Configurations de la charge de travail SAP avec des zones de disponibilité Azure
Le déploiement des différentes couches d’architecture SAP entre les Zones de disponibilité Azure est l’architecture recommandée pour les déploiements de charges de travail SAP sur Azure. La définition des zones de disponibilité Azure est la suivante : « Emplacements physiques uniques dans une région. Chaque zone de disponibilité est composée d’un ou de plusieurs centres de données équipés d’une alimentation, d’un système de refroidissement et d’un réseau indépendants. » Les zones de disponibilité Azure ne sont pas disponibles dans toutes les régions. Pour les régions Azure qui fournissent des Zones de disponibilité, consultez la carte des régions Azure. L’article répertorie les régions qui fournissent des Zones de disponibilité. La plupart des régions Azure équipées pour héberger une plus grande charge de travail SAP fournissent des Zones de disponibilité. Les nouvelles régions Azure fournissent des Zones de disponibilité dès le début. Certaines régions plus anciennes étaient ou sont en cours de mise à niveau avec les Zones de disponibilité.
Dans l’architecture SAP NetWeaver ou S/4HANA standard, vous devez protéger trois couches :
- La couche d’application SAP, qui peut comprendre une ou plusieurs dizaines de machines virtuelles. Vous souhaitez réduire le risque de déploiement des machines virtuelles sur le même serveur hôte. Vous souhaitez également que ces machines virtuelles se trouvent à proximité de la couche de base de données pour maintenir une latence réseau acceptable
- La couche SAP ASCS/SCS qui représente un point de défaillance unique dans l’architecture SAP NetWeaver et S/4HANA. En général, vous visez deux machines virtuelles à couvrir avec une infrastructure de basculement. Par conséquent, ces machines virtuelles doivent être allouées dans des domaines d’erreur d’infrastructure différents
- La couche de base de données SAP, qui représente également un point de défaillance unique. Dans les cas habituels, elle est constituée de deux machines virtuelles couvertes par une infrastructure de basculement. Par conséquent, ces machines virtuelles doivent être allouées dans des domaines d’erreur d’infrastructure différents. Les déploiements SAP HANA avec montée en puissance parallèle où plus de deux machines virtuelles peuvent être utilisées sont les seules exceptions.
Les principales différences entre le déploiement de vos machines virtuelles critiques via des groupes à haute disponibilité ou des zones de disponibilité sont les suivantes :
- Le déploiement avec un groupe à haute disponibilité aligne les machines virtuelles au sein du jeu dans une seule zone ou un seul centre de données (en fonction de ce qui s’applique à la région concernée). Par conséquent, le déploiement qui utilise un groupe à haute disponibilité n’est pas protégé contre les problèmes d’alimentation, de refroidissement ou de réseau qui affectent le ou les centres de données de la zone dans son ensemble. Avec les groupes à haute disponibilité, il n’existe pas non plus d’alignement forcé entre une machine virtuelle et ses disques. Signifie que les disques peuvent se trouver dans n’importe quel centre de données de la région Azure, indépendamment de la structure zonale de la région. L’aspect positif est que les machines virtuelles sont alignées avec les domaines de mise à jour et d’erreur au sein de cette zone ou de ce centre de données. En particulier pour la couche SAP ASCS ou de base de données dans laquelle nous protégeons deux machines virtuelles par groupe à haute disponibilité, l’alignement avec les domaines d’erreur empêche que les deux machines virtuelles se trouvent sur le même matériel hôte.
- Le déploiement de machines virtuelles dans les Zones de disponibilité Azure et le choix de différentes zones (trois maximum) implique de déployer les machines virtuelles dans différents emplacements physiques, et ajoute une protection contre les problèmes d’alimentation, de refroidissement ou de réseau qui affectent le ou les centres de données de la zone dans son ensemble. Les machines virtuelles et leurs disques associés sont également colocalisées dans la même Zone de disponibilité. Toutefois, quand vous déployez plusieurs machines virtuelles de la même famille VM dans la même zone de disponibilité, il n’est pas garanti que les machines virtuelles ne se retrouvent pas sur le même hôte ou dans le même domaine d’erreur. Par conséquent, le déploiement par le biais de Zones de disponibilité est idéal pour la couche SAP ASCS et de base de données, où nous utilisons en général deux machines virtuelles. Pour la couche application SAP, qui peut être comprendre bien plus de deux machines virtuelles, vous devrez peut-être revenir à un autre modèle de déploiement (voir plus loin).
Votre motivation pour un déploiement sur les Zones de disponibilité Azure doit être que vous souhaitez vous protéger contre des problèmes d’infrastructure plus importants susceptibles d’affecter la disponibilité d’un ou plusieurs centres de donnée Azure, en plus de vous protéger contre la défaillance d’une machine virtuelle ou de réduire les temps d’arrêt liés aux mises à jour logicielles.
Comme autre fonctionnalité de déploiement de résilience, Azure a introduit des groupes de machines virtuelles identiques avec orchestration flexible pour les charges de travail SAP. Les groupes de machines virtuelles identiques fournissent un regroupement logique des machines virtuelles gérées par la plateforme. L’orchestration flexible du groupe de machines virtuelles identiques offre la possibilité de créer le groupe identique dans une région ou de l’étendre entre les zones de disponibilité. Lors de la création d’un groupe identique flexible au sein d’une région avec platformFaultDomainCount>1 (FD>1), les machines virtuelles déployées dans le groupe identique sont réparties sur un nombre spécifié de domaines d’erreur dans la même région. En revanche, la création d’un groupe identique flexible entre les zones de disponibilité avec platformFaultDomainCount=1 (FD=1) distribuerait les machines virtuelles entre différentes zones et le groupe identique distribuerait également les machines virtuelles entre différents domaines d’erreur au sein de chaque zone, dans le meilleur des cas. Pour la charge de travail SAP, seul un groupe identique flexible avec FD=1 est pris en charge. L’avantage d’utiliser des groupes identiques flexibles avec FD=1 pour le déploiement interzone au lieu du déploiement traditionnel de zone de disponibilité, est que les machines virtuelles déployées avec le groupe identique seraient réparties entre différents domaines d’erreur au sein de la zone de manière optimale. Pour plus d’informations, consultez le Guide de déploiement du groupe identique flexible pour les charges de travail SAP.
Considérations liées au déploiement dans des zones de disponibilité
Tenez compte des points suivants quand vous utilisez des zones de disponibilité :
- Pour plus d’informations sur les Zones de disponibilité Azure, consultez le document Régions et zones de disponibilité.
- La latence d’aller-retour expérimentée sur le réseau n’indique pas nécessairement la distance géographique réelle des centres de données qui constituent les différentes zones. La latence aller-retour réseau est également influencée par les connectivités par câbles et le routage des câbles entre ces différents centres de données.
- Si vous utilisez des Zones de disponibilité comme solution de récupération d’urgence à petite distance, gardez à l’esprit que nous avons connu des catastrophes naturelles provoquant des dommages considérables dans différentes régions du monde, y compris des dommages importants et étendus aux infrastructures électriques. Les distances entre différentes zones ne sont pas toujours suffisantes pour compenser des catastrophes naturelles de cette ampleur.
- La latence réseau entre les zones de disponibilité n’est pas le même dans toutes les régions Azure. Même dans une région Azure, les latences réseau entre les différentes zones peuvent varier. Bien que même dans le pire des cas, la réplication synchrone au niveau de la base de données basée sur la réplication système HANA ou SQL Server Always On fonctionne sans impact sur la scalabilité de la charge de travail.
- Pour déterminer où utiliser des zones de disponibilité, tenez compte de la latence réseau entre les zones. La latence réseau joue un rôle important dans deux domaines :
- La latence entre les deux instances de base de données qui ont besoin d’une réplication synchrone. En fonction des opérations réussies des plus grands systèmes NetWeaver et S/4HANA entre les zones avec des latences réseau supérieures (moins de 1,5 millisecondes), cette considération peut être négligé
- La différence de latence réseau entre une machine virtuelle exécutant une instance de dialogue SAP dans la même zone que l’instance de base de données active et une machine virtuelle similaire dans une autre zone. Quand cette différence augmente, l’influence qu’elle exerce sur la durée d’exécution des processus métier et des programmes de traitement par lots augmente également, selon qu’ils s’exécutent dans la zone de la base de données ou dans une autre zone (voir plus loin dans cet article).
- La latence réseau avec les Zones de disponibilité Azure, même dans les plus grandes zones, est suffisamment faible pour exécuter des processus métier SAP. Jusqu’à présent, nous n’avons vu que quelques cas exceptionnels où les clients avaient besoin de colocaliser la couche d’application SAP et la couche de base de données sous une seule branche centrale du réseau de centres de données.
Quand vous déployez des machines virtuelles Azure sur des zones de disponibilité et établissez des solutions de basculement au sein d’une même région Azure, certaines restrictions s’appliquent :
- Vous devez utiliser Azure Disques managés pour un déploiement sur des zones de disponibilité Azure.
- Le mappage des énumérations de zones aux zones physiques est fixe sur la base d’un abonnement Azure. Si vous utilisez différents abonnements pour déployer vos systèmes SAP, vous devez définir les zones idéales pour chaque abonnement. Si vous voulez comparer le mappage logique de vos différents abonnements, utilisez le script Avzone-Mapping.
- Vous ne pouvez pas déployer de groupes à haute disponibilité Azure au sein d’une zone de disponibilité Azure, sauf si vous utilisez un groupe de placements de proximité Azure. La façon dont vous pouvez déployer la couche de base de données SAP et les services centraux entre les zones et, en même temps, déployer la couche d’application SAP à l’aide de groupes à haute disponibilité tout en continuant à proposer une proximité des machines virtuelles est décrite dans l’article Groupes de placements de proximité Azure pour une latence réseau optimale avec les applications SAP. Si vous n’utilisez pas de groupes de placement de proximité Azure, vous devez choisir l’un ou l’autre comme framework de déploiement pour les machines virtuelles.
- Vous ne pouvez pas utiliser un équilibreur de charge de base Azure pour créer des solutions de cluster de basculement basées sur le clustering de basculement Windows Server ou Linux Pacemaker. Vous devez plutôt utiliser la référence SKU Standard Load Balancer Azure.
- Vous devez déployer la version zonale de la passerelle ExpressRoute, la passerelle VPN et des adresses IP publiques standard pour obtenir la protection zonale souhaitée.
Combinaison de zones de disponibilité idéale
Sauf si vous configurez l’affectation de processus métier avec des fonctionnalités SAP telles que les groupes d’ouverture de session, les groupes de serveurs RFC, les groupes de serveurs de traitement par lots et d’autres similaires, vous pouvez exécuter des processus métier dans les différentes instances d’application de votre couche d’application SAP. L’effet secondaire de ce fait est que les travaux par lots peuvent être exécutés par toutes les instances d’application SAP indépendamment de leur exécution dans la même zone avec l’instance de base de données active ou non. Si la différence de latence réseau entre les différentes zones est faible par rapport à la latence réseau au sein d’une zone, la différence dans les temps d’exécution des travaux par lots peut ne pas être significative. Toutefois, plus la différence de latence réseau dans une zone par rapport à l’ensemble du trafic réseau de la zone est importante, plus la durée d’exécution des programmes de traitement par lots peut être affectée si le travail a été exécuté dans une zone où l’instance de base de données n’est pas active. C’est à vous, en tant que client, de décider des différences acceptables au moment de l’exécution. Mais aussi de la latence réseau acceptable pour le trafic interzone compte tenu de votre charge de travail. Purement d’un point de vue technique, les latences réseau entre les Zones de disponibilité Azure au sein d’une région Azure fonctionnent pour l’architecture de NetWeaver, S/4HANA ou d’autres applications SAP. Il est également de votre responsabilité en tant que client d’atténuer potentiellement ces différences à l’aide des concepts SAP des groupes d’ouverture de session, des groupes de serveurs RFC, des groupes de serveurs de traitement par lots, et d’autres similaires, lorsque vous optez pour l’un des concepts de déploiement que nous introduisons dans cet article.
Si vous voulez déployer un système SAP NetWeaver ou S/4HANA sur plusieurs zones, vous avez le choix entre deux modèles d’architecture :
- Actif/actif : la paire de machines virtuelles exécutant ASCS/SCS et la paire de machines virtuelles exécutant la couche de base de données sont réparties sur deux zones. Les machines virtuelles exécutant la couche d’application SAP sont déployées en nombres pairs dans les deux mêmes zones. En cas de basculement d’une machine virtuelle de base de données ou ASCS/SCS, certaines des transactions ouvertes et actives peuvent être restaurées. Mais les utilisateurs restent connectés. Les zones dans lesquelles s’exécutent les machines virtuelles de base de données actives et les instances d’application n’ont pas vraiment d’importance. Cette architecture est l’architecture privilégiée pour le déploiement entre zones. Dans les cas où les latences réseau entre les zones provoquent des différences plus importantes lors de l’exécution de processus métier, vous pouvez utiliser des fonctionnalités telles que les groupes d’ouverture de session SAP, les groupes de serveurs RFC, les groupes de serveurs de traitement par lots, et d’autres similaires, pour acheminer l’exécution des processus métier vers des instances de boîte de dialogue spécifiques qui se trouvent dans la même zone avec l’instance de base de données active
- Actif/passif : la paire de machines virtuelles exécutant ASCS/SCS et la paire de machines virtuelles exécutant la couche de base de données sont réparties sur deux zones. Les machines virtuelles exécutant la couche d’application SAP sont déployées dans l’une des Zones de disponibilité. Vous exécutez la couche d’application dans la même zone que l’instance active ASCS/SCS et celle de base de données. Vous pouvez utiliser cette architecture de déploiement si vous estimez que la latence réseau entre les différentes zones est trop élevée. Cela provoque également des différences intolérables dans l’exécution de vos processus métier. Ou si vous souhaitez utiliser des déploiements de Zone de disponibilité en tant que déploiements de récupération d’urgence à courte distance. les zones. Si une machine virtuelle ASCS/SCS ou de base de données bascule sur la zone secondaire, vous risquez de rencontrer plus de latence réseau et une réduction du débit. Vous devez restaurer la machine virtuelle précédemment basculée dès que possible pour revenir aux niveaux de débit précédents. En cas de panne dans la zone, la couche application doit être basculée vers la zone secondaire. Activité à laquelle les utilisateurs sont confrontés lors de l’arrêt complet du système.
Donc, avant de déterminer comment utiliser des zones de disponibilité, identifiez ce qui suit :
- La latence réseau entre les trois zones d’une région Azure. Le fait de connaître la latence réseau entre les zones d’une région vous permet de choisir les zones présentant la latence réseau la plus faible dans le trafic réseau entre zones.
- La différence entre la latence de machine virtuelle à machine virtuelle au sein de l’une des zones de votre choix et la latence réseau entre deux zones de votre choix.
- La disponibilité des types de machine virtuelle que vous avez besoin de déployer dans les deux zones que vous avez sélectionnées. Avec certaines référence SKU VM, vous risquez de vous retrouver dans des situations où certaines références SKU sont disponibles uniquement dans deux des trois zones.
Latence réseau entre les zones et au sein des zones
Pour déterminer la latence entre les différentes zones, vous avez besoin d’effectuer les étapes suivantes :
- Déployer la référence SKU de la machine virtuelle à utiliser pour votre instance de base de données dans les trois zones. Assurez-vous que l’accélération réseau Azure est activée quand vous prenez cette mesure. Les performances réseau accélérées sont le paramètre par défaut depuis quelques années. Néanmoins, vérifiez si la fonctionnalité est activée et fonctionne
- Une fois que vous avez trouvé les deux zones avec la latence réseau la plus faible, déployez trois autres machines virtuelles de la référence SKU de machine virtuelle que vous voulez utiliser comme machine virtuelle de la couche Application sur les trois zones de disponibilité. Mesurez la latence réseau par rapport aux deux machines virtuelles de base de données dans les deux zones que vous avez sélectionnées.
- Utilisez
nipingcomme outil de mesure. Cet outil, fourni par SAP, est décrit dans les notes de support SAP #500235 et #1100926. Traitez la classification de la latence réseau dans la note SAP #1100926 comme des conseils approximatifs. Les latences réseau supérieures à 0,7 millisecondes ne signifient pas que le système ne fonctionnera pas techniquement ou que les processus métier ne satisfont pas à vos contrats SLA individuels. La note n’est pas destinée à indiquer ce qui est pris en charge ou non pris en charge par SAP et/ou Microsoft. Concentrez-vous sur les commandes SAP documentées pour les mesures de latence. Étant donné que ping ne fonctionne pas par les chemins de code d’accélération réseau Azure, nous vous recommandons de ne pas l’utiliser.
Vous n’avez pas besoin d’effectuer ces tests manuellement. La procédure PowerShell Test de latence de la zone de disponibilité permet d’automatiser les tests de latence décrits.
En fonction de vos mesures et de la disponibilité de vos références SKU de machine virtuelle dans les zones de disponibilité, vous devez prendre des décisions :
- Définissez les zones idéales pour la couche de base de données.
- En fonction des différences de latence réseau au sein d’une zone ou entre plusieurs zones, déterminez si vous voulez distribuer votre couche Application SAP active sur une, deux ou trois zones.
- Déterminez si vous voulez déployer une configuration active/passive ou une configuration active/active du point de vue de l’application. (Ces configurations sont expliquées plus loin dans cet article.)
Important
Les mesures et les décisions que vous prenez sont valides pour l’abonnement Azure que vous avez utilisé quand vous avez pris les mesures. Si vous utilisez un autre abonnement Azure, le mappage des zones énumérées peut être différent pour cet abonnement. Par conséquent, vous devez répéter les mesures ou rechercher le mappage du nouvel abonnement relatif à l’ancien abonnement en utilisant l’outil script Avzone-Mapping.
Important
Il est probable que les mesures décrites précédemment fournissent des résultats différents dans chaque région Azure qui prend en charge les Zones de disponibilité. Même si vos besoins en latence réseau ne changent pas, il peut être nécessaire d’adopter différentes stratégies de déploiement dans les différentes régions Azure, car la latence réseau entre les zones peut varier. Dans certaines régions Azure, la latence réseau entre les trois différentes zones peut varier considérablement. Dans d’autres régions, la latence réseau entre les trois différentes zones peut être plus uniforme. L’idée qu’il y a toujours une latence réseau entre 1 et 2 millisecondes est fausse. La latence réseau entre les zones de disponibilité dans les régions Azure ne peut pas être généralisée.
Déploiement actif/actif
Cette architecture de déploiement est appelée active/active, car vous déployez vos serveurs d’applications SAP actifs sur deux ou trois zones. L’instance SAP Central Services qui utilise la réplication de la mise en file d’attente est déployée entre deux zones. Ceci vaut également pour la couche de base de données, qui est déployée sur les mêmes zones que SAP Central Service. Quand vous envisagez cette configuration, vous devez rechercher les deux Zones de disponibilité dans votre région qui offrent une latence réseau interzone acceptable pour votre charge de travail. Vous devez également vous assurer que le delta entre la latence réseau au sein des zones que vous avez sélectionnées et la latence réseau interzone est acceptable pour votre charge de travail.
Voici un schéma simplifié d’un déploiement actif/actif sur deux zones :
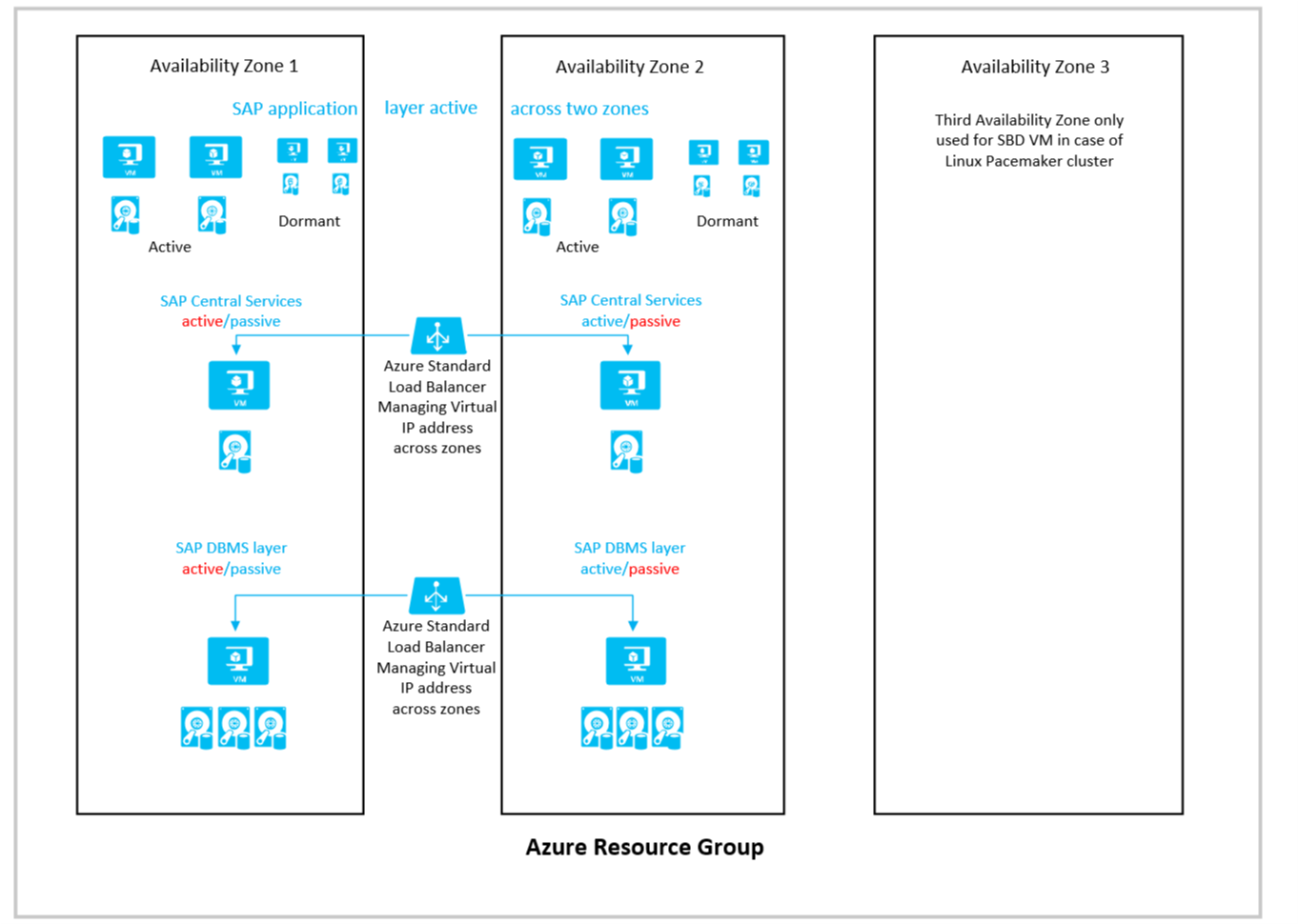
Les considérations suivantes s’appliquent pour cette configuration :
- Si vous n’utilisez pas de groupe de placement de proximité Azure, vous considérez les zones de disponibilité Azure comme des domaines d’erreur pour toutes les machines virtuelles, car les groupes à haute disponibilité ne peuvent pas être déployés dans des zones de disponibilité Azure.
- Si vous souhaitez combiner des déploiements zonaux pour la couche de base de données et les services centraux, mais que vous souhaitez utiliser des groupes à haute disponibilité Azure pour la couche d’application, vous devez utiliser des groupes de proximité Azure, comme décrit dans l’article Groupes de placements de proximité Azure pour une latence réseau optimale avec les applications SAP.
- Pour les équilibreurs de charge des clusters de basculement de SAP Central Services et la couche de base de données, vous devez utiliser le service Azure Load Balancer de la référence SKU Standard. Load Balancer au niveau Essentiel ne fonctionne pas entre les zones.
- Vous devez déployer la version zonale de la passerelle ExpressRoute, la passerelle VPN et des adresses IP publiques standard pour obtenir la protection zonale souhaitée.
- Le réseau virtuel Azure que vous avez déployé pour héberger le système SAP, ainsi que ses sous-réseaux, est réparti sur plusieurs zones. Vous n’avez pas besoin de réseaux virtuels et sous-réseaux distincts pour chaque zone.
- Pour toutes les machines virtuelles que vous déployez, vous devez utiliser Azure Disques managés. Les disques non managés ne sont pas pris en charge pour les déploiements sur des zones.
- SSD Premium Azure v2, le stockage SSD Ultra ou Azure NetApp Files ne prennent en charge aucune réplication de stockage synchrone dans les zones. Pour les déploiements de base de données, nous utilisons des méthodes de base de données pour répliquer les données entre les zones.
- SSD Premium v1 qui prend en charge la réplication zonale synchrone entre les Zones de disponibilité n’a pas été testé avec la charge de travail de base de données SAP. Par conséquent, la réplication synchrone zonale de SSD Premium Azure v1 doit être considérée comme non prise en charge pour les charges de travail de base de données SAP.
- Pour les partages SMB et NFS basés sur Azure Premium Files, une redondance zonale avec réplication synchrone est proposée. Consultez ce document pour connaître la disponibilité de ZRS pour Azure Premium Files dans la région de déploiement choisie. L’utilisation de partages NFS et SMB zonaux répliqués est entièrement prise en charge avec les déploiements de couche application SAP et les clusters de basculement à haute disponibilité pour les services centraux NetWeaver ou S/4HANA. Les documents qui couvrent ces cas sont les suivants :
- Haute disponibilité pour SAP NetWeaver sur les machines virtuelles Azure sur SUSE Linux Enterprise Server avec NFS sur Azure Files
- Haute disponibilité des machines virtuelles Azure pour SAP NetWeaver sur Red Hat Enterprise Linux avec Azure NetApp Files pour les applications SAP
- Haute disponibilité pour SAP NetWeaver sur des machines virtuelles Azure sous Windows avec Azure Files Premium SMB pour les applications SAP
- La troisième zone est utilisée pour héberger l’appareil SBD si vous créez un cluster SUSE Linux Pacemaker et si vous utilisez des appareils SBD au lieu de l’agent de délimitation Azure. Ou pour d’autres instances d’application.
- Pour obtenir la cohérence de temps d’exécution des processus métier critiques, vous pouvez essayer de diriger certains utilisateurs et travaux de traitement par lots vers des instances d’application qui se trouvent dans la même zone que l’instance de base de données active, à l’aide de groupes de serveurs de traitement par lots SAP, de groupes d’ouverture de session SAP ou de groupes RFC. Toutefois, dans le processus de basculement zonal, vous devez déplacer manuellement ces groupes vers les instances s’exécutant sur les machines virtuelles qui se trouvent dans la même zone que la machine virtuelle de base de données active.
- Vous pouvez éventuellement déployer des instances de dialogue dormantes dans chacune des zones.
Important
Dans ce scénario actif/actif, des frais pour le trafic interzone s’appliquent. Consultez le document Détails sur la tarification de la bande passante. Le transfert de données entre la couche d'application SAP et la couche de base de données SAP est assez intensif. Par conséquent, le scénario actif/actif peut contribuer aux coûts.
Déploiement actif/passif
Si vous ne trouvez pas de configuration qui atténue le delta potentiel lors de l’exécution des processus métier SAP ou si vous souhaitez déployer une configuration de récupération d’urgence à courte distance, vous pouvez déployer une architecture qui a un caractère actif/passif du point de vue de la couche d’application SAP. Vous définissez une zone active, à savoir la zone dans laquelle vous déployez la couche d’application complète et où vous essayez d’exécuter à la fois l’instance de base de données active et l’instance SAP Central Services. Avec une telle configuration, vous devez éviter les variations importantes au niveau du temps d’exécution des transactions métier et des programmes de traitement par lots, selon qu’un travail est exécuté dans la même zone que l’instance de base de données active.
La disposition de base de l’architecture ressemble à ceci :
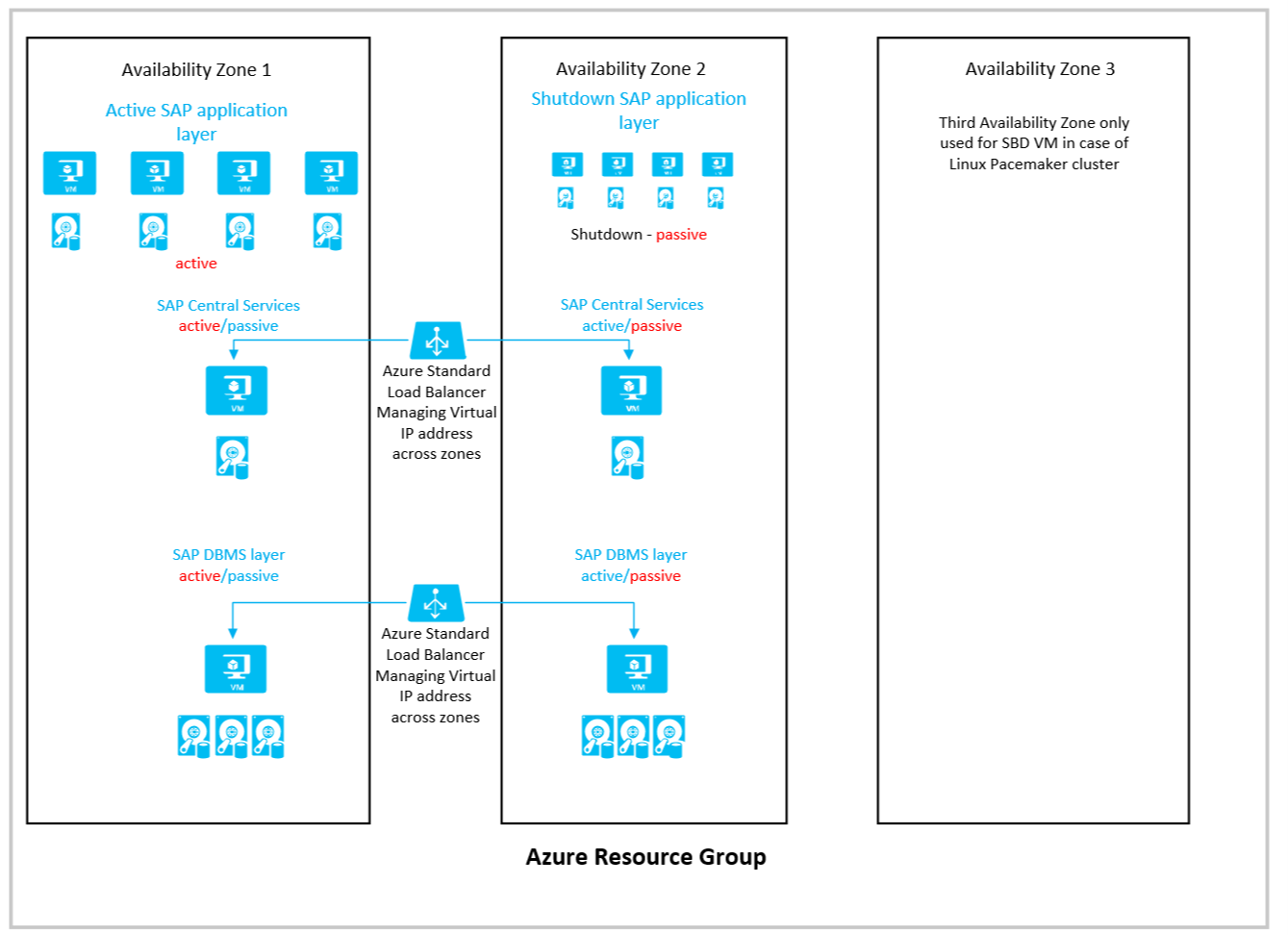
Les considérations suivantes s’appliquent pour cette configuration :
- Vous ne pouvez pas déployer des groupes à haute disponibilité dans des zones de disponibilité Azure. Pour compenser cela, vous pouvez utiliser des groupes de placement de proximité Azure, documentés dans l’article Groupes de placement de proximité Azure pour une latence réseau optimale avec les applications SAP.
- Quand vous utilisez cette architecture, vous devez superviser l’état attentivement et essayer de maintenir actives les instances de base de données et SAP Central Services dans la même zone que votre couche d’application déployée. En cas de basculement de l’instance de base de données ou SAP Central Service, vous devez basculer manuellement aussi vite que possible dans la zone qui a la couche d’application SAP déployée.
- Pour les équilibreurs de charge des clusters de basculement de SAP Central Services et la couche de base de données, vous devez utiliser le service Azure Load Balancer de la référence SKU Standard. Load Balancer au niveau Essentiel ne fonctionne pas entre les zones.
- Vous devez déployer la version zonale de la passerelle ExpressRoute, la passerelle VPN et des adresses IP publiques standard pour obtenir la protection zonale souhaitée.
- Le réseau virtuel Azure que vous avez déployé pour héberger le système SAP, ainsi que ses sous-réseaux, est réparti sur plusieurs zones. Vous n’avez pas besoin de réseaux virtuels distincts pour chaque zone.
- Pour toutes les machines virtuelles que vous déployez, vous devez utiliser Azure Disques managés. Les disques non managés ne sont pas pris en charge pour les déploiements sur des zones.
- SSD Premium Azure v2, le stockage SSD Ultra ou Azure NetApp Files ne prennent en charge aucune réplication de stockage synchrone dans les zones. Pour les déploiements de base de données, nous utilisons des méthodes de base de données pour répliquer les données entre les zones.
- SSD Premium v1 qui prend en charge la réplication zonale synchrone entre les Zones de disponibilité n’a pas été testé avec la charge de travail de base de données SAP. Par conséquent, la réplication synchrone zonale configurable de SSD Premium Azure v1 doit être considérée comme non prise en charge pour les charges de travail de base de données SAP.
- Pour les partages SMB et NFS basés sur Azure Premium Files, une redondance zonale avec réplication synchrone est proposée. Consultez ce document pour connaître la disponibilité de ZRS pour Azure Premium Files dans la région de déploiement choisie. L’utilisation de partages NFS et SMB zonaux répliqués est entièrement prise en charge avec les déploiements de couche application SAP et les clusters de basculement à haute disponibilité pour les services centraux NetWeaver ou S/4HANA. Les documents qui couvrent ces cas sont les suivants :
- Haute disponibilité pour SAP NetWeaver sur les machines virtuelles Azure sur SUSE Linux Enterprise Server avec NFS sur Azure Files
- Haute disponibilité des machines virtuelles Azure pour SAP NetWeaver sur Red Hat Enterprise Linux avec Azure NetApp Files pour les applications SAP
- Haute disponibilité pour SAP NetWeaver sur des machines virtuelles Azure sous Windows avec Azure Files Premium SMB pour les applications SAP
- La troisième zone est utilisée pour héberger l’appareil SBD si vous créez un cluster SUSE Linux Pacemaker et si vous utilisez des appareils SBD au lieu de l’agent de délimitation Azure. Ou pour d’autres instances de l’application.
- Vous devez déployer des machines virtuelles dormantes dans la zone passive (du point de vue de la base de données) pour être en mesure de démarrer les ressources de l’application en cas de défaillance d’une zone. Une autre possibilité est d’utiliser Azure Site Recovery, capable de répliquer des machines virtuelles actives sur des machines virtuelles dormantes entre différentes zones.
- Il est conseillé d’investir dans l’automatisation qui vous permet de démarrer automatiquement la couche Application SAP dans la deuxième zone en cas de défaillance d’une zone.
Configuration combinée de la haute disponibilité et de la reprise d’activité
Microsoft ne partage aucune information concernant la distance géographique qui existe entre les sites qui hébergent différentes zones de disponibilité Azure dans une région Azure. Pourtant, certains clients utilisent des zones pour obtenir une configuration de haute disponibilité et de récupération d’urgence (récupération d’urgence à courte distance) qui promet un objectif de point de récupération (RPO) de zéro. Un RPO de zéro signifie que vous ne devez perdre aucune transaction de base de données commitée, même en cas de reprise d’activité après sinistre.
Remarque
Si vous utilisez des Zones de disponibilité comme solution de récupération d’urgence à petite distance, n’oubliez pas que nous avons rencontré des catastrophes naturelles provoquant des dommages considérables dans différentes régions du monde, y compris des dommages importants et étendus aux infrastructures électriques. Les distances entre différentes zones ne sont pas toujours suffisantes pour compenser des catastrophes naturelles de cette ampleur.
Voici un exemple de la façon dont une telle configuration peut se présenter :

Les considérations suivantes s’appliquent pour cette configuration :
- Vous supposez qu’il existe une distance significative entre les installations hébergeant une Zone de disponibilité. Ou vous êtes obligé de rester dans une certaine région Azure. Vous ne pouvez pas déployer des groupes à haute disponibilité dans des zones de disponibilité Azure. Pour compenser cela, vous pouvez utiliser des groupes de placement de proximité Azure, tel que décrit dans l’article Groupes de placements de proximité Azure pour une latence réseau optimale avec les applications SAP.
- Quand vous utilisez cette architecture, vous devez superviser l’état attentivement et essayer de maintenir actives les instances de base de données et SAP Central Services dans la même zone que votre couche d’application déployée. En cas de basculement de l’instance de base de données ou SAP Central Service, vous devez basculer manuellement aussi vite que possible dans la zone qui a la couche d’application SAP déployée.
- Vous devez avoir des instances d’application de production préinstallées dans les machines virtuelles qui exécutent les instances d’application d’assurance qualité actives.
- En cas de défaillance d’une zone, vous arrêtez les instances d’application d’assurance qualité et vous démarrez à la place les instances de production. Vous devez utiliser les noms virtuels des instances d’application pour que cela fonctionne.
- Pour les équilibreurs de charge des clusters de basculement de SAP Central Services et la couche de base de données, vous devez utiliser le service Azure Load Balancer de la référence SKU Standard. Load Balancer au niveau Essentiel ne fonctionne pas entre les zones.
- Vous devez déployer la version zonale de la passerelle ExpressRoute, la passerelle VPN et des adresses IP publiques standard pour obtenir la protection zonale souhaitée.
- Le réseau virtuel Azure que vous avez déployé pour héberger le système SAP, ainsi que ses sous-réseaux, est réparti sur plusieurs zones. Vous n’avez pas besoin de réseaux virtuels distincts pour chaque zone.
- Pour toutes les machines virtuelles que vous déployez, vous devez utiliser Azure Disques managés. Les disques non managés ne sont pas pris en charge pour les déploiements sur des zones.
- SSD Premium Azure v2, le stockage SSD Ultra ou Azure NetApp Files ne prennent en charge aucune réplication de stockage synchrone dans les zones. Pour les déploiements de base de données, nous utilisons des méthodes de base de données pour répliquer les données entre les zones.
- SSD Premium v1 qui prend en charge la réplication zonale synchrone entre les Zones de disponibilité n’a pas été testé avec la charge de travail de base de données SAP. Par conséquent, la réplication synchrone zonale configurable de SSD Premium Azure v1 doit être considérée comme non prise en charge pour les charges de travail de base de données SAP.
- Pour les partages SMB et NFS basés sur Azure Premium Files, une redondance zonale avec réplication synchrone est proposée. Consultez ce document pour connaître la disponibilité de ZRS pour Azure Premium Files dans la région de déploiement choisie. L’utilisation de partages NFS et SMB zonaux répliqués est entièrement prise en charge avec les déploiements de couche application SAP et les clusters de basculement à haute disponibilité pour les services centraux NetWeaver ou S/4HANA. Les documents qui couvrent ces cas sont les suivants :
- Haute disponibilité pour SAP NetWeaver sur les machines virtuelles Azure sur SUSE Linux Enterprise Server avec NFS sur Azure Files
- Haute disponibilité des machines virtuelles Azure pour SAP NetWeaver sur Red Hat Enterprise Linux avec Azure NetApp Files pour les applications SAP
- Haute disponibilité pour SAP NetWeaver sur des machines virtuelles Azure sous Windows avec Azure Files Premium SMB pour les applications SAP
- La troisième zone est utilisée pour héberger l’appareil SBD si vous créez un cluster SUSE Linux Pacemaker et si vous utilisez des appareils SBD au lieu de l’agent de délimitation Azure.
Étapes suivantes
Voici certaines des étapes suivantes du déploiement sur des zones de disponibilité Azure :
- Mettre en cluster une instance SAP ASCS/SCS sur un cluster de basculement Windows à l’aide d’un disque partagé de cluster dans Azure
- Préparer une infrastructure Azure pour la haute disponibilité SAP à l’aide d’un cluster de basculement Windows et un partage de fichiers pour une instance SAP ASCS/SCS