Haute disponibilité pour SAP HANA sur des machines virtuelles Azure sur SUSE Linux Enterprise Server
Pour établir une haute disponibilité dans un déploiement SAP HANA local, vous pouvez utiliser la réplication du système SAP HANA ou le stockage partagé.
Actuellement sur des machines virtuelles Azure, la réplication du système SAP HANA sur Azure est la seule fonction de haute disponibilité prise en charge.
La réplication du système SAP HANA se compose d’un nœud principal et d’au moins un nœud secondaire. Les modifications apportées aux données sur le nœud principal sont répliquées vers les nœuds secondaires de manière synchrone ou asynchrone.
Cet article explique comment déployer et configurer les machines virtuelles, installer l’infrastructure de cluster et installer et configurer la réplication du système SAP HANA.
Avant de commencer, lisez les notes et documents SAP suivants :
- Note SAP 1928533. La note comprend les éléments suivants :
- La liste des tailles de machines virtuelles Azure prises en charge pour le déploiement de logiciels SAP.
- Des informations importantes sur la capacité en fonction de la taille des machines virtuelles Azure.
- Combinaisons de logiciels SAP, de système d’exploitation et de base de données SAP pris en charge.
- Versions requises du noyau SAP pour Windows et Linux sur Microsoft Azure.
- La note SAP 2015553 répertorie les conditions préalables au déploiement de logiciels SAP pris en charge par SAP sur Azure.
- La note SAP 2205917 recommande des paramètres de système d’exploitation pour SUSE Linux Enterprise Server 12 (SLES 12) pour les applications SAP.
- La note SAP 2684254 recommande des paramètres de système d’exploitation pour SUSE Linux Enterprise Server 15 (SLES 15) pour les applications SAP.
- La note 2235581 présente les systèmes d’exploitation pris en charge par SAP HANA
- La note SAP 2178632 contient des informations détaillées sur toutes les métriques de supervision signalées pour SAP dans Azure.
- La note SAP 2191498 a la version requise de l’agent hôte SAP pour Linux dans Azure.
- La note SAP 2243692 contient des informations sur les licences SAP pour Linux dans Azure.
- La note SAP 1984787 contient des informations sur SUSE Linux Enterprise Server 12.
- La note SAP 1999351 contient des informations supplémentaires sur le dépannage de l’extension Azure Enhanced Monitoring pour SAP.
- La note SAP 401162 contient des informations sur la façon d’éviter les erreurs d'« adresse déjà en cours d’utilisation » lorsque vous configurez la réplication du système HANA.
- Wiki de support de la communauté SAP contient toutes les notes SAP requises pour Linux.
- Plateformes IaaS certifiées SAP HANA.
- Guide Planification et implémentation de machines virtuelles Azure pour SAP sur Linux.
- Déploiement de machines virtuelles Azure pour SAP sur Linux guide.
- Guide de déploiement SGBD de machines virtuelles Azure pour SAP sur Linux.
- Guides des meilleures pratiques de SUSE Linux Enterprise Server pour SAP Applications 15 et Guides des meilleures pratiques de SUSE Linux Enterprise Server pour SAP Applications 12 :
- Configuration d’une infrastructure SAP HANA SR optimisée pour les performances (SLES pour les applications SAP). Le guide contient toutes les informations requises pour configurer la réplication du système SAP HANA pour le développement local. Utilisez ce guide comme référence.
- Configuration d’une infrastructure SAP HANA SR à coût optimisé (SLES pour les applications SAP).
Planifier la haute disponibilité DE SAP HANA
Pour obtenir une haute disponibilité, installez SAP HANA sur deux machines virtuelles. Les données sont répliquées à l’aide de la réplication du système HANA.
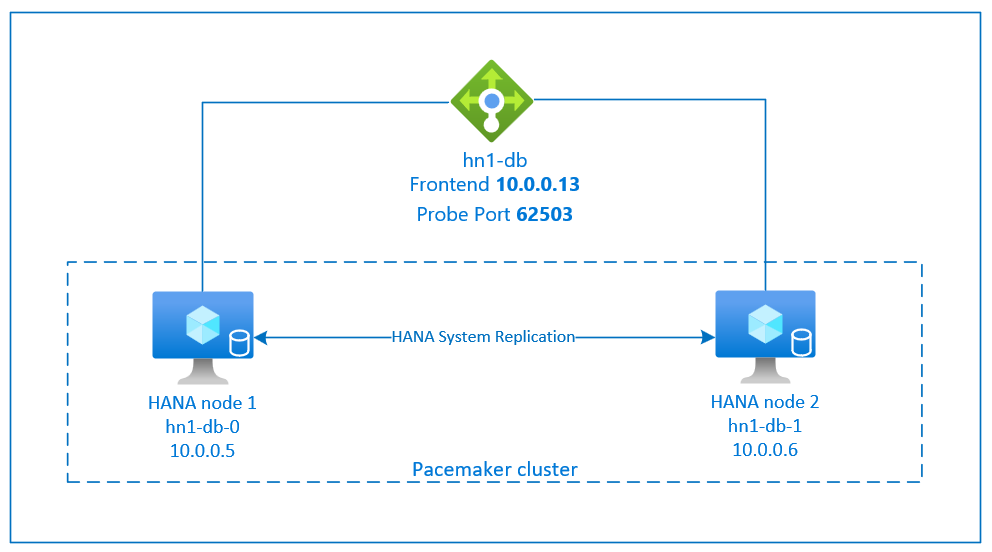
La configuration de la réplication du système SAP HANA utilise un nom d’hôte virtuel dédié et des adresses IP virtuelles. Dans Azure, vous avez besoin d’un équilibreur de charge pour déployer une adresse IP virtuelle.
La figure précédente montre un exemple d’équilibreur de charge qui a ces configurations :
- Adresse IP frontale : 10.0.0.13 pour HN1-db
- Port de la sonde : 62503
Préparer l’infrastructure
L’agent de ressource pour SAP HANA est inclus dans SUSE Linux Enterprise Server for SAP Applications. Une image pour SUSE Linux Enterprise Server for SAP Applications 12 ou 15 est disponible sur la Place de marché Azure. Vous pouvez utiliser l’image pour déployer de nouvelles machines virtuelles.
Déployer manuellement des machines virtuelles Linux via le portail Azure
Ce document part du principe que vous avez déjà déployé un groupe de ressources, un réseau virtuel Azure et un sous-réseau.
Déployez des machines virtuelles pour SAP HANA. Choisissez une image SLES appropriée prise en charge pour le système HANA. Vous pouvez déployer une machine virtuelle dans n’importe laquelle des options de disponibilité : groupe de machines virtuelles identiques, zone de disponibilité ou groupe à haute disponibilité.
Important
Assurez-vous que le système d’exploitation que vous sélectionnez est certifié SAP pour SAP HANA sur les types de machines virtuelles spécifiques que vous envisagez d’utiliser dans votre déploiement. Vous pouvez rechercher les types de machines virtuelles certifiées SAP HANA et leurs versions de système d’exploitation sur la page Plateformes IaaS certifiées SAP HANA. Veillez à consulter les détails du type de machine virtuelle pour obtenir la liste complète des versions de système d’exploitation prises en charge par SAP HANA pour le type de machine virtuelle spécifique.
Configurer l’équilibrage de charge Azure
Pendant la configuration de la machine virtuelle, vous avez la possibilité de créer ou de sélectionner un équilibreur de charge existant dans la section réseau. Suivez les étapes ci-dessous pour configurer l’équilibreur de charge standard pour la configuration de la haute disponibilité de la base de données HANA.
- Portail Azure
- Azure CLI
- PowerShell
Suivez les étapes dans Créer un équilibreur de charge pour configurer un équilibreur de charge standard pour un système SAP à haute disponibilité à l’aide du portail Azure. Pendant la configuration de l’équilibreur de charge, tenez compte des points suivants :
- Configuration d’une adresse IP front-end : créez une adresse IP front-end. Sélectionnez le même nom de réseau virtuel et de sous-réseau que vos machines virtuelles de base de données.
- Pool back-end : créez un pool back-end et ajoutez des machines virtuelles de base de données.
- Règles de trafic entrant : créez une règle d’équilibrage de charge. Suivez les mêmes étapes pour les deux règles d’équilibrage de charge.
- Adresse IP front-end : sélectionnez une adresse IP front-end.
- Pool back-end : sélectionnez un pool back-end.
- Ports haute disponibilité : sélectionnez cette option.
- Protocole : sélectionnez TCP.
- Sonde d’intégrité : créez une sonde d’intégrité avec les détails suivants :
- Protocole : sélectionnez TCP.
- Port : par exemple, 625<numéro-instance>.
- Intervalle : entrez 5.
- Seuil de sonde : entrez 2.
- Délai d'inactivité (minutes) : entrez 30.
- Activer l’adresse IP flottante : sélectionnez cette option.
Remarque
La propriété de configuration de la sonde d’intégrité numberOfProbes, également appelée Seuil de défaillance sur le plan de l’intégrité dans le portail, n’est pas respectée. Pour contrôler le nombre de sondes consécutives qui aboutissent ou qui échouent, définissez la propriété probeThreshold sur 2. Il n’est actuellement pas possible de définir cette propriété à l’aide du portail Azure. Utilisez donc l’interface Azure CLI ou la commande PowerShell.
Pour plus d’informations sur les ports requis pour SAP HANA, consultez le chapitre Connections to Tenant Databases (Connexions aux bases de données locataires) dans le guide SAP HANA Tenant Databases (Bases de données locataires SAP HANA) ou la Note SAP 2388694.
Remarque
Lorsque les machines virtuelles qui n’ont pas d’adresses IP publiques sont placées dans le pool principal d’une instance standard (aucune adresse IP publique) interne d’Azure Load Balancer, la configuration par défaut n’est pas une connectivité Internet sortante. Vous pouvez effectuer des étapes supplémentaires pour autoriser le routage vers des points de terminaison publics. Pour plus d’informations sur la façon d’obtenir une connectivité sortante, consultez connectivité de point de terminaison public pour les machines virtuelles à l’aide d’Azure Standard Load Balancer dans les scénarios de haute disponibilité SAP.
Important
- N’activez pas les horodatages TCP sur les machines virtuelles Azure placées derrière Azure Load Balancer. L’activation des horodateurs TCP provoque l’échec des sondes d’intégrité. Définissez le paramètre
net.ipv4.tcp_timestampssur0. Pour plus d’informations, consultez Sondes d’intégrité Load Balancer ou la note SAP 2382421. - Pour empêcher que saptune redéfinisse sur
1la valeurnet.ipv4.tcp_timestampsqui avait été définie manuellement sur0, mettez à jour saptune vers la version 3.1.1 ou ultérieure. Pour plus d’informations, consultez saptune 3.1.1 – Do I Need to Update?.
Créez un cluster Pacemaker
Suivez les étapes de Configurer Pacemaker sur SUSE Linux Enterprise Server dans Azure pour créer un cluster Pacemaker de base pour ce serveur HANA. Vous pouvez utiliser le même cluster Pacemaker pour SAP HANA et SAP NetWeaver (A)SCS.
Installer SAP HANA
Les étapes de cette section utilisent les préfixes suivants :
- [A] : l’étape s’applique à tous les nœuds.
- [1]: l’étape s’applique uniquement au nœud 1.
- [2]: l’étape s’applique uniquement au nœud 2 du cluster Pacemaker.
Remplacez <placeholders> par les valeurs de votre installation SAP HANA.
[A] Configuration de la disposition des disques à l’aide du gestionnaire de volumes logiques (LVM).
Nous recommandons d’utiliser LVM pour les volumes qui stockent des données et des fichiers journaux. L’exemple suivant suppose que les machines virtuelles ont quatre disques de données attachés utilisés pour créer deux volumes.
Exécutez cette commande pour répertorier tous les disques disponibles :
/dev/disk/azure/scsi1/lun*Exemple de sortie :
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3Créez des volumes physiques pour tous les disques que vous souhaitez utiliser :
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3Créez un groupe de volume pour les fichiers de données. Utilisez un groupe de volumes pour les fichiers journaux et un groupe de volumes pour le répertoire partagé de SAP HANA :
sudo vgcreate vg_hana_data_<HANA SID> /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_<HANA SID> /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_<HANA SID> /dev/disk/azure/scsi1/lun3Créez les volumes logiques.
Un volume linéaire est créé lorsque vous utilisez
lvcreatesans le commutateur-i. Nous vous suggérons de créer un volume agrégé par bandes pour améliorer les performances d’E/S. Alignez les tailles de bande sur les valeurs décrites dans configurations de stockage de machines virtuelles SAP HANA. L’argument-idoit être le nombre de volumes physiques sous-jacents, et l’argument-Iest la taille de bande.Par exemple, si deux volumes physiques sont utilisés pour le volume de données, l’argument
-icommutateur est défini sur 2, et la taille de bande du volume de données est 256Kio. Un volume physique étant utilisé pour le volume du fichier journal, aucun commutateur-iou-In’est utilisé explicitement pour les commandes de volume du fichier journal.Important
Lorsque vous utilisez plusieurs volumes physiques pour chaque volume de données, volume de journal ou volume partagé, utilisez le commutateur
-iet définissez-le comme nombre de volumes physiques sous-jacents. Lorsque vous créez un volume à bandes, utilisez le commutateur-Ipour spécifier la taille de bande.Pour connaître les configurations de stockage recommandées, notamment les tailles de bandes et le nombre de disques, consultez configurations de stockage de machines virtuelles SAP HANA.
sudo lvcreate <-i number of physical volumes> <-I stripe size for the data volume> -l 100%FREE -n hana_data vg_hana_data_<HANA SID> sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_<HANA SID> sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_<HANA SID> sudo mkfs.xfs /dev/vg_hana_data_<HANA SID>/hana_data sudo mkfs.xfs /dev/vg_hana_log_<HANA SID>/hana_log sudo mkfs.xfs /dev/vg_hana_shared_<HANA SID>/hana_sharedCréez les répertoires de montage et copiez l’identificateur universel unique (UUID) de tous les volumes logiques :
sudo mkdir -p /hana/data/<HANA SID> sudo mkdir -p /hana/log/<HANA SID> sudo mkdir -p /hana/shared/<HANA SID> # Write down the ID of /dev/vg_hana_data_<HANA SID>/hana_data, /dev/vg_hana_log_<HANA SID>/hana_log, and /dev/vg_hana_shared_<HANA SID>/hana_shared sudo blkidModifiez le fichier /etc/fstab pour créer des entrées
fstabpour les trois volumes logiques :sudo vi /etc/fstabInsérez les lignes suivantes dans le fichier /etc/fstab :
/dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_data_<HANA SID>-hana_data> /hana/data/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_log_<HANA SID>-hana_log> /hana/log/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_shared_<HANA SID>-hana_shared> /hana/shared/<HANA SID> xfs defaults,nofail 0 2Montez les nouveaux volumes :
sudo mount -a
[A] configurer la disposition du disque à l’aide de disques bruts.
Pour les systèmes de démonstration, vous pouvez placer vos données et fichiers journaux HANA sur un disque.
Créez une partition sur /dev/disk/azure/scsi1/lun0 et mettez-la en forme à l’aide de XFS :
sudo sh -c 'echo -e "n\n\n\n\n\nw\n" | fdisk /dev/disk/azure/scsi1/lun0' sudo mkfs.xfs /dev/disk/azure/scsi1/lun0-part1 # Write down the ID of /dev/disk/azure/scsi1/lun0-part1 sudo /sbin/blkid sudo vi /etc/fstabInsérez cette ligne dans le fichier /etc/fstab :
/dev/disk/by-uuid/<UUID> /hana xfs defaults,nofail 0 2Créez le répertoire cible et montez le disque :
sudo mkdir /hana sudo mount -a
[A] Configurez la résolution de nom d’hôte pour tous les hôtes.
Vous pouvez utiliser un serveur DNS ou modifier le fichier /etc/hosts sur tous les nœuds. Cet exemple montre comment utiliser le fichier /etc/hosts. Remplacez les adresses IP et les noms d’hôtes dans les commandes suivantes.
Modifiez le fichier /etc/hosts :
sudo vi /etc/hostsInsérez les lignes suivantes dans le fichier /etc/hosts. Modifiez les adresses IP et les noms d’hôte pour qu’ils correspondent à votre environnement.
10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] Installez les packages de haute disponibilité SAP HANA :
Exécutez la commande suivante pour installer les packages de haute disponibilité :
sudo zypper install SAPHanaSR
Pour installer la réplication du système SAP HANA, consultez le chapitre 4 du guide scénario optimisé pour les performances SAP HANA SR.
[A] Exécuter le programme hdblcm à partir du support d’installation HANA.
Lorsque vous y êtes invité, entrez les valeurs suivantes :
- Choose installation : tapez 1.
- Select additional components for installation : tapez 1.
- Entrez le chemin d’installation : entrez /hana/shared, puis sélectionnez Entrée.
- Entrez le nom d’hôte local : entrez .. et sélectionnez Entrée.
- Do you want to add additional hosts to the system? (y/n) : entrez n , puis sélectionnez Entrée.
- Entrez l’ID système SAP HANA : entrez votre SID HANA.
- Entrez le numéro d’instance : entrez le numéro d’instance HANA. Si vous avez déployé à l’aide du modèle Azure ou si vous avez suivi la section de déploiement manuel de cet article, entrez 03.
- Sélectionnez le mode de base de données / Entrez l’index : Entrez ou sélectionnez 1 , puis sélectionnez Entrée.
- Sélectionnez l’utilisation du système / Entrez l’index : sélectionnez la valeur d’utilisation du système 4.
- Entrez l’emplacement des volumes de données : entrez /hana/data/<HANA SID> , puis sélectionnez Entrée.
- Entrez l’emplacement des volumes de journal : entrez /hana/log/<HANA SID> , puis sélectionnez Entrée.
- Restreindre l’allocation maximale de mémoire : entrez n, puis sélectionnez Entrée.
- Entrez le nom d’hôte du certificat pour l’hôte : entrez ... , puis sélectionnez Entrée.
- Entrez le mot de passe de l’agent hôte SAP (sapadm) : entrez le mot de passe utilisateur de l’agent hôte, puis sélectionnez Entrée.
- Confirmez le mot de passe de l’utilisateur de l’agent hôte SAP (sapadm) : entrez à nouveau le mot de passe de l’agent hôte, puis sélectionnez Entrée.
- Entrez le mot de passe administrateur système (hdbadm) : entrez le mot de passe de l’administrateur système, puis sélectionnez Entrée.
- Confirmez le mot de passe administrateur système (hdbadm) : entrez à nouveau le mot de passe administrateur système, puis sélectionnez Entrée.
- Entrez le répertoire de base de l’administrateur système : entrez /usr/sap/<HANA SID>/home, puis sélectionnez Entrée.
- Entrez l’interpréteur de commandes de connexion administrateur système : entrez /bin/sh, puis sélectionnez Entrée.
- Entrez l’ID utilisateur de l’administrateur système : entrez 1001, puis sélectionnez Entrée.
- Entrez l’ID du groupe d’utilisateurs (sapsys) : entrez 79 , puis sélectionnez Entrée.
- Entrez le mot de passe de l’utilisateur de base de données (SYSTEM) : entrez le mot de passe de l’utilisateur de la base de données, puis sélectionnez Entrée.
- Confirmez le mot de passe de l’utilisateur de base de données (SYSTEM) : entrez à nouveau le mot de passe de l’utilisateur de la base de données, puis sélectionnez Entrée.
- Redémarrez le système après le redémarrage de l’ordinateur ? (y/n) : entrez n , puis sélectionnez Entrée.
- Do you want to continue? (y/n) : validez le récapitulatif. Tapez Y pour continuer.
[A] mettre à niveau l’agent hôte SAP.
Téléchargez la dernière archive de l’agent hôte SAP à partir du centre logiciel SAP. Pour mettre à niveau l’agent, exécutez la commande suivante. Remplacez le chemin d’accès à l’archive pour pointer vers le fichier que vous avez téléchargé.
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive <path to SAP host agent SAR>
Configurer la réplication de système SAP HANA 2.0
Les étapes de cette section utilisent les préfixes suivants :
- [A] : l’étape s’applique à tous les nœuds.
- [1]: l’étape s’applique uniquement au nœud 1.
- [2]: l’étape s’applique uniquement au nœud 2 du cluster Pacemaker.
Remplacez <placeholders> par les valeurs de votre installation SAP HANA.
[1] Créer une base de données locataire.
Si vous utilisez SAP HANA 2.0 ou SAP HANA MDC, créez une base de données de locataire pour votre système SAP NetWeaver.
Exécutez la commande suivante en tant que <SID HANA>adm :
hdbsql -u SYSTEM -p "<password>" -i <instance number> -d SYSTEMDB 'CREATE DATABASE <SAP SID> SYSTEM USER PASSWORD "<password>"'[1] configurer la réplication système sur le premier nœud :
Tout d’abord, sauvegardez les bases de données en tant que <HANA SID>adm :
hdbsql -d SYSTEMDB -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SYS>')" hdbsql -d <HANA SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for HANA SID>')" hdbsql -d <SAP SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SAP SID>')"Ensuite, copiez les fichiers d’infrastructure à clé publique système (PKI) sur le site secondaire :
scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/SSFS_<HANA SID>.DAT hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/ scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/SSFS_<HANA SID>.KEY hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/Créez le site principal :
hdbnsutil -sr_enable --name=<site 1>[2] configurer la réplication système sur le deuxième nœud :
Inscrivez le second nœud pour démarrer la réplication de système.
Exécutez la commande suivante en tant que <SID HANA>adm :
sapcontrol -nr <instance number> -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2>
Configurer la réplication système SAP HANA 1.0
Les étapes de cette section utilisent les préfixes suivants :
- [A] : l’étape s’applique à tous les nœuds.
- [1]: l’étape s’applique uniquement au nœud 1.
- [2]: l’étape s’applique uniquement au nœud 2 du cluster Pacemaker.
Remplacez <placeholders> par les valeurs de votre installation SAP HANA.
[1] Créez les utilisateurs requis.
Exécutez la commande suivante en tant que root :
PATH="$PATH:/usr/sap/<HANA SID>/HDB<instance number>/exe" hdbsql -u system -i <instance number> 'CREATE USER hdbhasync PASSWORD "<password>"' hdbsql -u system -i <instance number> 'GRANT DATA ADMIN TO hdbhasync' hdbsql -u system -i <instance number> 'ALTER USER hdbhasync DISABLE PASSWORD LIFETIME'[A] Créez l’entrée keystore.
Exécutez la commande suivante en tant que racine pour créer une nouvelle entrée de magasin de clés :
PATH="$PATH:/usr/sap/<HANA SID>/HDB<instance number>/exe" hdbuserstore SET hdbhaloc localhost:3<instance number>15 hdbhasync <password>[1] Sauvegardez la base de données.
Sauvegardez les bases de données en tant que racine :
PATH="$PATH:/usr/sap/<HANA SID>/HDB<instance number>/exe" hdbsql -d SYSTEMDB -u system -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file>')"Si vous utilisez une installation mutualisée, sauvegardez également la base de données locataire :
hdbsql -d <HANA SID> -u system -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file>')"[1] configurer la réplication système sur le premier nœud.
Créez le site principal en tant que <SID HANA>adm :
su - hdbadm hdbnsutil -sr_enable --name=<site 1>[2] configurer la réplication système sur le nœud secondaire.
Inscrivez le site secondaire en tant que <SID HANA>adm :
sapcontrol -nr <instance number> -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=<HANA SID>-db-<database 1> --remoteInstance=<instance number> --replicationMode=sync --name=<site 2>
Implémenter des hooks HANA – SAPHanaSR et susChkSrv
Dans cette étape importante, vous optimisez l’intégration au cluster et améliorez la détection lorsqu’un basculement de cluster est nécessaire. Nous vous recommandons vivement de configurer le hook Python SAPHanaSR. Pour HANA 2.0 SP5 et versions ultérieures, nous vous recommandons d’implémenter le hook SAPHanaSR et le hook susChkSrv.
Le hook susChkSrv étend les fonctionnalités du fournisseur de haute disponibilité SAPHanaSR principal. Il agit lorsque le processus HANA se bloque. Si un processus unique se bloque, HANA tente généralement de le redémarrer. Le redémarrage du processus indexserver peut prendre du temps, durant lequel la base de données HANA ne répond pas.
Avec susChkSrv implémenté, une action immédiate et configurable est exécutée. L’action déclenche un basculement dans la période d’expiration configurée au lieu d’attendre le redémarrage du processus hdbindexserver sur le même nœud.
[A] Installer le hook de réplication du système HANA. Le hook doit être installé sur les deux nœuds de base de données HANA.
Conseil
Le hook Python SAPHanaSR peut être implémenté uniquement pour HANA 2.0. Le package SAPHanaSR doit être au moins version 0.153.
Le hook Python susChkSrv nécessite SAP HANA 2.0 SP5 et la version SAPHanaSR 0.161.1_BF ou ultérieure doivent être installés.
Arrêter HANA sur les deux nœuds.
Exécutez le code suivant comme <sapsid>adm :
sapcontrol -nr <instance number> -function StopSystemAjustez global.ini sur chaque nœud de cluster. Si les conditions requises pour le hook susChkSrv ne sont pas remplies, supprimez l’intégralité du bloc
[ha_dr_provider_suschksrv]des paramètres suivants.Vous pouvez ajuster le comportement de
susChkSrvà l’aide du paramètreaction_on_lost. Les valeurs valides sont [ignore|stop|kill|fence].# add to global.ini [ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR execution_order = 3 action_on_lost = fence [trace] ha_dr_saphanasr = infoSi vous pointez vers l’emplacement standard /usr/share/SAPHanaSR, le code de hook Python est mis à jour automatiquement par le biais des mises à jour du système d’exploitation ou des mises à jour de package. HANA utilise les mises à jour du code de hook lors du redémarrage suivant. Avec un chemin d’accès facultatif tel que /hana/shared/myHooks, vous pouvez dissocier les mises à jour du système d’exploitation à partir de la version de hook que vous utilisez.
[A] Le cluster nécessite une configurationsudoers sur chaque nœud de cluster pour <SID SAP>adm. Dans cet exemple, cela est obtenu en créant un fichier.
Exécutez la commande suivante en tant que root :
cat << EOF > /etc/sudoers.d/20-saphana # Needed for SAPHanaSR and susChkSrv Python hooks hn1adm ALL=(ALL) NOPASSWD: /usr/sbin/crm_attribute -n hana_hn1_site_srHook_* hn1adm ALL=(ALL) NOPASSWD: /usr/sbin/SAPHanaSR-hookHelper --sid=HN1 --case=fenceMe EOFPour plus d’informations sur l’implémentation du hook de réplication du système SAP HANA, consultez Configurer des fournisseurs de haute disponibilité/récupération d’urgence HANA.
[A] Démarrez SAP HANA sur les deux nœuds.
Exécutez la commande suivante en tant que <SAP SID>adm :
sapcontrol -nr <instance number> -function StartSystem[1] Vérifiez l’installation de hook.
Exécutez la commande suivante en tant que <SAP SID>adm sur le site de réplication système HANA actif :
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example output # 2021-04-08 22:18:15.877583 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:18:46.531564 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:21:26.816573 ha_dr_SAPHanaSR SOKVérifiez l’installation du hook susChkSrv.
Exécutez la commande suivante en tant que <SAP SID>adm sur toutes les machines virtuelles HANA :
cdtrace egrep '(LOST:|STOP:|START:|DOWN:|init|load|fail)' nameserver_suschksrv.trc # Example output # 2022-11-03 18:06:21.116728 susChkSrv.init() version 0.7.7, parameter info: action_on_lost=fence stop_timeout=20 kill_signal=9 # 2022-11-03 18:06:27.613588 START: indexserver event looks like graceful tenant start # 2022-11-03 18:07:56.143766 START: indexserver event looks like graceful tenant start (indexserver started)
Créer les ressources de cluster SAP HANA
Tout d’abord, créez la topologie HANA.
Exécutez les commandes suivantes sur l’un des nœuds du cluster Pacemaker :
sudo crm configure property maintenance-mode=true
# Replace <placeholders> with your instance number and HANA system ID
sudo crm configure primitive rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> ocf:suse:SAPHanaTopology \
operations \$id="rsc_sap2_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10" timeout="600" \
op start interval="0" timeout="600" \
op stop interval="0" timeout="300" \
params SID="<HANA SID>" InstanceNumber="<instance number>"
sudo crm configure clone cln_SAPHanaTopology_<HANA SID>_HDB<instance number> rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> \
meta clone-node-max="1" target-role="Started" interleave="true"
Ensuite, créez les ressources HANA :
Important
Au cours des tests récents, netcat cesse de répondre aux demandes en raison d’un backlog et en raison de sa limitation de la gestion d’une seule connexion. La ressource netcat cesse d’écouter les requêtes Azure Load Balancer, et l’adresse IP flottante devient indisponible.
Pour les clusters Pacemaker existants, nous vous recommandons précédemment de remplacer netcat par socat. Actuellement, nous vous recommandons d’utiliser l’agent de ressources azure-lb, qui fait partie d’un package de resource-agents. Les versions de package suivantes sont requises :
- Pour SLES 12 SP4/SP5, la version minimum est resource-agents-4.3.018.a7fb5035-3.30.1.
- Pour SLES 15/15 SP1, la version minimum est resource-agents-4.3.0184.6ee15eb2-4.13.1.
Effectuer cette modification nécessite un bref temps d’arrêt.
Pour les clusters Pacemaker existants, si votre configuration a déjà été modifiée pour utiliser socat comme décrit dans Azure Load Balancer Detection Hardening , vous n’avez pas besoin de basculer immédiatement vers l’agent de ressources azure-lb.
Remarque
Cet article contient des références à des termes que Microsoft n’utilise plus. Lorsque ces termes seront supprimés du logiciel, nous les supprimerons de cet article.
# Replace <placeholders> with your instance number, HANA system ID, and the front-end IP address of the Azure load balancer.
sudo crm configure primitive rsc_SAPHana_<HANA SID>_HDB<instance number> ocf:suse:SAPHana \
operations \$id="rsc_sap_<HANA SID>_HDB<instance number>-operations" \
op start interval="0" timeout="3600" \
op stop interval="0" timeout="3600" \
op promote interval="0" timeout="3600" \
op monitor interval="60" role="Master" timeout="700" \
op monitor interval="61" role="Slave" timeout="700" \
params SID="<HANA SID>" InstanceNumber="<instance number>" PREFER_SITE_TAKEOVER="true" \
DUPLICATE_PRIMARY_TIMEOUT="7200" AUTOMATED_REGISTER="false"
sudo crm configure ms msl_SAPHana_<HANA SID>_HDB<instance number> rsc_SAPHana_<HANA SID>_HDB<instance number> \
meta notify="true" clone-max="2" clone-node-max="1" \
target-role="Started" interleave="true"
sudo crm resource meta msl_SAPHana_<HANA SID>_HDB<instance number> set priority 100
sudo crm configure primitive rsc_ip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_ip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<front-end IP address>"
sudo crm configure primitive rsc_nc_<HANA SID>_HDB<instance number> azure-lb port=625<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
sudo crm configure group g_ip_<HANA SID>_HDB<instance number> rsc_ip_<HANA SID>_HDB<instance number> rsc_nc_<HANA SID>_HDB<instance number>
sudo crm configure colocation col_saphana_ip_<HANA SID>_HDB<instance number> 4000: g_ip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Master
sudo crm configure order ord_SAPHana_<HANA SID>_HDB<instance number> Optional: cln_SAPHanaTopology_<HANA SID>_HDB<instance number> \
msl_SAPHana_<HANA SID>_HDB<instance number>
# Clean up the HANA resources. The HANA resources might have failed because of a known issue.
sudo crm resource cleanup rsc_SAPHana_<HANA SID>_HDB<instance number>
sudo crm configure property priority-fencing-delay=30
sudo crm configure property maintenance-mode=false
sudo crm configure rsc_defaults resource-stickiness=1000
sudo crm configure rsc_defaults migration-threshold=5000
Important
Nous vous recommandons de définir AUTOMATED_REGISTER sur false uniquement lorsque vous effectuez des tests de basculement complets, afin d’empêcher l’inscription automatique d’une instance principale en tant qu’instance principale ayant échoué. Une fois les tests de basculement terminés, définissez AUTOMATED_REGISTER sur true, de sorte qu’après la prise en charge, la réplication système reprend automatiquement.
Vérifiez que l’état du cluster est OK et que toutes les ressources ont démarré. Il n’importe pas le nœud sur lequel les ressources s’exécutent.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
Configurer la réplication système active/en lecture HANA dans un cluster Pacemaker
Dans SAP HANA 2.0 SPS 01 et versions ultérieures, SAP autorise une configuration active/en lecture pour la réplication du système SAP HANA. Dans ce scénario, les systèmes secondaires de la réplication de système SAP HANA peuvent être utilisés activement pour les charges de travail gourmandes en lecture.
Pour prendre en charge cette configuration dans un cluster, une deuxième adresse IP virtuelle est requise pour permettre aux clients d’accéder à la base de données SAP HANA en lecture secondaire. Pour vous assurer que le site de réplication secondaire est toujours accessible après une prise de contrôle, le cluster doit déplacer l’adresse IP virtuelle avec la ressource SAPHana secondaire.
Cette section décrit les étapes supplémentaires requises pour gérer une réplication système active/lecture HANA dans un cluster haute disponibilité SUSE qui utilise une deuxième adresse IP virtuelle.
Avant de continuer, vérifiez que vous avez entièrement configuré le cluster de haute disponibilité SUSE qui gère la base de données SAP HANA, comme décrit dans les sections précédentes.
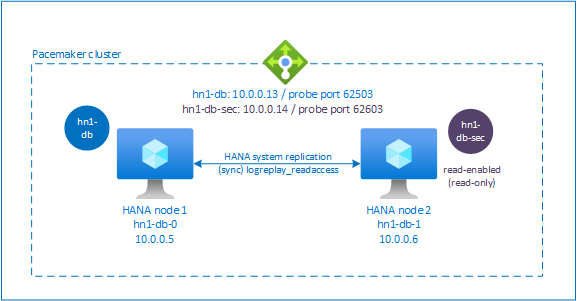
Configurer l’équilibreur de charge pour la réplication système active/en lecture
Pour suivre des étapes supplémentaires pour provisionner la deuxième adresse IP virtuelle, vérifiez que vous avez configuré Azure Load Balancer comme décrit dans Déployer manuellement des machines virtuelles Linux via le portail Azure.
Pour l’équilibreur de charge standard, effectuez ces étapes supplémentaires sur le même équilibreur de charge que celui que vous avez créé précédemment.
- Créez un deuxième pool d’adresses IP frontales :
- Ouvrez l’équilibrage de charge, sélectionnez le Pool d’adresses IP frontales, puis cliquez sur Ajouter.
- Entrez le nom du deuxième pool d’adresses IP frontales (par exemple hana-secondaryIP).
- Définissez l’Affectation sur Statique et entrez l’adresse IP (par exemple, 10.0.0.14).
- Cliquez sur OK.
- Une fois le nouveau pool d’adresses IP frontales créé, notez l’adresse IP frontale.
- Créez une sonde d’intégrité :
- Dans l’équilibreur de charge, sélectionnez sondes d’intégrité, puis sélectionnez Ajouter.
- Entrez le nom de la nouvelle sonde d’intégrité (par exemple, hana-secondaryhp).
- Sélectionnez TCP en tant que protocole et port 626<numéro d’instance>. Conservez la valeur Intervalle définie sur 5et la valeur seuil non sain définie sur 2.
- Cliquez sur OK.
- Créez les règles d’équilibrage de charge :
- Dans l’équilibreur de charge, sélectionnez règles d’équilibrage de charge, puis sélectionnez Ajouter.
- Entrez le nom de la nouvelle règle d’équilibrage de charge (par exemple, hana-secondarylb).
- Sélectionnez l’adresse IP frontale, le pool principal et la sonde d’intégrité que vous avez créés (par exemple,hana-secondaryIP, hana-backend et hana-secondaryhp).
- Sélectionnez Ports HA.
- Augmenter le délai d’inactivité à 30 minutes.
- Assurez-vous que vous activer l'IP flottante.
- Cliquez sur OK.
Configurer la réplication système active/en lecture HANA
Les étapes de configuration de la réplication du système HANA sont décrites dans Configurer la réplication système SAP HANA 2.0. Si vous déployez un scénario secondaire en lecture, lorsque vous configurez la réplication système sur le deuxième nœud, exécutez la commande suivante en tant que <SID HANA>adm :
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> --operationMode=logreplay_readaccess
Ajouter une ressource d’adresse IP virtuelle secondaire
Vous pouvez configurer la deuxième adresse IP virtuelle et la contrainte de colocation appropriée à l’aide des commandes suivantes :
crm configure property maintenance-mode=true
crm configure primitive rsc_secip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_secip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<secondary IP address>"
crm configure primitive rsc_secnc_<HANA SID>_HDB<instance number> azure-lb port=626<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
crm configure group g_secip_<HANA SID>_HDB<instance number> rsc_secip_<HANA SID>_HDB<instance number> rsc_secnc_<HANA SID>_HDB<instance number>
crm configure colocation col_saphana_secip_<HANA SID>_HDB<instance number> 4000: g_secip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Slave
crm configure property maintenance-mode=false
Vérifiez que l’état du cluster est OK et que toutes les ressources ont démarré. La deuxième adresse IP virtuelle s’exécute sur le site secondaire avec la ressource secondaire SAPHana.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# Resource Group: g_secip_HN1_HDB03:
# rsc_secip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
# rsc_secnc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
La section suivante décrit l’ensemble classique de tests de basculement à exécuter.
Considérations relatives au test d’un cluster HANA configuré avec une base de données secondaire activée en lecture :
Lorsque vous migrez la ressource de cluster
SAPHana_<HANA SID>_HDB<instance number>vershn1-db-1, la deuxième adresse IP virtuelle passe àhn1-db-0. Si vous avez configuréAUTOMATED_REGISTER="false"et que la réplication du système HANA n’est pas enregistrée automatiquement, la deuxième adresse IP virtuelle s’exécute surhn1-db-0, car le serveur est disponible et les services de cluster sont en ligne.Lorsque vous testez un incident de serveur, les deuxièmes ressources IP virtuelles (
rsc_secip_<HANA SID>_HDB<instance number>) et la ressource de port d’équilibreur de charge Azure (rsc_secnc_<HANA SID>_HDB<instance number>) s’exécutent sur le serveur principal en même temps que les ressources d’adresse IP virtuelle principale. Pendant que le serveur secondaire est arrêté, les applications connectées à une base de données HANA en lecture se connectent à la base de données HANA principale. Le comportement est attendu, car vous ne souhaitez pas que les applications connectées à une base de données HANA compatible en lecture soient inaccessibles pendant que le serveur secondaire n’est pas disponible.Lorsque le serveur secondaire est disponible et que les services de cluster sont en ligne, les deuxièmes ressources d’adresse IP virtuelle et de port se déplacent automatiquement vers le serveur secondaire, même si la réplication du système HANA peut ne pas être inscrite en tant que serveur secondaire. Veillez à inscrire la base de données HANA secondaire en lecture activée avant de démarrer les services de cluster sur ce serveur. Vous pouvez configurer la ressource de cluster d’instance HANA pour inscrire automatiquement le serveur secondaire en définissant le paramètre
AUTOMATED_REGISTER="true".Pendant le basculement et le secours, les connexions existantes pour les applications, qui utilisent ensuite la deuxième adresse IP virtuelle pour se connecter à la base de données HANA, peuvent être interrompues.
Tester la configuration du cluster
Cette section explique comment vous pouvez tester votre configuration. Chaque test suppose que vous êtes connecté en tant que racine et que le maître SAP HANA s’exécute sur la machine virtuelle hn1-db-0.
Tester la migration
Avant de démarrer le test, assurez-vous que Pacemaker n’a pas d’action ayant échoué (exécuter crm_mon -r), qu’il n’existe aucune contrainte d’emplacement inattendue (par exemple, les restes d’un test de migration) et que HANA est en état de synchronisation, par exemple en exécutant SAPHanaSR-showAttr.
hn1-db-0:~ # SAPHanaSR-showAttr
Sites srHook
----------------
SITE2 SOK
Global cib-time
--------------------------------
global Mon Aug 13 11:26:04 2018
Hosts clone_state lpa_hn1_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
hn1-db-0 PROMOTED 1534159564 online logreplay nws-hana-vm-1 4:P:master1:master:worker:master 150 SITE1 sync PRIM 2.00.030.00.1522209842 nws-hana-vm-0
hn1-db-1 DEMOTED 30 online logreplay nws-hana-vm-0 4:S:master1:master:worker:master 100 SITE2 sync SOK 2.00.030.00.1522209842 nws-hana-vm-1
Vous pouvez migrer le nœud maître SAP HANA en exécutant la commande suivante :
crm resource move msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1 force
Le cluster ferait migrer le nœud principal SAP HANA et le groupe qui contient l’adresse IP virtuelle vers hn1-db-1.
Une fois la migration terminée, la sortie crm_mon -r ressemble à cet exemple :
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Failed Actions:
* rsc_SAPHana_HN1_HDB03_start_0 on hn1-db-0 'not running' (7): call=84, status=complete, exitreason='none',
last-rc-change='Mon Aug 13 11:31:37 2018', queued=0ms, exec=2095ms
Avec AUTOMATED_REGISTER="false", le cluster ne redémarre pas la base de données HANA ayant échoué et ne l’inscrit pas auprès du nouveau serveur principal sur hn1-db-0. Dans ce cas, configurez l’instance HANA comme secondaire en exécutant cette commande :
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> sapcontrol -nr <instance number> -function StopWait 600 10
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
La migration crée des contraintes d’emplacement qui doivent être de nouveau supprimées :
# Switch back to root and clean up the failed state
exit
hn1-db-0:~ # crm resource clear msl_SAPHana_<HANA SID>_HDB<instance number>
Vous devez également nettoyer l’état de la ressource du nœud secondaire :
hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
Surveillez l’état de la ressource HANA à l’aide de crm_mon -r. Lorsque HANA est démarré sur hn1-db-0, la sortie ressemble à cet exemple :
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Blocage de la communication réseau
État des ressources avant le début du test :
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Exécutez une règle de pare-feu pour bloquer la communication sur l’un des nœuds.
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
Lorsque les nœuds de cluster ne peuvent pas communiquer entre eux, il existe un risque de scénario fractionné-cerveau. Dans de telles situations, les nœuds de cluster essaient de se clôturer simultanément, ce qui entraîne une course de clôture.
Lors de la configuration d’un appareil d’escrime, il est recommandé de configurer pcmk_delay_max propriété. Ainsi, dans le cas d'un scénario de cerveau divisé, le cluster introduit un délai aléatoire jusqu'à la valeur pcmk_delay_max, à l'action de clôture sur chaque nœud. Le nœud avec le délai le plus court est sélectionné pour l’escrime.
En outre, pour vous assurer que le nœud exécutant le maître HANA est prioritaire et gagne la course de clôture dans un scénario de fractionnement du cerveau, il est recommandé de définir priority-fencing-delay propriété dans la configuration du cluster. En activant la propriété priority-fencing-delay, le cluster peut introduire un délai supplémentaire dans l’action d’escrime spécifiquement sur le nœud hébergeant la ressource principale HANA, ce qui permet au nœud de gagner la course de clôture.
Exécutez la commande ci-dessous pour supprimer la règle de pare-feu.
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
Tester l’isolation SBD
Vous pouvez tester la configuration de SBD en tuant le processus d’inquisitor :
hn1-db-0:~ # ps aux | grep sbd
root 1912 0.0 0.0 85420 11740 ? SL 12:25 0:00 sbd: inquisitor
root 1929 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014056f268462316e4681b704a9f73 - slot: 0 - uuid: 7b862dba-e7f7-4800-92ed-f76a4e3978c8
root 1930 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014059bc9ea4e4bac4b18808299aaf - slot: 0 - uuid: 5813ee04-b75c-482e-805e-3b1e22ba16cd
root 1931 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-36001405b8dddd44eb3647908def6621c - slot: 0 - uuid: 986ed8f8-947d-4396-8aec-b933b75e904c
root 1932 0.0 0.0 90524 16656 ? SL 12:25 0:00 sbd: watcher: Pacemaker
root 1933 0.0 0.0 102708 28260 ? SL 12:25 0:00 sbd: watcher: Cluster
root 13877 0.0 0.0 9292 1572 pts/0 S+ 12:27 0:00 grep sbd
hn1-db-0:~ # kill -9 1912
Le nœud de cluster <HANA SID>-db-<database 1> redémarre. Le service Pacemaker peut ne pas redémarrer. Assurez-vous que vous la recommencez.
Tester un basculement manuel
Vous pouvez tester un basculement manuel en arrêtant le service Pacemaker sur le nœud hn1-db-0 :
service pacemaker stop
Après le basculement, vous pouvez démarrer de nouveau le service. Si vous définissez AUTOMATED_REGISTER="false", la ressource SAP HANA sur le nœud hn1-db-0 ne parvient pas à démarrer comme secondaire.
Dans ce cas, configurez l’instance HANA comme secondaire en exécutant cette commande :
service pacemaker start
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
# Switch back to root and clean up the failed state
exit
crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
Tests SUSE
Important
Assurez-vous que le système d’exploitation que vous sélectionnez est certifié SAP pour SAP HANA sur les types de machines virtuelles spécifiques que vous envisagez d’utiliser. Vous pouvez rechercher les types de machines virtuelles certifiées SAP HANA et leurs versions de système d’exploitation sur la page Plateformes IaaS certifiées SAP HANA. Vérifiez que vous examinez les détails du type de machine virtuelle que vous envisagez d’utiliser pour obtenir la liste complète des versions de système d’exploitation prises en charge par SAP HANA pour ce type de machine virtuelle.
Exécutez tous les cas de test répertoriés dans le guide du scénario optimisé pour les performances SAP HANA SR ou dans le guide du scénario optimisé pour les coûts SAP HANA SR, en fonction de votre scénario. Vous trouverez les guides répertoriés dans SLES pour les meilleures pratiques SAP.
Les tests suivants sont une copie des tests décrits dans le guide « SAP HANA SR Performance Optimized Scenario SUSE Linux Enterprise Server for SAP Applications 12 SP1 » (Scénario à performances optimisées de réplication système de SAP HANA SUSE Linux Enterprise Server for SAP Applications 12 SP1). Pour une version à jour, lisez également le guide lui-même. Vérifiez toujours que HANA est synchronisé avant de démarrer le test et vérifiez que la configuration Pacemaker est correcte.
Dans les descriptions de test suivantes, nous supposons PREFER_SITE_TAKEOVER="true" et AUTOMATED_REGISTER="false".
Remarque
Les tests suivants sont conçus pour être exécutés en séquence. Chaque test dépend de l’état de sortie du test précédent.
Test 1 : Arrêtez la base de données primaire sur le nœud 1.
État de la ressource avant de commencer le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Exécutez les commandes suivantes en tant que <hana sid>adm sur le nœud
hn1-db-0:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB stopPacemaker détecte l’instance HANA arrêtée et bascule vers l’autre nœud. Une fois le basculement terminé, l’instance HANA sur le nœud
hn1-db-0est arrêtée, car Pacemaker n’inscrit pas automatiquement le nœud en tant que nœud secondaire HANA.Exécutez les commandes suivantes pour inscrire le nœud
hn1-db-0en tant que nœud secondaire et nettoyer la ressource ayant échoué :hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0État de la ressource après le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 2 : Arrêtez la base de données primaire sur le nœud 2.
État de la ressource avant de commencer le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Exécutez les commandes suivantes en tant que <hana sid>adm sur le nœud
hn1-db-1:hn1adm@hn1-db-1:/usr/sap/HN1/HDB01> HDB stopPacemaker détecte l’instance HANA arrêtée et bascule vers l’autre nœud. Une fois le basculement terminé, l’instance HANA sur le nœud
hn1-db-1est arrêtée, car Pacemaker n’inscrit pas automatiquement le nœud en tant que nœud secondaire HANA.Exécutez les commandes suivantes pour inscrire le nœud
hn1-db-1en tant que nœud secondaire et nettoyer la ressource ayant échoué :hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1État de la ressource après le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 3 : Plantez la base de données primaire sur le nœud 1.
État de la ressource avant de commencer le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Exécutez les commandes suivantes en tant que <hana sid>adm sur le nœud
hn1-db-0:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker détecte l’instance HANA tuée et bascule vers l’autre nœud. Une fois le basculement terminé, l’instance HANA sur le nœud
hn1-db-0est arrêtée, car Pacemaker n’inscrit pas automatiquement le nœud en tant que nœud secondaire HANA.Exécutez les commandes suivantes pour inscrire le nœud
hn1-db-0en tant que nœud secondaire et nettoyer la ressource ayant échoué :hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0État de la ressource après le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 4 : Plantez la base de données primaire sur le nœud 2.
État de la ressource avant de commencer le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Exécutez les commandes suivantes en tant que <hana sid>adm sur le nœud
hn1-db-1:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker détecte l’instance HANA tuée et bascule vers l’autre nœud. Une fois le basculement terminé, l’instance HANA sur le nœud
hn1-db-1est arrêtée, car Pacemaker n’inscrit pas automatiquement le nœud en tant que nœud secondaire HANA.Exécutez les commandes suivantes pour inscrire le nœud
hn1-db-1en tant que nœud secondaire et nettoyer la ressource ayant échoué.hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1État de la ressource après le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 5 : Plantez le nœud de site principal (nœud 1).
État de la ressource avant de commencer le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Exécutez les commandes suivantes en tant que racine sur le nœud
hn1-db-0:hn1-db-0:~ # echo 'b' > /proc/sysrq-triggerPacemaker détecte le nœud de cluster tué et clôture le nœud. Lorsque le nœud est clôturé, Pacemaker déclenche une prise de contrôle de l’instance HANA. Lorsque le nœud délimité est redémarré, Pacemaker ne démarre pas automatiquement.
Exécutez les commandes suivantes pour démarrer Pacemaker, nettoyez les messages SBD du nœud
hn1-db-0, inscrivez le nœudhn1-db-0en tant que nœud secondaire et nettoyez la ressource ayant échoué :# run as root # list the SBD device(s) hn1-db-0:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-0:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-0 clear hn1-db-0:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0État de la ressource après le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 6 : Plantez le nœud de site secondaire (nœud 2).
État de la ressource avant de commencer le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Exécutez les commandes suivantes en tant que racine sur le nœud
hn1-db-1:hn1-db-1:~ # echo 'b' > /proc/sysrq-triggerPacemaker détecte le nœud de cluster tué et clôture le nœud. Lorsque le nœud est clôturé, Pacemaker déclenche une prise de contrôle de l’instance HANA. Lorsque le nœud délimité est redémarré, Pacemaker ne démarre pas automatiquement.
Exécutez les commandes suivantes pour démarrer Pacemaker, nettoyez les messages SBD du nœud
hn1-db-1, inscrivez le nœudhn1-db-1en tant que nœud secondaire et nettoyez la ressource ayant échoué :# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1État de la ressource après le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0 </code></pre>Test 7 : Arrêtez la base de données secondaire sur le nœud 2.
État de la ressource avant de commencer le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Exécutez les commandes suivantes en tant que <hana sid>adm sur le nœud
hn1-db-1:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB stopPacemaker détecte l’instance HANA arrêtée et marque la ressource comme ayant échoué sur le nœud
hn1-db-1. Pacemaker redémarre automatiquement l’instance HANA.Exécutez la commande suivante pour nettoyer l’état d’échec :
# run as root hn1-db-1>:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1État de la ressource après le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 8 : Plantez la base de données secondaire sur le nœud 2.
État de la ressource avant de commencer le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Exécutez les commandes suivantes en tant que <hana sid>adm sur le nœud
hn1-db-1:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker détecte l’instance HANA tuée et marque la ressource comme ayant échoué sur le nœud
hn1-db-1. Exécutez la commande suivante pour nettoyer l’état d’échec. Pacemaker redémarre ensuite automatiquement l’instance HANA.# run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> HN1-db-1État de la ressource après le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 9 : Plantez le nœud de site secondaire (nœud 2) qui exécute la base de données HANA secondaire.
État de la ressource avant de commencer le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Exécutez les commandes suivantes en tant que racine sur le nœud
hn1-db-1:hn1-db-1:~ # echo b > /proc/sysrq-triggerPacemaker détecte le nœud de cluster tué et la clôture du nœud. Lorsque le nœud délimité est redémarré, Pacemaker ne démarre pas automatiquement.
Exécutez les commandes suivantes pour démarrer Pacemaker, nettoyez les messages SBD du nœud
hn1-db-1et nettoyez la ressource ayant échoué :# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1État de la ressource après le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 10 : Planter le serveur d’index de base de données primaire
Ce test s’applique uniquement lorsque vous avez configuré le hook susChkSrv comme indiqué dans Implémenter des crochets HANA SAPHanaSR et susChkSrv.
État de la ressource avant de commencer le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Exécutez les commandes suivantes en tant que racine sur le nœud
hn1-db-0:hn1-db-0:~ # killall -9 hdbindexserverLorsque le serveur d’index est arrêté, le hook susChkSrv détecte l’événement et déclenche une action pour clôturer le nœud « hn1-db-0 » et lancer un processus de prise de contrôle.
Exécutez les commandes suivantes pour inscrire le nœud
hn1-db-0en tant que nœud secondaire et nettoyer la ressource ayant échoué :# run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0État de la ressource après le test :
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Vous pouvez exécuter un cas de test comparable en provoquant le blocage du serveur d’index sur le nœud secondaire. En cas d’incident de serveur d’index, le hook susChkSrv reconnaît l’occurrence et lance une action pour clôturer le nœud secondaire.
Étapes suivantes
Commentaires
Prochainement : Tout au long de l'année 2024, nous supprimerons progressivement les GitHub Issues en tant que mécanisme de retour d'information pour le contenu et nous les remplacerons par un nouveau système de retour d'information. Pour plus d’informations, voir: https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour