Conseiller Apache Spark pour des conseils en temps réel sur les notebooks
Le conseiller Apache Spark analyse les commandes et le code exécutés par Apache Spark et affiche des conseils en temps réel pour les exécutions de Notebook. Le conseiller Apache Spark a des modèles intégrés pour aider les utilisateurs à éviter les erreurs courantes. Il propose des recommandations pour l'optimisation du code, effectue une analyse des erreurs et localise la cause première des échecs.
Conseils intégrés
Le conseiller Spark, un outil intégré à Impulse, fournit des modèles intégrés pour détecter et résoudre les problèmes dans les applications Apache Spark. Cet article explique certains des modèles inclus dans l'outil.
Vous pouvez ouvrir le volet Exécutions récentes en fonction du type de conseil dont vous avez besoin.
Peut retourner des résultats incohérents lors de l’utilisation de « randomSplit »
Des résultats incohérents ou inexacts peuvent être renvoyés lors de l'utilisation de la méthode randomSplit. Utilisez la mise en cache Apache Spark (RDD) avant d'utiliser la méthode randomSplit().
La méthode randomSplit() équivaut à exécuter sample() plusieurs fois sur votre bloc de données. Où chaque échantillon récupère, partitionne et trie votre bloc de données dans les partitions. La distribution de données entre les partitions et l’ordre de tri est importante pour randomSplit() et sample(). Si l'un ou l'autre change lors de la nouvelle récupération des données, il peut y avoir des doublons ou des valeurs manquantes dans les divisions. Et le même échantillon utilisant la même semence peut produire des résultats différents.
Ces incohérences peuvent ne pas se produire à chaque exécution, mais pour les éliminer complètement, mettez en cache votre bloc de données, répartissez-le sur une ou plusieurs colonnes ou appliquez des fonctions d'agrégation telles que groupBy.
Le nom de la table/affichage est déjà utilisé
Une vue existe déjà avec le même nom que la table créée, ou une table existe déjà avec le même nom que la vue créée. Lorsque ce nom est utilisé dans les requêtes ou les applications, seul l’affichage est retourné, quel que soit le premier créé. Pour éviter les conflits, renommez la table ou la vue.
Impossible de reconnaître un conseil
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
Impossible de trouver un ou plusieurs noms de relation spécifiés
Impossible de trouver les relations spécifiées dans l’indicateur. Vérifiez que les relations sont correctement orthographiées et accessibles dans l’étendue de l’indicateur.
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Un indicateur dans la requête empêche l’application d’un autre indicateur
La requête sélectionnée contient un indicateur qui empêche l’application d’un autre indicateur.
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Activer « spark.advise.divisionExprConvertRule.enable » pour réduire la propagation d’erreurs d’arrondi
Cette requête contient l’expression avec un type double. Nous vous recommandons d’activer la configuration « spark.advise.divisionExprConvertRule.enable », ce qui peut vous aider à réduire les expressions de division et à réduire la propagation d’erreurs d’arrondi.
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
Activer « spark.advise.nonEqJoinConvertRule.enable » pour améliorer les performances des requêtes
Cette requête contient une jointure longue en raison d’une condition « Ou » dans la requête. Nous vous recommandons d’activer la configuration « spark.advise.nonEqJoinConvertRule.enable », qui peut vous aider à convertir la jointure déclenchée par la condition « Or » en SMJ ou BHJ pour accélérer cette requête.
Expérience utilisateur
Le conseiller Apache Spark affiche les conseils, y compris les informations, les avertissements et les erreurs, à la sortie de la cellule Notebook en temps réel.
Info
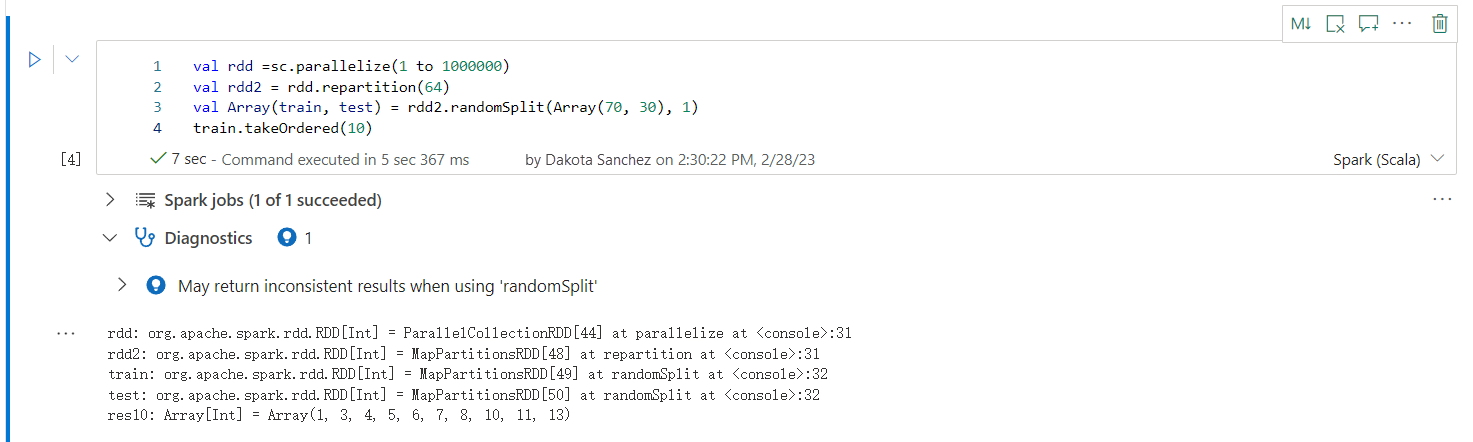
Avertissement
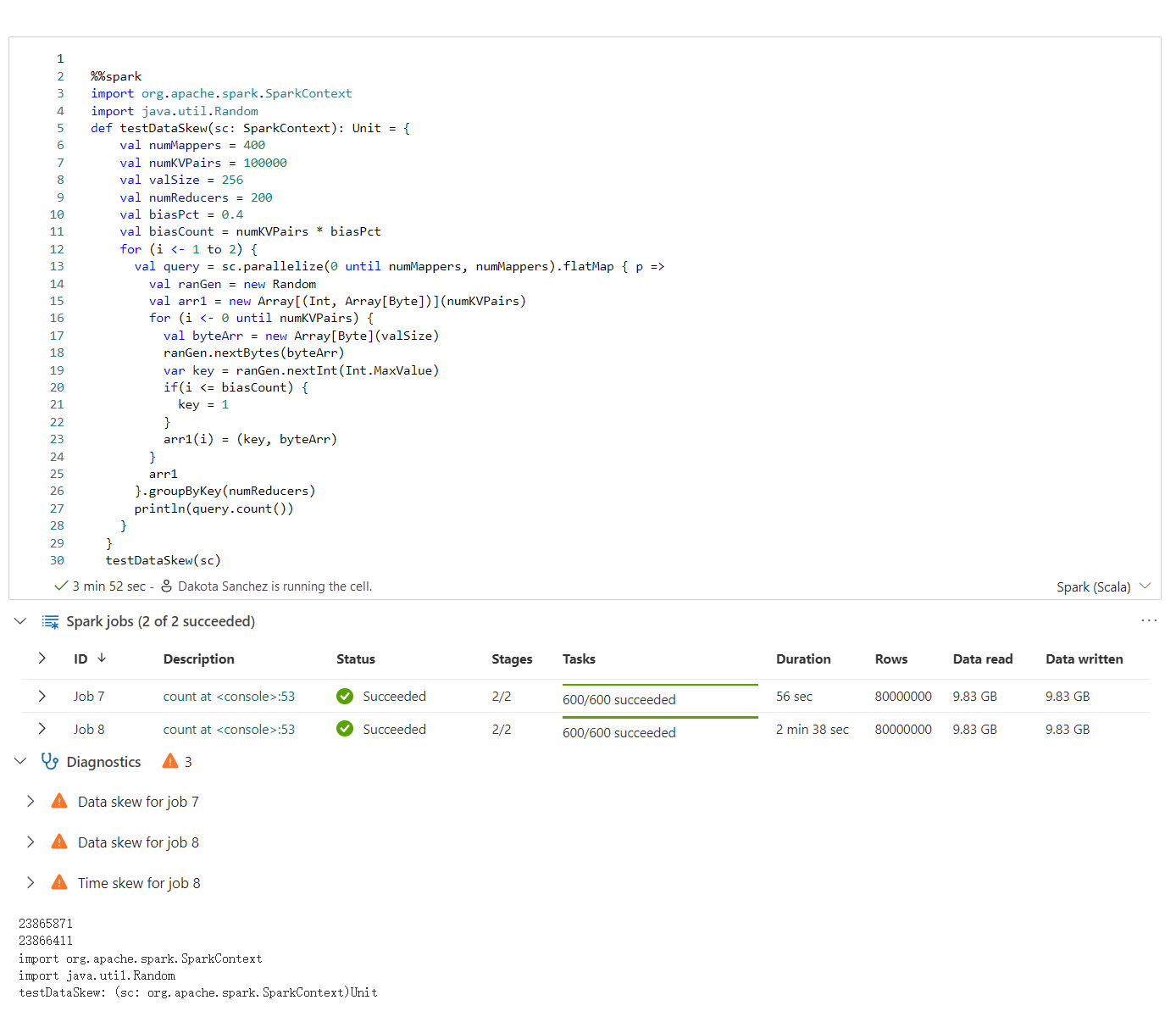
Erreur
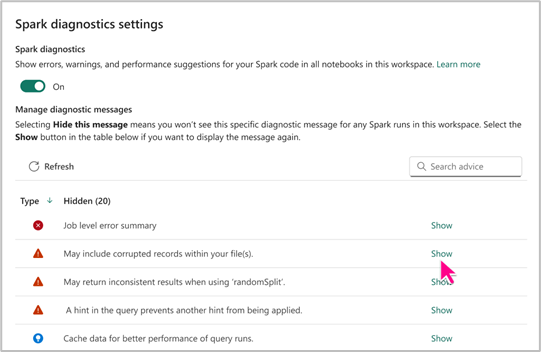
Paramètre Spark Advisor
Le paramètre Spark Advisor vous permet d'afficher ou de masquer des types spécifiques de conseils Spark en fonction de vos besoins. En outre, vous avez la possibilité d'activer ou de désactiver Spark Advisor pour vos notebooks au sein d'un espace de travail, en fonction de vos préférences.
Vous pouvez accéder aux paramètres de Spark Advisor au niveau de Fabric Notebook pour bénéficier de ses avantages. Cela vous permettra de créer des Notebooks productifs.