Agrégations automatiques
Les agrégations automatiques utilisent le Machine Learning (ML) de pointe pour optimiser en permanence les modèles sémantiques DirectQuery pour optimiser les performances maximales des requêtes de rapport. Les agrégations automatiques s’appuient sur une infrastructure d’agrégations définies par l’utilisateur existantes, introduite pour la première fois avec les modèles composites pour Power BI. Contrairement aux agrégations définies par l’utilisateur, les agrégations automatiques ne nécessitent pas de compétences étendues en modélisation des données et en optimisation des requêtes pour leur configuration et leur maintenance. Les agrégations automatiques sont à la fois auto-apprises et auto-optimisées. Ils permettent aux propriétaires de modèles de n’importe quel niveau de compétence d’améliorer les performances des requêtes, en fournissant des visualisations de rapport plus rapides pour les modèles volumineux.
Avec les agrégations automatiques :
- Les visualisations des rapports sont plus rapides : un pourcentage optimal de requêtes de rapport sont retournées par un cache d’agrégations en mémoire géré automatiquement, au lieu de l’être par des systèmes de source de données back-end. Les requêtes particulières qui ne sont pas retournées par le cache en mémoire sont passées directement à la source de données en utilisant DirectQuery.
- Architecture équilibrée : par rapport au mode DirectQuery pur, la plupart des résultats des requêtes sont retournés par le moteur de requête Power BI et le cache des agrégations en mémoire. La charge du traitement des requêtes sur les systèmes des sources de données lors de la génération intensive de rapports peut être considérablement réduite, ce qui signifie une plus grande scalabilité dans le back-end de la source de données.
- Configuration simple : les propriétaires de modèles peuvent activer l’apprentissage automatique des agrégations et planifier une ou plusieurs actualisations pour le modèle. Avec le premier apprentissage et la première actualisation, les agrégations automatiques démarrent par la création d’une infrastructure d’agrégations et des agrégations optimales. Le système s’optimise automatiquement lui-même au fil du temps.
- Optimisation : Grâce à une interface utilisateur simple et intuitive dans les paramètres du modèle, vous pouvez estimer les gains de performances d’un pourcentage différent des requêtes retournées par le cache des agrégations en mémoire et apporter des ajustements pour des gains encore plus importants. Un seul contrôle de curseur vous aide à optimiser facilement votre environnement.
Spécifications
Plans pris en charge
Les agrégations automatiques sont prises en charge pour Power BI Premium par capacité, Premium par utilisateur et modèles de Power BI Embedded.
Sources de données prises en charge
Les agrégations automatiques sont prises en charge pour les sources de données suivantes :
- Azure SQL Database
- Pool SQL dédié Azure Synapse
- SQL Server 2019 ou version ultérieure
- Google BigQuery
- Snowflake
- Databricks
- Amazon Redshift
Modes pris en charge
Les agrégations automatiques sont prises en charge pour les modèles en mode DirectQuery. Les modèles de modèle composite avec les tables d’importation et les connexions DirectQuery sont pris en charge. Les agrégations automatiques sont prises en charge pour la connexion DirectQuery uniquement.
Autorisations
Pour activer et configurer des agrégations automatiques, vous devez être le propriétaire de modèle. Les administrateurs d’espace de travail peuvent prendre le relais en tant que propriétaire pour configurer les paramètres d’agrégation automatique.
Configuration des agrégations automatiques
Les agrégations automatiques sont configurées dans les paramètres du modèle. La configuration est simple : activez la formation automatique des agrégations et programmez une ou plusieurs actualisations. Avant de configurer des agrégations automatiques pour votre modèle, veillez à lire entièrement cet article. Il vous permet d’acquérir une bonne compréhension du fonctionnement des agrégations automatiques et peut vous aider à déterminer si les agrégations automatiques sont appropriées pour votre environnement. Quand vous êtes prêt à suivre les instructions pas à pas pour activer la formation des agrégations automatiques, configurer une planification des actualisations et optimiser pour votre environnement, consultez Configurer les agrégations automatiques.
Avantages
Avec DirectQuery, chaque fois qu’un utilisateur de modèle ouvre un rapport ou interagit avec une visualisation de rapport, les requêtes DAX (Data Analysis Expressions) sont passées au moteur de requête, puis à la source de données principale en tant que requêtes SQL. La source de données doit calculer et retourner les résultats pour chaque requête. Par rapport aux modèles en mode importation stockés en mémoire, les allers-retours de source de données DirectQuery peuvent être à la fois longs et gourmands en processus, ce qui provoque souvent des temps de réponse de requête lents dans les visualisations de rapport.
Lorsqu’elles sont activées pour un modèle DirectQuery, les agrégations automatiques peuvent améliorer les performances des requêtes de rapport en évitant les allers-retours de requête de source de données. Les résultats de requête pré-agrégés sont retournés automatiquement par un cache d’agrégations en mémoire, au lieu d’être envoyés à la source de données, puis retournés par celle-ci. La quantité de données pré-agrégées dans le cache des agrégations en mémoire est une petite fraction de la quantité de données conservées dans les tables de faits et de détails au niveau de la source de données. Le résultat fournit non seulement de meilleures performances des requêtes de rapport, mais également une charge réduite sur les systèmes de sources de données back-end. Avec les agrégations automatiques, seule une petite partie des requêtes de rapport et des requêtes ad hoc qui nécessitent des agrégations non incluses dans le cache en mémoire sont passées à la source de données back-end, comme avec le mode DirectQuery pur.
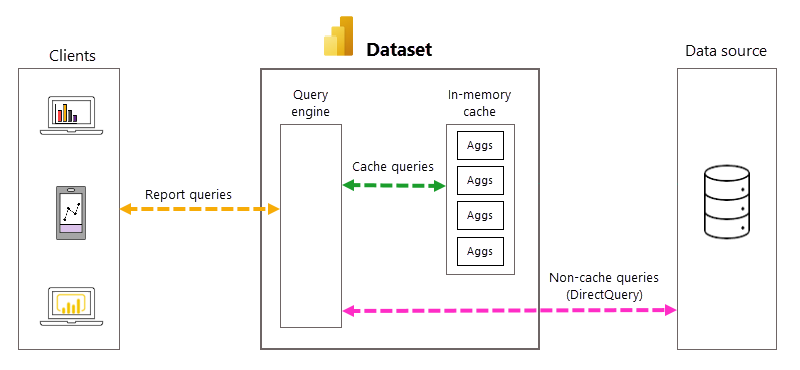
Gestion automatique des requêtes et des agrégations
Les agrégations automatiques éliminent la nécessité de créer des tables d’agrégations définies par l’utilisateur et simplifient considérablement l’implémentation d’une solution de données pré-agrégées. Cependant, une connaissance approfondie des processus et des dépendances sous-jacents est utile pour comprendre le fonctionnement des agrégations automatiques. Power BI s’appuie sur les éléments suivants pour créer et gérer des agrégations automatiques.
Journal des requêtes
Power BI effectue le suivi des requêtes de modèle et de rapport utilisateur dans un journal des requêtes. Pour chaque modèle, Power BI gère sept jours de données de journal de requête. Les données du journal des requêtes sont retraitées chaque jour. Le journal des requêtes est sécurisé et n’est pas visible pour les utilisateurs ou via le point de terminaison XMLA.
Opérations d’apprentissage
Dans le cadre de la première opération d’actualisation planifiée du modèle pour votre fréquence sélectionnée (jour ou semaine), Power BI lance d’abord une opération d’entraînement qui évalue le journal des requêtes pour garantir que les agrégations dans le cache des agrégations en mémoire s’adaptent à la modification des modèles de requête. Des tables d’agrégations en mémoire sont créées, mises à jour ou supprimées, et des requêtes spéciales sont envoyées à la source de données pour déterminer si les agrégations doivent être incluses dans le cache. Les données des agrégations calculées ne sont cependant pas chargées dans le cache en mémoire lors de l’apprentissage : elles sont chargées lors de l’opération d’actualisation suivante.
Par exemple, si vous choisissez une fréquence journalière et que vous planifiez des actualisations à 4h00, 9h00, 14h00 et 19h00, seule l’actualisation quotidienne effectuée à 4h00 inclura à la fois une opération d’apprentissage et une opération d’actualisation. Les actualisations planifiées suivantes à 9h00, 14h00 et 19h00 pour cette journée sont des opérations d’actualisation uniquement qui mettent à jour les agrégations existantes dans le cache.
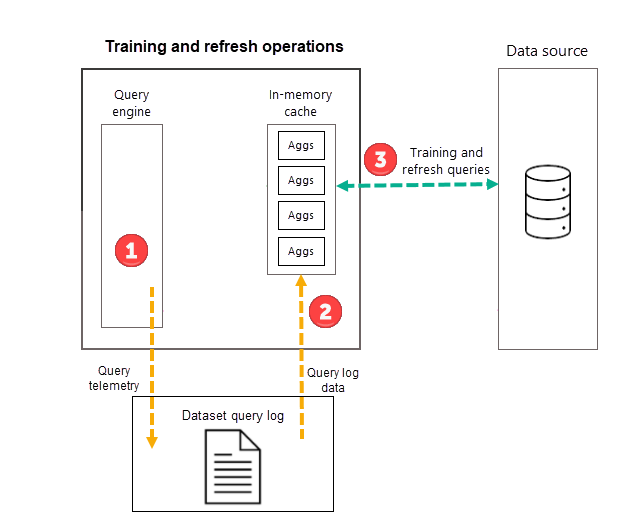
Si les opérations d’apprentissage évaluent les requêtes antérieures présentes dans journal des requêtes, les résultats sont suffisamment précis pour garantir la couverture des requêtes ultérieures. Il n’y a cependant aucune garantie quant au fait que les requêtes ultérieures seront retournées par le cache des agrégations en mémoire, car ces nouvelles requêtes peuvent être différentes de celles qui sont dérivées du journal des requêtes. Ces requêtes qui ne sont pas retournées par le cache des agrégations en mémoire sont passées à la source de données en utilisant DirectQuery. Selon la fréquence et le classement de ces nouvelles requêtes, des agrégations peuvent être incluses dans le cache des agrégations en mémoire lors l’opération d’apprentissage suivante.
L’opération d’apprentissage a une limite de 60 minutes. Si l’entraînement ne parvient pas à traiter l’intégralité du journal des requêtes dans le délai imparti, une notification est consignée dans l’historique d’actualisation du modèle et la formation reprend la prochaine fois qu’elle est lancée. Le cycle de formation se termine et remplace les agrégations automatiques existantes lorsque l’ensemble du journal des requêtes est traité.
Opérations d'actualisation
Comme décrit précédemment, une fois l’opération d’apprentissage terminée dans le cadre de la première actualisation planifiée pour la fréquence sélectionnée, Power BI effectue une opération d’actualisation qui interroge et charge les données des agrégations nouvelles et mises à jour dans le cache des agrégations en mémoire, et supprime toutes les agrégations qui ne sont plus suffisamment bien classées (tel que déterminé par l’algorithme d’apprentissage). Toutes les actualisations suivantes pour la fréquence journalière ou hebdomadaire choisie sont des opérations d’actualisation uniquement, qui interrogent la source de données pour mettre à jour les données d’agrégations existantes dans le cache. Prenons notre précédent exemple, les actualisations planifiées de 9h00, 14h00 et 19h00 pour cette journée sont des opérations d’actualisation uniquement.
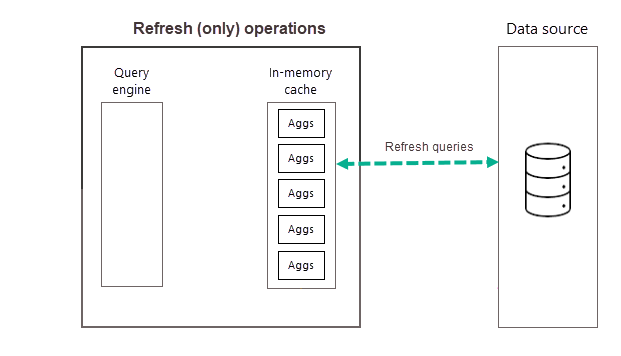
Des actualisations planifiées régulièrement au cours de la journée (ou de la semaine) garantissent que les données des agrégations dans le cache sont davantage à jour avec les données de la source de données back-end. Via les paramètres du modèle, vous pouvez planifier jusqu’à 48 actualisations par jour pour vous assurer que les requêtes de rapport retournées par le cache d’agrégations obtiennent des résultats en fonction des données actualisées les plus récentes de la source de données back-end.
Attention
Les opérations d’apprentissage et d’actualisation sont gourmandes en traitement et en ressources à la fois pour le service Power BI et les systèmes des sources de données. Le fait d’augmenter le pourcentage de requêtes qui utilisent des agrégations signifie que plus d’agrégations doivent être interrogées et calculées à partir des sources de données lors des opérations d’apprentissage et d’actualisation, ce qui augmente la probabilité d’une utilisation excessive des ressources système et peut provoquer des dépassements de délais d’attente. Pour plus d’informations, consultez Optimisation.
Formation à la demande
Comme mentionné précédemment, un cycle de formation peut ne pas se terminer dans les limites de temps d’un seul cycle d’actualisation des données. Si vous ne souhaitez pas attendre le prochain cycle d’actualisation planifié qui inclut l’entraînement, vous pouvez également déclencher une formation automatique d’agrégations à la demande en sélectionnant Effectuer l'apprentissage et actualiser maintenant dans les paramètres du modèle. L’utilisation de l’option Effectuer l’apprentissage et actualiser maintenant déclenche à la fois une opération d’apprentissage et une opération d’actualisation. Vérifiez l’historique d’actualisation du modèle pour voir si l’opération actuelle est terminée avant d’exécuter une autre opération d’entraînement et d’actualisation à la demande, si nécessaire.
Historique des actualisations
Chaque opération d’actualisation est enregistrée dans l’historique d’actualisation du modèle. Des informations importantes sur chaque actualisation sont montrées, notamment le nombre d’agrégations de mémoire dans le cache utilisées pour le pourcentage de requêtes configuré. Pour afficher l’historique des actualisations, dans la page Paramètres du modèle, sélectionnez historique d’actualisation. Si vous voulez plus d’informations, cliquez sur Afficher les détails.
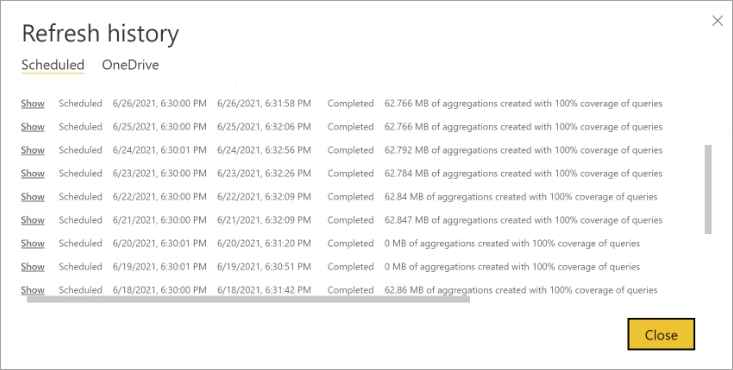
En contrôlant régulièrement l’historique d’actualisation, vous pouvez vérifier que vos opérations d’actualisation planifiées se terminent dans un délai acceptable. Vérifiez que les opérations d’actualisation sont terminées avant le début de l’actualisation planifiée suivante.
Échecs d’apprentissage et d’actualisation
Bien que Power BI effectue des opérations d’entraînement et d’actualisation dans le cadre de la première actualisation planifiée pour la fréquence de jour ou de semaine que vous choisissez, ces opérations sont implémentées en tant que transactions distinctes. Si une opération d’apprentissage ne peut pas traiter entièrement le journal des requêtes dans les délais impartis, Power BI procède à l’actualisation des agrégations existantes (et des tables régulières dans un modèle composite) en utilisant l’état d’apprentissage précédent. Dans ce cas, l’historique des actualisations indiquera que l’actualisation a réussi et que la formation reprendra le traitement du journal des requêtes lors du prochain lancement de la formation. Les performances des requêtes peuvent être moins optimisées si les modèles de requête de rapport client ont changé et que les agrégations n’ont pas encore été ajustées, mais que le niveau de performances atteint doit toujours être beaucoup mieux qu’un modèle DirectQuery pur sans agrégations.
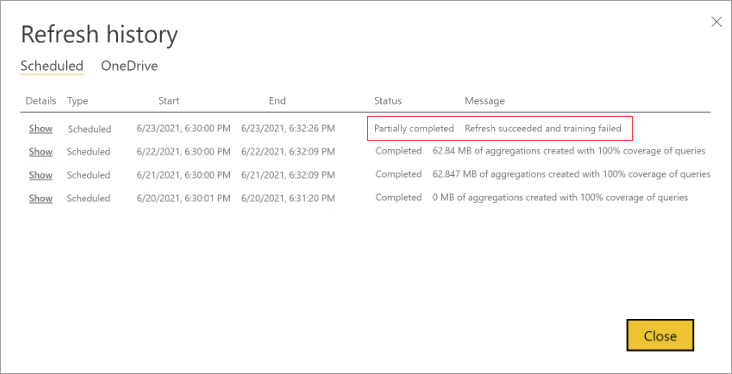
Si une opération d’entraînement nécessite trop de cycles pour terminer le traitement du journal des requêtes, envisagez de réduire le pourcentage de requêtes qui utilisent le cache d’agrégations en mémoire dans les paramètres du modèle. Ceci va réduire le nombre d’agrégations créées dans le cache, mais accorder plus de temps pour l’exécution des opérations d’apprentissage et d’actualisation. Pour plus d’informations, consultez Optimisation.
Si l’entraînement réussit, mais que l’actualisation échoue, l’actualisation entière est marquée comme ayant échoué, car le résultat est un cache d’agrégations en mémoire indisponible.
Lors de la planification de l’actualisation, vous pouvez spécifier des notifications par e-mail en cas d’échecs d’actualisation.
Agrégations définies par l’utilisateur et agrégations automatiques
Les agrégations définies par l’utilisateur dans Power BI peuvent être configurées manuellement en fonction des tables agrégées masquées dans le modèle. La configuration d’agrégations définies par l’utilisateur est souvent complexe, nécessitant un plus grand niveau de compétences en matière de modélisation des données et d’optimisation des requêtes. En revanche, les agrégations automatiques éliminent cette complexité dans le cadre d’un système basé sur l’intelligence artificielle. Contrairement aux agrégations définies par l’utilisateur qui restent statiques, Power BI gère en continu les journaux des requêtes et, à partir de ces journaux, il détermine les modèles de requête en se basant sur des algorithmes de modélisation prédictive de machine learning. Les données pré-agrégées sont calculées et stockées en mémoire en fonction de l’analyse des modèles de requête. Avec les agrégations automatiques, les modèles sont à la fois auto-entraînement et auto-optimisation. À mesure que les modèles des requêtes de rapport des clients changent, les agrégations automatiques ajustent, hiérarchisent et mettent en cache les agrégations utilisées le plus fréquemment.
Étant donné que les agrégations automatiques sont basées sur l’infrastructure d’agrégations définies par l’utilisateur existante, il est possible d’utiliser les agrégations définies par l’utilisateur et automatiques ensemble dans le même modèle. Les modélisateurs de données plus avancés peuvent définir des agrégations pour les tables en utilisant les modes DirectQuery, Importation (avec ou sans actualisation incrémentielle) ou Stockage double, tout en bénéficiant des avantages des agrégations plus automatisées pour les requêtes sur les connexions DirectQuery qui ne trouvent pas leur réponse dans les tables d’agrégation définies par l’utilisateur. Cette flexibilité permet d’obtenir des architectures équilibrées capables de réduire la charge des requêtes et d’éviter les goulots d’étranglement.
Les agrégations créées dans le cache en mémoire par l’algorithme d’apprentissage des agrégations automatiques sont identifiées comme agrégations System. L’algorithme d’apprentissage crée et supprime uniquement ces agrégations System, car les requêtes de création de rapports sont analysées et les ajustements sont effectués pour maintenir les agrégations optimales pour le modèle. Les agrégations définies par l’utilisateur et automatiques sont actualisées avec actualisation. Seules les agrégations créées par les agrégations automatiques et marquées comme agrégations générées par le système sont incluses dans le traitement automatique des agrégations.
Mise en cache des requêtes et agrégations automatiques
Power BI Premium prend également en charge la Mise en cache des requêtes dans Power BI Premium/Embedded pour gérer les résultats des requêtes. La mise en cache des requêtes est une fonctionnalité différente des agrégations automatiques. Avec la mise en cache des requêtes, Power BI Premium utilise son service de mise en cache local pour implémenter la mise en cache, tandis que les agrégations automatiques sont implémentées au niveau du modèle. Avec la mise en cache des requêtes, le service met en cache seulement les requêtes pour le chargement initial de la page de rapport : les performances des requêtes ne sont donc pas améliorées quand les utilisateurs interagissent avec un rapport. En revanche, les agrégations automatiques optimisent la plupart des requêtes de rapport en mettant préalablement en cache les résultats agrégés des requêtes, notamment les requêtes générées quand des utilisateurs interagissent avec des rapports. La mise en cache des requêtes et les agrégations automatiques peuvent être activées pour un modèle, mais il n’est probablement pas nécessaire.
Surveiller avec Azure Log Analytics
Azure Log Analytics est un service au sein d’Azure Monitor que Power BI peut utiliser pour enregistrer les journaux d’activité. Avec la suite Azure Monitor, vous pouvez collecter, analyser et agir sur les données de télémétrie de vos environnements Azure et locaux. Elle offre un stockage à long terme, une interface d’interrogation ad hoc et un accès via une API pour permettre l’exportation des données et leur intégration dans d’autres systèmes. Pour plus d’informations, consultez Utilisation d’Azure Log Analytics dans Power BI.
Si Power BI est configuré avec un compte Azure Log Analytics, comme décrit dans Configuration d’Azure Log Analytics pour Power BI, vous pouvez analyser le taux de réussite de vos agrégations automatiques. Entre autres choses, vous pouvez déterminer si les requêtes de rapport trouvent leur réponse dans le cache en mémoire.
Pour utiliser cette fonctionnalité, téléchargez le modèle PBIT et connectez-le à votre compte Log Analytics, comme décrit dans ce billet de blog Power BI. Dans le rapport, vous pouvez visualiser les données à trois niveaux différents : la vue de récapitulatif, la vue au niveau de la requête DAX et la vue au niveau de la requête SQL.
L’illustration suivante montre la page de récapitulatif pour toutes les requêtes. Comme vous pouvez le voir, le graphique avec les marques montre le pourcentage des requêtes qui ont été satisfaites par des agrégations par rapport à celles qui ont dû utiliser la source de données.
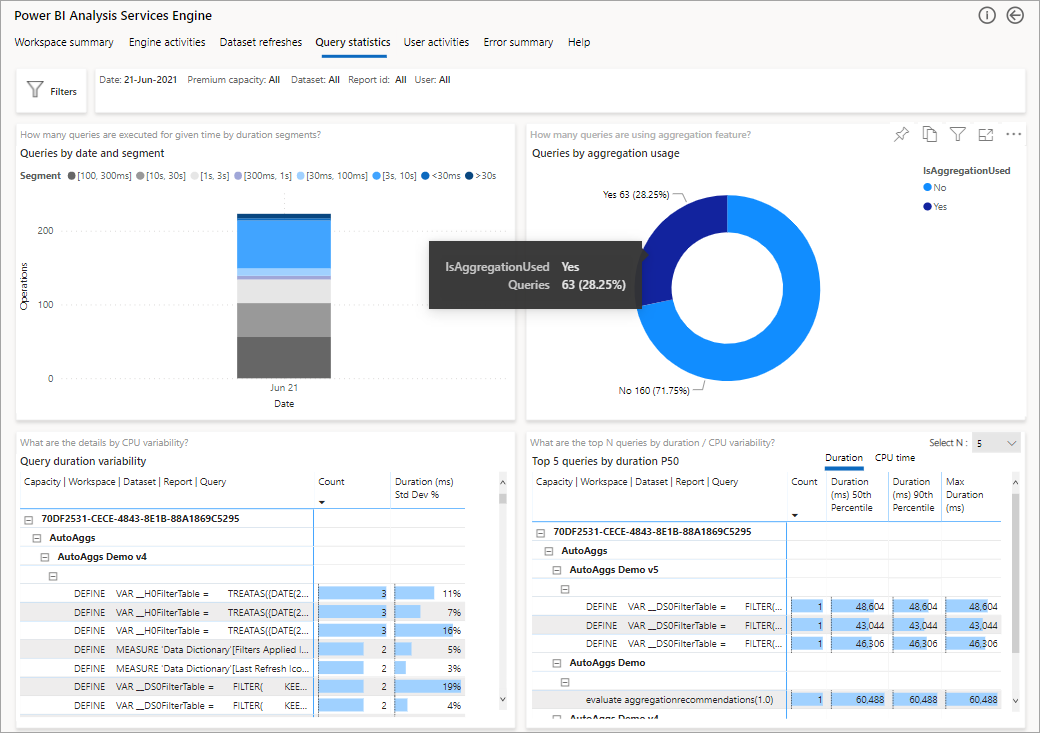
L’étape suivante pour approfondir l’exploration est d’examiner l’utilisation des agrégations au niveau de la requête DAX. Cliquez avec le bouton droit sur une requête DAX dans la liste (en bas à gauche) >Explorer>Historique des requêtes.
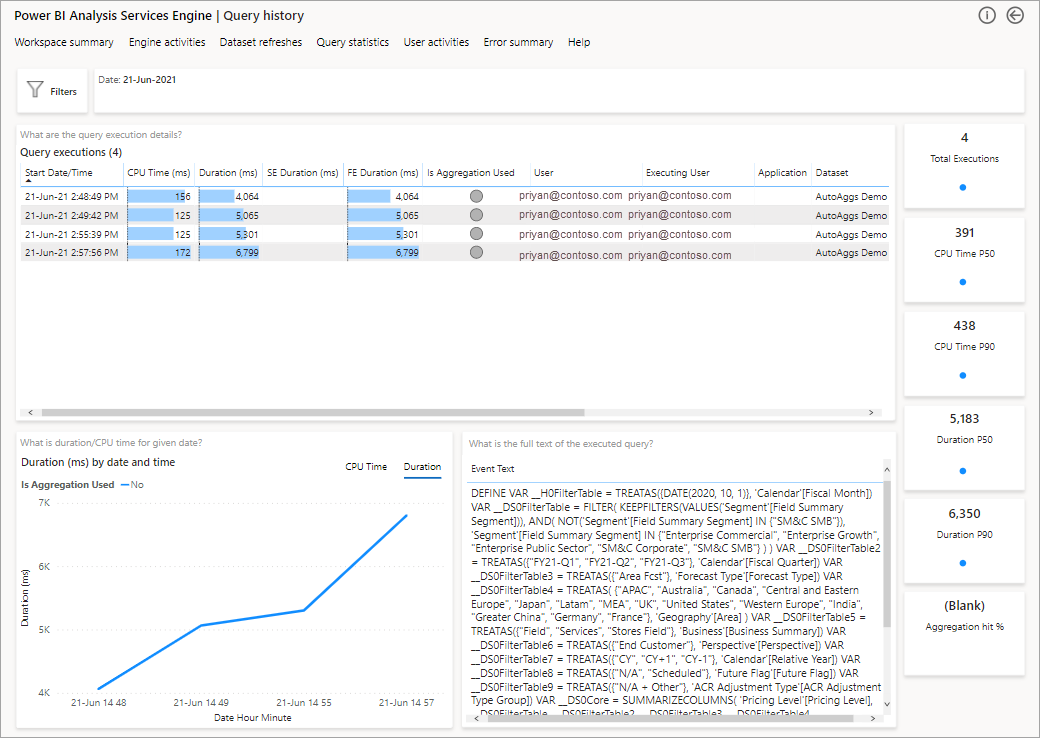
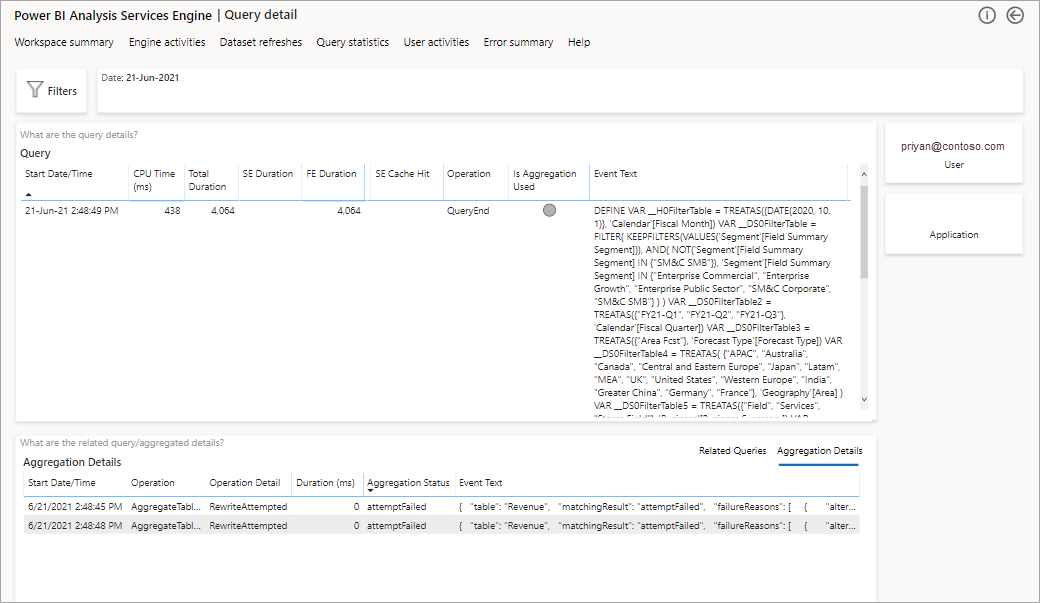
Vous obtenez une liste de toutes les requêtes pertinentes. Accédez au niveau suivant pour afficher plus de détails sur les agrégations.
Gestion du cycle de vie des applications
Du développement au test et à la production, les modèles avec agrégations automatiques activées ont des exigences particulières pour les solutions ALM.
Pipelines de déploiement
Avec les pipelines de déploiement, Power BI peut copier les modèles avec leur configuration de modèle de l’étape actuelle dans l’étape cible. Cependant, les agrégations automatiques doivent être réinitialisées dans la phase cible, car les paramètres ne sont pas transférés de la phase actuelle à la phase cible. Vous pouvez aussi déployer du contenu programmatiquement, en utilisant les API REST des pipelines de déploiement. Pour plus d’informations sur ce processus, consultez Automatiser votre pipeline de déploiement en utilisant des API et DevOps.
Solutions ALM personnalisées
Si vous utilisez une solution ALM personnalisée basée sur des points de terminaison XMLA, gardez à l’esprit que votre solution peut être en mesure de copier des tables d’agrégations générées par le système et créées par l’utilisateur dans le cadre des métadonnées du modèle. Vous devez cependant activer manuellement les agrégations automatiques après chaque étape de déploiement au niveau de la phase cible. Power BI conserve la configuration si vous remplacez un modèle existant.
Remarque
Si vous chargez ou republiez un modèle dans le cadre d’un fichier Power BI Desktop (.pbix), les tables d’agrégation créées par le système sont perdues, car Power BI remplace le modèle existant par toutes ses métadonnées et données dans l’espace de travail cible.
Modification d’un modèle
Après avoir modifié un modèle avec des agrégations automatiques activées via des points de terminaison XMLA, tels que l’ajout ou la suppression de tables, Power BI conserve toutes les agrégations existantes qui peuvent être et supprimer celles qui ne sont plus nécessaires ou pertinentes. Les performances des requêtes peuvent être impactées jusqu’à ce que la phase d’apprentissage suivante soit déclenchée.
Éléments de métadonnées
Les modèles avec agrégations automatiques activées contiennent des tables d’agrégations générées par le système uniques. Les tables d’agrégations ne sont pas visibles par les utilisateurs dans les outils de création de rapports. Elles sont visibles via le point de terminaison XMLA en utilisant des outils avec des Bibliothèques de client Analysis Services version 19.22.5 et ultérieure. Lorsque vous utilisez des modèles avec des agrégations automatiques activées, veillez à mettre à niveau vos outils de modélisation et d’administration des données vers la dernière version des bibliothèques clientes. Pour SQL Server Management Studio (SSMS), effectuez une mise à niveau vers SSMS version 18.9.2 ou ultérieure. Les versions antérieures de SSMS ne sont pas en mesure d’énumérer des tables ou de générer des scripts sur ces modèles.
Les tables d’agrégations automatiques sont identifiées par une propriété de table SystemManaged, qui est une nouveauté du modèle d’objet tabulaire (TOM, Tabular Object Model) dans les bibliothèques de client Analysis Services version 19.22.5 et ultérieure. L’extrait de code suivant montre que la propriété SystemManaged est définie sur true pour les tables d’agrégations automatiques et sur false pour les tables normales.
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AnalysisServices.Tabular;
namespace AutoAggs
{
class Program
{
static void Main(string[] args)
{
string workspaceUri = "<Specify the URL of the workspace where your model resides>";
string datasetName = "<Specify the name of your dataset>";
Server sourceWorkspace = new Server();
sourceWorkspace.Connect(workspaceUri);
Database dataset = sourceWorkspace.Databases.GetByName(datasetName);
// Enumerate system-managed tables.
IEnumerable<Table> aggregationsTables = dataset.Model.Tables.Where(tbl => tbl.SystemManaged == true);
if (aggregationsTables.Any())
{
Console.WriteLine("The following auto aggs tables exist in this dataset:");
foreach (Table table in aggregationsTables)
{
Console.WriteLine($"\t{table.Name}");
}
}
else
{
Console.WriteLine($"This dataset has no auto aggs tables.");
}
Console.WriteLine("\n\rPress [Enter] to exit the sample app...");
Console.ReadLine();
}
}
}
L’exécution de cet extrait de code génère des tables d’agrégations automatiques actuellement incluses dans le modèle dans une console.
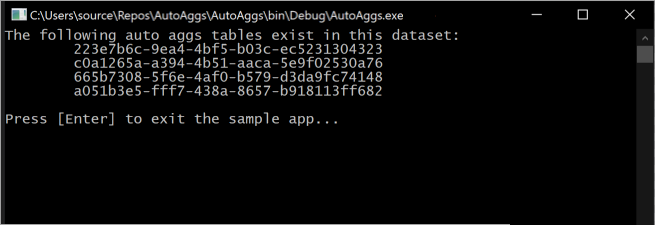
Gardez à l’esprit que les tables d’agrégations changent constamment, car les opérations d’apprentissage déterminent les agrégations optimales à inclure dans le cache des agrégations en mémoire.
Important
Power BI gère intégralement les objets de table générés automatiquement par le système des agrégations automatiques. Ne supprimez pas ou ne modifiez pas ces tables vous-même. Cela peut entraîner une dégradation des performances.
Power BI gère la configuration du modèle en dehors du modèle. La présence d’une table d’agrégations gérées par le système dans un modèle ne signifie pas nécessairement que le modèle est activé pour l’apprentissage automatique des agrégations. En d’autres termes, si vous scriptez une définition de modèle complète pour un modèle avec des agrégations automatiques activées et créez une nouvelle copie du modèle (avec un autre nom/espace de travail/capacité), le nouveau modèle résultant n’est pas activé pour l’apprentissage automatique des agrégations. Vous devez toujours activer l’apprentissage automatique des agrégations pour le nouveau modèle dans les paramètres du modèle.
Considérations et limitations
Quand vous utilisez les agrégations automatiques, gardez les points suivants à l’esprit :
- Les agrégations ne prennent pas en charge les paramètres de requête M dynamiques.
- Les requêtes SQL générées au cours de la phase initiale d’entraînement peuvent générer une charge significative sur l’entrepôt de données. Si l’entraînement continue d’échouer avant la fin et que les requêtes expirent du côté de l’entrepôt de données, effectuez un scale-up temporaire de votre entrepôt de données pour répondre à la demande d’entraînement.
- Les agrégations stockées dans le cache des agrégations en mémoire peuvent ne pas être calculées sur les données les plus récentes de la source de données. Contrairement à l’élément DirectQuery pur et à l’instar des tables d’importation régulières, il y a une latence entre les mises à jour de la source de données et les données des agrégations stockées dans le cache des agrégations en mémoire. Bien qu’il y ait toujours un certain degré de latence, il peut être atténué via une planification efficace des actualisations.
- Pour optimiser plus avant les performances, définissez toutes les tables de dimension en Mode double et laissez les tables de faits en mode DirectQuery.
- Les agrégations automatiques ne sont pas disponibles avec Power BI Pro, Azure Analysis Services ou SQL Server Analysis Services.
- Power BI ne prend pas en charge le téléchargement de modèles avec des agrégations automatiques activées. Si vous avez chargé ou publié un fichier Power BI Desktop (.pbix) sur Power BI, puis que vous avez activé les agrégations automatiques, vous ne pouvez plus télécharger le fichier PBIX. Veillez à conserver une copie du fichier PBIX localement.
- Les agrégations automatiques avec des tables externes dans Azure Synapse Analytics ne sont pas prises en charge. Vous pouvez énumérer les tables externes dans Synapse en utilisant la requête SQL suivante :
SELECT SCHEMA_NAME(schema_id) AS schema_name, name AS table_name FROM sys.external_tables. - Les agrégations automatiques sont disponibles uniquement pour les modèles utilisant des métadonnées améliorées. Si vous souhaitez activer les agrégations automatiques pour un modèle plus ancien, mettez à niveau d’abord le modèle pour améliorer les métadonnées. Pour plus d’informations, consultez Utilisation des métadonnées de modèle améliorées.
- N’activez pas les agrégations automatiques si la source de données DirectQuery est configurée pour l’authentification unique, et qu’elle utilise des vues de données dynamiques ou des contrôles de sécurité pour limiter les données auxquelles un utilisateur est autorisé à accéder. Les agrégations automatiques ne tiennent pas compte de ces contrôles au niveau de la source de données, ce qui rend impossible de garantir que des données correctes sont fournies pour un utilisateur donné. La formation enregistrera un avertissement dans l’historique d’actualisation indiquant qu’elle a détecté une source de données configurée pour l’authentification unique et qu’elle a ignoré les tables qui utilisent cette source de données. Si possible, désactivez l’authentification unique pour ces sources de données afin de profiter pleinement des performances optimisées des requêtes que les agrégations automatiques peuvent fournir.
- N’activez pas les agrégations automatiques si le modèle contient uniquement des tables hybrides pour éviter une surcharge de traitement inutile. Une table hybride utilise à la fois des partitions d’importation et une partition DirectQuery. Un scénario courant est l’actualisation incrémentielle avec des données en temps réel dans lequel une partition DirectQuery récupère les transactions de la source de données qui se sont produites après la dernière actualisation des données. Cependant, Power BI importe les agrégations pendant l’actualisation. Les agrégations automatiques ne peuvent pas inclure les transactions qui ont eu lieu après la dernière actualisation des données. La formation enregistrera un avertissement dans l’historique des actualisations indiquant qu’elle a détecté et ignoré des tables hybrides.
- Les colonnes calculées ne sont pas prises en compte pour les agrégations automatiques. Si vous utilisez une colonne calculée en mode DirectQuery, par exemple en utilisant la fonction DAX
COMBINEVALUESpour créer une relation basée sur plusieurs colonnes de deux tables DirectQuery, les requêtes de rapport correspondantes ne trouvent pas leur réponse dans le cache des agrégations en mémoire. - Les agrégations automatiques sont disponibles seulement dans le service Power BI. Power BI Desktop ne crée pas de tables d’agrégations générées par le système.
- Si vous modifiez les métadonnées d’un modèle avec des agrégations automatiques activées, les performances des requêtes peuvent se dégrader jusqu’à ce que le processus d’entraînement suivant soit déclenché. Vous devez supprimer les agrégations automatiques, apporter les modifications, puis relancer l’apprentissage.
- Ne modifiez pas ou supprimez les tables d’agrégations générées par le système, sauf si vous avez des agrégations automatiques désactivées et que vous nettoyez le modèle. Le système a la responsabilité de la gestion de ces objets.
Communauté
Power BI a une communauté dynamique où des MVP, des professionnels BI et des pairs partagent leur expertise dans des groupes de discussion, des vidéos, des blogs et bien plus encore. Pour en savoir plus sur les agrégations automatiques, veillez à consulter ces autres ressources :
- Communauté Power BI
- Recherchez « Power BI automatic aggregations » (Agrégations automatiques Power BI) sur Bing
Contenu connexe
Commentaires
Prochainement : Tout au long de l'année 2024, nous supprimerons progressivement les GitHub Issues en tant que mécanisme de retour d'information pour le contenu et nous les remplacerons par un nouveau système de retour d'information. Pour plus d’informations, voir: https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour