Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :![]() SQL Server sur Linux
SQL Server sur Linux
Ce tutoriel explique comment configurer des groupes de disponibilité SQL Server avec HPE Serviceguard pour Linux, exécuté sur des machines virtuelles locales ou des machines virtuelles Azure.
Pour obtenir une vue d’ensemble des clusters HPE Serviceguard, consultez les clusters HPE Serviceguard.
Note
Microsoft assure le support lié au déplacement des données, au groupe de disponibilité et aux composants SQL Server. Contactez HPE pour obtenir de l’aide relative à la documentation sur la gestion du quorum et du cluster HPE Serviceguard.
Ce didacticiel contient les tâches suivantes :
- Installez SQL Server sur les trois machines virtuelles que vous envisagez d’inclure dans le groupe de disponibilité.
- Installez HPE Serviceguard sur les machines virtuelles.
- Créez le cluster HPE Serviceguard.
- Créez l’équilibreur de charge dans le portail Azure.
- Créez le groupe de disponibilité et ajoutez un exemple de base de données au groupe de disponibilité.
- Déployez la charge de travail SQL Server sur le groupe de disponibilité via le gestionnaire de cluster Serviceguard.
- Effectuez un basculement automatique et réintégrez le nœud dans le cluster.
Prerequisites
Dans Azure, créez trois machines virtuelles Linux. Pour créer des machines virtuelles Linux, consultez le guide Démarrage rapide : Créer une machine virtuelle Linux dans le portail Azure. Quand vous déployez les machines virtuelles, veillez à utiliser les distributions Linux prises en charge par HPE ServiceGuard. Vous pouvez également déployer les machines virtuelles localement dans un environnement local si vous préférez.
Pour obtenir un exemple de distribution prise en charge, consultez HPE Serviceguard pour Linux. Contactez HPE pour obtenir des informations sur la prise en charge des environnements de cloud public.
Les instructions de ce tutoriel ont été validées pour HPE Serviceguard pour Linux. Une version d’essai peut être téléchargée à partir du site HPE.
Les fichiers de base de données SQL Server sur le montage de volume logique (LVM) pour les trois machines virtuelles. Consultez le guide de démarrage rapide pour Serviceguard Linux (HPE).
Vérifiez que le runtime Java OpenJDK est installé sur les machines virtuelles. Le SDK Java IBM n’est pas pris en charge.
Installer SQL Server
Sur les trois machines virtuelles, suivez l’une des étapes décrites dans la section suivante en fonction de la distribution Linux que vous choisissez pour ce didacticiel. Les étapes d’installation de SQL Server et d’outils.
Red Hat Enterprise Linux (RHEL)
SLES (SUSE Linux Enterprise Server)
Note
À compter de SQL Server 2025 (17.x), SUSE Linux Enterprise Server (SLES) n’est pas pris en charge.
Une fois cette étape terminée, vous disposez du service ET des outils SQL Server installés sur les trois machines virtuelles qui vont participer au groupe de disponibilité.
Installer HPE Serviceguard sur les machines virtuelles
Durant cette étape, vous installez HPE Serviceguard pour Linux sur les trois machines virtuelles. Le tableau suivant décrit le rôle de chaque serveur dans le cluster.
| Nombre d'ordinateurs virtuels | Rôle HPE Serviceguard | Rôle de réplica du groupe de disponibilité Microsoft SQL Server |
|---|---|---|
| 1 | Nœuds du cluster HPE Serviceguard | Réplica principal |
| 1 ou plus | Nœud du cluster HPE Serviceguard | Réplica secondaire |
| 1 | Serveur de quorum HPE Serviceguard | Réplica de configuration uniquement |
Note
Reportez-vous à cette vidéo de HPE, qui décrit comment installer et configurer un cluster HPE Serviceguard à partir de l'interface utilisateur.
Pour installer Serviceguard, utilisez la méthode cminstaller. Vous trouverez des instructions spécifiques via les liens ci-dessous :
- Installez Serviceguard pour Linux sur deux nœuds. Reportez-vous à la section Install_serviceguard_using_cminstaller.
- Installez le serveur de quorum Serviceguard sur le troisième nœud. Reportez-vous à la section Install_QS_from_the_ISO.
Une fois l’installation du cluster HPE Serviceguard terminée, vous pouvez activer le portail de gestion de cluster sur le port TCP 5522 sur le nœud réplica principal. Les étapes suivantes ajoutent une règle au pare-feu pour autoriser 5522. La commande suivante concerne un Red Hat Enterprise Linux (RHEL). Vous devez exécuter des commandes similaires pour d’autres distributions :
sudo firewall-cmd --zone=public --add-port=5522/tcp --permanent
sudo firewall-cmd --reload
Créer le cluster HPE Serviceguard
Suivez ces instructions pour créer et configurer le cluster HPE Serviceguard. Dans cette étape, vous configurez également le serveur de quorum.
- Configurez le serveur de quorum Serviceguard sur le troisième nœud. Reportez-vous à la section Configure_QS.
- Créez et configurez le cluster Serviceguard sur les deux autres nœuds. Reportez-vous à la section Configure_and_create_Cluster.
Note
Vous pouvez contourner l’installation manuelle de votre cluster HPE Serviceguard et du quorum, en ajoutant l’extension HPE Serviceguard pour Linux (SGLX) à partir de la Place de marché de machines virtuelles Azure lorsque vous créez votre machine virtuelle.
Créer le groupe de disponibilité et y ajouter un exemple de base de données
Dans cette étape, vous créez un groupe de disponibilité avec deux réplicas synchrones ou plus et un réplica de configuration uniquement, qui fournit une protection des données et peut également fournir une haute disponibilité. Le diagramme suivant illustre cette architecture :
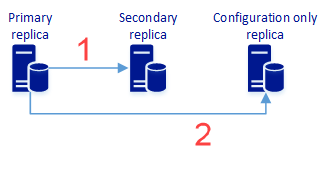
Réplication synchrone des données utilisateur vers le réplica secondaire. Il comprend également des métadonnées de configuration des groupes de disponibilité.
Réplication synchrone des métadonnées de configuration des groupes de disponibilité. Il n’inclut pas les données utilisateur.
Pour plus d’informations, consultez Haute disponibilité et protection des données pour les configurations des groupes de disponibilité.
Pour créer le groupe de disponibilité, effectuez les étapes suivantes :
- Activer les groupes de disponibilité et exécuter restart mssql-server sur toutes les machines virtuelles, y compris le réplica de configuration uniquement.
-
Activer une session d’événements
AlwaysOn_health(facultatif) - Créer un certificat sur la machine virtuelle principale
- Créer le certificat sur les serveurs secondaires
- Créer les points de terminaison de mise en miroir de bases de données sur les réplicas
- Créer un groupe de disponibilité
- Joindre les réplicas secondaires
- Ajouter une base de données au groupe de disponibilité
Activer les groupes de disponibilité et exécuter restart mssql-server
Activez les groupes de disponibilité sur tous les nœuds qui hébergent une instance SQL Server. Ensuite, redémarrez mssql-server. Exécutez le script suivant sur les trois réplicas :
sudo /opt/mssql/bin/mssql-conf
set hadr.hadrenabled 1 sudo systemctl restart mssql-server
Activer une session d’événements AlwaysOn_health (facultatif)
Si vous le souhaitez, activez les événements étendus des groupes de disponibilité Always On pour faciliter le diagnostic de la cause racine lorsque vous résolvez les problèmes d’un groupe de disponibilité. Exécutez la commande suivante sur chaque instance de SQL Server :
ALTER EVENT SESSION AlwaysOn_health ON SERVER
WITH (STARTUP_STATE = ON);
GO
Créer un certificat sur la machine virtuelle principale
Le script Transact-SQL suivant crée une clé principale et un certificat. Il sauvegarde ensuite le certificat et sécurise le fichier avec une clé privée. Mettez à jour le script avec des mots de passe forts. Connectez-vous à l’instance principale de SQL Server et exécutez le script Transact-SQL suivant :
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>';
CREATE CERTIFICATE dbm_certificate
WITH SUBJECT = 'dbm';
BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/dbm_certificate.pvk',
ENCRYPTION BY PASSWORD = '<private-key-password>'
);
À ce stade, le réplica SQL Server principal a un certificat à l’emplacement /var/opt/mssql/data/dbm_certificate.cer et une clé privée à l’emplacement var/opt/mssql/data/dbm_certificate.pvk. Copiez ces deux fichiers au même emplacement sur tous les serveurs qui hébergeront les réplicas de disponibilité. Pour accéder à ces fichiers, utilisez l’utilisateur mssql ou accordez l’autorisation à l’utilisateur mssql .
Par exemple, sur le serveur source, la commande suivante copie les fichiers sur la machine cible. Remplacez les valeurs node2 par le nom de l’hôte qui exécute l’instance SQL Server secondaire. Copiez le certificat sur le réplica réservé à la configuration et exécutez les commandes suivantes sur ce nœud.
cd /var/opt/mssql/data
scp dbm_certificate.* root@<node2>:/var/opt/mssql/data/
Maintenant, sur les machines virtuelles secondaires exécutant l’instance secondaire et le réplica de configuration uniquement de SQL Server, exécutez les commandes suivantes pour que l’utilisateur mssql puisse posséder le certificat copié :
cd /var/opt/mssql/data
chown mssql:mssql dbm_certificate.*
Créer le certificat sur les serveurs secondaires
Le script Transact-SQL suivant crée une clé principale et un certificat à partir de la sauvegarde que vous avez créée sur le réplica SQL Server principal. Mettez à jour le script avec des mots de passe forts. Le mot de passe de déchiffrement est le même mot de passe que celui que vous avez utilisé pour créer le .pvk fichier à une étape antérieure. Pour créer le certificat, exécutez le script suivant sur tous les serveurs secondaires à l’exception du réplica de configuration uniquement :
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>';
CREATE CERTIFICATE dbm_certificate
FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/dbm_certificate.pvk',
DECRYPTION BY PASSWORD = '<private-key-password>'
);
Dans l’exemple précédent, remplacez <private-key-password> par le mot de passe que vous avez utilisé au moment de la création du certificat sur le réplica principal.
Créer les points de terminaison de mise en miroir de bases de données sur les réplicas
Sur les réplicas principaux et secondaires, exécutez les commandes suivantes pour créer les points de terminaison pour la mise en miroir des bases de données :
CREATE ENDPOINT [hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING
(
ROLE = WITNESS,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [hadr_endpoint]
STATE = STARTED;
Note
Le port 5022 est le port standard utilisé pour le point de terminaison de mise en miroir de bases de données, mais vous pouvez choisir n’importe quel autre port disponible.
Sur le réplica de configuration uniquement, créez le point de terminaison de mise en miroir de bases de données à l’aide de la commande suivante. Définissez la valeur de Role sur WITNESS, qui est le rôle requis pour la réplique uniquement de configuration.
CREATE ENDPOINT [hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING
(
ROLE = WITNESS,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [hadr_endpoint]
STATE = STARTED;
Créer un groupe de disponibilité
Sur l’instance du réplica principal, exécutez les commandes suivantes. Ces commandes créent un groupe de disponibilité nommé ag1, qui a un cluster_type EXTERNAL et qui accorde l’autorisation de création de base de données au groupe de disponibilité.
Avant d’exécuter les scripts suivants, remplacez les espaces réservés <node1>, <node2> et <node3> (réplique uniquement pour la configuration) par les noms des machines virtuelles que vous avez créées lors des étapes précédentes.
CREATE AVAILABILITY GROUP [ag1]
WITH (CLUSTER_TYPE = EXTERNAL)
FOR REPLICA ON
N'<node1>' WITH (
ENDPOINT_URL = N'tcp://<node1>:<5022>',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<node2>' WITH (
ENDPOINT_URL = N'tcp://<node2>:\<5022>',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<node3>' WITH (
ENDPOINT_URL = N'tcp://<node3>:<5022>',
AVAILABILITY_MODE = CONFIGURATION_ONLY
);
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
Se connecter aux répliques secondaires
Exécutez les commandes suivantes sur tous les réplicas secondaires. Ces commandes joignent les réplicas secondaires au groupe de disponibilité ag1 contenant le réplica principal et accordent l’autorisation de création de base de données au groupe de disponibilité ag1.
ALTER AVAILABILITY GROUP [ag1]
JOIN WITH (CLUSTER_TYPE = EXTERNAL);
GO
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
GO
Ajouter une base de données au groupe de disponibilité
Connectez-vous au réplica principal et exécutez les commandes T-SQL suivantes pour :
Créez un exemple de base de données nommé
db1, que vous allez ajouter au groupe de disponibilité.CREATE DATABASE [db1]; GODéfinir le mode de récupération complet (full) pour la base de données. Toutes les bases de données d’un groupe de disponibilité nécessitent le modèle de récupération complète.
ALTER DATABASE [db1] SET RECOVERY FULL;Sauvegardez la base de données. Une base de données doit avoir fait l’objet d’une sauvegarde complète au moins avant d’être ajoutée à un groupe de disponibilité.
BACKUP DATABASE [db1] TO DISK = N'/var/opt/mssql/data/db1.bak';Définissez le mode de récupération complet (full) pour la base de données.
ALTER DATABASE [db1] SET RECOVERY FULL;Sauvegardez la base de données sur le disque.
BACKUP DATABASE [db1] TO DISK = N'/var/opt/mssql/data/db1.bak';Ajoutez la base de données
db1au groupe de disponibilité.ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1];
Une fois les étapes précédentes terminées, vous voyez un ag1 groupe de disponibilité. Les trois machines virtuelles sont ajoutées en tant que répliques avec une réplique principale, une réplique secondaire et une réplique uniquement pour la configuration.
ag1 contient une seule base de données.
Déployer la charge de travail du groupe de disponibilité SQL Server (gestionnaire de cluster HPE)
Dans HPE Serviceguard, déployez la charge de travail SQL Server sur le groupe de disponibilité par le biais de l’interface utilisateur du gestionnaire de cluster Serviceguard.
Déployez la charge de travail du groupe de disponibilité, et activez la haute disponibilité (HA) et la reprise après sinistre (DR) via le cluster Serviceguard à l’aide de l’interface graphique de Serviceguard Manager. Reportez-vous à la section Protection de Microsoft SQL Server sur Linux pour les groupes de disponibilité Always On.
Créer l’équilibrage de charge dans le portail Azure
Pour les déploiements dans Azure Cloud, HPE Serviceguard pour Linux nécessite un équilibreur de charge pour permettre aux connexions clientes avec le réplica principal, de remplacer les adresses IP traditionnelles.
Dans le portail Azure, ouvrez le groupe de ressources contenant les machines virtuelles ou nœuds de cluster Serviceguard.
Dans le groupe de ressources, sélectionnez Ajouter.
Faites une recherche sur « équilibreur de charge » puis, dans les résultats de la recherche, sélectionnez l’équilibreur de charge qui est publié par Microsoft.
Dans le volet Équilibreur de charge, sélectionnez Créer.
Configurez l’équilibreur de charge comme ceci :
Setting Valeur Name Nom de l’équilibreur de charge. Par exemple : SQLAvailabilityGroupLB.Type Interne SKU De base ou Standard Réseau virtuel Réseau virtuel utilisé pour les réplicas de machine virtuelle Sous-réseau Sous-réseau dans lequel les instances SQL Server sont hébergées Affectation d’adresses IP statique Adresse IP privée Créer une adresse IP privée dans le sous-réseau Abonnement Choisir l’abonnement concerné Groupe de ressources Choisir le groupe de ressources concerné Emplacement Sélectionner le même emplacement que les nœuds SQL
Configurer le pool principal
Le pool de back-ends est constitué des adresses des deux instances sur lesquelles le cluster Serviceguard est configuré.
- Dans votre groupe de ressources, cliquez sur l’équilibreur de charge que vous avez créé.
- Accédez aux Paramètres>pools back-end, puis sélectionnez Ajouter pour créer un pool d’adresses back-end.
- Dans Ajouter un pool de back-ends, sous Nom, tapez un nom pour le pool de back-ends.
- Sous Associé à, sélectionnez Machine virtuelle.
- Sélectionnez chaque machine virtuelle dans l’environnement et associez l’adresse IP appropriée à chaque sélection.
- Sélectionnez Ajouter.
Créer une sonde
La sonde définit la façon dont Azure vérifie lequel des nœuds du cluster Serviceguard est le réplica principal. Azure sonde le service avec l’adresse IP sur un port que vous définissez lors de la création de la sonde.
Dans le volet Paramètres de l’équilibreur de charge, sélectionnez Sondes d’intégrité.
Dans le volet Sondes d’intégrité, sélectionnez Ajouter.
Utilisez les valeurs suivantes pour configurer la sonde :
Setting Valeur Name Nom de la sonde. Par exemple : SQLAGPrimaryReplicaProbe.Protocol TCP Port Vous pouvez utiliser n’importe quel port disponible. Par exemple, 59999. Intervalle 5 Seuil de l'état non sain 2 Sélectionnez OK.
Connectez-vous à toutes vos machines virtuelles, puis ouvrez le port de la sonde à l’aide des commandes suivantes :
sudo firewall-cmd --zone=public --add-port=59999/tcp --permanent sudo firewall-cmd --reload
Azure crée la sonde, puis il l’utilise pour tester le nœud Serviceguard sur lequel l’instance du réplica principal du groupe de disponibilité est en cours d’exécution. N’oubliez pas le port que vous avez configuré (59999), qui est nécessaire pour déployer le groupe de disponibilité (AG) dans le cluster Serviceguard.
Configurer les règles d’équilibrage de charge
Les règles d’équilibrage de la charge configurent la façon dont l’équilibreur de charge route le trafic vers le nœud Serviceguard, qui est le réplica principal dans le cluster. Pour cet équilibreur de charge, activez le retour direct du serveur, car un seul des nœuds du cluster Serviceguard à la fois peut être un réplica principal.
Dans les paramètres de l’équilibreur de charge, sélectionnez règles d’équilibrage de charge.
Dans les règles d’équilibrage de charge, sélectionnez Ajouter.
Configurez la règle d’équilibrage de charge en utilisant les paramètres suivants :
Setting Valeur Name Nom représentant la règle d’équilibrage de charge. Par exemple : SQLAGPrimaryReplicaListener.Protocol TCP Port 1433 Port principal 1433. Cette valeur est ignorée, car cette règle utilise une adresse IP flottante. Sonde Utilisez le nom de la sonde que vous avez créée pour cet équilibrage de charge. Persistance de session Aucun Délai d’inactivité (minutes) 4 IP flottante activé Sélectionnez OK.
Azure configure la règle d’équilibrage de charge. À présent, l’équilibreur de charge est configuré pour router le trafic vers le nœud Serviceguard qui est l’instance du réplica principal dans le cluster.
Notez l’adresse IP frontale de l'équilibreur de charge LbReadWriteIP, que vous devez utiliser pour déployer le groupe de disponibilité dans le cluster Serviceguard.
À ce stade, le groupe de ressources a un équilibreur de charge qui se connecte à tous les nœuds Serviceguard. L’équilibreur de charge contient également une adresse IP permettant aux clients de se connecter à l’instance du réplica principal dans le cluster. Ainsi, n’importe quelle machine qui est un réplica principal pourra répondre aux demandes du groupe de disponibilité.
Effectuer un basculement automatique et joindre à nouveau le nœud au cluster
Pour le test de basculement automatique, mettez le réplica principal hors connexion (hors tension). Cette action réplique l’indisponibilité soudaine du nœud principal. Le comportement attendu est le suivant :
Le gestionnaire de cluster promeut l’un des réplicas secondaires du groupe de disponibilité en réplica principal.
Le réplica principal à l’arrêt rejoint automatiquement le cluster après son redémarrage. Le gestionnaire de cluster le promeut en réplica secondaire.
Pour HPE Serviceguard, voir Tester la configuration pour être prêt au basculement.