Tutoriel : Déployer des clusters Big Data SQL Server en mode AD sur Azure Kubernetes Service (AKS)
Cet article explique comment déployer un cluster Big Data SQL Server en mode d’authentification Active Directory avec une architecture de référence. L’architecture de référence étend Active Directory Domain Services (AD DS) à Azure. Vous pouvez le déployer à partir du Centre des architectures Azure, à l’aide de composants Azure.
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Prérequis
Avant de déployer un cluster Big Data SQL Server, vous devez :
- Accéder à une machine virtuelle Azure à des fins de gestion. Cette machine virtuelle doit pouvoir accéder au réseau virtuel Azure sur lequel vous allez déployer le cluster Big Data. Elle doit se trouver soit sur le même réseau virtuel, soit sur un réseau virtuel appairé.
- Installer les outils Big Data sur la machine virtuelle de gestion.
- Préparer le déploiement du cluster en mode d’authentification Active Directory dans votre contrôleur AD local.
Créer un sous-réseau AKS
Définir des variables d’environnement
export REGION_NAME=< your Azure Region > export RESOURCE_GROUP=<your resource group > export SUBNET_NAME=aks-subnet export VNet_NAME= adds-vnet export AKS_NAME= <your aks cluster name>Créez le sous-réseau AKS.
SUBNET_ID=$(az network vnet subnet show \ --resource-group $RESOURCE_GROUP \ --vnet-name $VNet_NAME \ --name $SUBNET_NAME \ --query id -o tsv)
La capture d’écran suivante montre l’architecture des sous-réseaux dans le réseau virtuel.
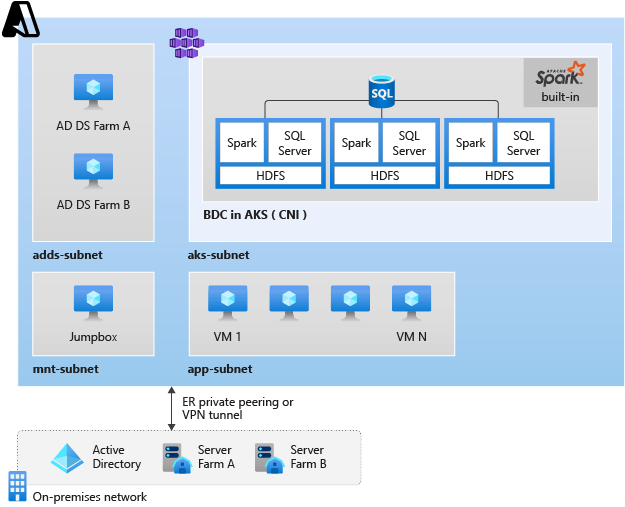
Créer un cluster privé AKS
Vous pouvez utiliser la commande suivante pour déployer le cluster privé AKS. Si vous n’avez pas besoin d’un cluster privé, supprimez le paramètre --enable-private-cluster dans la commande. Pour plus d’informations sur les autres exigences, consultez Comment déployer un cluster Azure Kubernetes (AKS).
az aks create \
--resource-group $RESOURCE_GROUP \
--name $AKS_NAME \
--load-balancer-sku standard \
--enable-private-cluster \
--network-plugin azure \
--vnet-subnet-id $SUBNET_ID \
--docker-bridge-address 172.17.0.1/16 \
--dns-service-ip 10.3.0.10 \
--service-cidr 10.3.0.0/24 \
--node-vm-size Standard_D13_v2 \
--node-count 2 \
--generate-ssh-keys
Après l’avoir déployé, connectez-vous au cluster AKS.
Vérifier l’entrée DNS inversée pour le contrôleur de domaine
Avant de démarrer le déploiement des clusters Big Data SQL Server en mode AD dans le cluster AKS, vérifiez que le contrôleur de domaine comprend un enregistrement A et un enregistrement PTR (entrée de DNS inversé) qui sont inscrits auprès du serveur DNS.
Pour vérifier ce paramètre, exécutez la commande nslookup ou exécutez le script PowerShell suivant pour vérifier que l’entrée de DNS inversé (enregistrement PTR) est configurée.
Créer un profil de déploiement de cluster Big Data
La commande suivante crée un profil de déploiement :
azdata bdc config init --source kubeadm-prod --target bdc-ad-aks
Les commandes suivantes sont utilisées pour définir les paramètres d’un profil de déploiement.
control.json
azdata bdc config replace -p bdc-ad-aks/control.json -j "$.spec.storage.data.className=default"
azdata bdc config replace -p bdc-ad-aks/control.json -j "$.spec.storage.logs.className=default"
azdata bdc config replace -p bdc-ad-aks/control.json -j "$.spec.endpoints[0].serviceType=NodePort"
azdata bdc config replace -p bdc-ad-aks/control.json -j "$.spec.endpoints[1].serviceType=NodePort"
azdata bdc config replace -p bdc-ad-aks/control.json -j "$.spec.endpoints[0].dnsName=controller.contoso.com"
azdata bdc config replace -p bdc-ad-aks/control.json -j "$.spec.endpoints[1].dnsName=proxys.contoso.com"
# security settings
azdata bdc config replace -p bdc-ad-aks/control.json -j "$.security.activeDirectory.ouDistinguishedName=OU\=bdc\,DC\=contoso\,DC\=com"
azdata bdc config replace -p bdc-ad-aks/control.json -j "$.security.activeDirectory.dnsIpAddresses=[\"192.168.0.4\"]"
azdata bdc config replace -p bdc-ad-aks/control.json -j "$.security.activeDirectory.domainControllerFullyQualifiedDns=[\"ad1.contoso.com\"]"
azdata bdc config replace -p bdc-ad-aks/control.json -j "$.security.activeDirectory.domainDnsName=contoso.com"
azdata bdc config replace -p bdc-ad-aks/control.json -j "$.security.activeDirectory.clusterAdmins=[\"bdcadminsgroup\"]"
azdata bdc config replace -p bdc-ad-aks/control.json -j "$.security.activeDirectory.clusterUsers=[\"bdcusersgroup\"]"
bdc.json
azdata bdc config replace -p bdc-ad-aks/bdc.json -j "$.spec.resources.master.spec.endpoints[0].dnsName=master.contoso.com"
azdata bdc config replace -p bdc-ad-aks/bdc.json -j "$.spec.resources.master.spec.endpoints[0].serviceType=NodePort"
azdata bdc config replace -p bdc-ad-aks/bdc.json -j "$.spec.resources.master.spec.endpoints[1].dnsName=mastersec.contoso.com"
azdata bdc config replace -p bdc-ad-aks/bdc.json -j "$.spec.resources.master.spec.endpoints[1].serviceType=NodePort"
azdata bdc config replace -p bdc-ad-aks/bdc.json -j "$.spec.resources.gateway.spec.endpoints[0].dnsName=gateway.contoso.com"
azdata bdc config replace -p bdc-ad-aks/bdc.json -j "$.spec.resources.gateway.spec.endpoints[0].serviceType=NodePort"
azdata bdc config replace -p bdc-ad-aks/bdc.json -j "$.spec.resources.appproxy.spec.endpoints[0].dnsName=approxy.contoso.com"
azdata bdc config replace -p bdc-ad-aks/bdc.json -j "$.spec.resources.appproxy.spec.endpoints[0].serviceType=NodePort"
Lancer le déploiement
La commande suivante lance un déploiement de cluster Big Data :
azdata bdc create --config-profile bdc-ad-aks --accept-eula yes
Contenu connexe
Commentaires
Prochainement : Tout au long de l'année 2024, nous supprimerons progressivement les GitHub Issues en tant que mécanisme de retour d'information pour le contenu et nous les remplacerons par un nouveau système de retour d'information. Pour plus d’informations, voir: https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour