Langage de requête Kusto dans Microsoft Sentinel
Le langage de requête Kusto est le langage que vous utiliserez pour travailler avec les données et les manipuler dans Microsoft Sentinel. Les journaux que vous alimentez dans votre espace de travail ne valent pas grand chose si vous ne pouvez pas les analyser et obtenir les informations importantes cachées dans toutes ces données. Le langage de requête Kusto a non seulement la puissance et la flexibilité nécessaires pour obtenir ces informations, mais aussi la simplicité permettant de le prendre en main rapidement. Si vous avez de l’expérience en matière de script ou d’utilisation de bases de données, une grande partie du contenu de cet article vous semblera très familier. Si ce n’est pas le cas, ne vous inquiétez pas, car la nature intuitive du langage vous permet rapidement de commencer à écrire vos propres requêtes et à créer de la valeur pour votre organisation.
Cet article présente les principes de base du langage de requête Kusto, couvrant certains des opérateurs et des fonctions les plus utilisés, ce qui devrait répondre à 75 à 80 % des requêtes que vous écrirez au jour le jour. Lorsque vous aurez besoin d’aller plus loin ou pour exécuter des requêtes plus avancées, vous pourrez tirer parti du nouveau classeur KQL avancé pour Microsoft Sentinel (voir ce billet de blog d’introduction). Consultez également la documentation officielle du langage de requête Kusto, ainsi qu’une variété de cours en ligne (tels que celui de Pluralsight).
Contexte : Pourquoi le langage de requête Kusto ?
Microsoft Sentinel s’appuie sur le service Azure Monitor et utilise les espaces de travail Log Analytics d’Azure Monitor pour stocker toutes ses données. Ces données incluent les éléments suivants :
- données ingérées de sources externes dans des tables prédéfinies à l’aide de connecteurs de données Microsoft Sentinel.
- données ingérées de sources externes dans des tables personnalisées définies par l’utilisateur, à l’aide de connecteurs de données personnalisés et de certains types de connecteurs prêts à l’emploi.
- données créées par Microsoft Sentinel proprement dit, résultant des analyses qu’il crée et effectue (par exemple, les alertes, les incidents et les informations liées à UEBA).
- données chargées sur Microsoft Sentinel pour faciliter la détection et l’analyse (par exemple, les flux de renseignements sur les menaces et les watchlists).
Le langage de requête Kusto a été développé dans le cadre du service Azure Data Explorer. Il est donc optimisé pour la recherche dans les magasins de Big Data dans un environnement cloud. Inspiré du célèbre explorateur sous-marin Jacques Cousteau (dont il tire son nom), il est conçu pour vous aider à plonger dans vos océans de données et à en explorer les trésors cachés.
Le langage de requête Kusto est également utilisé dans Azure Monitor (et par conséquent dans Microsoft Sentinel), y compris certaines fonctionnalités supplémentaires d’Azure Monitor, pour vous permettre de récupérer, visualiser et analyser les données dans les magasins de données Log Analytics. Dans Microsoft Sentinel, vous utilisez des outils basés sur le langage de requête Kusto chaque fois que vous visualisez et analysez des données et que vous repérez des menaces, que ce soit dans des règles et des classeurs existants ou en créant les vôtres.
Étant donné que le langage de requête Kusto fait partie de presque tout ce que vous faites dans Microsoft Sentinel, une bonne compréhension de son fonctionnement vous aidera à tirer le maximum de votre SIEM.
Qu’est-ce qu’une requête ?
Une requête en langage de requête Kusto est une requête en lecture seule qui permet de traiter des données et de renvoyer des résultats : elle n’écrit aucune donnée. Les requêtes opèrent sur des données qui sont organisées dans une hiérarchie de bases de données, de tables et de colonnes, comme en SQL.
Les requêtes sont formulées en langage clair et utilisent un modèle de flux de données conçu pour faciliter la lecture, l’écriture et l’automatisation de la syntaxe. Nous allons voir cela en détail.
Les requêtes en langage de requête Kusto sont constituées d’instructions séparées par des points-virgules. Il existe de nombreux types d’instructions, mais nous aborderons ici seulement deux types largement utilisés :
Les instructions d’expression tabulaire sont ce que nous entendons généralement lorsque nous parlons de requêtes : elles constituent le corps réel de la requête. Ce qu’il faut savoir sur les expressions tabulaires, c’est qu’elles acceptent une entrée tabulaire (une table ou une autre expression tabulaire) et produisent une sortie tabulaire. Au moins l’un de ces éléments est requis. La majeure partie du reste de cet article traitera de ce type d’instruction.
Les instructions let vous permettent de créer et de définir des variables et des constantes en dehors du corps de la requête, afin d’en faciliter la lecture et la polyvalence. Elles sont facultatives et dépendent de vos besoins particuliers. Nous aborderons ce type d’instruction à la fin de l’article.
Environnement de démonstration
Vous pouvez vous exercer aux instructions du langage de requête Kusto, y compris celles de cet article, dans un environnement de démonstration Log Analytics dans le portail Azure. L’utilisation de cet environnement d’entraînement est gratuite, mais vous devez disposer d’un compte Azure pour y accéder.
Explorez l’environnement de démonstration. Comme Log Analytics dans votre environnement de production, il peut être utilisé de plusieurs façons :
Choisissez une table sur laquelle générer une requête. À partir de l’onglet Tables par défaut (affiché dans le rectangle rouge en haut à gauche), sélectionnez une table dans la liste des tables regroupées par rubriques (affichées en bas à gauche). Développez les rubriques pour afficher les différentes tables, et vous pouvez développer davantage chaque table pour voir tous ses champs (colonnes). Double-cliquez sur une table ou sur un nom de champ pour l’ajouter dans la fenêtre de requête à l’endroit où se trouve le curseur. Tapez le reste de votre requête après le nom de la table, comme indiqué ci-dessous.
Recherchez une requête existante à étudier ou à modifier. Sélectionnez l’onglet Requêtes (affiché dans le rectangle rouge en haut à gauche) pour afficher la liste des requêtes prêtes à l’emploi. Vous pouvez également sélectionner l’option Requêtes dans la barre de boutons située en haut à droite. Vous pouvez explorer les requêtes prêtes à l’emploi fournies avec Microsoft Sentinel. Double-cliquez sur une requête pour ajouter la requête entière dans la fenêtre de requête à l’endroit où se trouve le curseur.
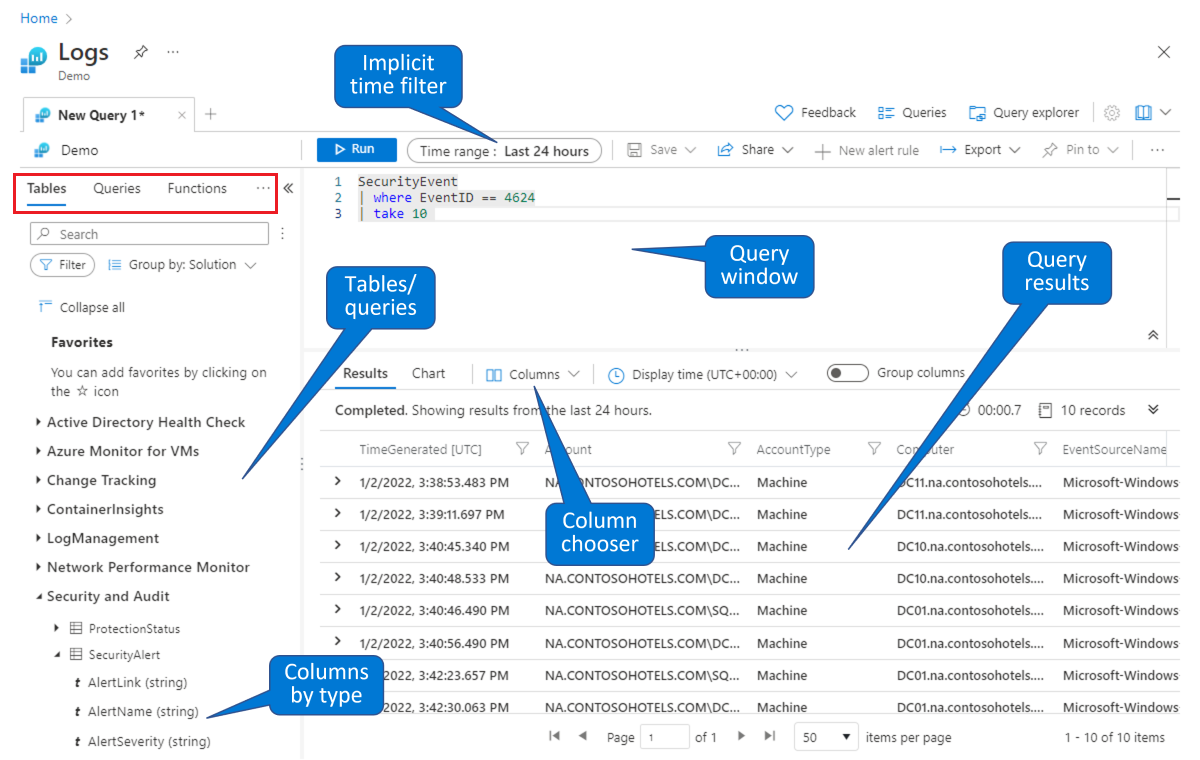
Comme dans cet environnement de démonstration, vous pouvez interroger et filtrer les données dans la page Journaux de Microsoft Sentinel. Vous pouvez sélectionner une table et descendre dans la hiérarchie pour voir les colonnes. Vous pouvez modifier les colonnes par défaut affichées à l’aide du sélecteur de colonnes, et vous pouvez définir l’intervalle de temps par défaut pour les requêtes. Si l’intervalle de temps est défini explicitement dans la requête, le filtre temporel ne sera pas disponible (grisé).
Structure de la requête
Un bon point de départ pour apprendre le langage de requête Kusto est de comprendre la structure globale d’une requête. La première chose que vous remarquerez en regardant une requête Kusto est l’utilisation du symbole de barre verticale (|). La structure d’une requête Kusto commence par l’obtention de vos données à partir d’une source de données, puis la transmission des données dans un « pipeline ». Chaque étape fournit un certain niveau de traitement, puis transmet les données à l’étape suivante. À la fin du pipeline, vous obtiendrez le résultat final. En réalité, voici notre pipeline :
Get Data | Filter | Summarize | Sort | Select
Ce concept de transmission des données dans le pipeline constitue une structure très intuitive, car il est facile de se faire une idée mentale de vos données à chaque étape.
Pour illustrer cela, jetons un coup d’œil à la requête suivante, qui porte sur les journaux de connexion de Microsoft Entra. Au fur et à mesure que vous lisez chaque ligne, vous pouvez voir les mots clés qui indiquent ce qui arrive aux données. Nous avons inclus l’étape pertinente dans le pipeline sous la forme d’un commentaire dans chaque ligne.
Notes
Vous pouvez ajouter des commentaires à n’importe quelle ligne d’une requête en les faisant précéder d’une double barre oblique (//).
SigninLogs // Get data
| evaluate bag_unpack(LocationDetails) // Ignore this line for now; we'll come back to it at the end.
| where RiskLevelDuringSignIn == 'none' // Filter
and TimeGenerated >= ago(7d) // Filter
| summarize Count = count() by city // Summarize
| sort by Count desc // Sort
| take 5 // Select
Comme la sortie de chaque étape sert d’entrée à l’étape suivante, l’ordre des étapes peut déterminer les résultats de la requête et avoir une incidence sur ses performances. Il est essentiel de classer les étapes en fonction de ce que vous souhaitez obtenir de la requête.
Conseil
- Une bonne règle de base consiste à filtrer vos données dès le début, afin de ne transmettre que les données pertinentes dans le pipeline. Cela permet d’améliorer considérablement les performances et de ne pas inclure accidentellement des données non pertinentes dans les étapes de résumé.
- Cet article met en avant les autres meilleures pratiques à garder à l’esprit. Pour obtenir une liste plus complète, consultez Meilleures pratiques relatives aux requêtes.
Nous espérons que vous avez maintenant une idée de la structure globale d’une requête en langage de requête Kusto. Examinons à présent les opérateurs de requête eux-mêmes, qui sont utilisés pour créer une requête.
Types de données
Avant d’aborder les opérateurs de requête, commençons par examiner rapidement les types de données. Comme dans la plupart des langages, le type de données détermine les calculs et les manipulations qui peuvent être effectués sur une valeur. Par exemple, si vous avez une valeur de type chaîne, vous ne pourrez pas effectuer de calculs arithmétiques sur cette valeur.
Dans le langage de requête Kusto, la plupart des types de données suivent des conventions standard et ont des noms que vous avez probablement déjà vus. Le tableau suivant montre la liste complète :
Tableau des types de données
| Type | Nom(s) supplémentaire(s) | Type .NET équivalent |
|---|---|---|
bool |
Boolean |
System.Boolean |
datetime |
Date |
System.DateTime |
dynamic |
System.Object |
|
guid |
uuid, uniqueid |
System.Guid |
int |
System.Int32 |
|
long |
System.Int64 |
|
real |
Double |
System.Double |
string |
System.String |
|
timespan |
Time |
System.TimeSpan |
decimal |
System.Data.SqlTypes.SqlDecimal |
Si la plupart des types de données sont standard, vous êtes peut-être moins familier des types comme dynamic, timespan et guid.
Dynamic a une structure très similaire à JSON, mais avec une différence essentielle : il peut stocker des types de données spécifiques au langage de requête Kusto que le JSON traditionnel ne peut pas stocker, comme une valeur dynamic imbriquée ou timespan. Voici un exemple de type « dynamic » :
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
Timespan est un type de données qui fait référence à une mesure de temps telle que des heures, des jours ou des secondes. Ne confondez pas timespan et datetime, qui correspond à une date et une heure réelles, et non à une mesure de temps. Le tableau suivant présente une liste de suffixes de timespan.
Suffixes de timespan
| Fonction | Description |
|---|---|
D |
jours |
H |
heures |
M |
minutes |
S |
secondes |
Ms |
millisecondes |
Microsecond |
microsecondes |
Tick |
nanosecondes |
Guid est un type de données représentant un identificateur unique au niveau mondial de 128 bits, qui suit le format standard [8]-[4]-[4]-[4]-[12], où chaque [nombre] représente le nombre de caractères et chaque caractère peut aller de 0 à 9 ou de a à f.
Notes
Le langage de requête Kusto possède à la fois des opérateurs tabulaires et scalaires. Dans le reste de cet article, si vous voyez simplement le mot « opérateur », vous pouvez supposer qu’il s’agit d’un opérateur tabulaire, sauf indication contraire.
Obtenir, limiter, trier et filtrer des données
Le vocabulaire de base du langage de requête Kusto (la fondation qui vous permettra d’accomplir l’écrasante majorité de vos tâches) est une collection d’opérateurs permettant de filtrer, trier et sélectionner vos données. Les autres tâches que vous aurez à accomplir vous obligeront à étendre vos connaissances du langage pour répondre à vos besoins plus avancés. Développons un peu plus certaines des commandes que nous avons utilisées dans notre exemple ci-dessus et examinons les commandes take, sort et where.
Pour chacun de ces opérateurs, nous examinerons son utilisation dans notre exemple SigninLogs précédent, et nous découvrirons une astuce utile ou une meilleure pratique.
Obtention de données
La première ligne de toute requête de base spécifie la table avec laquelle vous voulez travailler. Dans le cas de Microsoft Sentinel, il s’agit probablement du nom d’un type de journal dans votre espace de travail, tel que SigninLogs, SecurityAlert ou CommonSecurityLog. Par exemple :
SigninLogs
Notez que, dans le langage de requête Kusto, les noms de journaux respectent la casse, SigninLogs et signinLogs seront donc interprétés différemment. Faites attention lorsque vous choisissez les noms de vos journaux personnalisés afin qu’ils soient facilement identifiables et ne ressemblent pas trop à un autre journal.
Limitation des données : take / limit
L’opérateur take (et l’opérateur limit identique) est utilisé pour limiter les résultats en ne renvoyant qu’un nombre donné de lignes. Il est suivi d’un nombre entier qui spécifie le nombre de lignes à renvoyer. En règle générale, il est utilisé à la fin d’une requête, après avoir déterminé l’ordre de tri. Dans ce cas, il renvoie le nombre de lignes indiqué en haut de l’ordre de tri.
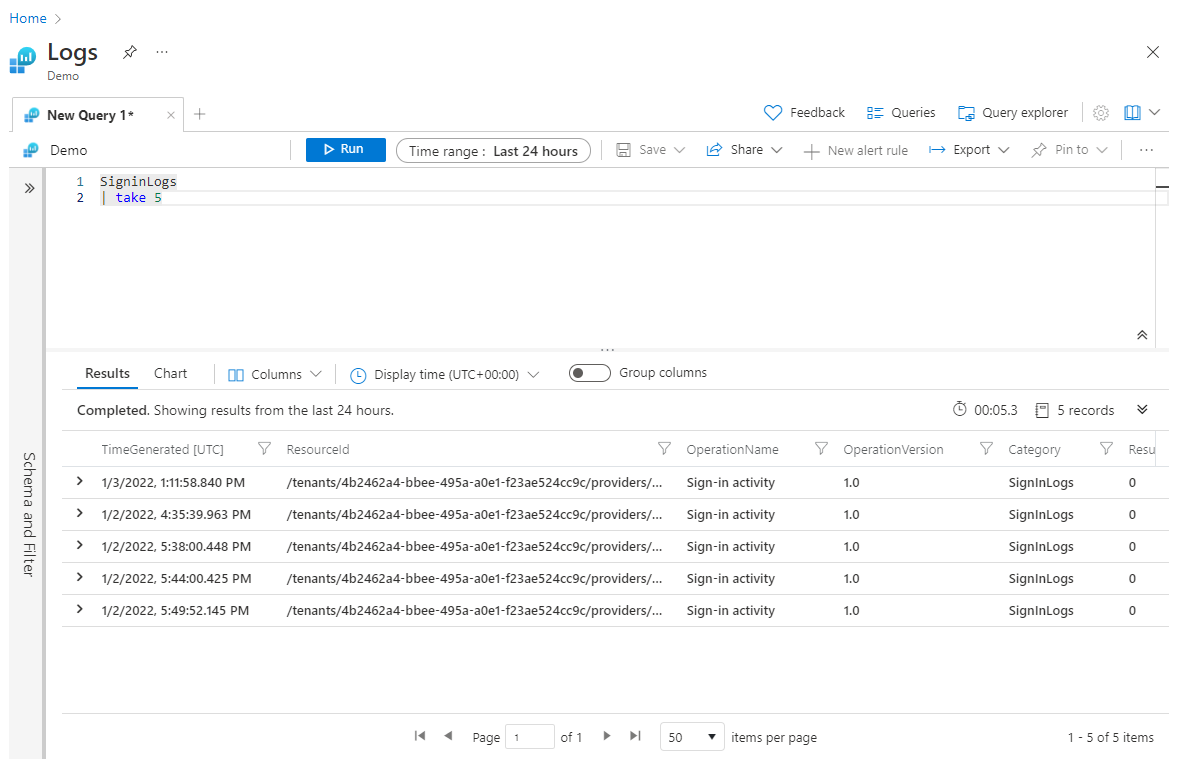
L’utilisation de take plus tôt dans la requête peut être utile pour tester une requête, lorsque vous ne souhaitez pas renvoyer de grands jeux de données. Toutefois, si vous placez l’opération take avant toute opération sort, take renverra des lignes sélectionnées de manière aléatoire, et peut-être un ensemble de lignes différent à chaque exécution de la requête. Voici un exemple d’utilisation de take :
SigninLogs
| take 5
Conseil
Lorsque vous travaillez sur une toute nouvelle requête et que vous ne savez pas à quoi elle ressemblera, il peut être utile de placer une instruction take au début afin de limiter artificiellement votre jeu de données et accélérer le traitement et l’expérimentation. Une fois que vous êtes satisfait de la requête complète, vous pouvez supprimer l’étape take initiale.
Tri des données : sort / order
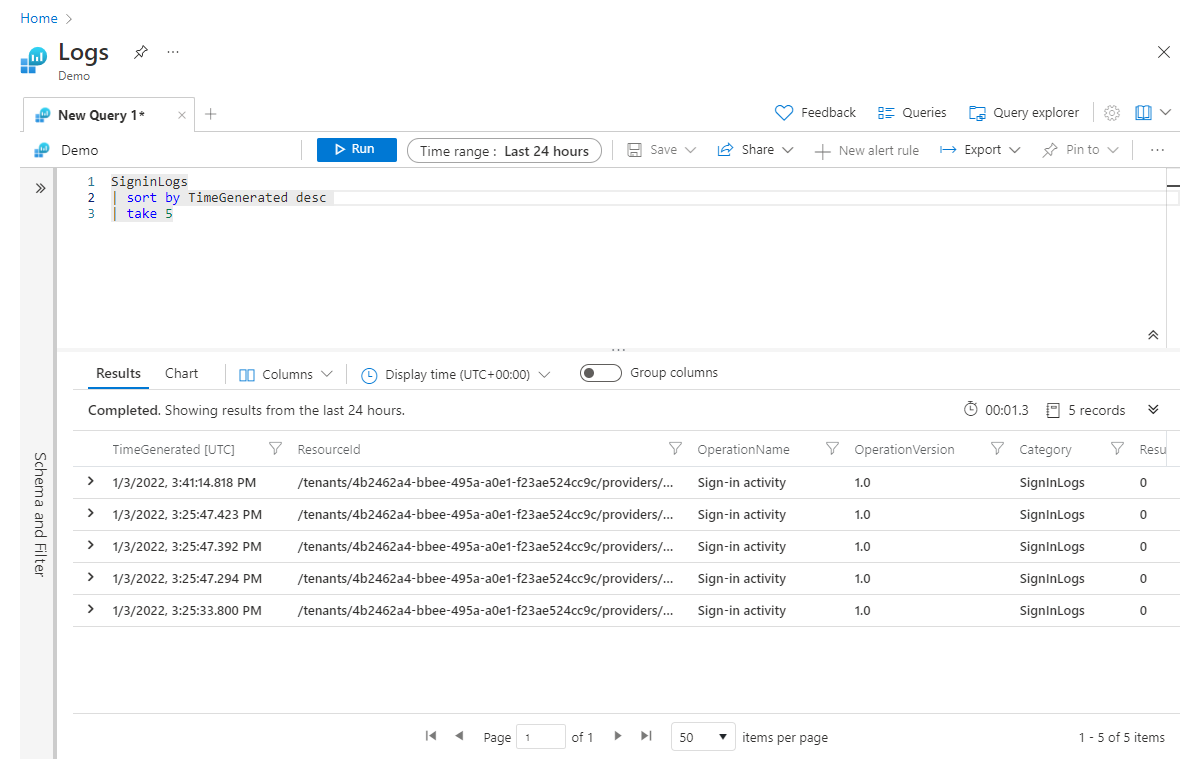
L’opérateur sort (et l’opérateur order identique) est utilisé pour trier vos données selon une colonne spécifiée. Dans l’exemple suivant, nous avons classé les résultats par TimeGenerated et défini le sens de l’ordre sur descendant grâce au paramètre desc, en plaçant les valeurs les plus élevées en premier ; pour un ordre ascendant, nous utiliserions asc.
Notes
La direction par défaut des tris est descendante. Techniquement, vous devez donc seulement spécifier si vous voulez trier par ordre croissant. Toutefois, le fait de spécifier le sens du tri dans tous les cas rendra votre requête plus lisible.
SigninLogs
| sort by TimeGenerated desc
| take 5
Comme nous l’avons mentionné, nous avons placé l’opérateur sort avant l’opérateur take. Nous devons d’abord effectuer un tri pour nous assurer que nous obtenons les cinq enregistrements appropriés.
Top
L’opérateur top nous permet de combiner les opérations sort et take en un seul opérateur :
SigninLogs
| top 5 by TimeGenerated desc
Dans les cas où deux enregistrements ou plus ont la même valeur dans la colonne sur laquelle vous effectuez le tri, vous pouvez ajouter d’autres colonnes de tri. Ajoutez des colonnes de tri supplémentaires dans une liste séparée par des virgules, située après la première colonne de tri, mais avant le mot clé de l’ordre de tri. Par exemple :
SigninLogs
| sort by TimeGenerated, Identity desc
| take 5
Désormais, si la valeur TimeGenerated est la même entre plusieurs enregistrements, la requête essaiera ensuite de trier les enregistrements par la valeur de la colonne Identity.
Notes
Quand utiliser sort et take, et quand utiliser top?
Si vous ne triez que sur un seul champ, utilisez
top, car il offre de meilleures performances que la combinaison desortettake.Si vous devez trier sur plusieurs champs (comme dans le dernier exemple ci-dessus),
topne peut pas le faire, vous devez donc utilisersortettake.
Filtrage des données where
L’opérateur where est sans doute l’opérateur le plus important, car il permet de s’assurer que vous ne travaillez qu’avec le sous-ensemble de données qui s’applique à votre scénario. Vous devez faire de votre mieux pour filtrer vos données le plus tôt possible dans la requête, car cela améliorera les performances de la requête en réduisant la quantité de données à traiter lors des étapes suivantes. Cela garantit également que vous effectuez des calculs uniquement sur les données souhaitées. Consultez l’exemple suivant :
SigninLogs
| where TimeGenerated >= ago(7d)
| sort by TimeGenerated, Identity desc
| take 5
L’opérateur where spécifie une variable, un opérateur de comparaison (scalaire) et une valeur. Dans notre cas, nous avons utilisé >= pour indiquer que la valeur de la colonne TimeGenerated doit être supérieure à (autrement dit, ultérieure à) ou égale à sept jours auparavant.
Il existe deux types d’opérateurs de comparaison dans le langage de requête Kusto : chaîne et numérique. Le tableau suivant présente la liste complète des opérateurs numériques :
Opérateurs numériques
| Opérateur | Description |
|---|---|
+ |
Addition |
- |
Soustraction |
* |
Multiplication |
/ |
Division |
% |
Modulo |
< |
Inférieur à |
> |
Supérieur à |
== |
Égal à |
!= |
Différent de |
<= |
Inférieur ou égal à |
>= |
Supérieur ou égal à |
in |
Égal à l’un des éléments |
!in |
N’est égal à aucun des éléments |
La liste des opérateurs de chaîne est beaucoup plus longue, car elle contient des permutations pour le respect de la casse, les emplacements des sous-chaînes, les préfixes, les suffixes et bien plus encore. L’opérateur == est à la fois un opérateur numérique et un opérateur de chaîne, ce qui signifie qu’il peut être utilisé pour les nombres et le texte. Par exemple, les deux instructions suivantes seraient des instructions where valides :
| where ResultType == 0| where Category == 'SignInLogs'
Conseil
Meilleure pratique : Dans la plupart des cas, vous voudrez probablement filtrer vos données sur plusieurs colonnes ou filtrer la même colonne de plusieurs façons. Dans ce cas, il y a deux meilleures pratiques à garder à l’esprit.
Vous pouvez combiner plusieurs instructions where en une seule étape à l’aide du mot clé and. Par exemple :
SigninLogs
| where Resource == ResourceGroup
and TimeGenerated >= ago(7d)
Lorsque vous avez plusieurs filtres réunis dans une seule instruction where à l’aide du mot clé and, comme ci-dessus, vous obtiendrez de meilleures performances en plaçant en premier les filtres qui ne font référence qu’à une seule colonne. Par conséquent, une meilleure façon d’écrire la requête ci-dessus serait :
SigninLogs
| where TimeGenerated >= ago(7d)
and Resource == ResourceGroup
Dans cet exemple, le premier filtre mentionne une seule colonne (TimeGenerated), tandis que le second fait référence à deux colonnes (Resource et ResourceGroup).
Résumé des données
Summarize est l’un des opérateurs tabulaires les plus importants dans le langage de requête Kusto, mais il s’agit également de l’un des opérateurs les plus complexes à apprendre si vous débutez dans les langages de requête en général. La tâche de summarize consiste à utiliser une table de données et à générer une nouvelle table qui est agrégée par une ou plusieurs colonnes.
Structure de l’instruction summarize
La structure de base d’une instruction summarize est la suivante :
| summarize <aggregation> by <column>
Par exemple, l’instruction suivante renvoie le nombre d’enregistrements pour chaque valeur CounterName dans la table Perf :
Perf
| summarize count() by CounterName
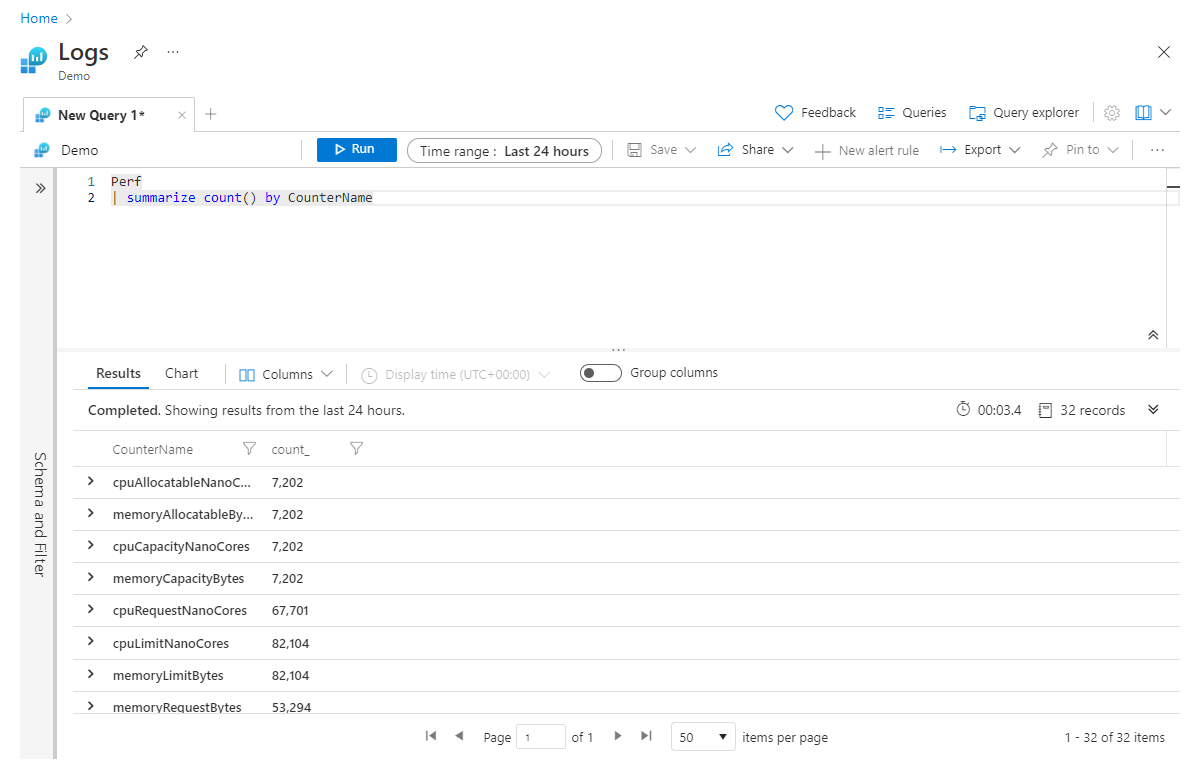
Comme la sortie de summarize est une nouvelle table, toutes les colonnes qui ne sont pas explicitement spécifiées dans l’instruction summarizene seront pas transmises dans le pipeline. Pour illustrer ce concept, prenons l’exemple suivant :
Perf
| project ObjectName, CounterValue, CounterName
| summarize count() by CounterName
| sort by ObjectName asc
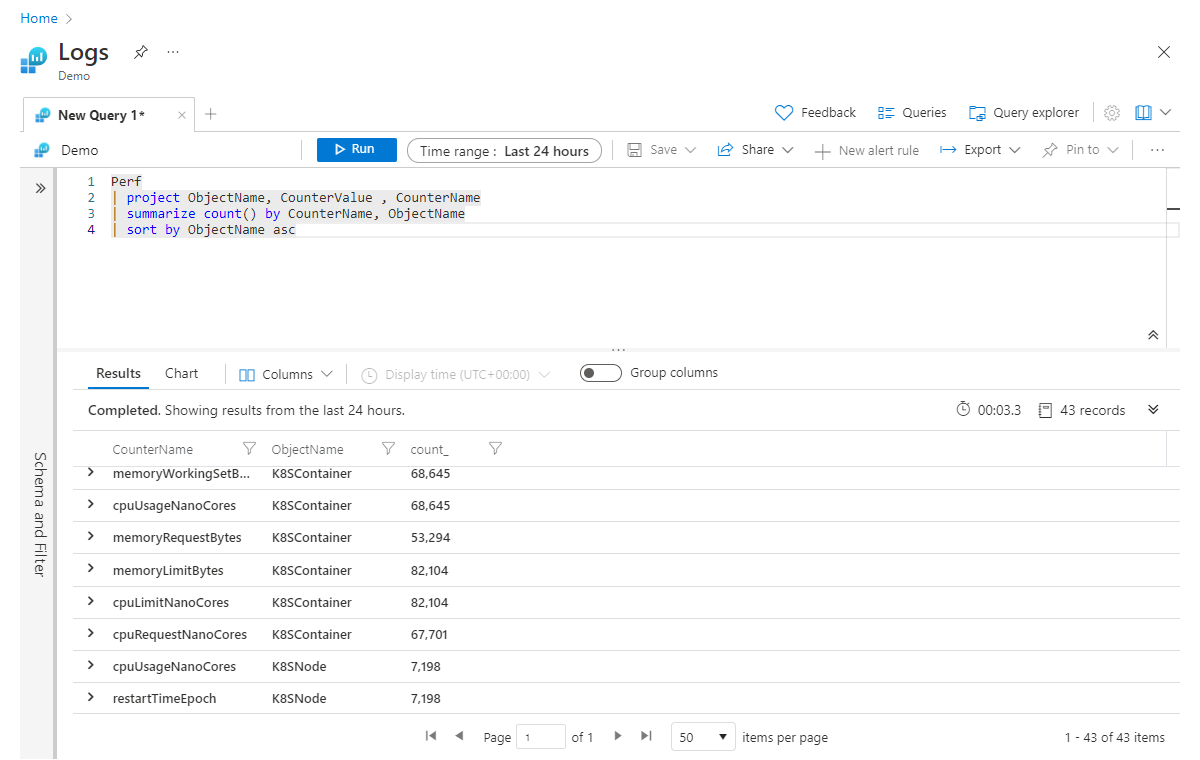
Sur la deuxième ligne, nous spécifions que seules les colonnes ObjectName, CounterValue et CounterName nous intéressent. Nous résumons ensuite pour obtenir le nombre d’enregistrements par CounterName et, enfin, nous essayons de trier les données par ordre croissant en fonction de la colonne ObjectName. Malheureusement, cette requête échouera avec une erreur (indiquant que la colonne ObjectName est inconnue), car, lorsque nous avons résumé, nous avons uniquement inclus les colonnes Count et CounterName dans notre nouvelle table. Pour éviter cette erreur, nous pouvons simplement ajouter ObjectName à la fin de notre étape summarize, comme ceci :
Perf
| project ObjectName, CounterValue , CounterName
| summarize count() by CounterName, ObjectName
| sort by ObjectName asc
La façon de lire la ligne summarize dans votre tête serait : « résumer le nombre d’enregistrements par CounterName, et grouper par ObjectName ». Vous pouvez continuer à ajouter des colonnes, séparées par des virgules, à la fin de l’instruction summarize.
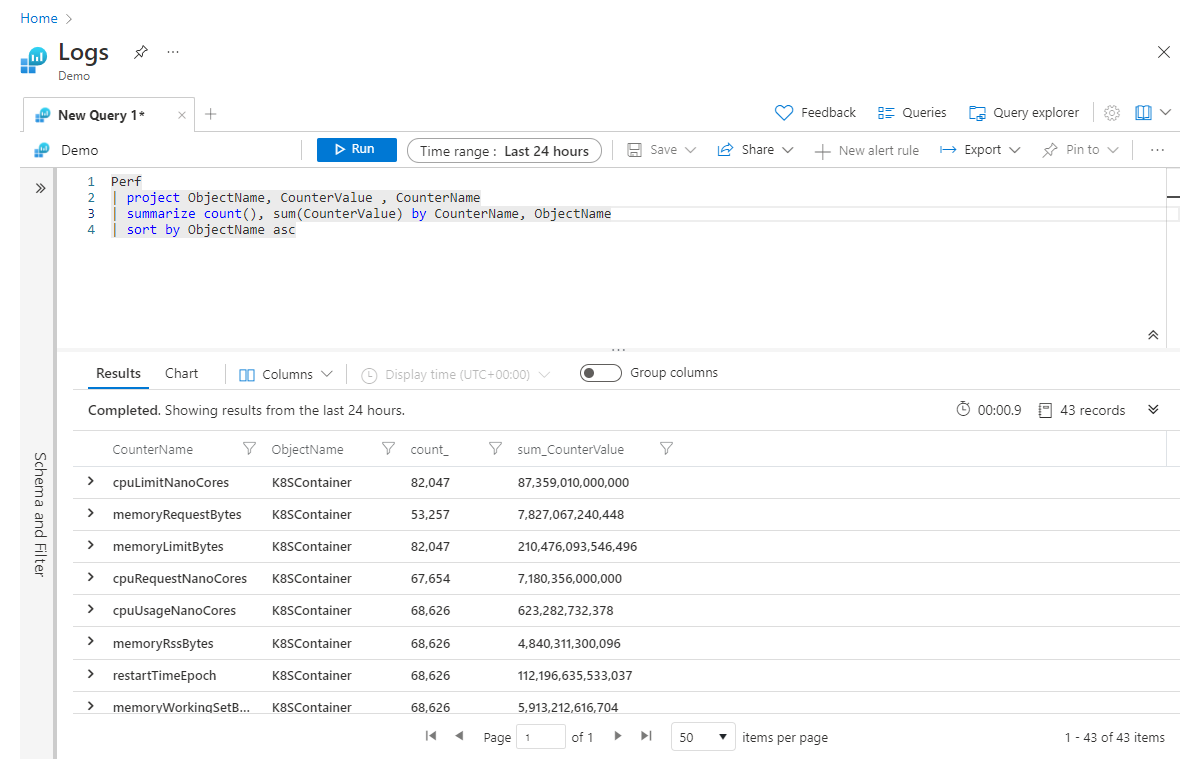
Dans l’exemple précédent, si nous voulons agréger plusieurs colonnes en même temps, nous pouvons le faire en ajoutant des agrégations à l’opérateur summarize, séparées par des virgules. Dans l’exemple ci-dessous, nous obtenons non seulement un compte de tous les enregistrements, mais aussi une somme des valeurs de la colonne CounterValue pour tous les enregistrements (qui correspondent aux filtres de la requête) :
Perf
| project ObjectName, CounterValue , CounterName
| summarize count(), sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
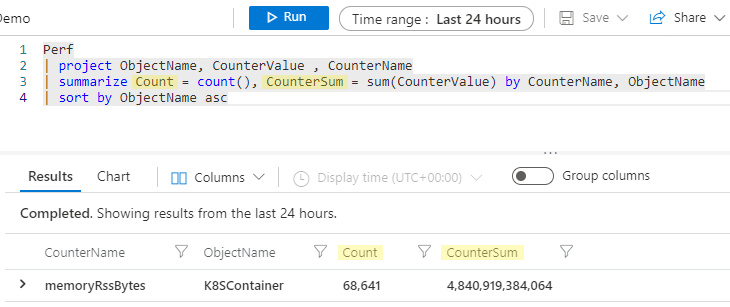
Renommage des colonnes agrégées
Le moment semble bien choisi pour parler des noms de colonnes pour ces colonnes agrégées. Au début de cette section, nous avons dit que l’opérateur summarize prend une table de données et produit une nouvelle table, et que seules les colonnes que vous spécifiez dans l’instruction summarize continueront dans le pipeline. Par conséquent, si vous exécutez l’exemple ci-dessus, les colonnes résultantes pour notre agrégation seront count_ et sum_CounterValue.
Le moteur Kusto va automatiquement créer un nom de colonne sans que nous ayons à être explicite, mais souvent, vous remarquerez qu’il est préférable que votre nouvelle colonne ait un nom plus convivial. Vous pouvez facilement renommer votre colonne dans l’instruction summarize en spécifiant un nouveau nom, suivi de = et de l’agrégation, comme ceci :
Perf
| project ObjectName, CounterValue , CounterName
| summarize Count = count(), CounterSum = sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
Maintenant, nos colonnes résumées seront nommées Count et CounterSum.
L’opérateur summarize est bien plus complexe que ce que nous pouvons couvrir ici, mais vous devez prendre le temps de l’apprendre, car il s’agit d’un composant clé de toute analyse de données que vous prévoyez d’effectuer sur vos données Microsoft Sentinel.
Référence d’agrégation
Il existe de nombreuses fonctions d’agrégation, mais certaines des plus utilisées sont sum(), count() et avg(). Voici une liste partielle (voir la liste complète) :
Fonctions d’agrégation
| Fonction | Description |
|---|---|
arg_max() |
Renvoie une ou plusieurs expressions lorsque l’argument est maximisé |
arg_min() |
Renvoie une ou plusieurs expressions lorsque l’argument est minimisé |
avg() |
Renvoie la valeur moyenne du groupe |
buildschema() |
Renvoie le schéma minimal qui admet toutes les valeurs de l’entrée dynamique |
count() |
Renvoie le compte du groupe |
countif() |
Renvoie le compte avec le prédicat du groupe |
dcount() |
Renvoie le compte distinct approximatif des éléments de groupe |
make_bag() |
Retourne un jeu de propriétés de valeurs dynamiques dans le groupe |
make_list() |
Retourne une liste de toutes les valeurs dans le groupe |
make_set() |
Retourne un jeu de valeurs distinctes dans le groupe |
max() |
Retourne la valeur maximale dans l'ensemble du groupe |
min() |
Retourne la valeur minimale dans l'ensemble du groupe |
percentiles() |
Retourne le centile approximatif du groupe |
stdev() |
Renvoie l'écart type dans l'ensemble du groupe |
sum() |
Renvoie la somme des éléments du groupe |
take_any() |
Renvoie une valeur non vide aléatoire pour le groupe |
variance() |
Renvoie la variance dans l'ensemble du groupe |
Sélection : ajout et suppression de colonnes
Lorsque vous commencez à travailler davantage avec les requêtes, vous pouvez constater que vous avez plus d’informations que nécessaire sur vos sujets (c’est-à-dire, trop de colonnes dans votre table). Ou vous pouvez avoir besoin de plus d’informations que vous n’en avez (autrement dit, vous devez ajouter une nouvelle colonne qui contiendra les résultats de l’analyse d’autres colonnes). Examinons quelques-uns des principaux opérateurs de manipulation des colonnes.
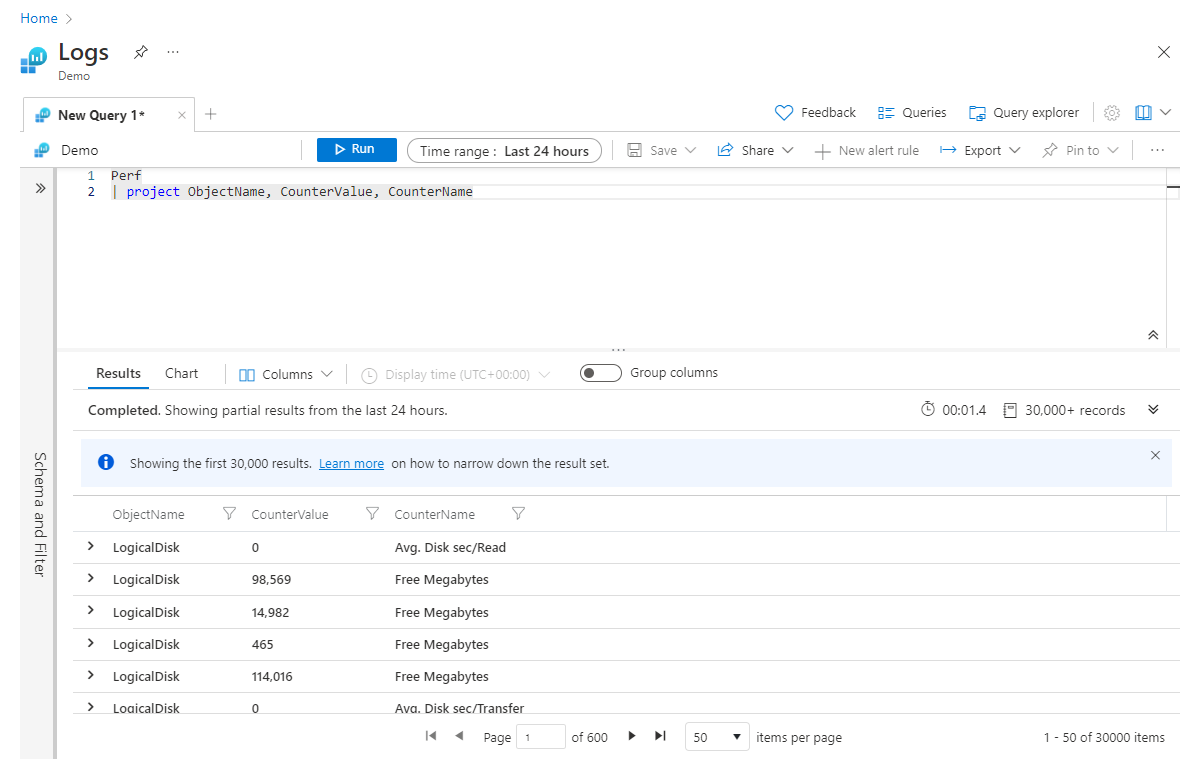
Project et project-away
Project est à peu près l’équivalent des instructions select de nombreux langages. Il vous permet de choisir les colonnes à conserver. L’ordre des colonnes renvoyées correspondra à l’ordre des colonnes que vous avez listées dans votre instruction project, comme le montre l’exemple suivant :
Perf
| project ObjectName, CounterValue, CounterName
Comme vous pouvez l’imaginer, lorsque vous travaillez avec des jeux de données très larges, vous pouvez avoir un grand nombre de colonnes que vous souhaitez conserver, et les spécifier toutes par leur nom nécessiterait beaucoup de saisie. Dans ces cas-là, vous avez project-away, qui vous permet de spécifier les colonnes à supprimer, plutôt que celles à conserver, comme ceci :
Perf
| project-away MG, _ResourceId, Type
Conseil
Il peut être utile d’utiliser project à deux endroits dans vos requêtes, au début et à la fin. L’utilisation de project au début de votre requête peut aider à améliorer les performances en supprimant de grandes quantités de données dont vous n’avez pas besoin de transmettre au pipeline. En l’utilisant à nouveau à la fin, vous pouvez vous débarrasser de toutes les colonnes qui ont pu être créées dans les étapes précédentes et qui ne sont pas nécessaires dans votre sortie finale.
Prolonger
Extend est utilisé pour créer une nouvelle colonne calculée. Cela peut être utile lorsque vous souhaitez effectuer un calcul sur des colonnes existantes et voir la sortie de chaque ligne. Prenons un exemple simple où nous calculons une nouvelle colonne appelée Kbytes, que nous pouvons calculer en multipliant la valeur Mo (dans la colonne Quantity existante) par 1 024.
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| project ResourceUri, MBytes=Quantity, KBytes
Sur la dernière ligne de notre instruction project, nous avons renommé la colonne Quantity en Mbytes, de sorte que nous pouvons facilement dire quelle unité de mesure est pertinente pour chaque colonne.
Il est à noter que extend fonctionne également avec des colonnes déjà calculées. Par exemple, nous pouvons ajouter une colonne supplémentaire appelée Bytes qui est calculée à partir de Kbytes :
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| extend Bytes = KBytes * 1024
| project ResourceUri, MBytes=Quantity, KBytes, Bytes
Joindre des tables
Une grande partie de votre travail dans Microsoft Sentinel peut être effectuée en utilisant un seul type de journal, mais il peut arriver que vous souhaitiez mettre en corrélation des données ou effectuer une recherche sur un autre jeu de données. Comme la plupart des langages de requête, le langage de requête Kusto offre un certain nombre d’opérateurs utilisés pour exécuter différents types de jointures. Dans cette section, nous allons voir les opérateurs les plus utilisés, union et join.
Union
Union prend simplement deux tables ou plus et renvoie toutes les lignes. Par exemple :
OfficeActivity
| union SecurityEvent
Cela renvoie toutes les lignes des tables OfficeActivity et SecurityEvent. Union offre quelques paramètres qui peuvent être utilisés pour ajuster le comportement de l’union. Deux des plus utiles sont withsource et kind :
OfficeActivity
| union withsource = SourceTable kind = inner SecurityEvent
Le paramètre withsource vous permet de spécifier le nom d’une nouvelle colonne dont la valeur dans une ligne donnée sera le nom de la table d’où provient la ligne. Dans l’exemple ci-dessus, nous avons nommé la colonne SourceTable, et selon la ligne, la valeur sera soit OfficeActivity, soit SecurityEvent.
L’autre paramètre que nous avons spécifié est kind, qui a deux options : inner ou outer. Dans l’exemple ci-dessus, nous avons spécifié inner, ce qui signifie que les seules colonnes qui seront conservées pendant l’union sont celles qui existent dans les deux tables. Par contre, si nous avions spécifié outer (qui est la valeur par défaut), toutes les colonnes des deux tables seraient renvoyées.
Join
Join fonctionne de la même manière que union, sauf qu’au lieu de joindre des tables pour créer une nouvelle table, nous joignons des lignes pour créer une nouvelle table. Comme dans la plupart des langues de base de données, il existe plusieurs types de jointures que vous pouvez effectuer. La syntaxe générale de join est la suivante :
T1
| join kind = <join type>
(
T2
) on $left.<T1Column> == $right.<T2Column>
Après l’opérateur join, nous spécifions le type de jointure que nous voulons effectuer, suivi d’une parenthèse ouvrante. C’est entre les parenthèses que l’on spécifie la table à joindre, ainsi que toute autre instruction de requête sur cette table que l’on souhaite ajouter. Après la parenthèse fermante, nous utilisons le mot clé on suivi de nos colonnes gauche ($left.<columnName>) et droite ($right.<columnName>) séparées par l’opérateur ==. Voici un exemple de jointure interne :
OfficeActivity
| where TimeGenerated >= ago(1d)
and LogonUserSid != ''
| join kind = inner (
SecurityEvent
| where TimeGenerated >= ago(1d)
and SubjectUserSid != ''
) on $left.LogonUserSid == $right.SubjectUserSid
Notes
Si les deux tables ont le même nom pour les colonnes sur lesquelles vous effectuez une jointure, vous n’avez pas besoin d’utiliser $left et $right ; vous pouvez simplement spécifier le nom de la colonne. Toutefois, l’utilisation de $left et $right est plus explicite et généralement considérée comme une bonne pratique.
Pour référence, le tableau suivant présente une liste des types de jointures disponibles.
Types de jointures
| Type de jointure | Description |
|---|---|
inner |
Renvoie un seul résultat pour chaque combinaison de lignes correspondantes des deux tables. |
innerunique |
Retourne les lignes de la table de gauche avec des valeurs distinctes dans le champ lié qui ont une correspondance dans la table de droite. Il s’agit du type de jointure non spécifié par défaut. |
leftsemi |
Renvoie tous les enregistrements de la table de gauche qui ont une correspondance dans la table de droite. Seules les colonnes de la table de gauche seront renvoyées. |
rightsemi |
Renvoie tous les enregistrements de la table de droite qui ont une correspondance dans la table de gauche. Seules les colonnes de la table de droite seront renvoyées. |
leftanti/leftantisemi |
Renvoie tous les enregistrements de la table de gauche qui n’ont pas de correspondance dans la table de droite. Seules les colonnes de la table de gauche seront renvoyées. |
rightanti/rightantisemi |
Renvoie tous les enregistrements de la table de droite qui n’ont pas de correspondance dans la table de gauche. Seules les colonnes de la table de droite seront renvoyées. |
leftouter |
Renvoie tous les enregistrements de la table de gauche. Pour les enregistrements qui n’ont pas de correspondance dans la table de droite, les valeurs des cellules seront Null. |
rightouter |
Renvoie tous les enregistrements de la table de droite. Pour les enregistrements qui n’ont pas de correspondance dans la table de gauche, les valeurs des cellules seront Null. |
fullouter |
Retourne tous les enregistrements des tables de gauche et de droite, avec ou sans correspondance. Les valeurs sans correspondance seront Null. |
Conseil
La meilleure pratique consiste à placer la plus petite table à gauche. Dans certains cas, le respect de cette règle peut vous apporter d’énormes avantages en matière de performances, selon les types de jointures que vous effectuez et la taille des tables.
Évaluer
Vous vous souvenez peut-être que, dans le premier exemple, nous avons vu l’opérateur evaluate sur l’une des lignes. L’opérateur evaluate est moins couramment utilisé que ceux que nous avons abordés précédemment. Toutefois, savoir comment fonctionne l’opérateur evaluate vaut la peine de s’y attarder. Une fois encore, voici la première requête, où vous verrez evaluate sur la deuxième ligne.
SigninLogs
| evaluate bag_unpack(LocationDetails)
| where RiskLevelDuringSignIn == 'none'
and TimeGenerated >= ago(7d)
| summarize Count = count() by city
| sort by Count desc
| take 5
Cet opérateur vous permet d’appeler des plug-ins disponibles (essentiellement des fonctions intégrées). Un grand nombre de ces plug-ins sont axés sur la science des données, comme autocluster, diffpatterns et sequence_detect, ce qui vous permet d’effectuer des analyses avancées et de découvrir des anomalies statistiques et des valeurs hors norme.
Le plug-in utilisé dans l’exemple ci-dessus a été appelé bag_unpack, et il permet de prendre très facilement un bloc de données dynamiques et de le convertir en colonnes. N’oubliez pas que les données dynamiques sont un type de données qui ressemble beaucoup à JSON, comme le montre cet exemple :
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
Dans ce cas, nous avons voulu résumer les données par ville, mais la valeur city est contenue en tant que propriété dans la colonne LocationDetails. Pour utiliser la propriété city dans notre requête, nous avons dû d’abord la convertir en colonne à l’aide de bag_unpack.
En revenant aux étapes initiales de notre pipeline, nous avons vu ceci :
Get Data | Filter | Summarize | Sort | Select
Maintenant que nous avons examiné l’opérateur evaluate, nous pouvons voir qu’il représente une nouvelle étape dans le pipeline, qui ressemble maintenant à ceci :
Get Data | Parse | Filter | Summarize | Sort | Select
Il existe de nombreux autres exemples d’opérateurs et de fonctions qui peuvent être utilisés pour analyser des sources de données dans un format plus lisible et manipulable. Vous pouvez en savoir plus sur eux, ainsi que sur le reste du langage de requête Kusto, dans la documentation complète et dans le classeur.
Instructions let
Maintenant que nous avons abordé les principaux opérateurs et types de données, terminons par l’instruction let, qui est un excellent moyen de faciliter la lecture, la modification et la maintenance de vos requêtes.
L’instruction let vous permet de créer et de définir une variable ou d’attribuer un nom à une expression. Cette expression peut être une valeur unique, mais il peut également s’agir d’une requête entière. Voici un exemple simple :
let aWeekAgo = ago(7d);
SigninLogs
| where TimeGenerated >= aWeekAgo
Ici, nous avons spécifié le nom aWeekAgo et l’avons défini comme étant égal à la sortie d’une fonction timespan, qui renvoie une valeur datetime. Nous terminons ensuite l’instruction let par un point-virgule. Nous avons maintenant une nouvelle variable appelée aWeekAgo qui peut être utilisée n’importe où dans notre requête.
Comme nous venons de le mentionner, vous pouvez utiliser une instruction let pour prendre une requête entière et donner un nom au résultat. Puisque les résultats d’une requête, étant des expressions tabulaires, peuvent être utilisés comme entrées de requêtes, vous pouvez traiter ce résultat nommé comme une table dans le but d’exécuter une autre requête sur celle-ci. Voici une légère modification de l’exemple précédent :
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
Dans ce cas, nous avons créé une deuxième instruction let, dans laquelle nous avons encapsulé toute notre requête dans une nouvelle variable appelée getSignins. Comme précédemment, nous terminons la deuxième instruction let par un point-virgule. Ensuite, nous appelons la variable sur la dernière ligne, ce qui va exécuter la requête. Notez que nous avons pu utiliser aWeekAgo dans la deuxième instruction let. Cela est dû au fait que nous l’avons spécifiée sur la ligne précédente ; si nous devions intervertir les instructions let pour que getSignins vienne en premier, nous obtiendrions une erreur.
Nous pouvons maintenant utiliser getSignins comme base d’une autre requête (dans la même fenêtre) :
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
| where level >= 3
| project IPAddress, UserDisplayName, Level
Les instructions let vous donnent plus de puissance et de flexibilité pour organiser vos requêtes. Let permet de définir des valeurs scalaires et tabulaires ainsi que de créer des fonctions définies par l’utilisateur. Elles s’avèrent très utiles lorsque vous organisez des requêtes plus complexes qui peuvent comporter plusieurs jointures.
Étapes suivantes
Bien que cet article ait à peine effleuré la surface, vous disposez désormais des bases nécessaires et nous avons couvert les parties que vous utiliserez le plus souvent pour effectuer votre travail dans Microsoft Sentinel.
Classeur KQL avancé pour Microsoft Sentinel
Profitez d’un classeur de langage de requête Kusto directement dans Microsoft Sentinel : le classeur KQL avancé pour Microsoft Sentinel. Il vous fournit une aide étape par étape et des exemples pour de nombreuses situations que vous êtes susceptibles de rencontrer au cours de vos opérations de sécurité quotidiennes et vous indique également de nombreux exemples prêts à l’emploi de règles d’analyse, de classeurs, de règles de chasse et d’autres éléments qui utilisent des requêtes Kusto. Lancez ce classeur à partir du panneau Classeurs dans Microsoft Sentinel.
Classeur d’infrastructure KQL avancée : Comment devenir un expert en KQL est un excellent billet de blog qui vous montre comment utiliser ce classeur.
Plus de ressources
Consultez cette collection de ressources d’apprentissage, de formation et d’acquisition de compétences pour élargir et approfondir vos connaissances du langage de requête Kusto.