Modèle de carte d’assurance maladie Intelligence documentaire
Article
Ce contenu s’applique à :v4.0 | Versions précédentes :v3.1 (GA)v3.0 (GA) ::: moniker-end
Ce contenu s’applique à :v3.1 (GA) | Dernière version :v4.0 | Versions précédentes :v3.0
Ce contenu s’applique à :v3.0 (GA) | Dernières versions :v4.0v3.1
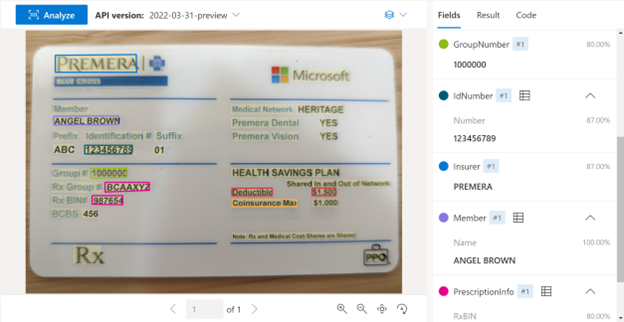
Le modèle de carte d’assurance maladie Intelligence documentaire associe de puissantes capacités de reconnaissance optique de caractères (Optical Character Recognition/OCR) à des modèles Deep Learning pour analyser et extraire des informations essentielles des cartes d’assurance maladie. Une carte d’assurance maladie est un document clé pour le traitement des soins. Elle peut être analysée numériquement pour l’intégration des patients, les informations de couverture financière, les paiements sans espèces et le traitement des revendications d’assurance. Le modèle de carte d’assurance maladie analyse les images de carte d’assurance maladie et extrait des informations clés telles que l’assureur, le membre, l’ordonnance et le numéro de groupe afin de retourner une représentation JSON structurée. Les cartes d'assurance maladie peuvent être présentées sous divers formats et qualités, notamment des images prises par téléphone, des documents numérisés et des fichiers PDF.
Exemple de carte d’assurance maladie américaine traitée à l’aide du Studio Intelligence documentaire
Options de développement
Intelligence Documentaire v4.0 : 2024-11-30 (GA) prend en charge les outils, applications et bibliothèques suivants :
Microsoft Office : Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTML
Lire
✔
✔
✔
Layout
✔
✔
✔
Document général
✔
✔
Prédéfinie
✔
✔
Extraction personnalisée
✔
✔
Classification personnalisée
✔
✔
✔
Pour de meilleurs résultats, fournissez une photo nette ou une copie de qualité par document.
Pour les PDF et TIFF, jusqu'à 2 000 pages peuvent être traitées (avec un abonnement gratuit, seules les deux premières pages sont traitées).
La taille de fichier pour l’analyse de documents est de 500 Mo pour le niveau payant (S0) et de 4 Mo pour le niveau gratuit (F0).
Les dimensions de l’image doivent être comprises entre 50 pixels x 50 pixels et 10 000 pixels x 10 000 pixels.
Si vos fichiers PDF sont verrouillés par mot de passe, vous devez supprimer le verrou avant leur envoi.
La hauteur minimale du texte à extraire est de 12 pixels pour une image de 1024 x 768 pixels. Cette dimension correspond environ à un texte de 8 points à 150 points par pouce (ppp).
Pour la formation de modèles personnalisés, le nombre maximal de pages pour les données de formation est de 500 pour le modèle personnalisé et 50 000 pour le modèle neural personnalisé.
Pour l’apprentissage du modèle d’extraction personnalisé, la taille totale des données d’entraînement est de 50 Mo pour le modèle de gabarit et de 1 Go pour le modèle neuronal.
Pour l’apprentissage du modèle de classification personnalisé, la taille totale des données d’entraînement est de 1 Go, avec un maximum de 10 000 pages. Pour 2024-11-30 (GA), la taille totale des données d’entraînement est de 2 Go, avec un maximum de 10 000 pages.
Essayer le Studio Intelligence documentaire
Découvrez comment les données sont extraites des cartes d’assurance maladie à l’aide du Studio Intelligence documentaire. Vous avez besoin des ressources suivantes :
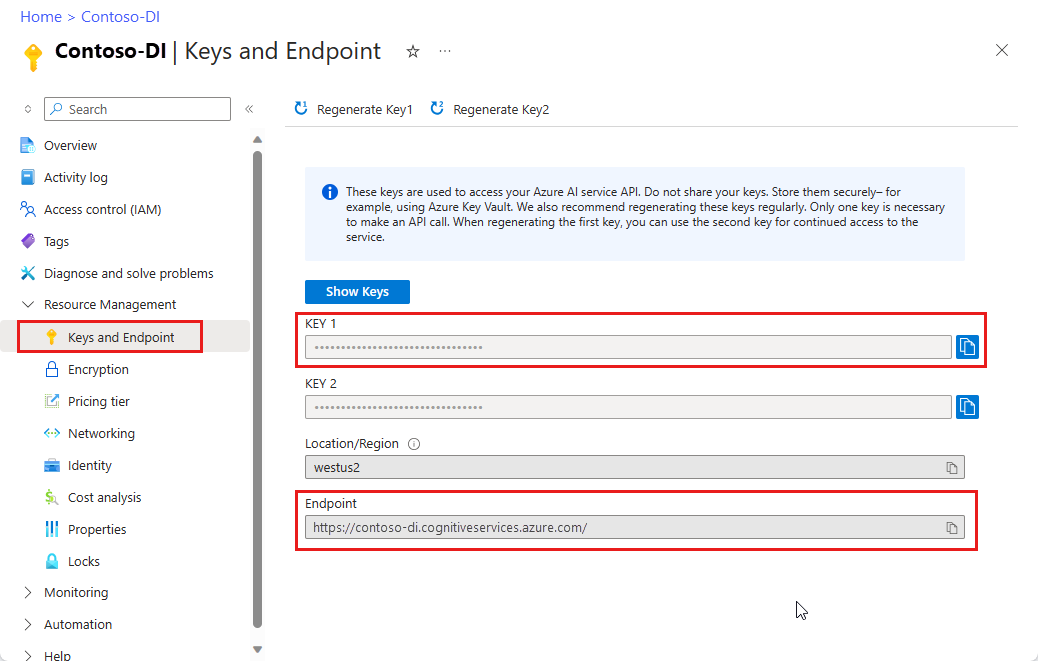
Instance Intelligence documentaire dans le Portail Azure. Vous pouvez utiliser le niveau tarifaire gratuit (F0) pour tester le service. Une fois votre ressource déployée, sélectionnez Accéder à la ressource pour accéder à la clé et au point de terminaison.
Notes
Le Studio Intelligence documentaire est disponible avec l’API v3.0.
Effectuez un démarrage rapide Intelligence Documentaire et commencez à créer une application de traitement de documents dans le langage de développement de votre choix.
Azure Intelligence documentaire extrait les données à grande échelle pour permettre l’envoi de documents en temps réel, à l’échelle, avec précision. Ce module fournit aux utilisateurs les outils nécessaires pour utiliser l’API de vision Azure Intelligence documentaire.
Gérer l’ingestion et la préparation des données, l’entraînement et le déploiement des modèles, ainsi que la surveillance des solutions d’apprentissage automatique avec Python, Azure Machine Learning et MLflow.
La reconnaissance optique de caractères (OCR) et l’extraction aux États-Unis de relevés bancaires basée sur le Machine Learning dans Intelligence documentaire extrait les données clés des relevés bancaires.