Tutoriel : Configurer la base de données mise en miroir Microsoft Fabric pour Azure Cosmos DB (préversion)
Dans ce tutoriel, vous configurez une base de données mise en miroir Fabric à partir d’un compte Azure Cosmos DB for NoSQL existant.
La mise en miroir réplique de manière incrémentielle les données Azure Cosmos DB dans Fabric OneLake en quasi-temps réel, sans affecter les performances des charges de travail transactionnelles ou sur l’utilisation d’unités de requête (RU). Vous pouvez générer des rapports Power BI directement sur les données dans OneLake, à l’aide du mode DirectLake. Vous pouvez exécuter des requêtes ad hoc en SQL ou Spark, créer des modèles de données à l’aide de notebooks et utiliser les fonctionnalités d’IA avancées et Copilot intégrées dans Fabric pour analyser les données.
Important
La mise en miroir d'Azure Cosmos DB est actuellement en préversion. Les charges de travail de production ne sont pas prises en charge dans la préversion. Seuls les comptes Azure Cosmos DB for NoSQL sont pris en charge.
Prérequis
- Un compte Azure Cosmos DB for NoSQL existant.
- Si vous n’avez pas d’abonnement Azure, essayez gratuitement Azure Cosmos DB for NoSQL.
- Si vous disposez d’un abonnement Azure, créez un compte Azure Cosmos DB for SQL.
- Une capacité existante de Microsoft Fabric. Si vous ne disposez d'aucune capacité existante, démarrez une version d'évaluation de Microsoft Fabric. La mise en miroir peut ne pas être disponible dans certaines régions Microsoft Fabric. Pour plus d’informations, consultez les régions prises en charge.
Conseil
Pendant la préversion publique, il est recommandé d'utiliser une copie de test ou de développement de vos données Azure Cosmos DB existantes qui peuvent être récupérées rapidement à partir d'une sauvegarde.
Configurer votre compte Azure Cosmos DB
Tout d'abord, vérifiez que le compte Azure Cosmos DB source est correctement configuré pour l'utiliser avec la mise en miroir Microsoft Fabric.
Dans le portail Azure, accédez à votre compte Azure Cosmos DB.
Assurez-vous que la sauvegarde continue est activée. Si elle n'est pas activée, suivez le guide de migration d'un compte Azure Cosmos DB existant vers une sauvegarde continue pour activer la sauvegarde continue. Les caractéristiques peuvent ne pas être disponibles dans certains scénarios. Pour plus d'informations, consultez limitations de base de données et de compte.
Assurez-vous que les options de mise en réseau sont définies sur accès au réseau public pour tous les réseaux. Si tel n'est pas le cas, suivez le guide de configuration de l'accès réseau à un compte Azure Cosmos DB.
Créer une base de données miroir
À présent, créez une base de données miroir qui est la cible des données répliquées. Pour plus d'informations, consultez Ce qu'il faut attendre d'une mise en miroir.
Accédez à la page d'accueil du portail Microsoft Fabric.
Ouvrez un espace de travail existant ou créez un espace de travail.
Dans le menu de navigation, sélectionnez Créer.
Sélectionnez Créer, recherchez la section Data Warehouse, puis sélectionnez Azure Cosmos DB en miroir (préversion).
Nommez la base de données miroir, puis sélectionnez Créer.
Se connecter à la base de données source
Ensuite, connectez la base de données source à la base de données miroir.
Dans la section Nouvelle connexion, sélectionnez Azure Cosmos DB for NoSQL.
Fournissez des identifiants pour le compte Azure Cosmos DB for NoSQL, notamment les articles suivants :
Valeur Point de terminaison Azure Cosmos DB Point de terminaison d'URL pour le compte source. Nom de connexion Unique nom pour la connexion. Type d'authentification Sélectionnez Clé de compte. Clé de compte Clé en lecture et en écriture pour le compte source. 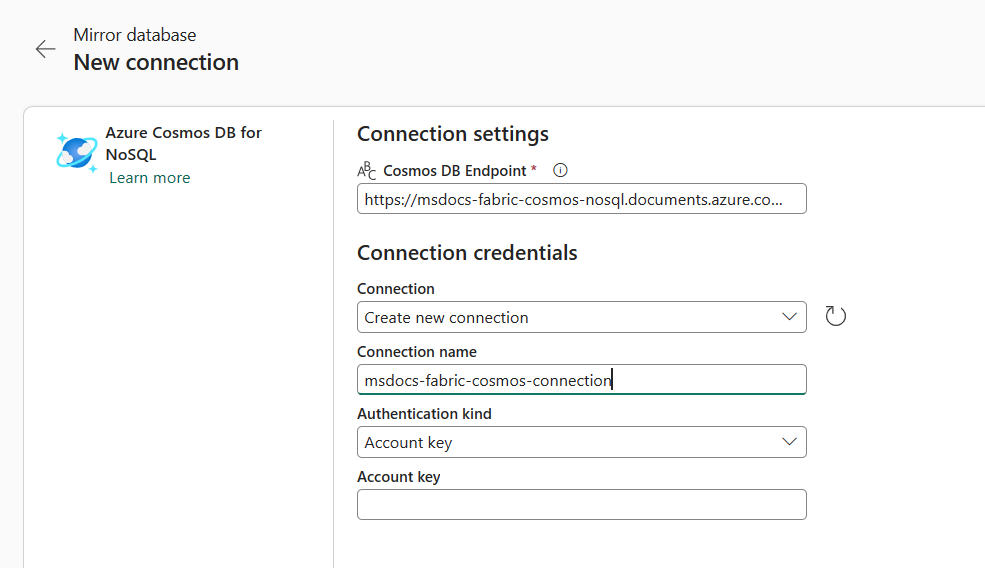
Sélectionnez Connecter. Sélectionnez ensuite une base de données à utiliser en miroir.
Remarque
Tous les conteneurs de la base de données sont en miroir.

Démarrer le processus de mise en miroir
Sélectionnez Base de données miroir. La mise en miroir commence maintenant.
Patientez deux à cinq minutes. Ensuite, sélectionnez Surveiller la réplication pour afficher l'état de l'action de réplication.
Au bout de quelques minutes, l'état doit passer à En cours d'exécution, ce qui indique que les conteneurs sont synchronisés.
Conseil
Si vous ne trouvez pas de conteneurs et l'état de réplication correspondant, patientez quelques secondes, puis actualisez le volet. Dans de rares cas, vous pouvez recevoir des messages d'erreur temporaires. Vous pouvez les ignorer en toute sécurité et continuer à les actualiser.
Lorsque la mise en miroir termine la copie initiale des conteneurs, une date apparaît dans la colonne de dernière actualisation. Si les données ont été répliquées avec succès, la colonne de ligne de total contient le nombre d'articles répliqués.
Surveiller la mise en miroir de Microsoft Fabric
À présent que vos données sont opérationnelles, il existe différents scénarios d'analyse disponibles dans l'ensemble de Microsoft Fabric.
Une fois la mise en miroir de Microsoft Fabric configurée, vous accédez automatiquement au volet État de la réplication.
Ici, surveillez l'état actuel de la réplication. Pour plus d’informations sur les états de réplication, consultez Surveiller la réplication de la base de données mise en miroir de Fabric.
Interroger la base de données source à partir de Microsoft Fabric
Utilisez le portail Microsoft Fabric pour explorer les données qui existent déjà dans votre compte Azure Cosmos DB, en interrogeant votre base de données Cosmos DB source.
Accédez à la base de données miroir dans le portail Microsoft Fabric.
Sélectionnez Vue, puis Base de données source. Cette action ouvre l'explorateur de données Azure Cosmos DB avec une vue en lecture seule de la base de données source.
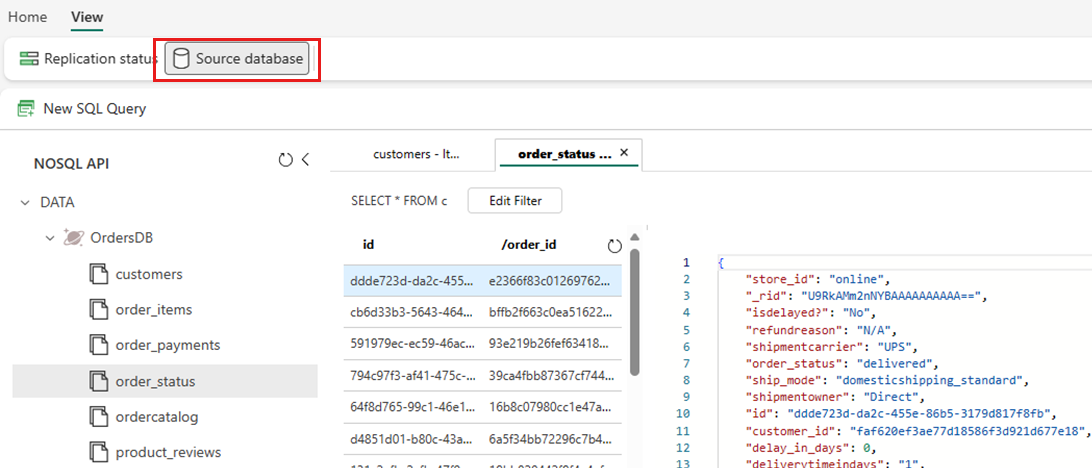
Sélectionnez un conteneur, puis ouvrez le menu local et sélectionnez Nouvelle requête SQL.
Permet d'exécuter une requête. Par exemple, utilisez
SELECT COUNT(1) FROM containerpour compter le nombre d'articles dans le conteneur.Remarque
Toutes les lectures de la base de données source sont acheminées vers Azure et consomment des unités de requête (RU) réparties sur le compte.

Analyser la base de données miroir cible
À présent, utilisez T-SQL pour interroger vos données NoSQL stockées dans Fabric OneLake.
Accédez à la base de données miroir dans le portail Microsoft Fabric.
Passez d'Azure Cosmos DB en miroir au point de terminaison d'analytique SQL.
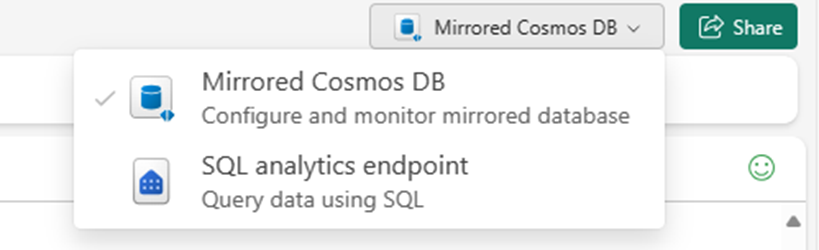
Chaque conteneur de la base de données source doit être déclaré dans le point de terminaison d'analytique SQL en tant que table d'entrepôt.
Sélectionnez n'importe quel tableau, ouvrez le menu local, puis sélectionnez Nouvelle requête SQL, puis sélectionnez Sélectionner le top 100.
La requête s'exécute et retourne 100 enregistrements dans la table sélectionnée.
Ouvrez le menu local de la même table et sélectionnez Nouvelle requête SQL. Écrivez un exemple de requête qui utilise des agrégats comme
SUM,COUNT,MIN, ouMAX. Joignez plusieurs tables dans l'entrepôt pour exécuter la requête sur plusieurs conteneurs.Remarque
Par exemple, cette requête s'exécuterait sur plusieurs conteneurs :
SELECT d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type], sum(o.[price]) as price, sum(o.[freight_value]) freight_value FROM [dbo].[products] p INNER JOIN [dbo].[OrdersDB_order_payments] p on o.[order_id] = p.[order_id] INNER JOIN [dbo].[OrdersDB_order_status] t ON o.[order_id] = t.[order_id] INNER JOIN [dbo].[OrdersDB_customers] c on t.[customer_id] = c.[customer_id] INNER JOIN [dbo].[OrdersDB_productdirectory] d ON o.product_id = d.product_id INNER JOIN [dbo].[OrdersDB_sellers] s on o.seller_id = s.seller_id GROUP BY d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type]Cet exemple endosse le nom de votre table et de vos colonnes. Utilisez votre table et vos colonnes lors de l'écriture de votre requête SQL.
Sélectionnez la requête, puis sélectionnez Enregistrer comme vue. Donnez à la vue un nom unique. Vous pouvez accéder à cette vue à tout moment à partir du portail Microsoft Fabric.
Retournez à la base de données miroir dans le portail Microsoft Fabric.
Sélectionnez Nouvelle requête d'objet visuel. Utilisez l'éditeur de requête pour créer des requêtes complexes.
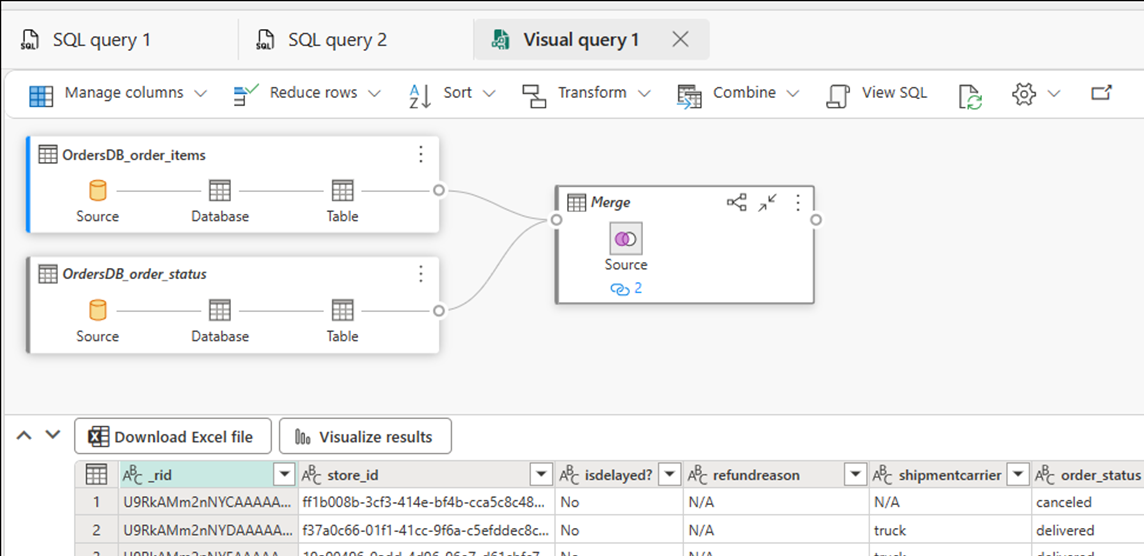


Créer des rapports BI sur les requêtes ou vues SQL
- Sélectionnez la requête ou la vue, puis sélectionnez Explorer ces données (préversion). Cette action explore la requête dans Power BI directement à l'aide de Direct Lake sur OneLake miroir données.
- Modifiez les graphiques en fonction des besoins et enregistrez le rapport.
Conseil
Vous pouvez également utiliser Copilot ou d'autres améliorations pour créer des tableaux de bord et des rapports sans déplacement des données supplémentaire.
Autres exemples
En savoir plus sur l'accès et l'interrogation des données Azure Cosmos DB en miroir dans Microsoft Fabric :
- Comment faire : interroger les données imbriquées mises en miroir Microsoft Fabric à partir d’Azure Cosmos DB (préversion)
- Aide et astuces pour accéder aux données Azure Cosmos DB en miroir dans Lakehouse et notebooks à partir de Microsoft Fabric (préversion)
- Guide pratique pour joindre des données Azure Cosmos DB mises en miroir avec d’autres bases de données mises en miroir dans Microsoft Fabric (préversion)