Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Azure Files peut répondre aux besoins de performances pour la plupart des applications et des cas d’usage. Cet article explique les différents facteurs qui peuvent affecter les performances des partages de fichiers, et comment optimiser les performances des partages de fichiers Azure pour votre charge de travail.
S’applique à
| Modèle de gestion | Modèle de facturation | Échelon médiatique | Redondance | PME | Système de fichiers en réseau (NFS) |
|---|---|---|---|---|---|
| Microsoft.Storage | V2 approvisionné | HDD (standard) | Local (LRS) |
|
|
| Microsoft.Storage | V2 approvisionné | HDD (standard) | Zone (ZRS) |
|
|
| Microsoft.Storage | V2 approvisionné | HDD (standard) | Géo (GRS) |
|
|
| Microsoft.Storage | V2 approvisionné | HDD (standard) | GeoZone (GZRS) |
|
|
| Microsoft.Storage | V1 approvisionné | SSD (Premium) | Local (LRS) |
|
|
| Microsoft.Storage | V1 approvisionné | SSD (Premium) | Zone (ZRS) |
|
|
| Microsoft.Storage | Paiement à l’utilisation | HDD (standard) | Local (LRS) |
|
|
| Microsoft.Storage | Paiement à l’utilisation | HDD (standard) | Zone (ZRS) |
|
|
| Microsoft.Storage | Paiement à l’utilisation | HDD (standard) | Géo (GRS) |
|
|
| Microsoft.Storage | Paiement à l’utilisation | HDD (standard) | GeoZone (GZRS) |
|
|
Glossaire
Avant de lire cet article, il est utile de comprendre certains termes clés relatifs aux performances de stockage :
Opérations d’E/S par seconde (IOPS)
Les IOPS, ou opérations d’entrée/sortie par seconde, mesurent le nombre d’opérations de système de fichiers par seconde. Le terme « E/S » est interchangeable avec les termes « opération » et « transaction » dans la documentation Azure Files.
Taille des E/S
La taille des E/S, parfois appelée taille de bloc, correspond à la taille de la requête utilisée par une application pour effectuer une seule opération d’entrée/sortie (E/S) sur le stockage. Selon l’application, la taille des E/S peut se situer entre des tailles très petites, par exemple 4 Kio, et des tailles beaucoup plus grandes. La taille des E/S joue un rôle majeur dans le débit pouvant être atteint.
Débit
Le débit mesure le nombre de bits lus ou écrits dans le stockage par seconde. Il est mesuré en mébioctets par seconde (Mio/s). Pour calculer le débit, multipliez les IOPS par la taille des E/S. Par exemple, 10 000 IOPS * taille d’E/S de 1 Mio = 10 Gio/s, alors que 10 000 IOPS * taille d’E/S de 4 Kio = 38 Mio/s.
Latence
La latence est un synonyme de délai et est mesurée en millisecondes (ms). Il existe deux types de latence : la latence de bout en bout et la latence du service. Pour plus d’informations, consultez Latence.
Profondeur de file d’attente
La profondeur de file d’attente correspond au nombre de requêtes d’E/S en attente qu’une ressource de stockage peut gérer à un moment donné. Pour plus d’informations, consultez Profondeur de file d’attente.
Choix d’un niveau multimédia en fonction des modèles d’utilisation
Azure Files fournit deux niveaux de support de stockage vous permettent d’équilibrer les performances et le prix : SSD et HDD. Vous choisissez le niveau multimédia du partage de fichiers au niveau du compte de stockage et une fois que vous avez créé un compte de stockage dans un niveau multimédia particulier, vous ne pouvez pas passer à l’autre sans migrer manuellement vers un nouveau partage de fichiers.
Lorsque vous choisissez entre les partages de fichiers SSD et HDD, il est important de comprendre les exigences du modèle d’utilisation attendu que vous envisagez d’exécuter sur Azure Files. Si vous avez besoin de grandes quantités d’IOPS, de vitesses de transfert de données rapides ou de faible latence, vous devez choisir des partages de fichiers SSD.
Le tableau suivant récapitule les cibles de performances attendues entre les partages de fichiers SSD et HDD. Pour plus d’informations, consultez Objectifs de scalabilité et de performance d’Azure Files.
| Besoins liés au modèle d’utilisation | ssd | HDD |
|---|---|---|
| Latence d’écriture (à un seul chiffre en millisecondes) | Oui | Oui |
| Latence de lecture (à un seul chiffre en millisecondes) | Oui | Non |
Les partages de fichiers SSD offrent un modèle d’approvisionnement qui garantit le profil de performances suivant en fonction de la taille du partage. Pour plus d’informations, consultez Modèle provisionné v1.
Liste de contrôle de performance
Que vous évaluez les exigences de performances pour une charge de travail nouvelle ou existante, la compréhension de vos modèles d’utilisation vous permet d’obtenir des performances prévisibles.
Sensibilité de la latence : Les charges de travail sensibles à la latence de lecture et qui ont une visibilité élevée pour les utilisateurs finaux sont plus adaptées aux partages de fichiers SSD, ce qui peut fournir une latence d’une milliseconde pour les opérations de lecture et d’écriture (< 2 ms pour une petite taille d’E/S).
Exigences en matière d’IOPS et de débit : Les partages de fichiers SSD prennent en charge des IOPS et des limites de débit plus importantes que les partages de fichiers HDD. Pour plus d’informations, consultez cibles d’échelle de partage de fichiers.
Durée et fréquence de la charge de travail : Les charges de travail courtes (minutes) et peu fréquentes (toutes les heures) sont moins susceptibles d’atteindre les limites de performances supérieures des partages de fichiers HDD par rapport aux charges de travail à long terme qui se produisent fréquemment. Sur les partages de fichiers SSD, la durée de la charge de travail est utile lors de la détermination du profil de performances approprié à utiliser en fonction du stockage provisionné, des E/S par seconde et du débit. Une erreur courante consiste à exécuter des tests de performances pendant quelques minutes seulement, ce qui est souvent trompeur. Pour obtenir une vue réaliste des performances, veillez à effectuer les tests à une fréquence et une durée suffisamment élevées.
Parallélisation de la charge de travail : Pour les charges de travail qui effectuent des opérations en parallèle, telles que via plusieurs threads, processus ou instances d’application sur le même client, les partages de fichiers SSD offrent un avantage clair sur les partages de fichiers HDD : SMB Multichannel. Pour plus d’informations, consultez Améliorer les performances des partages de fichiers Azure SMB.
Distribution des opérations d’API : les charges de travail lourdes de métadonnées, telles que les charges de travail qui effectuent des opérations de lecture sur un grand nombre de fichiers, conviennent mieux aux partages de fichiers SSD. Consultez Charge de travail avec de nombreux espaces de noms ou métadonnées.
Latence
Quand vous pensez à la latence, vous devez d’abord bien comprendre la façon dont elle est déterminée avec Azure Files. Les mesures les plus courantes sont la latence associée aux métriques de latence de bout en bout et de latence du service. L’utilisation de ces métriques de transaction peut permettre d’identifier les problèmes de latence et/ou les problèmes réseau côté client en déterminant la durée de transit du trafic de votre application à destination et en provenance du client.
La latence de bout en bout (SuccessE2ELatency) correspond au temps total nécessaire à une transaction pour effectuer un aller-retour complet entre le client, le réseau, le service Azure Files, puis le client.
La latence de service (SuccessServerLatency) est le temps nécessaire à une transaction pour aller-retour uniquement dans Azure Files. Cela n’inclut pas la latence du client ou le temps de réponse du réseau.
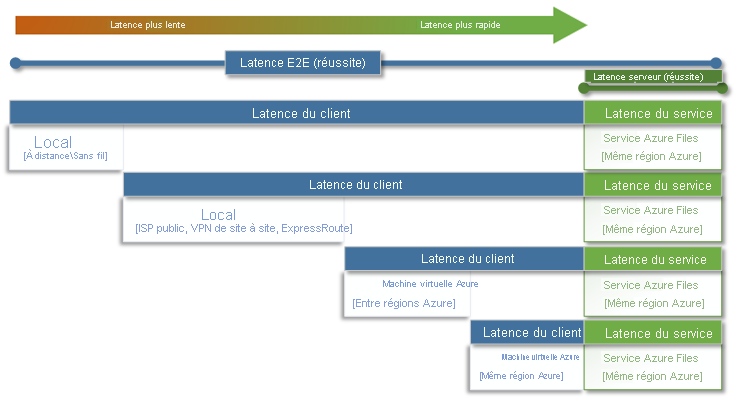
La différence entre les valeurs de SuccessE2ELatency et SuccessServerLatency correspond à la latence probable causée par le réseau et/ou le client.
Il est courant de confondre la latence du client et la latence du service (dans le cas présent, les performances d’Azure Files). Par exemple, si la latence du service est faible, et si la latence de bout en bout correspond à une latence très élevée pour les demandes, cela peut signifier que tout le temps est passé en transit à destination et en provenance du client, et non dans le service Azure Files.
En outre, comme l’illustre le diagramme, plus vous êtes loin du service, plus l’expérience de latence est lente, et plus il est difficile d’atteindre les limites d’échelle des performances avec n’importe quel service cloud. Cela est particulièrement vrai quand vous accédez à Azure Files depuis un environnement local. Bien que les options telles qu’ExpressRoute soient idéales pour un environnement local, elles ne correspondent toujours pas aux performances d’une application (calcul + stockage) qui s’exécute exclusivement dans la même région Azure.
Conseil
L’utilisation d’une machine virtuelle dans Azure pour tester les performances entre l’environnement local et Azure est un moyen efficace et pratique d’établir une base de référence des fonctionnalités réseau de la connexion à Azure. Les circuits ExpressRoute sous-dimensionnés ou mal routés, ainsi que les passerelles VPN mal configurées, peuvent ralentir considérablement les charges de travail s'exécutant sur Azure Files.
Profondeur de file d’attente
La profondeur de file d’attente correspond au nombre de requêtes d’E/S en attente qu’une ressource de stockage peut traiter. Au fur et à mesure que les disques utilisés par les systèmes de stockage sont passés des disques HDD à plateaux (IDE, SATA, SAS) aux périphériques SSD, NVMe, ils ont également évolué pour prendre en charge une profondeur de file d’attente plus importante. Une charge de travail composée d’un seul client qui interagit en série avec un seul fichier au sein d’un jeu de données volumineux est un exemple de faible profondeur de file d’attente. En revanche, une charge de travail qui gère le parallélisme avec plusieurs threads et plusieurs fichiers peut facilement atteindre une profondeur de file d’attente importante. Dans la mesure où Azure Files est un service de fichiers distribué qui s’étend sur des milliers de nœuds de cluster Azure, et qu’il est conçu pour exécuter des charges de travail à grande échelle, nous vous recommandons de créer et de tester des charges de travail avec une profondeur de file d’attente importante.
Vous pouvez obtenir une profondeur de file d’attente importante de plusieurs façons différentes, en combinaison avec les clients, les fichiers et les threads. Pour déterminer la profondeur de file d’attente de votre charge de travail, multipliez le nombre de clients par le nombre de fichiers, puis par le nombre de threads (clients * fichiers * threads = profondeur de file d’attente).
Le tableau ci-dessous illustre les différentes combinaisons qui vous permettent d’obtenir une profondeur de file d’attente plus importante. Bien que vous puissiez dépasser la profondeur de file d’attente optimale définie à 64, nous vous le déconseillons. En effet, vous ne constaterez plus de gains de performances, et vous risquez d’augmenter la latence en raison de la saturation TCP.
| Clients | Fichiers | Sujets | Profondeur de file d’attente |
|---|---|---|---|
| 1 | 1 | 1 | 1 |
| 1 | 1 | 2 | 2 |
| 1 | 2 | 2 | 4 |
| 2 | 2 | 2 | 8 |
| 2 | 2 | 4 | 16 |
| 2 | 4 | 4 | 32 |
| 1 | 8 | 8 | 64 |
| 4 | 4 | 2 | 64 |
Conseil
Pour atteindre les limites de performances supérieures, vérifiez que votre charge de travail ou votre test de point de référence est multithread avec plusieurs fichiers.
Applications monothread et multithread
Azure Files convient mieux aux applications multithread. Le moyen le plus simple de comprendre l’impact du multithread sur les performances d’une charge de travail consiste à parcourir le scénario par E/S. Dans l’exemple suivant, nous avons une charge de travail qui doit copier 10 000 petits fichiers le plus rapidement possible en provenance ou à destination d’un partage de fichiers Azure.
Ce tableau décompose le temps nécessaire (en millisecondes) pour créer un seul fichier de 16 Kio sur un partage de fichiers Azure, sur la base d’une application monothread qui écrit des blocs de 4 Kio.
| Opération d’E/S | Créer | Écriture de 4 Kio | Écriture de 4 Kio | Écriture de 4 Kio | Écriture de 4 Kio | Fermer | Total |
|---|---|---|---|---|---|---|---|
| Thread 1 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
Dans cet exemple, la création d’un seul fichier de 16 Kio à partir des six opérations prend environ 14 ms. Si une application monothread souhaite déplacer 10 000 fichiers vers un partage de fichiers Azure, cela se traduit par 140 000 ms (14 ms * 10 000) ou 140 secondes, car chaque fichier est déplacé de manière séquentielle, un par un. N’oubliez pas que le délai de traitement de chaque requête est principalement déterminé par la proximité entre le calcul et le stockage, comme indiqué dans la section précédente.
En utilisant huit threads au lieu d’un seul, la charge de travail ci-dessus peut être réduite de 140 000 ms (140 secondes) à 17 500 ms (17,5 secondes). Comme le montre le tableau ci-dessous, quand vous déplacez huit fichiers en parallèle au lieu d’un seul fichier à la fois, vous pouvez déplacer la même quantité de données en 87,5 % moins de temps.
| Opération d’E/S | Créer | Écriture de 4 Kio | Écriture de 4 Kio | Écriture de 4 Kio | Écriture de 4 Kio | Fermer | Total |
|---|---|---|---|---|---|---|---|
| Thread 1 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 2 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 3 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 4 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 5 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 6 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 7 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Thread 8 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |