Concevoir pour survivre aux échecs (création Real-World Cloud Apps avec Azure)
par Rick Anderson, Tom Dykstra
Télécharger le projet de correction ou télécharger le livre électronique
Le livre électronique Building Real World Cloud Apps avec Azure est basé sur une présentation développée par Scott Guthrie. Il explique 13 modèles et pratiques qui peuvent vous aider à développer avec succès des applications web pour le cloud. Pour plus d’informations sur le livre électronique, consultez le premier chapitre.
L’une des choses à laquelle vous devez réfléchir lorsque vous créez n’importe quel type d’application, mais en particulier une application qui s’exécutera dans le cloud où de nombreuses personnes l’utiliseront, est la façon de concevoir l’application afin qu’elle puisse gérer correctement les défaillances et continuer à fournir de la valeur autant que possible. Avec suffisamment de temps, les choses vont se passer mal dans n’importe quel environnement ou tout système logiciel. La façon dont votre application gère ces situations détermine le niveau de contrariété de vos clients et le temps que vous devez consacrer à l’analyse et à la résolution des problèmes.
Types de défaillance
Il existe deux catégories de défaillances de base que vous souhaitez gérer différemment :
- Défaillances temporaires et autorégation, telles que des problèmes de connectivité réseau intermittents.
- Défaillances durables nécessitant une intervention.
Pour les défaillances temporaires, vous pouvez implémenter une stratégie de nouvelle tentative pour vous assurer que la plupart du temps l’application récupère rapidement et automatiquement. Vos clients peuvent remarquer un temps de réponse légèrement plus long, sans quoi ils ne seront pas affectés. Nous allons montrer certaines façons de gérer ces erreurs dans le chapitre Gestion des erreurs temporaires.
Pour les défaillances durables, vous pouvez implémenter des fonctionnalités de surveillance et de journalisation qui vous avertit rapidement lorsque des problèmes surviennent et qui facilite l’analyse de la cause racine. Nous allons vous montrer comment vous aider à rester informé de ces types d’erreurs dans le chapitre Surveillance et télémétrie.
Étendue de l’échec
Vous devez également réfléchir à l’étendue de l’échec: si une seule machine est affectée, un service entier tel que SQL Database ou Stockage, ou une région entière.

Défaillances de l’ordinateur
Dans Azure, un serveur défaillant est automatiquement remplacé par un nouveau serveur, et une application cloud bien conçue récupère automatiquement et rapidement ce type de défaillance. Précédemment, nous avons souligné les avantages de scalabilité d’un niveau web sans état, et la facilité de récupération à partir d’un serveur défaillant est un autre avantage de l’apatridie. La facilité de récupération est également l’un des avantages des fonctionnalités PaaS (Platform-as-a-Service), telles que SQL Database et Azure App Service Web Apps. Les défaillances matérielles sont rares, mais lorsqu’elles se produisent, ces services les gèrent automatiquement ; vous n’avez même pas besoin d’écrire du code pour gérer les défaillances de l’ordinateur lorsque vous utilisez l’un de ces services.
Échecs de service
Les applications cloud utilisent généralement plusieurs services. Par exemple, l’application Corriger utilise le service SQL Database, le service de stockage et l’application web est déployée sur Azure App Service. Que fera votre application si l’un des services dont vous dépendez échoue ? Pour certains échecs de service, un message convivial « Désolé, réessayez plus tard » peut être le meilleur que vous puissiez faire. Mais dans de nombreux scénarios, vous pouvez faire mieux. Par exemple, lorsque votre magasin de données back-end est en panne, vous pouvez accepter l’entrée utilisateur, afficher « votre demande a été reçue » et stocker l’entrée ailleurs temporairement ; Ensuite, lorsque le service dont vous avez besoin est à nouveau opérationnel, vous pouvez récupérer l’entrée et la traiter.
Le chapitre Modèle de travail centré sur la file d’attente montre une façon de gérer ce scénario. L’application Corriger stocke les tâches dans SQL Database, mais elle n’a pas besoin de cesser de fonctionner lorsque SQL Database est en panne. Dans ce chapitre, nous allons voir comment stocker l’entrée utilisateur d’une tâche dans une file d’attente et utiliser un processus worker pour lire la file d’attente et mettre à jour la tâche. Si SQL est arrêté, la possibilité de créer des tâches de correction n’est pas affectée ; le processus de travail peut attendre et traiter de nouvelles tâches lorsque SQL Database est disponible.
Échecs de région
Des régions entières peuvent échouer. Une catastrophe naturelle peut détruire un centre de données, il peut être aplati par un météore, la ligne de tronc dans le centre de données pourrait être coupée par un agriculteur enterrant une vache avec une pelle, etc. Si votre application est hébergée dans le centre de données frappé, que faites-vous ? Il est possible de configurer votre application dans Azure pour qu’elle s’exécute simultanément dans plusieurs régions afin qu’en cas de sinistre dans l’une d’elles, vous continuez à l’exécuter dans une autre région. De tels échecs sont des occurrences extrêmement rares, et la plupart des applications ne passent pas par les arceaux nécessaires pour garantir un service ininterrompu en cas d’échecs de ce type. Consultez la section Ressources à la fin du chapitre pour plus d’informations sur la façon de maintenir votre application disponible même en cas de défaillance d’une région.
L’un des objectifs d’Azure est de faciliter la gestion de tous ces types d’échecs, et vous verrez quelques exemples de la façon dont nous procédons dans les chapitres suivants.
Contrats SLA
Personnes entendez souvent parler des contrats de niveau de service (SLA) dans l’environnement cloud. Fondamentalement, ce sont des promesses que les entreprises font sur la fiabilité de leur service. Un contrat SLA de 99,9 % signifie que vous devez vous attendre à ce que le service fonctionne correctement 99,9 % du temps. Il s’agit d’une valeur assez typique pour un contrat SLA, qui sonne comme un nombre très élevé, mais vous pouvez ne pas vous rendre compte de la quantité de temps d’arrêt .1 % réellement. Voici un tableau qui montre la quantité de temps d’arrêt des différents pourcentages sla sur une année, un mois et une semaine.
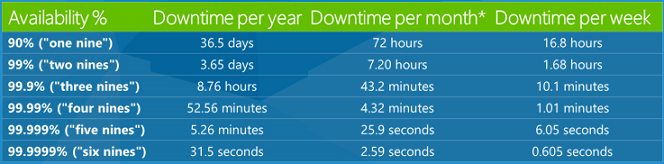
Ainsi, un contrat SLA de 99,9 % signifie que votre service peut être en baisse de 8,76 heures par an ou de 43,2 minutes par mois. C’est plus de temps d’arrêt que la plupart des gens ne le réalisent. Ainsi, en tant que développeur, vous voulez être conscient qu’un certain temps d’arrêt est possible et le gérer de manière appropriée. À un moment donné, quelqu’un va utiliser votre application, et un service va être en panne, et vous souhaitez réduire l’impact négatif de cela sur le client.
Une chose que vous devez savoir sur un contrat SLA est la période à laquelle il fait référence : l’horloge est-elle réinitialisée chaque semaine, chaque mois ou chaque année ? Dans Azure, nous réinitialisons l’horloge chaque mois, ce qui est mieux pour vous qu’un contrat SLA annuel, car un contrat SLA annuel peut masquer les mauvais mois en les compensant par une série de bons mois.
Bien sûr, nous aspirons toujours à faire mieux que le contrat SLA; en général, vous serez en panne beaucoup moins que ça. La promesse est que si nous sommes en panne plus longtemps que le temps d’arrêt maximal, vous pouvez demander de l’argent en retour. Le montant d’argent que vous récupérez ne vous compenserait probablement pas entièrement pour l’impact commercial du temps d’arrêt excédentaire, mais cet aspect du contrat SLA agit comme une politique d’application et vous indique que nous le prenons très au sérieux.
Contrats SLA composites
Une chose importante à prendre en compte lorsque vous examinez les contrats SLA est l’impact de l’utilisation de plusieurs services dans une application, chaque service ayant un contrat SLA distinct. Par exemple, l’application Corriger utilise Azure App Service Web Apps, Stockage Azure et SQL Database. Voici leurs numéros sla à la date à laquelle ce livre électronique est en cours d’écriture en décembre 2013 :
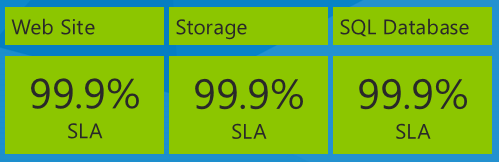
Quel est le temps d’arrêt maximal que vous attendez pour l’application en fonction de ces contrats SLA de service ? Vous pouvez penser que votre temps d’arrêt serait égal au pire pourcentage de contrats SLA, ou 99,9 % dans ce cas. Cela serait vrai si les trois services ont toujours échoué en même temps, mais ce n’est pas nécessairement ce qui se passe réellement. Chaque service peut échouer indépendamment à différents moments. Vous devez donc calculer le contrat SLA composite en multipliant les numéros de contrat SLA individuels.
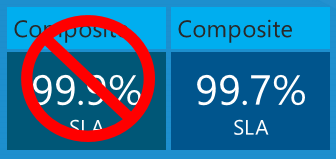
Ainsi, votre application peut être en panne non seulement 43,2 minutes par mois, mais 3 fois cette quantité, 108 minutes par mois, tout en respectant les limites du contrat SLA Azure.
Ce problème n’est pas propre à Azure. En fait, nous fournissons les meilleurs contrats SLA cloud de tous les services cloud disponibles, et vous aurez des problèmes similaires à résoudre si vous utilisez les services cloud d’un fournisseur. Cela met en évidence l’importance de réfléchir à la façon dont vous pouvez concevoir votre application pour gérer correctement les défaillances de service inévitables, car elles peuvent se produire assez souvent pour impacter vos clients ou utilisateurs.
Contrats SLA cloud par rapport à l’expérience de temps d’arrêt d’entreprise
Personnes disent parfois : « Dans mon application d’entreprise, je n’ai jamais ces problèmes. » Si vous demandez combien de temps d’arrêt par mois ils ont réellement, ils disent généralement: « Eh bien, cela se produit occasionnellement. Et si vous demandez à quelle fréquence, ils admettent que « Parfois, nous devons sauvegarder ou installer un nouveau serveur ou mettre à jour un logiciel . » Bien sûr, cela compte comme temps d’arrêt. La plupart des applications d’entreprise, sauf si elles sont particulièrement critiques, sont en fait en panne pendant plus de temps que le temps autorisé par nos contrats SLA de service. Mais quand il s’agit de votre serveur et de votre infrastructure et que vous en êtes responsable et en contrôle, vous avez tendance à vous sentir moins anangé par les temps d’arrêt. Dans un environnement cloud, vous êtes dépendant de quelqu’un d’autre et vous ne savez pas ce qui se passe.
Lorsqu’une entreprise obtient un pourcentage de temps d’activité supérieur à celui que vous obtenez d’un contrat SLA cloud, elle le fait en dépensant beaucoup plus d’argent sur le matériel. Un service cloud pourrait le faire, mais il devrait facturer beaucoup plus pour ses services. Au lieu de cela, vous tirez parti d’un service économique et concevez vos logiciels afin que les défaillances inévitables entraînent une interruption minimale pour vos clients. Votre travail en tant que concepteur d’applications cloud n’est pas tant pour éviter l’échec que pour éviter une catastrophe, et vous le faites en vous concentrant sur le logiciel, et non sur le matériel. Alors que les applications d’entreprise s’efforcent de maximiser le temps moyen entre les défaillances, les applications cloud s’efforcent de réduire le temps moyen de récupération.
Tous les services cloud n’ont pas de contrats SLA
N’oubliez pas non plus que tous les services cloud ne disposent pas d’un contrat SLA. Si votre application dépend d’un service sans garantie de temps d’utilisation, vous risquez d’être en panne bien plus longtemps que vous ne l’imaginez. Par exemple, si vous activez la connexion à votre site à l’aide d’un fournisseur de réseaux sociaux tel que Facebook ou Twitter, case activée avec le fournisseur de services pour savoir s’il existe un contrat SLA, et vous pouvez découvrir qu’il n’y en a pas un. Toutefois, si le service d’authentification tombe en panne ou ne peut pas prendre en charge le volume de demandes que vous lui lancez, vos clients sont bloqués hors de votre application. Vous pourriez être en panne pendant des jours ou plus. Les créateurs d’une nouvelle application s’attendaient à des centaines de millions de téléchargements et ont pris une dépendance sur l’authentification Facebook , mais n’ont pas parlé à Facebook avant d’être mis en ligne et ont découvert trop tard qu’il n’y avait pas de contrat SLA pour ce service.
Tous les temps d’arrêt ne comptent pas pour les contrats SLA
Certains services cloud peuvent délibérément refuser le service si votre application les utilise trop. C’est ce qu’on appelle la limitation. Si un service a un contrat SLA, il doit indiquer les conditions dans lesquelles vous pouvez être limité, et votre conception d’application doit éviter ces conditions et réagir de manière appropriée à la limitation si elle se produit. Par exemple, si les demandes adressées à un service commencent à échouer lorsque vous dépassez un certain nombre par seconde, vous souhaitez vous assurer que les nouvelles tentatives automatiques ne se produisent pas si rapidement qu’elles entraînent la poursuite de la limitation. Nous aurons plus à dire sur la limitation dans le chapitre Gestion des erreurs temporaires.
Résumé
Ce chapitre a essayé de vous aider à comprendre pourquoi une application cloud du monde réel doit être conçue pour survivre aux échecs avec grâce. À compter du chapitre suivant, les autres modèles de cette série entrent en détail sur certaines stratégies que vous pouvez utiliser pour ce faire :
- Disposez d’une bonne surveillance et d’une bonne télémétrie, de sorte que vous soyez rapidement au courant des défaillances qui nécessitent une intervention et que vous disposiez d’informations suffisantes pour les résoudre.
- Gérez les erreurs temporaires en implémentant une logique de nouvelle tentative intelligente, afin que votre application récupère automatiquement lorsqu’elle le peut et revient à la logique de disjoncteur quand elle ne le peut pas.
- Utilisez la mise en cache distribuée afin de réduire le débit, la latence et les problèmes de connexion avec l’accès à la base de données.
- Implémentez le couplage libre via le modèle de travail centré sur la file d’attente, afin que le serveur frontal de votre application puisse continuer à fonctionner lorsque le serveur principal est en panne.
Ressources
Pour plus d’informations, consultez les chapitres suivants de ce livre électronique et les ressources suivantes.
Documentation :
- Failsafe : Conseils pour les architectures cloud résilientes. Livre blanc de Marc Mercuri, Ulrich Homann et Andrew Townhill. Version de page web de la série de vidéos FailSafe.
- Meilleures pratiques pour la conception de Large-Scale Services sur Azure Services cloud. Livre blanc de Mark Simms et Michael Thomassy.
- Conseils techniques de continuité d’activité Azure. Livre blanc de Patrick Wickline et Jason Roth.
- Récupération d’urgence et haute disponibilité pour les applications Azure. Livre blanc de Michael McKeown, Hanu Kommalapati et Jason Roth.
- Modèles et pratiques Microsoft - Conseils Azure. Consultez Guide de déploiement multi-centre de données, Modèle de disjoncteur.
- Support Azure - Contrats de niveau de service.
- Continuité de l’activité dans Azure SQL base de données. Documentation sur SQL Database fonctionnalités de haute disponibilité et de récupération d’urgence.
- Haute disponibilité et récupération d’urgence pour SQL Server dans Azure Machines Virtuelles.
Vidéos :
- FailSafe : création de Services cloud évolutifs et résilients. Série en neuf parties par Ulrich Homann, Marc Mercuri et Mark Simms. Présente des concepts de haut niveau et des principes architecturaux d’une manière très accessible et intéressante, avec des histoires tirées de l’expérience de l’équipe de conseil à la clientèle Microsoft (CAT) avec des clients réels. Les épisodes 1 et 8 expliquent en détail les raisons de la conception d’applications cloud pour survivre aux échecs. Consultez également la discussion de suivi sur la limitation dans l’épisode 2 à partir de 49:57, la discussion sur les points d’échec et les modes d’échec dans l’épisode 2 à partir de 56:05, et la discussion des disjoncteurs dans l’épisode 3 à partir de 40:55.
- Création d’une grande taille : leçons apprises des clients Azure - Partie II. Mark Simms parle de la conception de l’échec et de l’instrumentation de tout. Similaire à la série Failsafe, mais va dans plus de détails.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour