Obtenir des données à partir du hub Real-Time (aperçu)
Dans cet article, vous apprendrez comment obtenir des events à partir du hub Real-Time existant dans un tableau nouveau ou existant.
Important
Cette fonctionnalité est en version préliminaire.
Remarque
Actuellement, le hub Real-Time prend uniquement en charge les flux d’événements en tant que source. Le hub Real-Time est actuellement en version préliminaire.
Prérequis
- Un espace de travail avec une capacité compatible Microsoft Fabric
- Une base de données KQL avec des autorisations de modification
- Un eventstream avec une source de données
Source
Pour obtenir des données à partir du hub Real-Time, vous devez sélectionner un flux Real-Time à partir du hub de données en temps réel en tant que source de données. Vous pouvez sélectionner le hub Real-Time en procédant comme suit :
Dans le ruban inférieur de votre base de données KQL, procédez comme suit :
Dans le menu déroulant Obtenir des données, puis sous Continu, sélectionnez Hub Real-Time (aperçu).
Sélectionnez Obtenir des données, puis dans la fenêtre Obtenir des données, sélectionnez un flux dans la section Hub Real-Time.

Sélectionnez un flux de données dans la liste des flux de hub Real-Time.

Configurer
Sélectionner la table cible. Si vous souhaitez ingérer des données dans une nouvelle table, sélectionnez +Nouvelle table et entrez un nom de table.
Remarque
Les noms de tables peuvent comporter jusqu’à 1024 caractères, y compris des espaces, des caractères alphanumériques, des traits d’union et des traits de soulignement. Les caractères spéciaux ne sont pas pris en charge.
Sous Configurer la source de données, renseignez les paramètres à l’aide des informations contenues dans la table suivante. Certaines informations de paramètre remplissent automatiquement votre flux d’événements.
Paramètre Description Espace de travail Emplacement de votre espace de travail eventstream. Le nom de votre espace de travail est automatiquement rempli. Nom de l’eventstream Nom de votre eventstream. Votre nom eventstream est automatiquement rempli. Nom de la connexion de données Nom utilisé pour référencer et gérer votre connexion de données dans votre espace de travail. Le nom de la connexion de données est automatiquement rempli. En option, vous pouvez saisir un nouveau nom. Le nom ne peut contenir que des caractères alphanumériques, des tirets et des points, et contenir jusqu’à 40 caractères. Traiter l’événement avant l’ingestion dans Eventstream Cette option vous permet de configurer le traitement des données avant l’ingestion des données dans la table de destination. Si cette option est sélectionnée, vous poursuivez le processus d’ingestion des données dans Eventstream. Pour plus d’informations, consultez Traiter l’événement avant l’ingestion dans Eventstream. Filtres avancés Compression Compression des données des événements provenant du Hub. Les options sont Aucune (valeur par défaut) ou GZip. Propriétés du système d’événements S’il existe plusieurs enregistrements par message d’événement, les propriétés système sont ajoutées au premier enregistrement. Pour plus d’informations, consultez Propriétés du système d’événements. Date de début de la récupération d’événement La connexion de données récupère les événements existants créés depuis la date de début de la récupération d’événements. Elle peut uniquement récupérer les événements conservés par le Hub en fonction de sa période de rétention. Le fuseau horaire est UTC. Si aucune heure n’est spécifiée, l’heure par défaut correspond à l’heure de création de la connexion de données. Sélectionnez Suivant.

Traiter l’événement avant l’ingestion dans Eventstream
L’option Traiter l’événement avant l’ingestion dans Eventstream vous permet de traiter les données avant qu’elles soient ingérées dans la table de destination. En sélectionnant cette option, le processus d’obtention des données se poursuit en toute transparence dans Eventstream, avec les détails de la table de destination et de la source de données automatiquement renseignés.
Pour traiter l’événement avant l’ingestion dans Eventstream :
Sous l’onglet Configurer, sélectionnez Traiter les événements avant l’ingestion dans Eventstream.
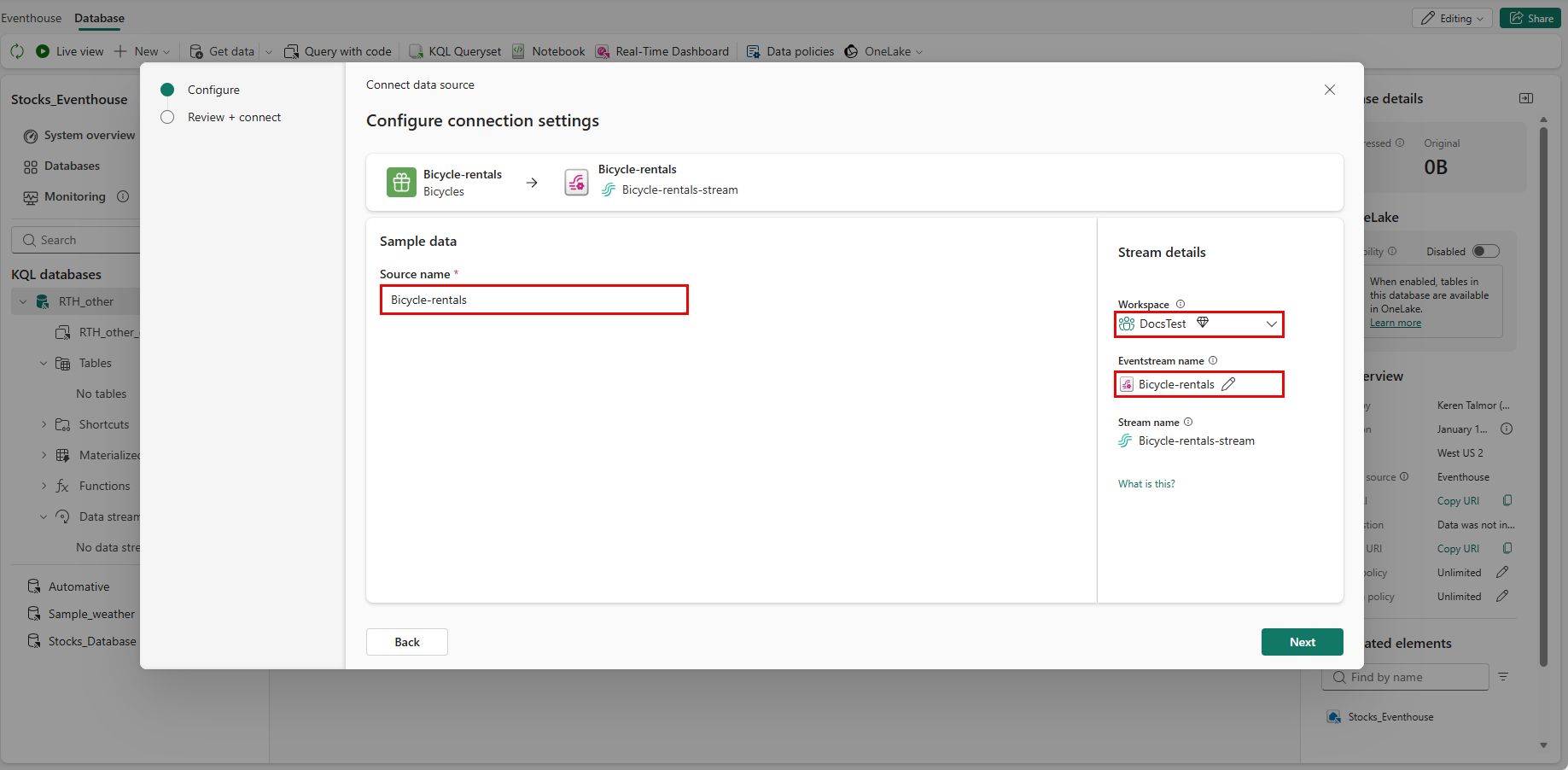
Dans la boîte de dialogue Traiter les événements dans Eventstream, sélectionnez Continuer dans Eventstream.
Important
La sélection de Continuer dans Eventstream met fin au processus d’obtention des données dans Real-Time Intelligence et se poursuit dans Eventstream avec la table de destination et les détails sur la source de données automatiquement renseignés.
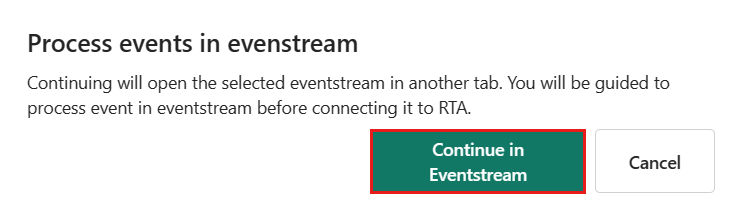
Dans Eventstream, sélectionnez le nœud de destination de la base de données KQL et, dans le volet Base de données KQL, vérifiez que l’option Traitement des événements avant l’ingestion est sélectionnée et que les détails de destination sont corrects.
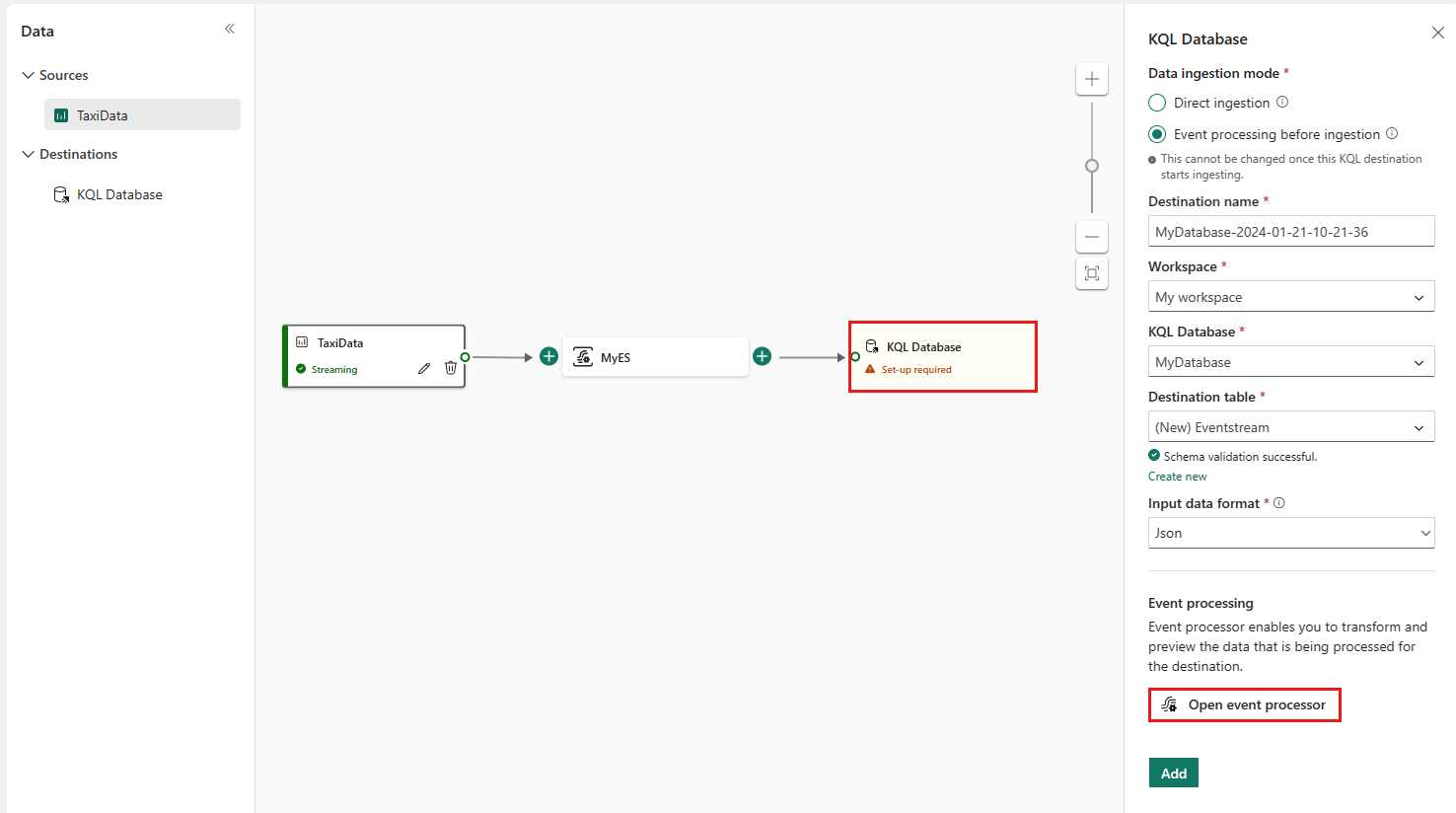
Sélectionnez Ouvrir le processeur d’événements pour configurer le traitement des données, puis sélectionnez Enregistrer. Pour plus d’informations, consultez Traiter les données d’événement avec l’éditeur du processeur d’événements.
Dans le volet Base de données KQL, sélectionnez Ajouter pour terminer la configuration du nœud de destination de la base de données KQL.
Vérifiez que les données sont ingérées dans la table de destination.


Remarque
L’événement de processus avant l’ingestion dans le processus Eventstream est terminé et les étapes restantes de cet article ne sont pas requises.
Inspecter
L’onglet Inspecter s’ouvre avec un aperçu des données.
Pour terminer le processus d’ingestion, sélectionnez Terminer.

Si vous le souhaitez :
- Sélectionnez Visionneuse de commandes pour afficher et copier les commandes automatiques générées à partir de vos entrées.
- Modifiez le format de données déduit automatiquement en sélectionnant le format souhaité dans la liste déroulante. Les données sont lues à partir du hub sous forme d’objets EventData. Les formats pris en charge sont : Avro, Apache Avro, CSV, JSON, ORC, Parquet, PSV, RAW, SCsv, SOHsv, TSV, TXT, and TSVE.
- Modifier les colonnes.
- Explorez les options avancées basées sur le type de données.
Modifier les colonnes
Remarque
- Pour les formats tabulaires (CSV, TSV, PSV), vous ne pouvez pas mapper deux fois une même colonne. Pour effectuer un mappage à une colonne existante, commencez par supprimer la nouvelle colonne.
- Vous ne pouvez pas changer un type de colonne existant. Si vous essayez de mapper à une colonne avec un format différent, vous risquez de vous retrouver avec des colonnes vides.
Les modifications que vous pouvez apporter dans une table dépendent des paramètres suivants :
- Si le type de la table est nouveau ou existant
- Si le type du mappage est nouveau ou existant
| Type de la table | Type de mappage | Ajustements disponibles |
|---|---|---|
| Nouvelle table | Nouveau mappage | Renommer une colonne, modifier le type de données, modifier la source de données, transformation de mappage, ajouter une colonne, supprimer une colonne |
| Table existante | Nouveau mappage | Ajoutez une colonne (vous pourrez ensuite modifier le type de données, la renommer ou la mettre à jour) |
| Table existante | Mappage existant | Aucune |

Mappage des transformations
Certains mappages de format de données (Parquet, JSON et Avro) prennent en charge des transformations simples au moment de l’ingestion. Pour appliquer des transformations de mappage, créez ou mettez à jour une colonne dans la fenêtre Modifier les colonnes.
Les transformations de mappage peuvent être effectuées sur une colonne de type string ou datetime, avec la source dont le type de données est int ou long. Les transformations de mappage prises en charge sont :
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Options avancées basées sur le type de données
Tabulaire (CSV, TSV, PSV) :
Les données tabulaires n’incluent pas nécessairement les noms de colonnes utilisés pour mapper les données sources aux colonnes existantes. Pour utiliser la première ligne comme noms de colonnes, activez l’option Première ligne comme en-tête de colonne.

JSON :
Pour déterminer la division de colonnes des données JSON, sélectionnez Avancé>Niveaux imbriqués, de 1 à 100.

Résumé
Dans la fenêtre Préparation des données, les trois étapes sont signalées par des coches vertes quand l’ingestion des données s’est terminée avec succès. Vous pouvez sélectionner une carte à interroger, supprimer les données ingérées ou afficher un tableau de bord de votre résumé d’ingestion. Sélectionnez Fermer pour fermer la fenêtre.

Contenu connexe
- Pour gérer votre base de données, consultez Gérer les données
- Pour créer, stocker et exporter des requêtes, consultez Interroger des données dans un ensemble de requêtes KQL
- Pour obtenir des données à partir d’un nouvel eventstream, consultez Obtenir des données à partir d’un nouvel eventstream