Surveillance et télémétrie (création d’applications cloud Real-World avec Azure)
par Rick Anderson, Tom Dykstra
Télécharger corriger le projet ou télécharger le livre électronique
Le livre électronique Building Real World Cloud Apps with Azure est basé sur une présentation développée par Scott Guthrie. Il explique 13 modèles et pratiques qui peuvent vous aider à développer des applications web pour le cloud. Pour plus d’informations sur le livre électronique, consultez le premier chapitre.
De nombreuses personnes s’appuient sur les clients pour leur faire savoir quand leur application est en panne. Ce n’est pas vraiment une bonne pratique nulle part, et surtout pas dans le cloud. Il n’y a aucune garantie de notification rapide, et lorsque vous recevez une notification, vous obtenez souvent des données minimales ou trompeuses sur ce qui s’est passé. Avec de bons systèmes de télémétrie et de journalisation, vous pouvez être conscient de ce qui se passe avec votre application, et en cas de problème, vous le découvrez immédiatement et disposez d’informations de dépannage utiles à utiliser.
Acheter ou louer une solution de télémétrie
Notes
Cet article a été écrit avant la publication d’Application Insights . Application Insights est l’approche privilégiée pour les solutions de télémétrie sur Azure. Pour plus d’informations, consultez Configurer Application Insights pour votre site web ASP.NET .
L’une des choses qui est géniale dans l’environnement cloud est qu’il est vraiment facile d’acheter ou de louer votre chemin vers la victoire. La télémétrie en est un exemple. Sans beaucoup d’efforts, vous pouvez obtenir un très bon système de télémétrie opérationnel, très rentable. Il existe un ensemble d’excellents partenaires qui s’intègrent à Azure, et certains d’entre eux ont des niveaux gratuits. Vous pouvez donc obtenir des données de télémétrie de base pour rien. Voici quelques-unes des options actuellement disponibles sur Azure :
Microsoft System Center inclut également des fonctionnalités de supervision.
Nous allons rapidement parcourir la configuration de New Relic pour montrer à quel point il peut être facile d’utiliser un système de télémétrie.
Dans le portail de gestion Azure, inscrivez-vous au service. Cliquez sur Nouveau, puis sur Store. La boîte de dialogue Choisir un complément s’affiche . Faites défiler vers le bas et cliquez sur New Relic.

Cliquez sur la flèche droite et choisissez le niveau de service souhaité. Pour cette démonstration, nous allons utiliser le niveau gratuit.
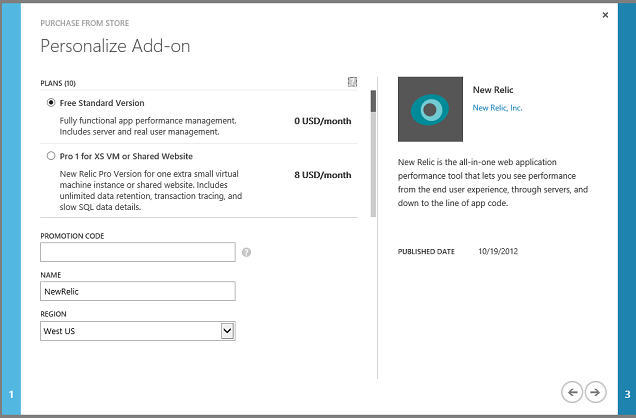
Cliquez sur la flèche droite, confirmez l'« achat » et New Relic s’affiche désormais en tant que module complémentaire dans le portail.
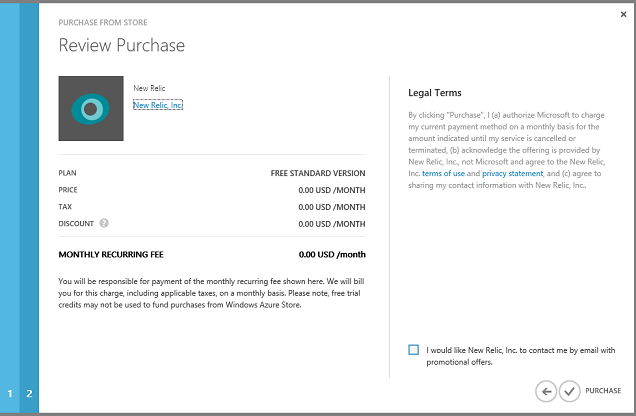
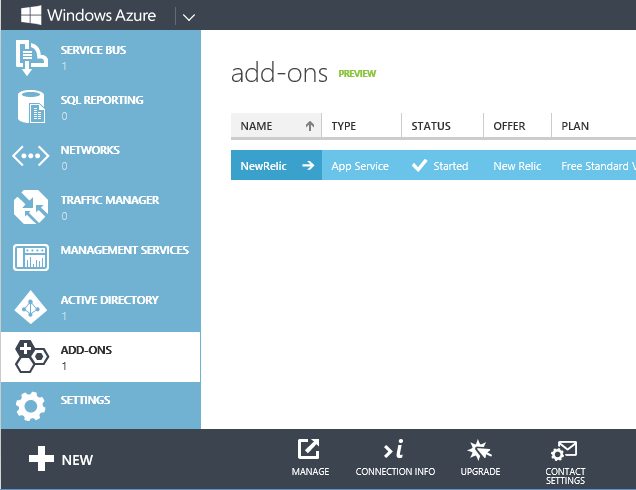
Cliquez sur Informations de connexion, puis copiez la clé de licence.
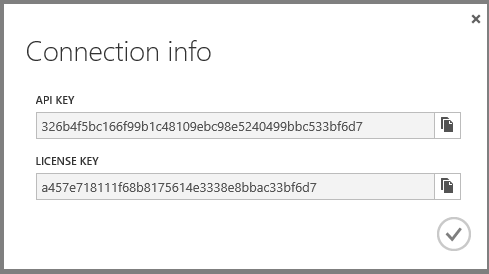
Accédez à l’onglet Configurer de votre application web dans le portail, définissez Analyse des performancessur Module complémentaire et définissez la liste déroulante Choisir un complément surNew Relic. Ensuite, cliquez sur Enregistrer.
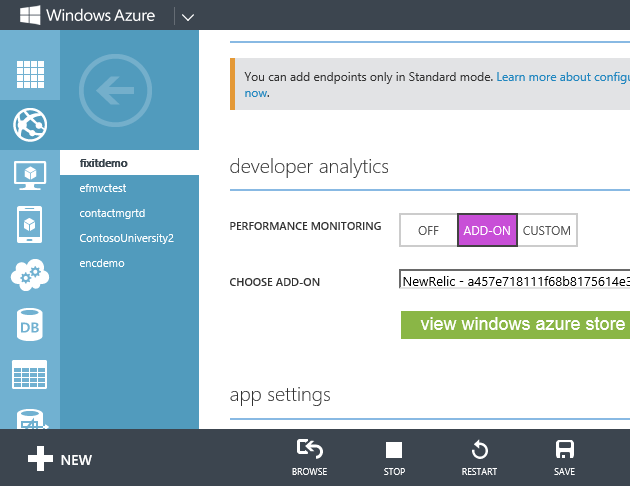
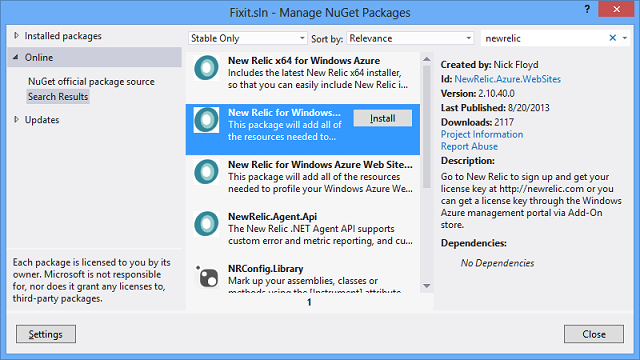
Dans Visual Studio, installez le package NuGet New Relic dans votre application.
Déployez l’application sur Azure et commencez à l’utiliser. Créez quelques tâches de correction pour fournir une activité que New Relic doit surveiller.
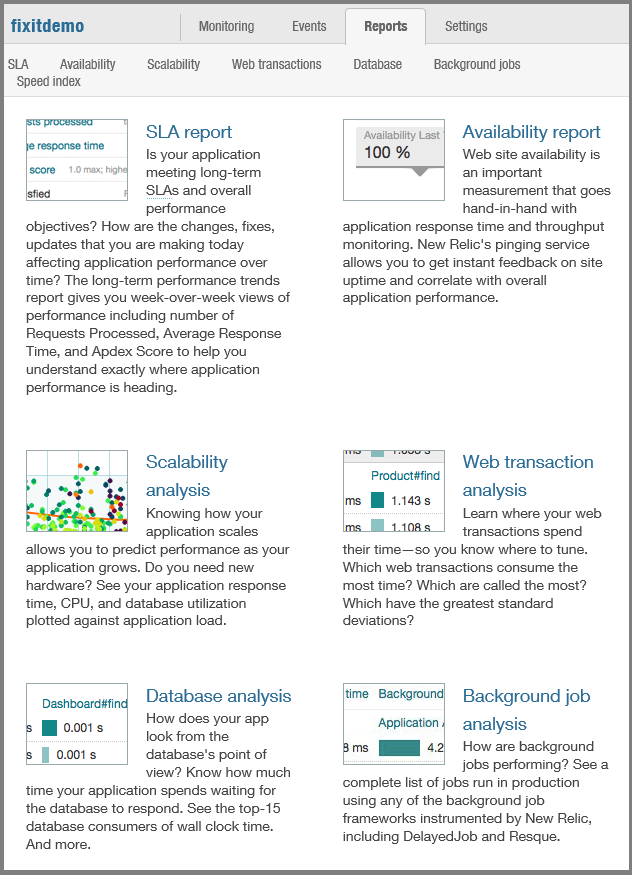
Revenez ensuite à la page New Relic sous l’onglet Modules complémentaires du portail, puis cliquez sur Gérer. Le portail vous envoie au portail de gestion New Relic, en utilisant l’authentification unique pour l’authentification afin que vous n’ayez pas à entrer à nouveau vos informations d’identification. La page Vue d’ensemble présente diverses statistiques de performances. (Cliquez sur l’image pour afficher la page de vue d’ensemble pleine taille.)
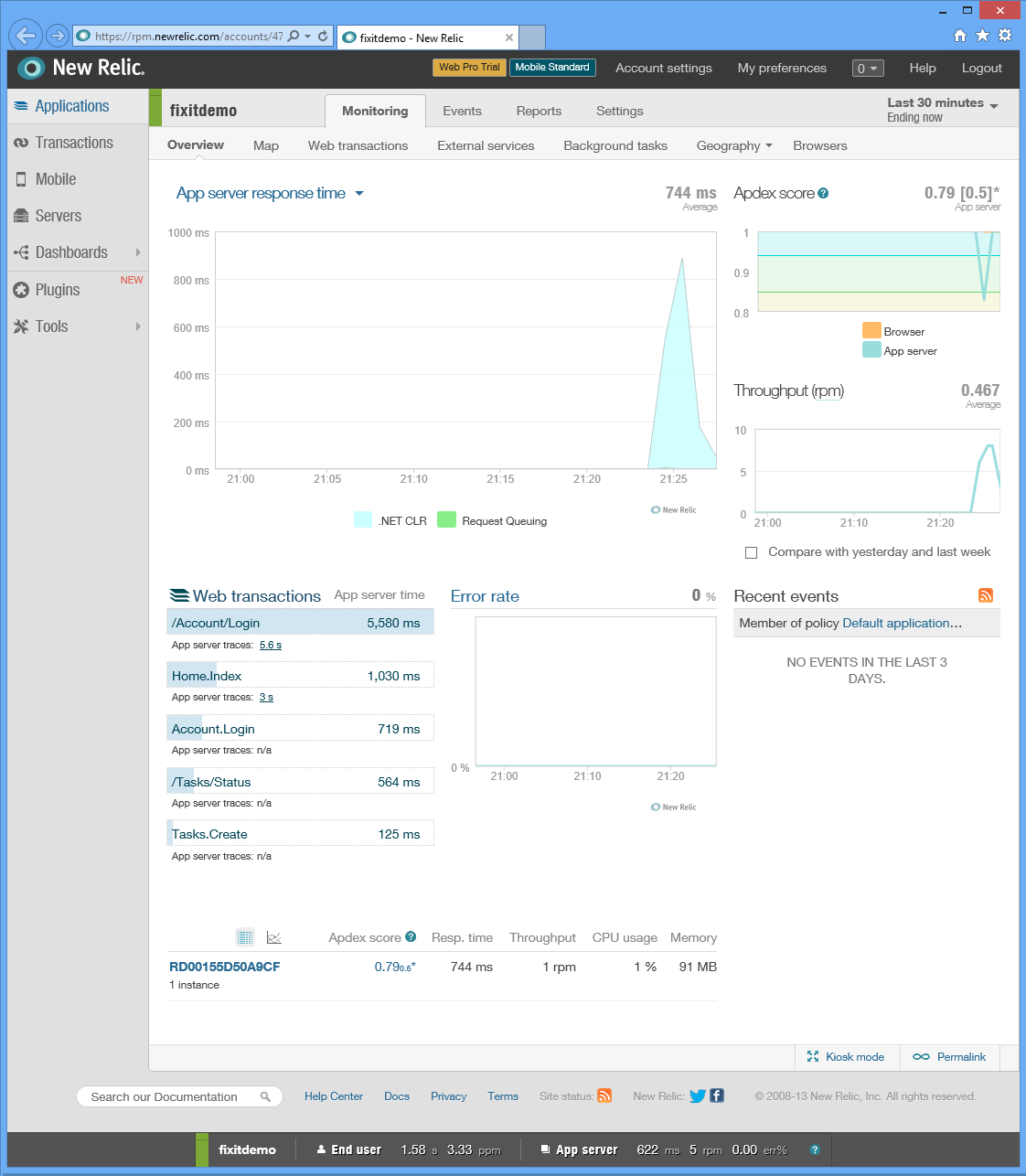
Voici quelques-unes des statistiques que vous pouvez voir :
Temps de réponse moyen à différents moments de la journée.
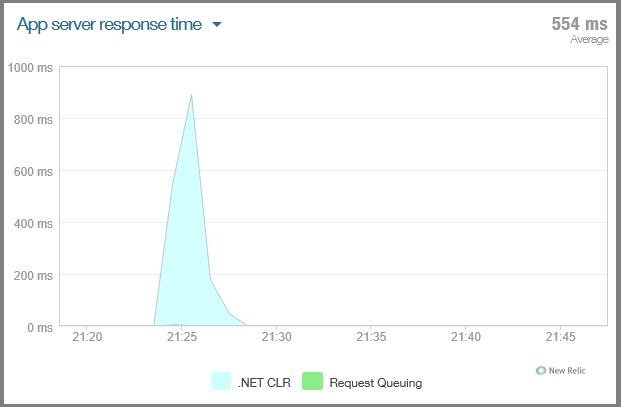
Débit (en requêtes par minute) à différents moments de la journée.
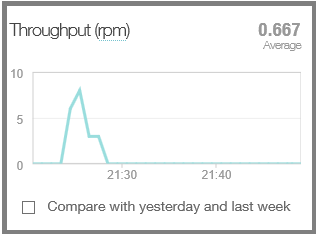
Temps processeur du serveur consacré à la gestion des différentes requêtes HTTP.
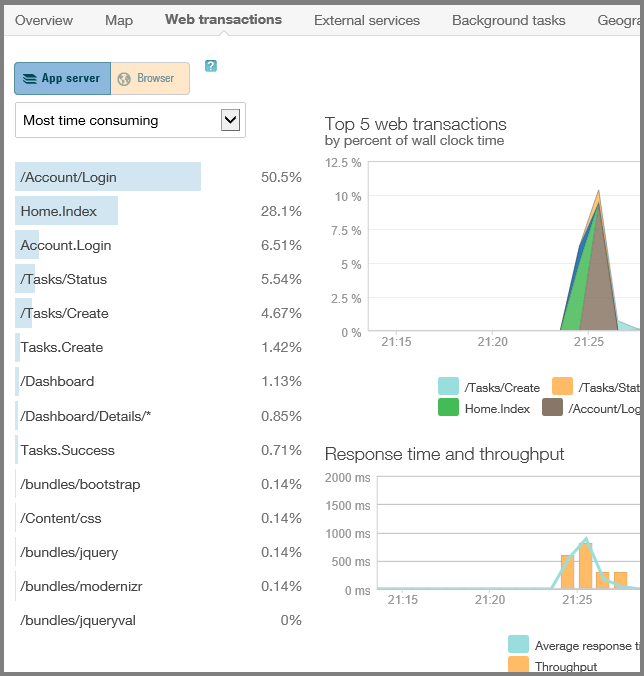
Temps processeur passé dans différentes parties du code de l’application :
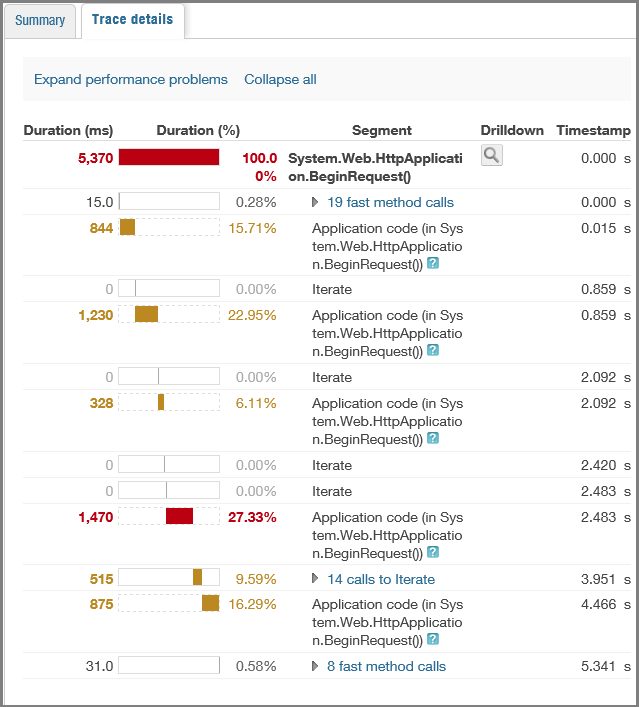
Statistiques de performances historiques.
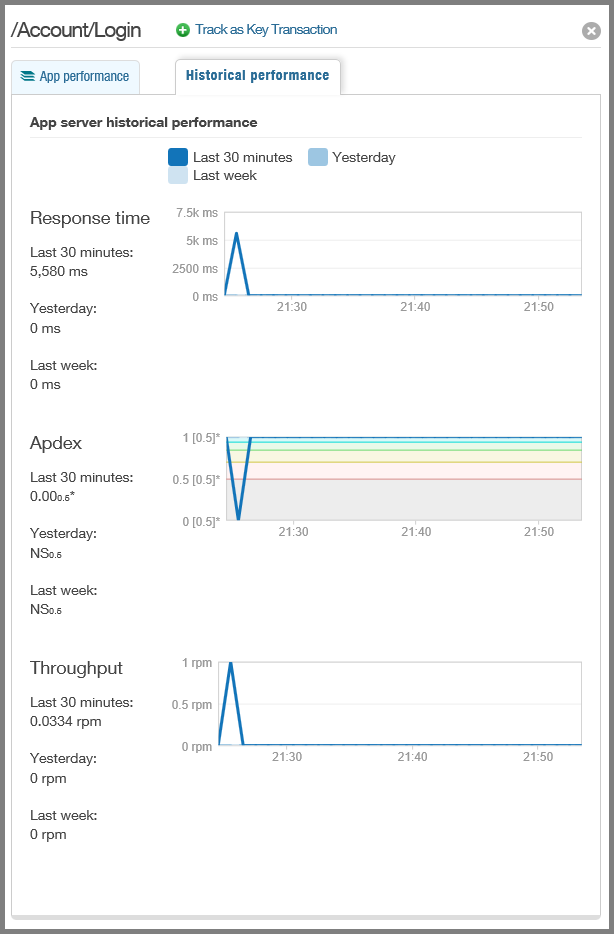
Appels à des services externes tels que le service Blob et statistiques sur la fiabilité et la réactivité du service.
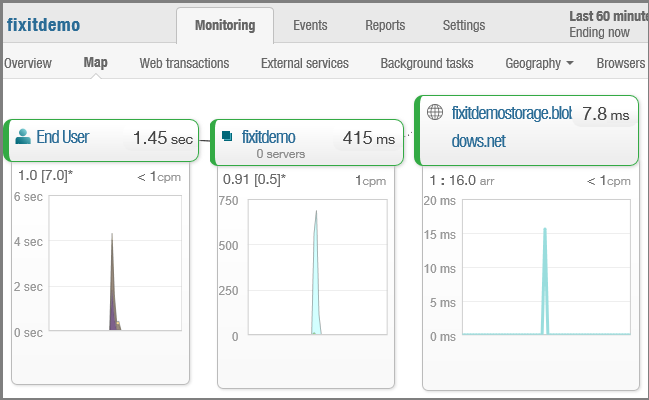
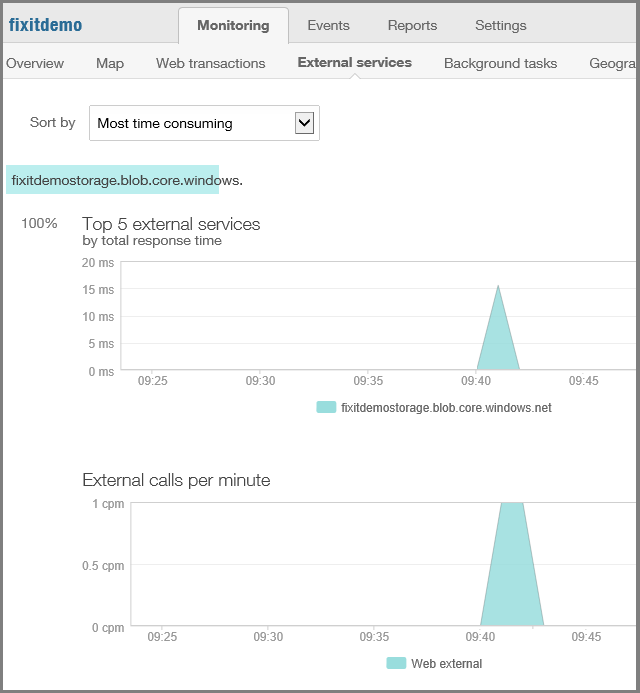
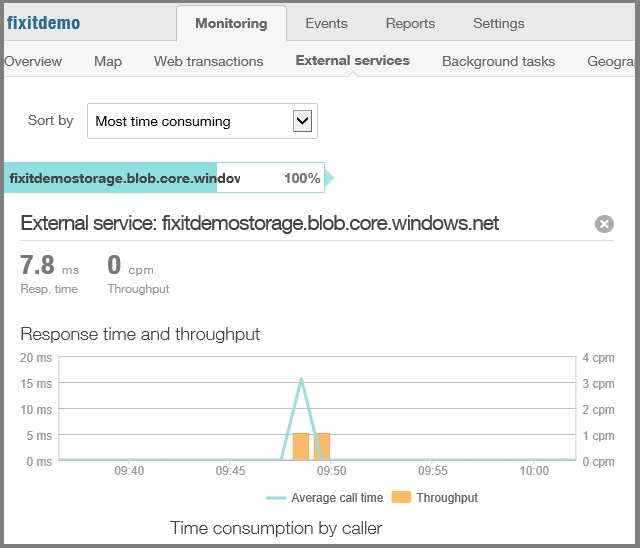
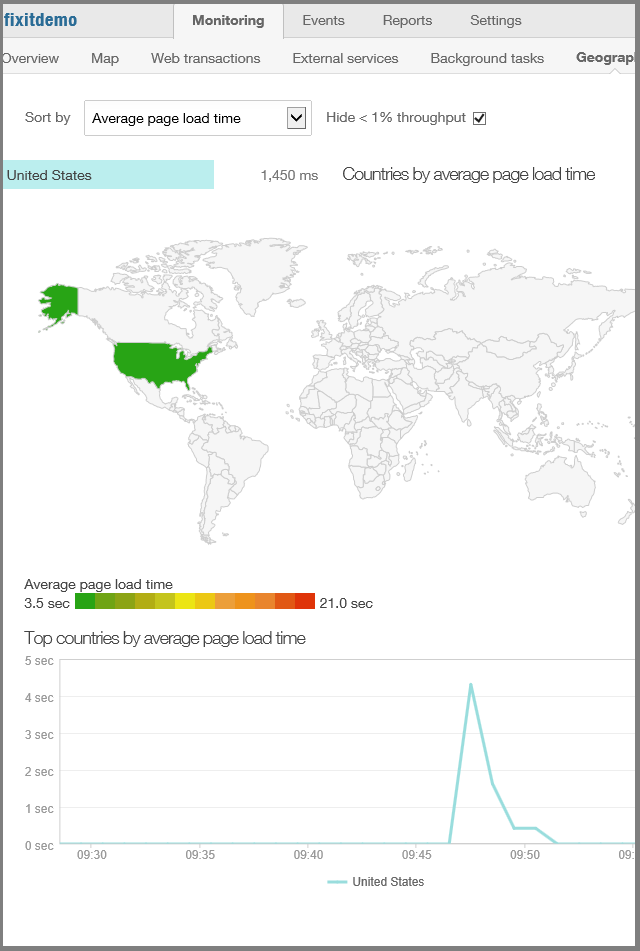
Informations sur l’endroit où dans le monde ou d’où provient le trafic d’application web aux États-Unis.
Vous pouvez également configurer des rapports et des événements. Par exemple, vous pouvez indiquer que chaque fois que vous commencez à voir des erreurs, envoyez un e-mail pour avertir le personnel du support technique du problème.
New Relic n’est qu’un exemple de système de télémétrie ; vous pouvez obtenir tout cela à partir d’autres services ainsi. La beauté du cloud est que sans avoir à écrire de code, et pour un coût minimal ou sans frais, vous pouvez soudainement obtenir beaucoup plus d’informations sur la façon dont votre application est utilisée et ce que vos clients vivent réellement.
Journaliser les insights
Un package de télémétrie est une bonne première étape, mais vous devez toujours instrumenter votre propre code. Le service de télémétrie vous indique en cas de problème et vous indique ce que les clients rencontrent, mais il ne vous donne peut-être pas beaucoup d’informations sur ce qui se passe dans votre code.
Vous ne souhaitez pas avoir à vous connecter à distance à un serveur de production pour voir ce que fait votre application. Cela peut être pratique quand vous avez un serveur, mais qu’en est-il quand vous avez mis à l’échelle des centaines de serveurs et que vous ne savez pas dans lesquels vous devez vous connecter à distance ? Votre journalisation doit fournir suffisamment d’informations que vous n’avez jamais à distance dans les serveurs de production pour analyser et déboguer les problèmes. Vous devez journaliser suffisamment d’informations pour pouvoir isoler les problèmes uniquement par le biais des journaux.
Se connecter en production
De nombreuses personnes n’activent le traçage en production que lorsqu’il y a un problème et qu’elles veulent déboguer. Cela peut entraîner un délai important entre le moment où vous avez connaissance d’un problème et le moment où vous obtenez des informations de dépannage utiles à ce sujet. Et les informations que vous obtenez peuvent ne pas être utiles pour les erreurs intermittentes.
Ce que nous recommandons dans l’environnement cloud où le stockage est bon marché, c’est de laisser toujours la connexion en production. Ainsi, lorsque des erreurs se produisent, vous les avez déjà journalisées, et vous disposez de données historiques qui peuvent vous aider à analyser les problèmes qui se développent au fil du temps ou se produisent régulièrement à différents moments. Vous pouvez automatiser un processus de purge pour supprimer d’anciens journaux, mais vous constaterez peut-être qu’il est plus coûteux de configurer un tel processus que de conserver les journaux.
Le coût supplémentaire de la journalisation est insignifiant par rapport au temps et à l’argent de résolution des problèmes que vous pouvez économiser en mettant à disposition toutes les informations dont vous avez besoin en cas de problème. Ensuite, quand quelqu’un vous dit qu’il a eu une erreur aléatoire vers 8 :00 la nuit dernière, mais qu’il ne se souvient pas de l’erreur, vous pouvez facilement découvrir quel était le problème.
Pour moins de 4 $ par mois, vous pouvez conserver 50 gigaoctets de journaux, et l’impact sur les performances de la journalisation est insignifiant tant que vous gardez une chose à l’esprit : pour éviter les goulots d’étranglement des performances, assurez-vous que votre bibliothèque de journalisation est asynchrone.
Différencier les journaux qui informent des journaux qui nécessitent une action
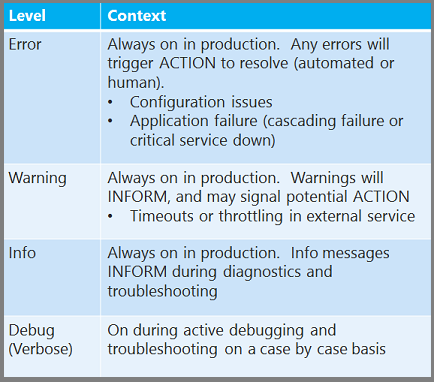
Les journaux sont destinés à INFORMER (je veux que vous sachiez quelque chose) ou ACT (je veux que vous fassiez quelque chose). Veillez à écrire uniquement les journaux ACT pour les problèmes qui nécessitent réellement une personne ou un processus automatisé pour agir. Un trop grand nombre de journaux ACT créera du bruit, nécessitant trop de travail pour tout parcourir pour trouver des problèmes réels. Et si vos journaux ACT déclenchent automatiquement une action telle que l’envoi d’e-mails au personnel du support technique, évitez de laisser des milliers d’actions de ce type être déclenchées par un seul problème.
Dans le suivi .NET System.Diagnostics, les journaux peuvent recevoir le niveau d’erreur, d’avertissement, d’informations et de débogage/détaillé. Vous pouvez différencier ACT des journaux INFORM en réservant le niveau d’erreur pour les journaux ACT et en utilisant les niveaux inférieurs pour les journaux INFORM.
Configurer les niveaux de journalisation au moment de l’exécution
Bien qu’il soit utile d’avoir toujours la journalisation en production, une autre bonne pratique consiste à implémenter une infrastructure de journalisation qui vous permet d’ajuster au moment de l’exécution le niveau de détail que vous journalisez, sans redéployer ou redémarrer votre application. Par exemple, lorsque vous utilisez la fonctionnalité de suivi dans System.Diagnostics , vous pouvez créer des journaux d’erreur, d’avertissement, d’informations et de débogage/détaillé. Nous vous recommandons de toujours consigner les journaux d’erreur, d’avertissement et d’informations en production, et vous voudrez pouvoir ajouter dynamiquement la journalisation déboguer/détaillée pour résoudre les problèmes au cas par cas.
Web Apps dans Azure App Service disposez d’une prise en charge intégrée pour l’écriture System.Diagnostics de journaux dans le système de fichiers, le stockage Table ou le stockage Blob. Vous pouvez sélectionner différents niveaux de journalisation pour chaque destination de stockage, et vous pouvez modifier le niveau de journalisation à la volée sans redémarrer votre application. La prise en charge du stockage Blob facilite l’exécution des travaux d’analyse HDInsight sur vos journaux d’application, car HDInsight sait comment utiliser directement le stockage Blob.
journaliser des exceptions
Ne mettez pas d’exception. ToString() dans votre code de journalisation. Cela exclut les informations contextuelles. Dans le cas d’erreurs SQL, il exclut le numéro d’erreur SQL. Pour toutes les exceptions, incluez les informations de contexte, l’exception elle-même et les exceptions internes pour vous assurer que vous fournissez tout ce qui sera nécessaire pour la résolution des problèmes. Par exemple, les informations de contexte peuvent inclure le nom du serveur, un identificateur de transaction et un nom d’utilisateur (mais pas le mot de passe ou les secrets !).
Si vous comptez sur chaque développeur pour faire la bonne chose avec la journalisation des exceptions, certains d’entre eux ne le feront pas. Pour vous assurer que cela est effectué de la bonne façon à chaque fois, créez la gestion des exceptions directement dans votre interface d’enregistreur d’événements : passez l’objet d’exception lui-même à la classe d’enregistreur d’événements et consignez correctement les données d’exception dans la classe logger.
Journaliser les appels aux services
Nous vous recommandons vivement d’écrire un journal chaque fois que votre application appelle un service, qu’il s’agisse d’une base de données, d’une API REST ou d’un service externe. Incluez dans vos journaux non seulement une indication de réussite ou d’échec, mais également la durée de chaque requête. Dans l’environnement cloud, vous verrez souvent des problèmes liés à des ralentissements plutôt qu’à des pannes complètes. Quelque chose qui prend normalement 10 millisecondes peut soudainement commencer à prendre une seconde. Quand quelqu’un vous dit que votre application est lente, vous souhaitez être en mesure d’examiner New Relic ou un service de télémétrie que vous avez et de valider son expérience, puis vous voulez être en mesure de rechercher vos propres journaux pour découvrir les détails de la raison pour laquelle il est lent.
Utiliser une interface ILogger
Lorsque vous créez une application de production, nous vous recommandons de créer une interface ILogger simple et d’y coller certaines méthodes. Cela permet de modifier facilement l’implémentation de la journalisation ultérieurement et de ne pas avoir à parcourir tout votre code pour le faire. Nous pourrions utiliser la System.Diagnostics.Trace classe dans l’application Fix It, mais au lieu de cela, nous l’utilisons sous les couvertures dans une classe de journalisation qui implémente ILogger, et nous effectuons des appels de méthode ILogger dans toute l’application.
De cette façon, si vous souhaitez enrichir votre journalisation, vous pouvez remplacer par System.Diagnostics.Trace le mécanisme de journalisation de votre choix. Par exemple, à mesure que votre application se développe, vous pouvez décider d’utiliser un package de journalisation plus complet, tel que NLog ou Enterprise Library Logging Application Block. (Log4Net est une autre infrastructure de journalisation populaire, mais elle n’effectue pas de journalisation asynchrone.)
L’une des raisons possibles de l’utilisation d’une infrastructure telle que NLog est de faciliter la division de la sortie de journalisation en magasins de données à volume élevé et à valeur élevée distincts. Cela vous permet de stocker efficacement de grands volumes de données INFORM sur lesquelles vous n’avez pas besoin d’exécuter des requêtes rapides, tout en conservant un accès rapide aux données ACT.
Journalisation sémantique
Pour obtenir une méthode relativement nouvelle pour effectuer la journalisation qui peut produire des informations de diagnostic plus utiles, consultez Enterprise Library Semantic Logging Application Block (SLAB). SLAB utilise le suivi d’événements pour Windows (ETW) et la prise en charge d’EventSource dans .NET 4.5 pour vous permettre de créer des journaux plus structurés et interrogeables. Vous définissez une méthode différente pour chaque type d’événement que vous journalisez, ce qui vous permet de personnaliser les informations que vous écrivez. Par exemple, pour enregistrer une erreur de SQL Database, vous pouvez appeler une LogSQLDatabaseError méthode. Pour ce type d’exception, vous savez qu’une information clé est le numéro d’erreur. Vous pouvez donc inclure un paramètre de numéro d’erreur dans la signature de la méthode et enregistrer le numéro d’erreur sous forme de champ distinct dans l’enregistrement de journal que vous écrivez. Étant donné que le nombre se trouve dans un champ distinct, vous pouvez obtenir plus facilement et de manière plus fiable des rapports basés sur des numéros d’erreur SQL que si vous concaténiez simplement le numéro d’erreur dans une chaîne de message.
Journalisation dans l’application Corriger le problème
Interface ILogger
Voici l’interface ILogger dans l’application Corriger.
public interface ILogger
{
void Information(string message);
void Information(string fmt, params object[] vars);
void Information(Exception exception, string fmt, params object[] vars);
void Warning(string message);
void Warning(string fmt, params object[] vars);
void Warning(Exception exception, string fmt, params object[] vars);
void Error(string message);
void Error(string fmt, params object[] vars);
void Error(Exception exception, string fmt, params object[] vars);
void TraceApi(string componentName, string method, TimeSpan timespan);
void TraceApi(string componentName, string method, TimeSpan timespan, string properties);
void TraceApi(string componentName, string method, TimeSpan timespan, string fmt, params object[] vars);
}
Ces méthodes vous permettent d’écrire des journaux aux quatre mêmes niveaux pris en charge par System.Diagnostics. Les méthodes TraceApi permettent de journaliser les appels de service externes avec des informations sur la latence. Vous pouvez également ajouter un ensemble de méthodes pour le niveau Debug/Verbose.
Implémentation logger de l’interface ILogger
L’implémentation de l’interface est vraiment simple. Il appelle simplement les méthodes System.Diagnostics standard. L’extrait de code suivant montre les trois méthodes Information et chacune des autres.
public class Logger : ILogger
{
public void Information(string message)
{
Trace.TraceInformation(message);
}
public void Information(string fmt, params object[] vars)
{
Trace.TraceInformation(fmt, vars);
}
public void Information(Exception exception, string fmt, params object[] vars)
{
var msg = String.Format(fmt, vars);
Trace.TraceInformation(string.Format(fmt, vars) + ";Exception Details={0}", exception.ToString());
}
public void Warning(string message)
{
Trace.TraceWarning(message);
}
public void Error(string message)
{
Trace.TraceError(message);
}
public void TraceApi(string componentName, string method, TimeSpan timespan, string properties)
{
string message = String.Concat("component:", componentName, ";method:", method, ";timespan:", timespan.ToString(), ";properties:", properties);
Trace.TraceInformation(message);
}
}
Appel des méthodes ILogger
Chaque fois que le code de l’application Corriger le problème intercepte une exception, il appelle une méthode ILogger pour consigner les détails de l’exception. Et chaque fois qu’il effectue un appel à la base de données, au service Blob ou à une API REST, il démarre un chronomètre avant l’appel, arrête le chronomètre lorsque le service retourne et consigne le temps écoulé avec des informations sur la réussite ou l’échec.
Notez que le message du journal inclut le nom de la classe et le nom de la méthode. Il est recommandé de s’assurer que les messages de journal identifient la partie du code de l’application qui les a écrits.
public class FixItTaskRepository : IFixItTaskRepository
{
private MyFixItContext db = new MyFixItContext();
private ILogger log = null;
public FixItTaskRepository(ILogger logger)
{
log = logger;
}
public async Task<FixItTask> FindTaskByIdAsync(int id)
{
FixItTask fixItTask = null;
Stopwatch timespan = Stopwatch.StartNew();
try
{
fixItTask = await db.FixItTasks.FindAsync(id);
timespan.Stop();
log.TraceApi("SQL Database", "FixItTaskRepository.FindTaskByIdAsync", timespan.Elapsed, "id={0}", id);
}
catch(Exception e)
{
log.Error(e, "Error in FixItTaskRepository.FindTaskByIdAsynx(id={0})", id);
}
return fixItTask;
}
Ainsi, pour chaque fois que l’application Corriger le problème a passé un appel à SQL Database, vous pouvez voir l’appel, la méthode qui l’a appelé et exactement le temps nécessaire.
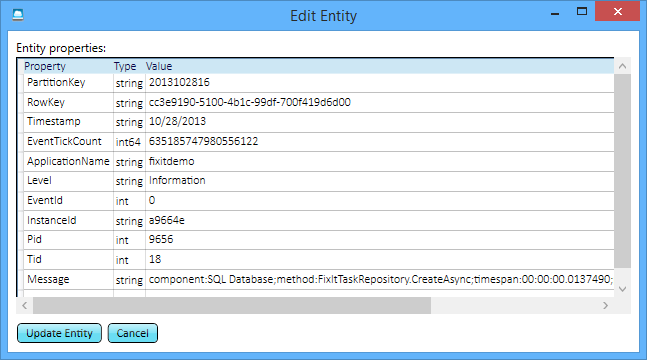
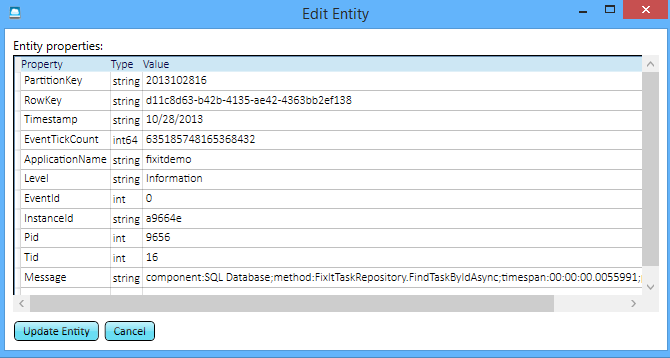
Si vous parcourez les journaux, vous pouvez voir que la durée des appels de base de données est variable. Ces informations peuvent être utiles : dans la mesure où l’application consigne tout cela, vous pouvez analyser les tendances historiques du fonctionnement du service de base de données au fil du temps. Pour instance, un service peut être rapide la plupart du temps, mais les demandes peuvent échouer ou les réponses peuvent ralentir à certains moments de la journée.
Vous pouvez faire la même chose pour le service Blob : pour chaque fois que l’application charge un nouveau fichier, il existe un journal et vous pouvez voir exactement combien de temps il a fallu pour charger chaque fichier.
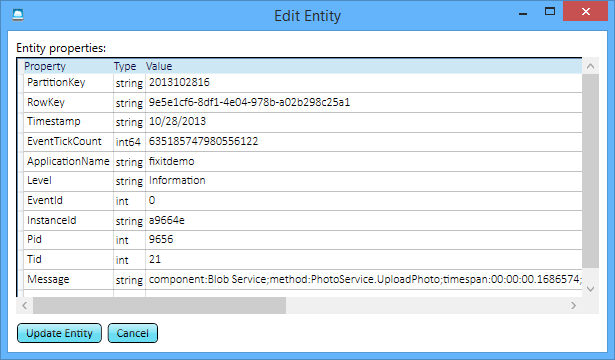
Il s’agit juste de quelques lignes de code supplémentaires à écrire chaque fois que vous appelez un service, et maintenant, chaque fois que quelqu’un dit qu’il a rencontré un problème, vous savez exactement quel était le problème, s’il s’agissait d’une erreur ou même s’il s’agissait simplement d’une exécution lente. Vous pouvez identifier la source du problème sans avoir à vous connecter à distance à un serveur ou à activer la journalisation après l’erreur et espérer la recréer.
Injection de dépendances dans l’application Corriger le problème
Vous vous demandez peut-être comment le constructeur de référentiel dans l’exemple ci-dessus obtient l’implémentation de l’interface de l’enregistreur d’événements :
public class FixItTaskRepository : IFixItTaskRepository
{
private MyFixItContext db = new MyFixItContext();
private ILogger log = null;
public FixItTaskRepository(ILogger logger)
{
log = logger;
}
Pour connecter l’interface à l’implémentation, l’application utilise l’injection de dépendances (DI) avec AutoFac. L’ID vous permet d’utiliser un objet basé sur une interface à de nombreux endroits dans votre code et n’a qu’à spécifier dans un seul emplacement l’implémentation qui est utilisée lorsque l’interface est instanciée. Cela facilite la modification de l’implémentation : par exemple, vous pouvez remplacer l’enregistreur System.Diagnostics par un enregistreur NLog. Ou pour les tests automatisés, vous pouvez remplacer une version fictive de l’enregistreur d’événements.
L’application Fix It utilise l’ID dans tous les dépôts et tous les contrôleurs. Les constructeurs des classes de contrôleur obtiennent une interface ITaskRepository de la même façon que le dépôt obtient une interface d’enregistreur d’événements :
public class DashboardController : Controller
{
private IFixItTaskRepository fixItRepository = null;
public DashboardController(IFixItTaskRepository repository)
{
fixItRepository = repository;
}
L’application utilise la bibliothèque AutoFac DI pour fournir automatiquement des instances TaskRepository et Logger pour ces constructeurs.
public class DependenciesConfig
{
public static void RegisterDependencies()
{
var builder = new ContainerBuilder();
builder.RegisterControllers(typeof(MvcApplication).Assembly);
builder.RegisterType<Logger>().As<ILogger>().SingleInstance();
builder.RegisterType<FixItTaskRepository>().As<IFixItTaskRepository>();
builder.RegisterType<PhotoService>().As<IPhotoService>().SingleInstance();
builder.RegisterType<FixItQueueManager>().As<IFixItQueueManager>();
var container = builder.Build();
DependencyResolver.SetResolver(new AutofacDependencyResolver(container));
}
}
Ce code indique essentiellement que partout où un constructeur a besoin d’une interface ILogger, passez une instance de la classe Logger et chaque fois qu’il a besoin d’une interface IFixItTaskRepository, transmettez une instance de la classe FixItTaskRepository.
AutoFac est l’une des nombreuses infrastructures d’injection de dépendances que vous pouvez utiliser. Un autre populaire est Unity, qui est recommandé et pris en charge par Microsoft Patterns and Practices.
Prise en charge de la journalisation intégrée dans Azure
Azure prend en charge les types de journalisation suivants pour Web Apps dans Azure App Service :
- Suivi System.Diagnostics (vous pouvez activer et désactiver et définir des niveaux à la volée sans redémarrer le site).
- Événements Windows.
- Journaux IIS (HTTP/FREB).
Azure prend en charge les types de journalisation suivants dans Services cloud :
- Suivi System.Diagnostics.
- Compteurs de performance.
- Événements Windows.
- Journaux IIS (HTTP/FREB).
- Surveillance d’annuaires personnalisés.
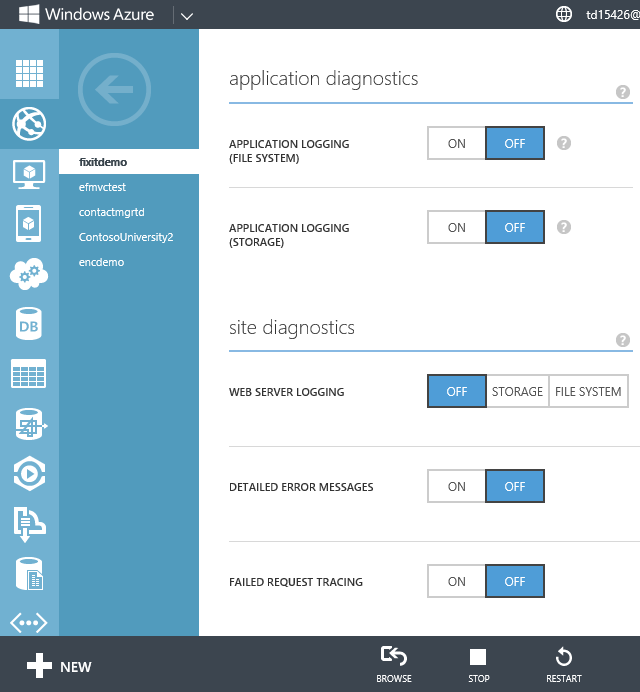
L’application Corriger le problème utilise le suivi System.Diagnostics. Pour activer la journalisation System.Diagnostics dans une application web, il vous suffit d’activer un commutateur dans le portail ou d’appeler l’API REST. Dans le portail, cliquez sur l’onglet Configuration de votre site, puis faites défiler vers le bas pour afficher la section Diagnostics de l’application . Vous pouvez activer ou désactiver la journalisation et sélectionner le niveau de journalisation souhaité. Azure peut écrire les journaux dans le système de fichiers ou dans un compte de stockage.
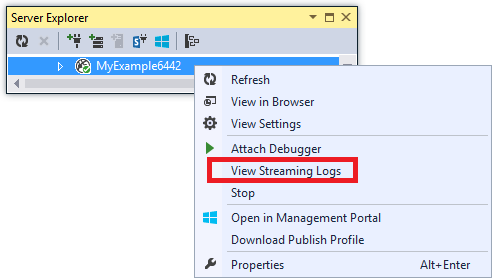
Après avoir activé la journalisation dans Azure, vous pouvez voir les journaux dans la fenêtre Sortie de Visual Studio lors de leur création.
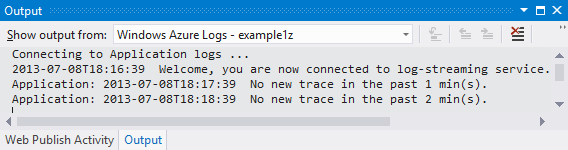
Vous pouvez également avoir écrit des journaux dans votre compte de stockage et les afficher avec n’importe quel outil qui peut accéder au service Table de stockage Azure, comme Server Explorer dans Visual Studio ou Explorateur Stockage Azure.
Résumé
Il est très simple d’implémenter un système de télémétrie prête à l’emploi, d’instrumenter la journalisation dans votre propre code et de configurer la journalisation dans Azure. Et lorsque vous rencontrez des problèmes de production, la combinaison d’un système de télémétrie et de journaux personnalisés vous aidera à résoudre rapidement les problèmes avant qu’ils ne deviennent des problèmes majeurs pour vos clients.
Dans le chapitre suivant , nous allons voir comment gérer les erreurs temporaires afin qu’elles ne deviennent pas des problèmes de production que vous devez examiner.
Ressources
Pour plus d'informations, consultez les ressources ci-dessous.
Documentation principalement sur la télémétrie :
- Modèles et pratiques Microsoft - Conseils Azure. Consultez Conseils sur l’instrumentation et la télémétrie, Conseils sur le contrôle de service, Modèle d’analyse du point de terminaison d’intégrité et Modèle de reconfiguration du runtime.
- Penny Pinching in the Cloud : Activation de l’analyse des performances de New Relic sur les sites web Azure.
- Meilleures pratiques pour la conception de Large-Scale Services sur Azure Services cloud. Livre blanc de Mark Simms et Michael Thomassy. Consultez la section Télémétrie et diagnostics.
- Développement de nouvelle génération avec Application Insights. Article msdn Magazine.
Documentation principalement sur la journalisation :
- Bloc d’application de journalisation sémantique (SLAB). Neil Mackenzie présente le cas de la journalisation sémantique avec SLAB.
- Création de journaux structurés et significatifs avec la journalisation sémantique. (Vidéo) Julian Dominguez présente le cas de la journalisation sémantique avec SLAB.
- Journalisation EF6 SQL – Partie 1 : Journalisation simple. Arthur Vickers montre comment journaliser les requêtes exécutées par Entity Framework dans EF 6.
- Résilience de connexion et interception de commandes avec Entity Framework dans une application MVC ASP.NET. Quatrième d’une série de tutoriels en neuf parties, montre comment utiliser la fonctionnalité d’interception de commande EF 6 pour journaliser les commandes SQL envoyées à la base de données par Entity Framework.
- Améliorez la journalisation à l’aide des attributs d’informations de l’appelant C# 5.0. Comment enregistrer facilement le nom de la méthode appelante sans la coder en dur dans des littéraux ou utiliser la réflexion pour l’obtenir manuellement.
Documentation principalement sur la résolution des problèmes :
- Blog De résolution des problèmes Azure & débogage.
- AzureTools : utilitaire de diagnostic utilisé par l’équipe du support technique pour les développeurs Azure. Introduit et fournit un lien de téléchargement pour un outil qui peut être utilisé sur une machine virtuelle Azure pour télécharger et exécuter un large éventail d’outils de diagnostic et de supervision. Utile lorsque vous devez diagnostiquer un problème sur une machine virtuelle particulière.
- Résoudre les problèmes d’une application web dans Azure App Service à l’aide de Visual Studio. Tutoriel pas à pas pour bien démarrer avec le suivi System.Diagnostics et le débogage à distance.
Vidéos :
- FailSafe : création de Services cloud évolutifs et résilients. Série en neuf parties par Ulrich Homann, Marc Mercuri et Mark Simms. Présente des concepts de haut niveau et des principes architecturaux d’une manière très accessible et intéressante, avec des histoires tirées de l’expérience de l’équipe de conseil à la clientèle Microsoft (CAT) avec des clients réels. Les épisodes 4 et 9 concernent la surveillance et la télémétrie. L’épisode 9 comprend une vue d’ensemble des services de surveillance MetricsHub, AppDynamics, New Relic et PagerDuty.
- Création d’une grande taille : leçons apprises des clients Azure - Partie II. Mark Simms parle de la conception de l’échec et de l’instrumentation de tout. Similaire à la série Failsafe, mais va dans plus de détails.
Exemple de code :
- Principes de base du service cloud dans Azure. Exemple d’application créé par l’équipe de conseil à la clientèle Microsoft Azure. Illustre à la fois les pratiques de télémétrie et de journalisation, comme expliqué dans les articles suivants. L’exemple implémente la journalisation des applications à l’aide de NLog. Pour obtenir de la documentation connexe, consultez la série de quatre articles wiki TechNet sur la télémétrie et la journalisation.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour