id2_ID2 vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01 nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
Important
Vous devez gérer l’instance Db2 en cluster Pacemaker à l’aide des outils Pacemaker. Si vous utilisez des commandes db2, telles que db2stop, Pacemaker détecte l’action comme un échec de ressource. Si vous effectuez une maintenance, vous pouvez placer les nœuds ou les ressources en mode de maintenance. Pacemaker suspend la supervision des ressources et vous pouvez alors utiliser les commandes d’administration db2 normales.
Apporter des modifications aux profils SAP afin d’utiliser l’adresse IP virtuelle pour la connexion
Pour se connecter à l’instance primaire de la configuration HADR, la couche d’application SAP doit utiliser l’adresse IP virtuelle que vous avez définie et configurée pour Azure Load Balancer. Les modifications suivantes sont requises :
/sapmnt/<SID>/profile/DEFAULT.PFL
SAPDBHOST = db-virt-hostname
j2ee/dbhost = db-virt-hostname
/sapmnt/<SID>/global/db6/db2cli.ini
Hostname=db-virt-hostname
Installer des serveurs d’applications principal et de boîte de dialogue
Quand vous installez des serveurs d’applications principal et de boîte de dialogue sur une configuration Db2 HADR, utilisez le nom d’hôte virtuel que vous avez choisi pour la configuration.
Si vous avez effectué l’installation avant de créer la configuration HADR Db2, apportez les modifications comme décrit dans la section précédente et comme suit pour les piles SAP Java.
Vérification de l’URL JDBC des systèmes de piles Java ou ABAP+Java
Utilisez l’outil de configuration J2EE pour vérifier ou mettre à jour l’URL JDBC. Étant donné que l’outil de configuration J2EE est un outil graphique, le serveur X doit être installé :
Connectez-vous au serveur d’applications principal de l’instance J2EE et exécutez :
sudo /usr/sap/*SID*/*Instance*/j2ee/configtool/configtool.shDans le cadre de gauche, choisissez Security store (Magasin de sécurité).
Dans le cadre de droite, choisissez la clé
jdbc/pool/\<SAPSID>/url.Remplacez le nom d’hôte dans l’URL JDBC par le nom d’hôte virtuel.
jdbc:db2://db-virt-hostname:5912/TSP:deferPrepares=0Sélectionnez Ajouter.
Pour enregistrer vos modifications, sélectionnez l’icône en forme de disque en haut à gauche.
Fermez l’outil de configuration.
Redémarrez l’instance Java.
Configurer l’archivage des journaux pour la configuration HADR
Pour configurer l’archivage des journaux Db2 pour la configuration HADR, nous vous recommandons de configurer à la fois les bases de données primaire et de secours pour activer la fonctionnalité de récupération des journaux automatique à partir de tous les emplacements des archives des journaux. Les bases de données primaire et de secours doivent être en mesure de récupérer les fichiers d’archive des journaux à partir de tous les emplacements auxquels l’une ou l’autre des instances de base de données peut archiver des fichiers journaux.
L’archivage des journaux est effectué uniquement par la base de données primaire. Si vous modifiez les rôles HADR des serveurs de base de données ou si une défaillance se produit, la nouvelle base de données primaire est responsable de l’archivage des journaux. Si vous avez configuré plusieurs emplacements pour les archives des journaux, il est possible que vos journaux soient archivés à deux reprises. En cas d’une mise à jour locale ou distante, vous devrez peut-être également copier manuellement les journaux archivés à partir de l’ancien serveur principal à l’emplacement actif des journaux du nouveau serveur principal.
Nous vous recommandons de configurer un partage NFS ou GlusterFS commun dans lequel les journaux sont écrits à partir des deux nœuds. Le partage NFS ou GlusterFS doit être hautement disponible.
Vous pouvez utiliser des partages NFS ou GlusterFS hautement disponibles existants pour les transports ou un répertoire de profil. Pour plus d’informations, consultez l’article suivant :
- GlusterFS sur des machines virtuelles Azure sur Red Hat Enterprise Linux pour SAP NetWeaver.
- Haute disponibilité pour SAP NetWeaver sur des machines virtuelles Azure sur Red Hat Enterprise Linux avec Azure NetApp Files pour les applications SAP.
- Azure NetApp Files (pour créer des partages NFS).
Tester la configuration du cluster
Cette section explique comment vous pouvez tester votre configuration HADR Db2. Chaque test suppose que le primaire IBM DB2 s’exécute sur la machine virtuelle az-idb01. L’utilisateur avec des privilèges sudo ou racine (non recommandé) doit être utilisé.
L’état initial de tous les cas de test est expliqué ici : (crm_mon -r ou pcs status)
- pcs status est un instantané de l’état de Pacemaker au moment de l’exécution.
- crm_mon -r est la sortie continue de l’état de Pacemaker.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
L’état d’origine dans un système SAP est documenté dans Transaction DBACOCKPIT > Configuration > Vue d’ensemble, comme illustré dans l’image suivante :
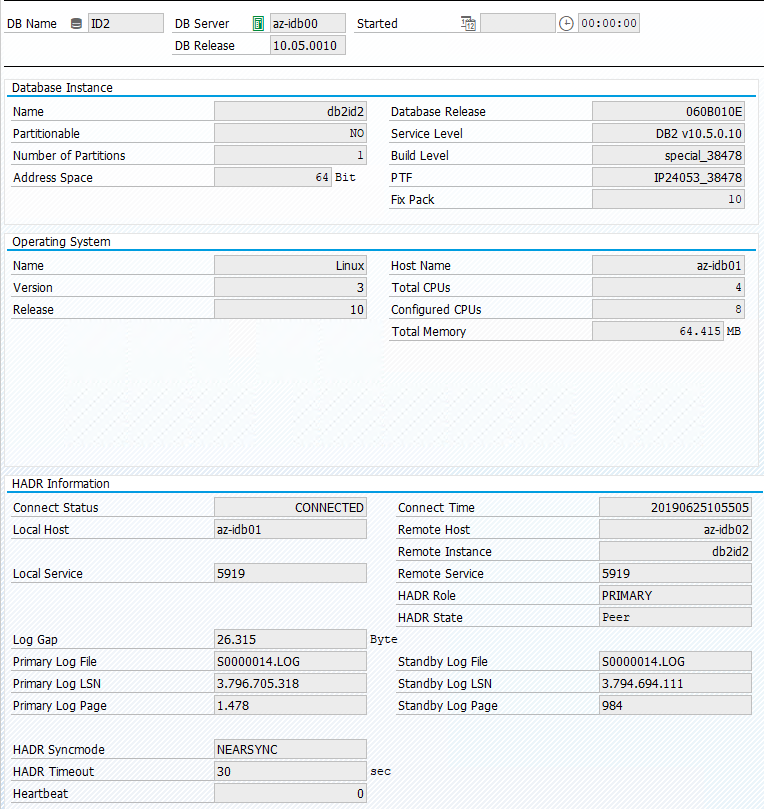
Tester la prise de contrôle d’IBM Db2
Important
Avant de commencer le test, vérifiez les points suivants :
Pacemaker ne comporte pas d’action ayant échoué (pcs status).
Il n’existe aucune contrainte d’emplacement (reliquats d’un test de migration).
La synchronisation HADR IBM Db2 fonctionne. Vérifiez auprès de l’utilisateur db2<sid>.
db2pd -hadr -db <DBSID>
Migrez le nœud qui exécute la base de données Db2 primaire en exécutant la commande suivante :
# On RHEL 7.x
sudo pcs resource move Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource move Db2_HADR_ID2-clone --master
Une fois la migration terminée, la sortie crm status ressemble à ce qui suit :
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
L’état d’origine dans un système SAP est documenté dans Transaction DBACOCKPIT > Configuration > Vue d’ensemble, comme illustré dans l’image suivante :
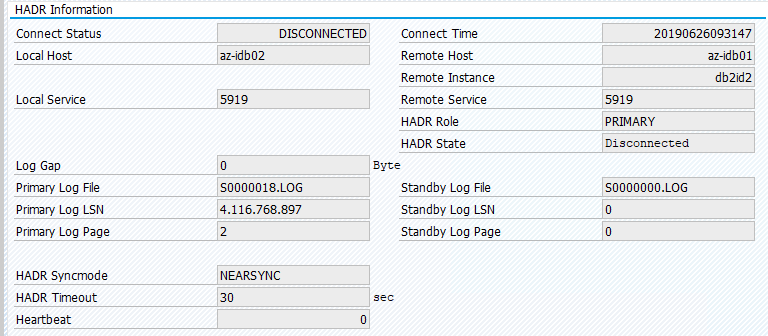
La migration de ressources avec « pcs resource migrate » crée des contraintes d’emplacement. Dans ce cas, les contraintes d’emplacement empêchent l’exécution de l’instance IBM DB2 sur az-idb01. Si les contraintes d’emplacement ne sont pas supprimées, la ressource ne peut pas être restaurée automatiquement.
Supprimez la contrainte d’emplacement et le nœud de secours sera démarré sur az-idb01.
# On RHEL 7.x
sudo pcs resource clear Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource clear Db2_HADR_ID2-clone
Et l’état du cluster devient :
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
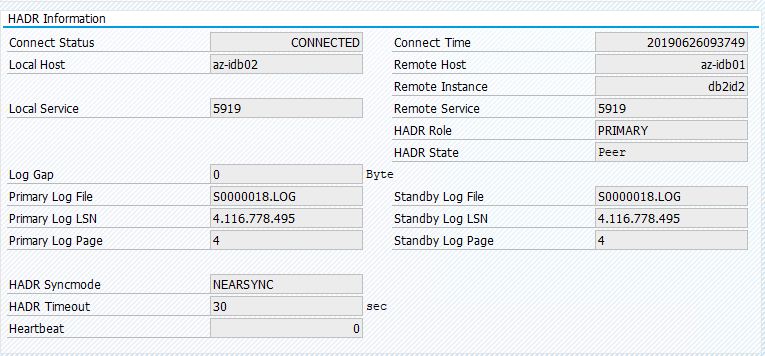
Ramenez la ressource vers az-idb01 et effacez les contraintes d’emplacement
# On RHEL 7.x
sudo pcs resource move Db2_HADR_ID2-master az-idb01
sudo pcs resource clear Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource move Db2_HADR_ID2-clone --master
sudo pcs resource clear Db2_HADR_ID2-clone
- Sur RHEL 7.x –
pcs resource move <resource_name> <host>: crée des contraintes d’emplacement et peut entraîner des problèmes de prise de contrôle - Sur RHEL 8.x –
pcs resource move <resource_name> --master: crée des contraintes d’emplacement et peut entraîner des problèmes de prise de contrôle pcs resource clear <resource_name>: efface les contraintes d’emplacementpcs resource cleanup <resource_name>: efface toutes les erreurs de la ressource
Tester une prise de contrôle manuelle
Vous pouvez tester une prise de contrôle manuelle en arrêtant le service Pacemaker sur le nœud az-idb01 :
systemctl stop pacemaker
état sur az-ibdb02
2 nodes configured
5 resources configured
Node az-idb01: pending
Online: [ az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Après le basculement, vous pouvez redémarrer le service sur az-idb01.
systemctl start pacemaker
Arrêter le processus Db2 sur le nœud qui exécute la base de données primaire HADR
#Kill main db2 process - db2sysc
[sapadmin@az-idb02 ~]$ sudo ps -ef|grep db2sysc
db2ptr 34598 34596 8 14:21 ? 00:00:07 db2sysc 0
[sapadmin@az-idb02 ~]$ sudo kill -9 34598
L’instance DB2 va échouer, et le Pacemaker déplace le nœud maître et affiche le rapport suivant :
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=49, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 09:57:35 2019', queued=0ms, exec=362ms
Soit Pacemaker redémarre l’instance de base de données primaire Db2 sur le même nœud, soit il bascule vers le nœud qui exécute l’instance de base de données secondaire et une erreur est signalée.
Arrêter le processus Db2 sur le nœud qui exécute l’instance de base de données secondaire
[sapadmin@az-idb02 ~]$ sudo ps -ef|grep db2sysc
db2id2 23144 23142 2 09:53 ? 00:00:13 db2sysc 0
[sapadmin@az-idb02 ~]$ sudo kill -9 23144
Le nœud passe en état d’échec et une erreur est signalée.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Failed Actions:
* Db2_HADR_ID2_monitor_20000 on az-idb02 'not running' (7): call=144, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 10:02:09 2019', queued=0ms, exec=0ms
L’instance Db2 est redémarrée dans le rôle secondaire qu’elle avait auparavant.
Arrêter Db2 par le biais de db2stop force sur le nœud qui exécute l’instance de base de données primaire HADR
En tant qu’utilisateur db2<sid>, exécutez la commande db2stop force :
az-idb01:db2ptr> db2stop force
Échec détecté :
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Slaves: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Stopped
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Stopped
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=110, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 14:03:12 2019', queued=0ms, exec=355ms
L’instance de base de données secondaire de haute disponibilité et récupération d’urgence DB2 a été promue au rôle principal.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=110, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 14:03:12 2019', queued=0ms, exec=355ms
Planter la machine virtuelle qui exécute l’instance de base de données primaire HADR avec « halt »
#Linux kernel panic.
sudo echo b > /proc/sysrq-trigger
Dans ce cas, Pacemaker détecte que le nœud qui exécute l’instance de base de données primaire ne répond pas.
2 nodes configured
5 resources configured
Node az-idb01: UNCLEAN (online)
Online: [ az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
L’étape suivante consiste à rechercher une situation de Split-Brain. Une fois que le nœud restant a déterminé que le nœud qui a exécuté en dernier l’instance de base de données primaire est en panne, un basculement des ressources est exécuté.
2 nodes configured
5 resources configured
Online: [ az-idb02 ]
OFFLINE: [ az-idb01 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
En cas de panique du noyau, le nœud défaillant est redémarré par l’agent de clôturage. Une fois le nœud défaillant remis en ligne, vous devez démarrer le cluster du pacemaker par
sudo pcs cluster start
il démarre l’instance DB2 dans le rôle secondaire.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Étapes suivantes
Commentaires
Prochainement : Tout au long de l'année 2024, nous supprimerons progressivement les GitHub Issues en tant que mécanisme de retour d'information pour le contenu et nous les remplacerons par un nouveau système de retour d'information. Pour plus d’informations, voir: https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour