Tutoriel : Accès aux données Azure Synapse ADLS Gen2 dans Azure Machine Learning
Dans ce tutoriel, nous vous guidons tout au long du processus d’accès aux données stockées dans Azure Synapse Azure Data Lake Storage Gen2 (ADLS Gen2) à partir d’Azure Machine Learning (Azure Machine Learning). Cette fonctionnalité est particulièrement utile quand vous voulez simplifier votre workflow de machine learning en tirant parti d’outils comme le ML automatisé, le suivi intégré des modèles et des expériences, ou du matériel spécialisé comme les GPU disponibles dans Azure Machine Learning.
Pour accéder aux données ADLS Gen2 dans Azure Machine Learning, nous créons un magasin de données Azure Machine Learning qui pointe vers le compte de stockage Azure Synapse ADLS Gen2.
Prérequis
- Un espace de travail Azure Synapse Analytics. Assurez-vous qu’il comporte un compte de stockage Azure Data Lake Storage Gen2 configuré comme stockage par défaut. Pour le système de fichiers Data Lake Storage Gen2 que vous utilisez, vérifiez que vous êtes contributeur aux données Blob de stockage.
- Un espace de travail Azure Machine Learning.
Installation des bibliothèques
Pour commencer, nous installons le package azure-ai-ml.
%pip install azure-ai-ml
Créer un magasin de données
Azure Machine Learning offre une fonctionnalité appelée Magasin de données, qui fait office de référence à votre compte de stockage Azure existant. Nous créons un magasin de données qui référence notre compte de stockage Azure Synapse ADLS Gen2.
Dans cet exemple, nous créons un magasin de données qui fait la liaison avec notre stockage Azure Synapse ADLS Gen2. Après avoir initialisé un objet MLClient, vous pouvez fournir les détails de connexion à votre compte ADLS Gen2. Enfin, vous pouvez exécuter le code pour créer ou mettre à jour le magasin de données.
from azure.ai.ml.entities import AzureDataLakeGen2Datastore
from azure.ai.ml import MLClient
ml_client = MLClient.from_config()
# Provide the connection details to your Azure Synapse ADLSg2 storage account
store = AzureDataLakeGen2Datastore(
name="",
description="",
account_name="",
filesystem=""
)
ml_client.create_or_update(store)
Vous pouvez en savoir plus sur la création et la gestion des magasins de données Azure Machine Learning à partir de ce tutoriel sur les magasins de données Azure Machine Learning.
Monter votre compte de stockage ADLS Gen2
Dès que vous avez configuré votre magasin de données, vous pouvez accéder à ces données en créant un montage dans votre compte ADLSg2. Dans Azure Machine Learning, la création d’un montage dans votre compte ADLS Gen2 implique l’établissement d’une liaison directe entre votre espace de travail et le compte de stockage, ce qui permet un accès fluide aux données qui y sont stockées. Fondamentalement, un montage agit comme un chemin qui permet à Azure Machine Learning d’interagir avec les fichiers et dossiers de votre compte ADLS Gen2, comme s’ils faisaient partie du système de fichiers local au sein de votre espace de travail.
Une fois le compte de stockage monté, vous pouvez facilement lire, écrire et manipuler les données stockées dans ADLS Gen2 en utilisant des opérations de système de fichiers familières directement dans votre environnement Azure Machine Learning, ce qui simplifie le prétraitement des données, l’entraînement de modèle et les tâches d’expérimentation.
Pour ce faire :
Démarrez votre moteur de calcul.
Sélectionnez Actions de données, puis Monter.
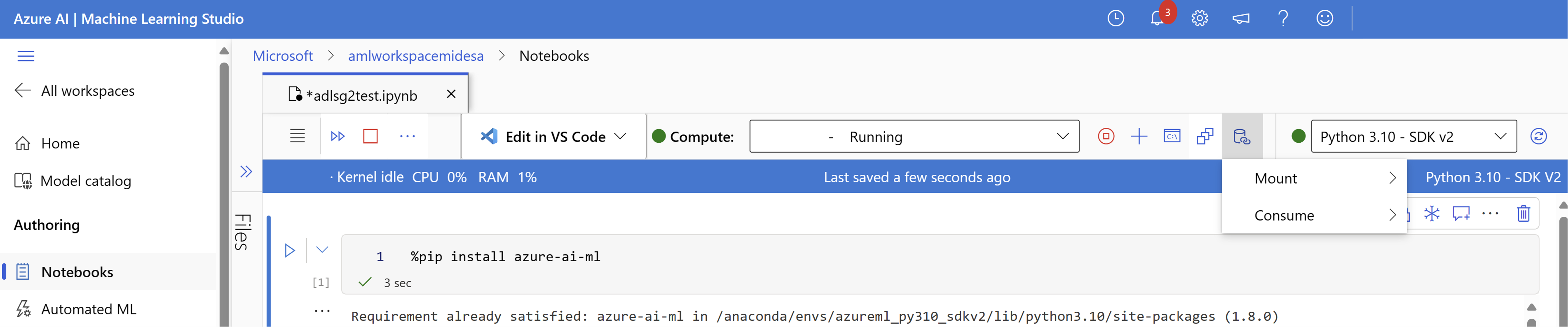
À partir de là, vous devez voir et sélectionner le nom de votre compte de stockage ADLSg2. La création de votre montage peut prendre quelques instants.
Une fois votre montage prêt, vous pouvez sélectionner Actions de données, puis Consommer. Sous Données, vous pouvez ensuite sélectionner le montage dont vous voulez consommer les données.
À présent, vous pouvez utiliser vos bibliothèques préférées pour lire directement les données de votre compte Azure Data Lake Storage monté.
Lire les données de votre compte de stockage
import os
# List the files in the mounted path
print(os.listdir("/home/azureuser/cloudfiles/data/datastore/{name of mount}"))
# Get the path of your file and load the data using your preferred libraries
import pandas as pd
df = pd.read_csv("/home/azureuser/cloudfiles/data/datastore/{name of mount}/{file name}")
print(df.head(5))