Événement
Championnats du monde Power BI DataViz
14 févr., 16 h - 31 mars, 16 h
Avec 4 chances d’entrer, vous pourriez gagner un package de conférence et le rendre à la Live Grand Finale à Las Vegas
En savoir plusCe navigateur n’est plus pris en charge.
Effectuez une mise à niveau vers Microsoft Edge pour tirer parti des dernières fonctionnalités, des mises à jour de sécurité et du support technique.
Les agrégations dans Power BI peuvent améliorer les performances des requêtes sur les modèles sémantiques DirectQuery volumineux. L’utilisation d’agrégations permet de mettre les données en cache à un niveau agrégé. Les agrégations dans Power BI peuvent être configurées manuellement dans le modèle de données, comme décrit dans cet article. Pour les abonnements Premium, activez automatiquement la fonctionnalité d’agrégations automatiques dans les paramètres du modèle.
Selon le type de source de données, une table d’agrégations peut être créée à la source de données en tant que table ou vue, requête native. Pour des performances optimales, créez une table d’agrégations en tant que table d’importation créée dans Power Query. Ensuite, dans la boîte de dialogue Gérer les agrégations de Power BI Desktop, vous définissez des agrégations pour les colonnes d’agrégation avec des propriétés de synthèse, de table de détails et de colonne de détails.
Les sources de données dimensionnelles, telles que les entrepôts de données et les mini-Data Warehouses, peuvent utiliser des agrégations basées sur les relations. Souvent, les sources de big data basées sur Hadoop basent les agrégations sur les colonnes GroupBy. Cet article décrit les principales différences dans la modélisation des données Power BI pour chaque type de source de données.
Dans le volet Données de n’importe quelle vue Power BI Desktop, cliquez avec le bouton droit sur la table d’agrégations, puis sélectionnez Gérer les agrégations.
La boîte de dialogue Gérer les agrégations montre une ligne pour chaque colonne de la table, où vous pouvez spécifier le comportement d’agrégation. Dans l’exemple suivant, les requêtes adressées à la table de détails Sales sont redirigées en interne vers la table d’agrégation Sales Agg.
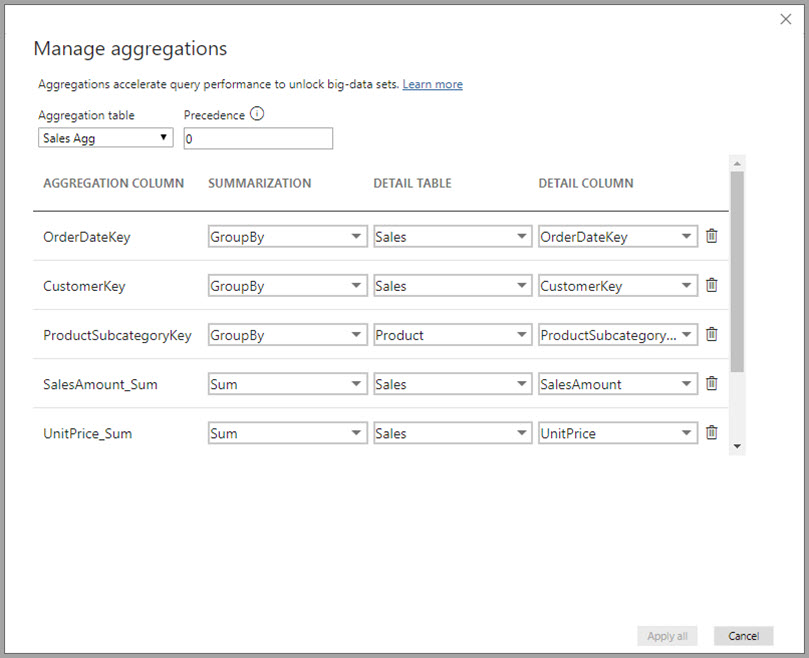
Dans cet exemple d’agrégation basée sur les relations, les entrées GroupBy sont facultatives. À l’exception de DISTINCTCOUNT, elles n’affectent pas le comportement d’agrégation et sont principalement utilisées pour une meilleure lisibilité. Sans les entrées GroupBy, les agrégations obtiendraient quand même des correspondances, en fonction des relations. Cela diffère de l’exemple de Big Data plus loin dans cet article, où les entrées GroupBy sont requises.
La boîte de dialogue Gérer les agrégations applique des validations :
La plupart des validations sont appliquées en désactivant les valeurs de liste déroulante et en affichant un texte explicatif dans l’info-bulle.
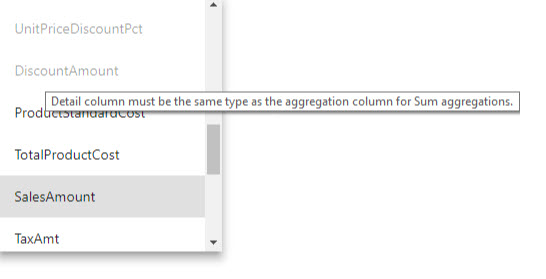
Les utilisateurs disposant d’un accès en lecture seule au modèle ne peuvent pas interroger les tables d’agrégation. L’accès en lecture seule évite des problèmes de sécurité en cas d’utilisation avec la sécurité au niveau des lignes (RLS). Les consommateurs et les requêtes font référence à la table de détails, et non pas à la table d’agrégation, et n’ont pas besoin de connaître la table d’agrégation.
Pour cette raison, les tables d’agrégation sont masquées dans la vue Rapport. Si la table n’est pas déjà masquée, la boîte de dialogue Gérer les agrégations la définit comme masquée lorsque vous sélectionnez Appliquer tout.
La fonctionnalité d’agrégation interagit avec les modes de stockage de niveau table. Les tables Power BI peuvent utiliser les modes de stockage DirectQuery, Importer ou Double. DirectQuery interroge directement le back-end, tandis que le mode Importer met en cache les données en mémoire et envoie les requêtes aux données mises en cache. Toutes les sources de données DirectQuery non multidimensionnelles et d’importation Power BI fonctionnent avec les agrégations.
Pour définir le mode de stockage d’une table agrégée sur Importer pour accélérer les requêtes, sélectionnez la table agrégée dans la vue Modèle de Power BI Desktop. Dans le volet Propriétés, développez Avancé, déroulez la liste de sélection Mode de stockage et sélectionnez Importer. La modification de l’importation est irréversible.
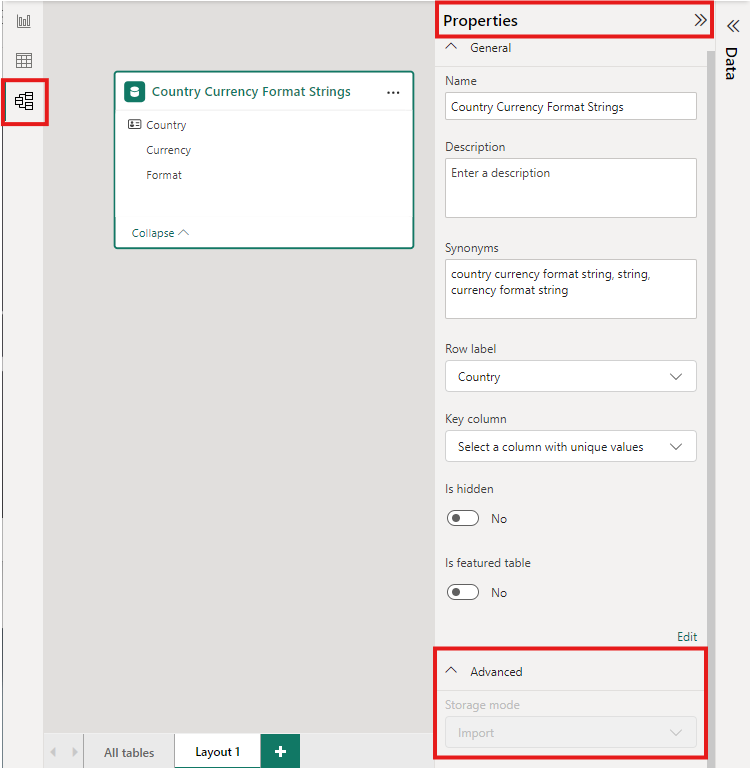
Pour en savoir plus sur les modes de stockage des tables, consultez Gérer le mode de stockage dans Power BI Desktop.
Pour fonctionner correctement pour les agrégations, les expressions de sécurité au niveau des lignes (SNL) doivent filtrer la table d’agrégation et la table de détails.
Dans l’exemple suivant, l’expression SNL sur la table Geography fonctionne pour les agrégations, car Geography se trouve du côté du filtrage des relations avec les tables Sales et Sales Agg. La sécurité au niveau des lignes est appliquée aussi bien aux requêtes qui accèdent à la table d’agrégation qu’à celles qui n’y accèdent pas.
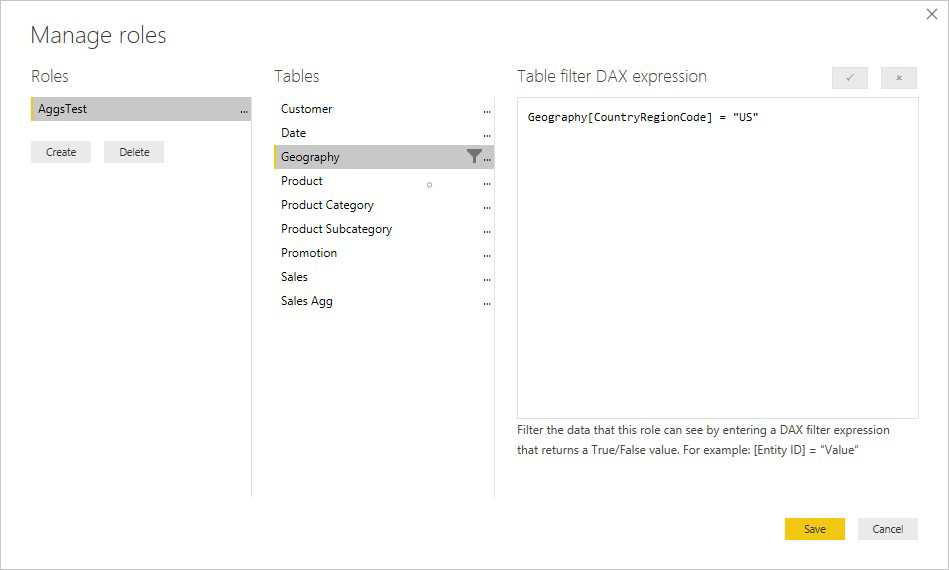
Une expression SNL sur la table Product filtre seulement la table de détails Sales, et non pas la table agrégée Sales Agg. La table d’agrégation étant une autre représentation des données de la table de détails, il ne serait pas sûr de répondre aux requêtes à partir de la table d’agrégation si le filtre SNL ne peut pas être appliqué. Le filtrage de la table de détails uniquement n’est pas recommandé, car les requêtes utilisateur issues de ce rôle ne bénéficient pas des accès à l’agrégation.
Une expression SNL qui filtrerait uniquement la table d’agrégation Sales Agg et pas la table de détails Sales n’est pas autorisée.

Pour les agrégations basées sur les colonnes GroupBy, une expression SNL appliquée à la table de détails peut être utilisée pour filtrer la table d’agrégation, car toutes les colonnes GroupBy de la table d’agrégation sont couvertes par la table de détails. En revanche, un filtre SNL sur la table d’agrégation ne peut pas être appliqué à la table de détails et il est donc interdit.
Les modèles dimensionnels utilisent généralement des agrégations basées sur des relations. Les modèles Power BI issus d’entrepôts de données et de datamart ressemblent à des schémas en étoile/flocons de neige, avec des relations entre les tables de dimension et les tables de faits.
Dans l’exemple suivant, le modèle obtient des données à partir d’une source de données unique. Les tables utilisent le mode de stockage DirectQuery. La table de faits Sales contient des milliards de lignes. La définition du mode de stockage de Sales sur Importer pour la mise en cache entraînerait une charge de mémoire et de ressources considérable.
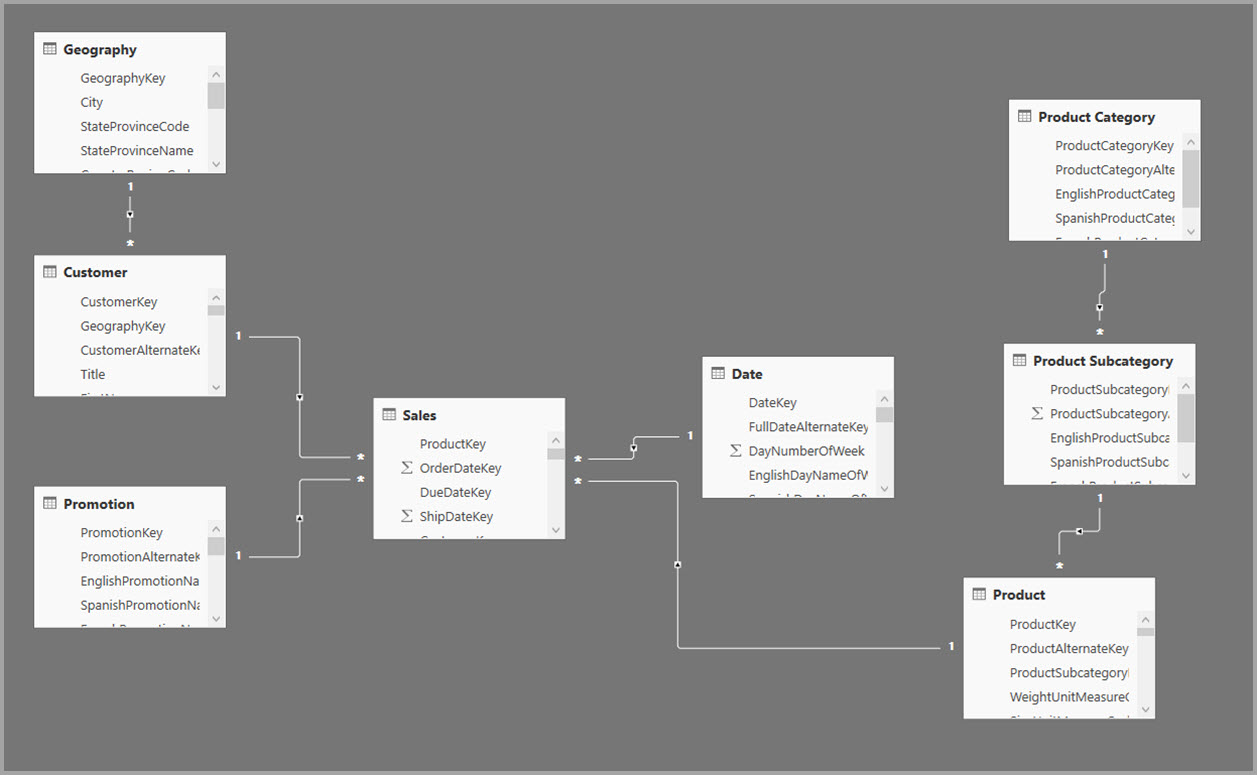
À la place, créez la table d’agrégation Sales Agg. Dans la table Sales Agg, le nombre de lignes est égal à la somme des SalesAmount regroupés par CustomerKey, DateKey et ProductSubcategoryKey. La table Sales Agg figure à un niveau de précision plus élevé que Sales. Par conséquent, au lieu de milliards, elle peut contenir des millions de lignes, ce qui est plus facile à gérer.
Si les tables de dimension suivantes sont les plus couramment utilisées pour les requêtes à forte valeur métier, elles peuvent filtrer Sales Agg à l’aide de relations un-à-plusieurs ou plusieurs-à-un.
L’image suivante illustre ce modèle.
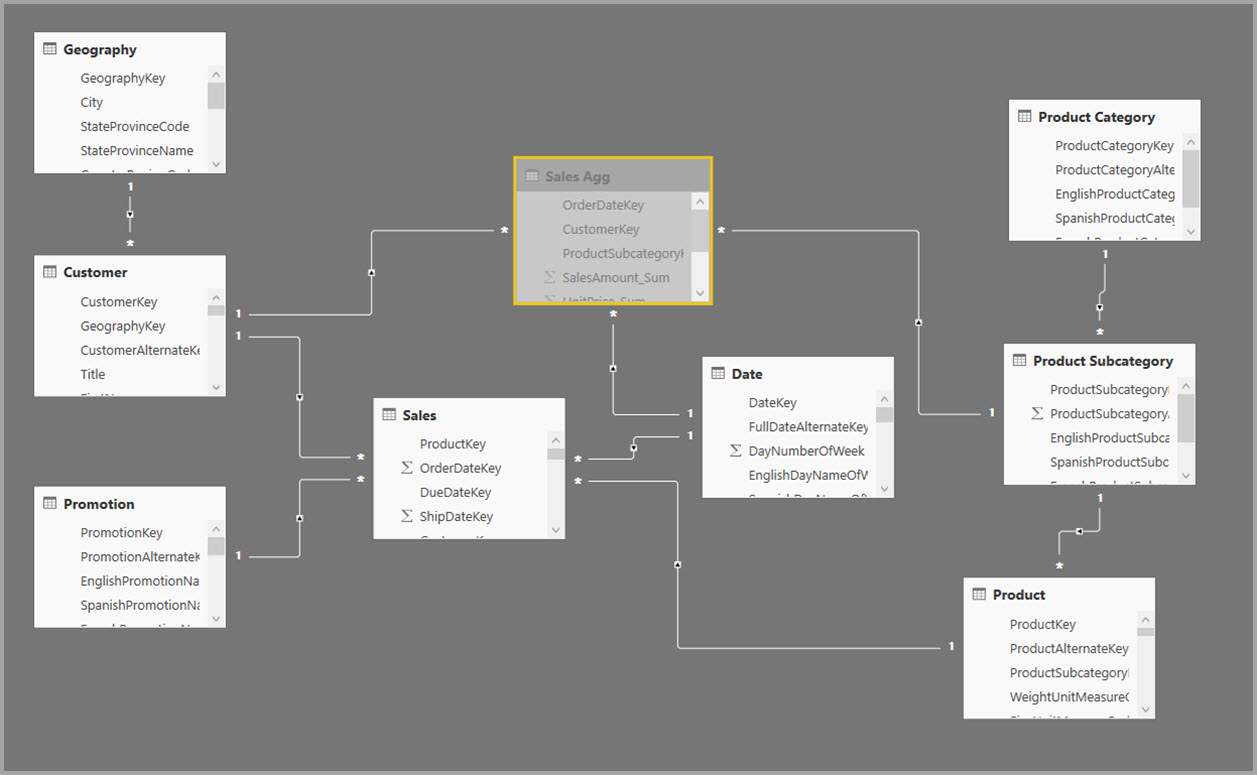
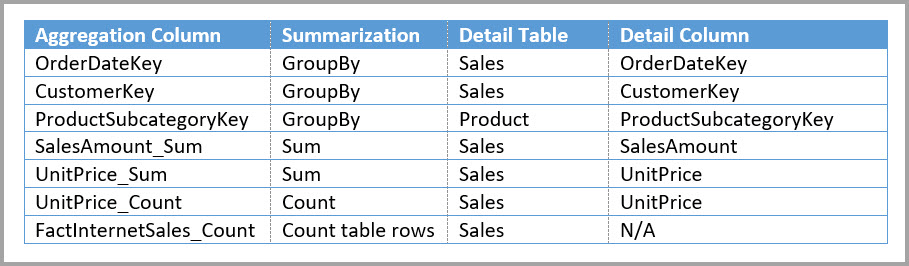
Le tableau suivant présente les agrégations pour la table Sales Agg.
Note
La table Sales Agg, comme toute autre table, offre la flexibilité de pouvoir être chargée de différentes manières. L’agrégation peut être effectuée dans la base de données source à l’aide de processus ETL/ELT, ou par l’expression M pour la table. La table agrégée peut utiliser le mode de stockage Importer, avec ou sans actualisation incrémentielle pour les modèles sémantiques, ou elle peut utiliser DirectQuery et être optimisée pour les requêtes rapides à l’aide des index columnstore. Cette flexibilité permet d’obtenir des architectures équilibrées capables de répartir la charge des requêtes pour éviter les goulots d’étranglement.
Le remplacement du mode de stockage de la table agrégée Sales Agg par Importer ouvre une boîte de dialogue indiquant que les tables de dimension associées peuvent être définies sur le mode de stockage Double.
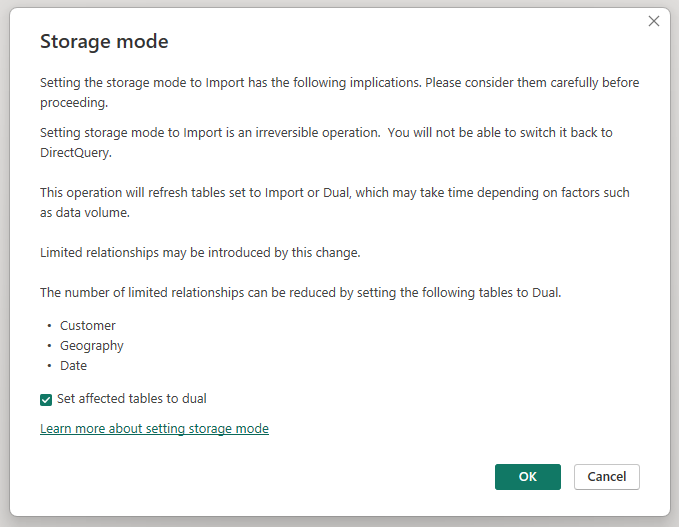
La configuration des tables de dimension associées en mode Double leur permet d’agir comme si elles étaient en mode Importer ou DirectQuery, en fonction de la sous-requête. Dans l’exemple :
Pour plus d’informations sur le mode de stockage Double, consultez Gérer le mode de stockage dans Power BI Desktop.
Les occurrences d’agrégations basées sur des relations nécessitent des relations régulières.
Les relations régulières incluent les combinaisons de modes de stockage suivantes, où les deux tables proviennent d’une source unique :
| Table côté plusieurs | Table côté 1 |
|---|---|
| Double | Double |
| Importer | Importer ou Double |
| DirectQuery | DirectQuery ou Double |
Le seul cas où une relation inter-sources est considérée comme régulière est celui où les deux tables sont en mode Importer. Les relations plusieurs-à-plusieurs sont toujours considérées comme limitées.
Pour les accès à l’agrégation inter-sources qui ne dépendent pas de relations, consultez Agrégation en fonction des colonnes GroupBy.
La requête suivante atteint l’agrégation, car les colonnes de la table Date sont au niveau de granularité qui peut atteindre l’agrégation. La colonne SalesAmount utilise l’agrégation Somme.

La requête suivante n’atteint pas l’agrégation. Bien qu’elle demande la somme de SalesAmount, la requête effectue une opération GroupBy sur une colonne de la table Product, dont le niveau de précision ne permet pas d’accéder à l’agrégation. Si vous observez les relations dans le modèle, une sous-catégorie de produit peut avoir plusieurs lignes Product. La requête ne peut pas déterminer le produit dans lequel effectuer l’agrégation. Dans ce cas, la requête rebascule vers DirectQuery et soumet une requête SQL à la source de données.

Les agrégations ne sont pas uniquement destinées à des calculs simples qui effectuent une simple addition. Les calculs complexes peuvent également en tirer parti. Conceptuellement, un calcul complexe est divisé en sous-requêtes pour chaque SUM, MIN, MAX et COUNT. Chaque sous-requête est évaluée pour déterminer si elle peut atteindre l’agrégation. Si cette logique n’est pas valable dans tous les cas en raison de l’optimisation du plan de requête, elle doit d’une manière générale s’appliquer. L’exemple suivant atteint l’agrégation :

La fonction COUNTROWS peut tirer parti des agrégations. La requête suivante accède à l’agrégation, car il y a une agrégation Compter les lignes de la table définie pour la table Sales.

La fonction AVERAGE peut tirer parti des agrégations. La requête suivante atteint l’agrégation, car AVERAGE équivaut en interne à une SUM divisée par un COUNT. Étant donné que la colonne UnitPrice a des agrégations définies pour SUM et COUNT, l’agrégation est atteinte.

Dans certains cas, la fonction DISTINCTCOUNT peut tirer parti des agrégations. La requête suivante atteint l’agrégation, car il existe une entrée GroupBy pour CustomerKey, qui préserve le caractère distinct de CustomerKey dans la table d’agrégation. Cette technique peut encore atteindre le seuil de performances, où une quantité de valeurs distinctes comprise entre deux et cinq millions peut affecter le niveau de performance des requêtes. Toutefois, elle peut être utile dans les scénarios où il existe des milliards de lignes dans la table de détails mais entre deux et cinq millions de valeurs distinctes dans la colonne. Dans ce cas, la fonction DISTINCTCOUNT peut être plus rapide que l’analyse de la table contenant des milliards de lignes, même si elles ont été mises en cache en mémoire.

Les fonctions temporelles Data Analysis Expressions (DAX) prennent en charge l’agrégation. La requête suivante atteint l’agrégation, car la fonction DATESYTD génère une table de valeurs CalendarDay et la table d’agrégation se situe à un niveau de précision couvert pour les colonnes group-by dans la table Date. Il s’agit d’un exemple de filtre table pour la fonction CALCULATE, qui peut fonctionner avec des agrégations.

Les modèles de Big Data basés sur Hadoop ont des caractéristiques différentes des modèles dimensionnels. Pour éviter les jointures entre les grandes tables, les modèles de Big Data n’utilisent souvent pas de relations, mais dénormalisent les attributs de dimension en tables de faits. Vous pouvez déverrouiller ces modèles de Big Data pour effectuer une analyse interactive à l’aide d’agrégations basées sur des colonnes GroupBy.
Le tableau suivant contient la colonne numérique Movement à agréger. Toutes les autres colonnes sont des attributs permettant d’effectuer des regroupements. La table contient des données IoT et un très grand nombre de lignes. Le mode de stockage est DirectQuery. Les requêtes, sur la source de données, qui agrègent sur l’ensemble du modèle sont lentes en raison du volume élevé.
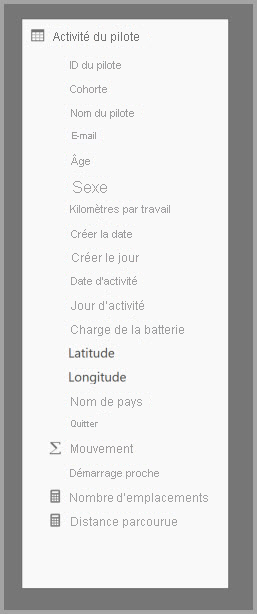
Pour permettre une analyse interactive sur ce modèle, vous pouvez ajouter une table d’agrégation qui effectue des regroupements selon la plupart des attributs, mais exclut les attributs à cardinalité élevée comme la longitude et la latitude. Cela réduit considérablement le nombre de lignes, qui est suffisamment petit pour tenir confortablement dans un cache en mémoire.
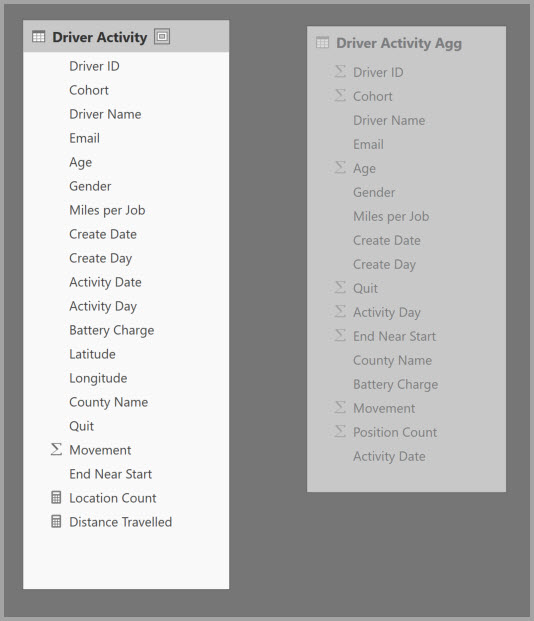
Vous définissez les mappages d’agrégation pour la table Driver Activity Agg dans la boîte de dialogue Gérer les agrégations.
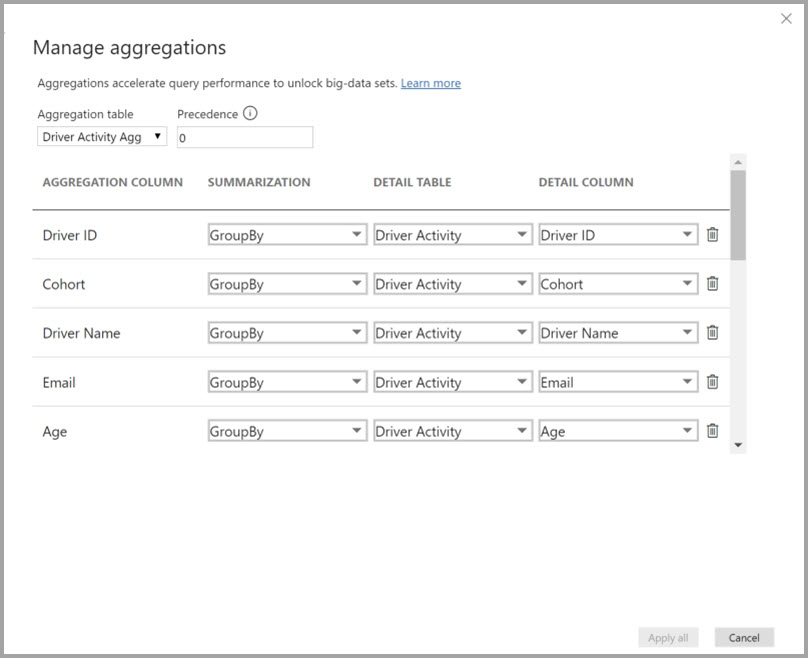
Dans les agrégations basées sur des colonnes GroupBy, les entrées GroupBy ne sont pas facultatives. Sans elles, les agrégations ne sont pas atteintes. Cela diffère de l’utilisation d’agrégations basées sur des relations, où les entrées GroupBy sont facultatives.
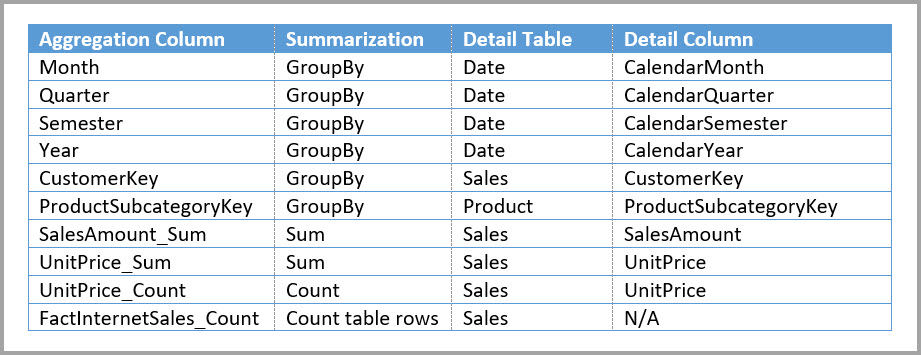
Le tableau suivant présente les agrégations pour la table Driver Activity Agg.
Vous pouvez définir le mode de stockage de la table agrégée Driver Activity Agg sur Importer.
La requête suivante accèdent à l’agrégation, car la colonne Activity Date est couverte par la table d’agrégation. La fonction COUNTROWS utilise l’agrégation Lignes de la table comptées.

Il est judicieux d’utiliser des agrégations Compter les lignes de la table, en particulier pour les modèles qui contiennent des attributs de filtre dans les tables de faits. Power BI peut soumettre des requêtes au modèle à l’aide de COUNTROWS dans des cas où cela n’est pas demandé explicitement par l’utilisateur. Par exemple, la boîte de dialogue de filtres indique le nombre de lignes pour chaque valeur.
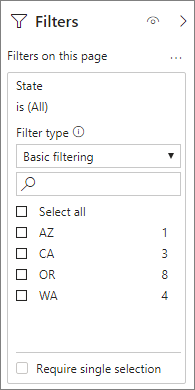
Vous pouvez combiner les relations et les techniques des colonnes GroupBy pour les agrégations. Les agrégations basées sur les relations peuvent nécessiter le fractionnement en plusieurs tables des tables de dimension dénormalisées. Si cette opération est coûteuse ou difficile pour certaines tables de dimension, vous pouvez répliquer les attributs nécessaires dans la table d’agrégation pour ces dimensions et utiliser des relations pour les autres.
Par exemple, le modèle suivant réplique Month, Quarter, Semester et Year dans la table Sales Agg. Il n’existe aucune relation entre Sales Agg et la table Date, mais il existe des relations avec Customer et Product Subcategory. Le mode de stockage de Sales Agg est Importer.
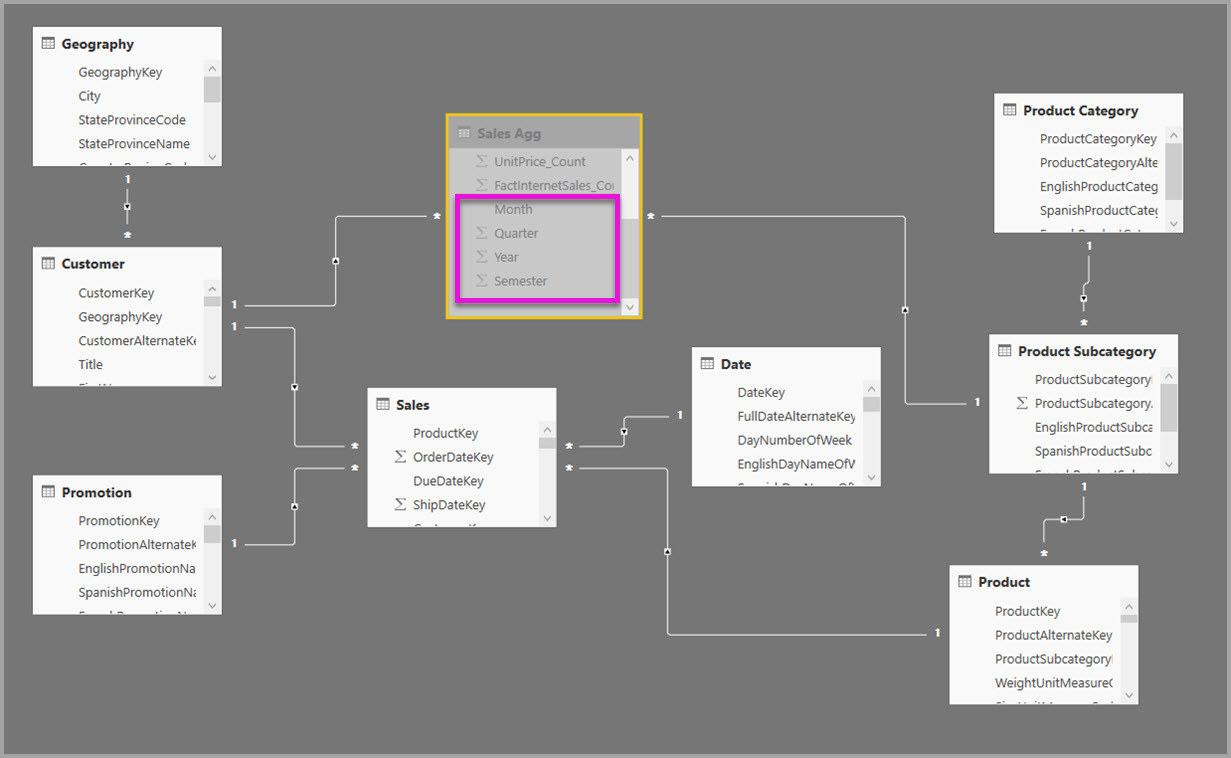
Le tableau suivant présente les entrées définies dans la boîte de dialogue Gérer les agrégations pour la table Sales Agg. Les entrées GroupBy où Date est la table de détails sont obligatoires pour accéder aux agrégations pour les requêtes qui regroupent par les attributs Date. Comme dans l’exemple précédent, les entrées GroupBy pour CustomerKey et ProductSubcategoryKey n’affectent pas les accès à l’agrégation, à l’exception de DISTINCTCOUNT, en raison de la présence des relations.
La requête suivante accède à l’agrégation, car la table d’agrégation couvre CalendarMonth et CategoryName est accessible via des relations un-à-plusieurs. SalesAmount utilise l’agrégation SUM.

La requête suivante n’accède pas à l’agrégation, car la table d’agrégation ne couvre pas CalendarDay.

La requête temporelle suivante n’accède pas à l’agrégation, car la fonction DATESYTD génère une table de valeurs CalendarDay et la table d’agrégation ne couvre pas CalendarDay.

La précédence d’agrégation permet à plusieurs tables d’agrégation d’être prises en compte par une sous-requête unique.
L’exemple suivant est un modèle composite contenant plusieurs sources :
Note
Les tables d’agrégation en mode DirectQuery qui utilisent une source de données différente de la table de détails sont uniquement prises en charge si la table d’agrégation provient d’une source SQL Server, Azure SQL ou Azure Synapse Analytics (anciennement SQL Data Warehouse).
L’encombrement mémoire de ce modèle est relativement faible, mais il déverrouille un modèle volumineux. Il représente une architecture équilibrée, car il répartit la charge des requêtes entre les composants de l’architecture et les utilise en fonction de leurs points forts.
La boîte de dialogue Agrégations gérées pour Driver Activity Agg2 définit le champ Précédence sur 10, ce qui est supérieur à la précédence pour Driver Activity Agg. Le paramètre de priorité plus élevé signifie que les requêtes qui utilisent des agrégations prennent d’abord en compte Driver Activity Agg2. Les sous-requêtes qui ne présentent pas la précision pouvant être satisfaite par Driver Activity Agg2 considèrent Driver Activity Agg à la place. Les requêtes de détail qui ne peuvent être satisfaites par aucune de ces tables d’agrégation peuvent être dirigées vers Driver Activity.
La table spécifiée dans la colonne Table de détails est Driver Activity, et non pas Driver Activity Agg, car les agrégations chaînées ne sont pas autorisées.
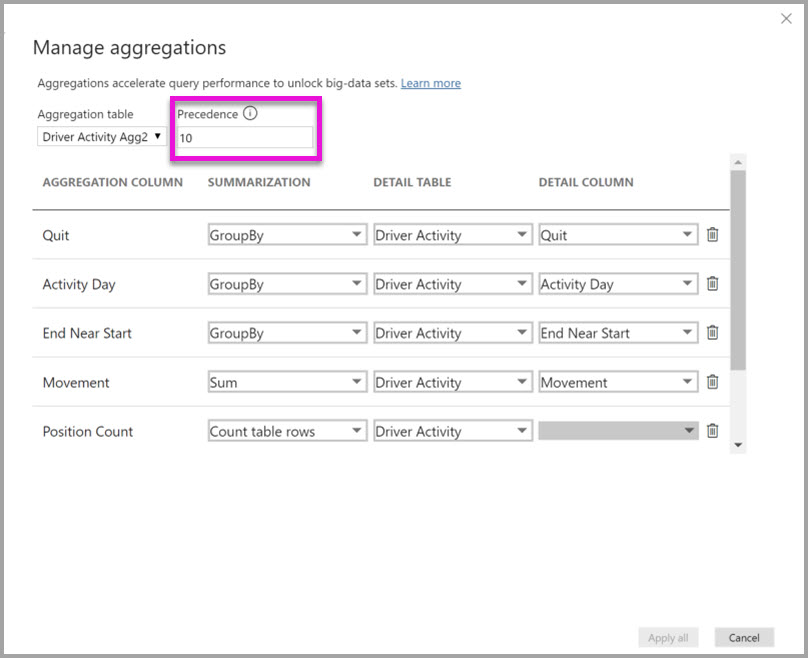
Le tableau suivant présente les agrégations pour la table Driver Activity Agg2.
SQL Profiler peut détecter si les requêtes sont retournées à partir du moteur de stockage du cache en mémoire ou envoyées (push) à la source de données par DirectQuery. Vous pouvez utiliser le même processus pour détecter si les agrégations sont atteintes. Pour plus d’informations, consultez Requêtes accédant au cache ou le manquant.
SQL Profiler fournit également l’événement étendu Query Processing\Aggregate Table Rewrite Query.
L’extrait de code JSON suivant montre un exemple de sortie de l’événement quand une agrégation est utilisée.

Les agrégations qui combinent les modes de stockage DirectQuery, Importer et/ou Double peuvent retourner des données différentes à moins que le cache en mémoire soit maintenu synchronisé avec les données sources. Par exemple, l’exécution des requêtes ne tente pas de masquer les problèmes de données en filtrant les résultats DirectQuery pour qu’ils correspondent aux valeurs mises en cache. Il existe des techniques établies pour gérer ces problèmes à la source, si nécessaire. Les optimisations de performances doivent être utilisées uniquement d’une manière qui ne compromet pas votre capacité à répondre aux besoins de l’entreprise. Il vous incombe de connaître vos flux de données et de réaliser la conception en conséquence.
Les agrégations ne prennent pas en charge les paramètres de requête M dynamiques.
À partir d’août 2022, en raison de changements dans la fonctionnalité, Power BI ignorera les tables d’agrégation en mode d’importation avec des sources de données activées par authentification unique (SSO) en raison de risques potentiels pour la sécurité. Pour garantir une performance optimale des requêtes avec les agrégations, il est recommandé de désactiver l’authentification unique pour ces sources de données.
Power BI a une communauté dynamique où des MVP, des professionnels BI et des pairs partagent leur expertise dans des groupes de discussion, des vidéos, des blogs et bien plus encore. Lorsque vous vous familiarisez avec les agrégations, veillez à consulter ces ressources supplémentaires :
Événement
Championnats du monde Power BI DataViz
14 févr., 16 h - 31 mars, 16 h
Avec 4 chances d’entrer, vous pourriez gagner un package de conférence et le rendre à la Live Grand Finale à Las Vegas
En savoir plusFormation
Parcours d’apprentissage
Use advance techniques in canvas apps to perform custom updates and optimization - Training
Use advance techniques in canvas apps to perform custom updates and optimization
Certification
Microsoft Certified: Power BI Data Analyst Associate - Certifications
Démontrez des méthodes et les meilleures pratiques qui s’alignent sur les exigences métier et techniques pour la modélisation, la visualisation et l’analyse des données avec Microsoft Power BI.
Documentation
Vue d’ensemble des agrégations automatiques - Power BI
Découvrez comment utiliser des agrégations automatiques pour optimiser les performances des requêtes pour les modèles sémantiques DirectQuery.
Utiliser le comportement du filtre de valeur dans Power BI - Power BI
Découvrez comment utiliser le comportement du filtre de valeurs dans Power BI.
Créer des groupes de calcul dans Power BI - Power BI
Découvrez comment créer des groupes de calcul dans Power BI.