Utiliser des tableaux de bord pour visualiser les métriques Azure Databricks
Notes
Cet article s’appuie sur une bibliothèque open source hébergée sur GitHub sur : https://github.com/mspnp/spark-monitoring.
La bibliothèque d’origine prend en charge Azure Databricks Runtime 10.x (Spark 3.2.x) et versions antérieures.
Databricks a fourni une version mise à jour pour prendre en charge Azure Databricks Runtime 11.0 (Spark 3.3.x) et versions ultérieures sur la branche l4jv2 à l’adresse : https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Notez que la version 11.0 n’est pas rétrocompatible, en raison des différents systèmes de journalisation utilisés dans les runtimes Databricks. Veillez à utiliser la build appropriée pour votre runtime Databricks. La bibliothèque et le dépôt GitHub sont en mode maintenance. Il n’est pas prévu d’autres versions, et la prise en charge des problèmes sera uniquement fournie sur la base du meilleur effort. Pour toute question supplémentaire sur la bibliothèque ou sur la feuille de route pour le monitoring et la journalisation de vos environnements Azure Databricks, contactez azure-spark-monitoring-help@databricks.com.
Cet article explique comment configurer un tableau de bord Grafana pour surveiller Azure Databricks travaux en cas de problèmes de performances.
Azure Databricks est un service d’analyse rapide, puissant et collaboratif basé sur Apache Spark, qui permet de développer et de déployer de manière simple et rapide l’analytique de big data et des solutions d’intelligence artificielle (IA). Une surveillance est indispensable aux charges de travail Azure Databricks en production. La première étape consiste à collecter des métriques dans un espace de travail à des fins d’analyse. Dans Azure, Azure Monitor constitue la meilleure solution de gestion des données de journal. Azure Databricks ne prend pas en charge en mode natif l’envoi de données de journal à Azure Monitor, mais une bibliothèque permettant cette fonctionnalité est disponible dans GitHub.
Cette bibliothèque permet la journalisation des métriques de service Azure Databricks, ainsi que des métriques d’événement de requête de transmission en continu pour la structure Apache Spark. Après avoir déployé cette bibliothèque sur un cluster Azure Databricks, vous pouvez déployer un ensemble de tableaux de bord Grafana dans votre environnement de production.
Prérequis
Configurez votre cluster Azure Databricks pour utiliser la bibliothèque d’analyse, comme décrit dans le fichier Lisez-moi GitHub.
Déployer l’espace de travail Azure Log Analytics
Pour déployer l’espace de travail Azure Log Analytics, procédez comme suit :
Accédez au répertoire
/perftools/deployment/loganalytics.Déployez le modèle Azure Resource Manager logAnalyticsDeploy.json. Pour des informations complètes sur le déploiement de modèles Resource Manager, consultez Déployer des ressources à l’aide de modèles Resource Manager et Azure CLI. Le modèle est doté des paramètres suivants :
- location : Région dans laquelle l’espace de travail et les tableaux de bord Log Analytics sont déployés.
- serviceTier : Niveau tarifaire de l’espace de travail. Pour obtenir la liste des valeurs valides, consultez ceci.
- dataRetention (facultatif) : Nombre de jours durant lesquels les données de journal sont conservées dans l’espace de travail Log Analytics. La valeur par défaut est de 30 jours. Si le niveau tarifaire est
Free, la conservation des données doit être de sept jours. - workspaceName (facultatif) : Nom de l’espace de travail. S’il n’est pas spécifié, le modèle génère un nom.
az deployment group create --resource-group <resource-group-name> --template-file logAnalyticsDeploy.json --parameters location='East US' serviceTier='Standalone'
Ce modèle crée l’espace de travail, de même qu’un ensemble de requêtes prédéfinies utilisées par le tableau de bord.
Déployer Grafana dans une machine virtuelle
Grafana est un projet open source que vous pouvez déployer pour visualiser des métriques de séries chronologiques stockées dans votre espace de travail Azure Log Analytics à l’aide du plug-in Grafana pour Azure Monitor. Grafana s’exécute sur une machine virtuelle et requiert un compte de stockage, un réseau virtuel et d’autres ressources. Pour déployer une machine virtuelle avec l’image Grafana certifiée Bitnami et les ressources connexes, procédez comme suit :
Utilisez Azure CLI pour accepter les termes de l’image de la Place de marché Azure pour Grafana.
az vm image terms accept --publisher bitnami --offer grafana --plan defaultAccédez au répertoire
/spark-monitoring/perftools/deployment/grafanadans votre copie locale du référentiel GitHub.Déployez le modèle Resource Manager grafanaDeploy.json comme suit :
export DATA_SOURCE="https://raw.githubusercontent.com/mspnp/spark-monitoring/master/perftools/deployment/grafana/AzureDataSource.sh" az deployment group create \ --resource-group <resource-group-name> \ --template-file grafanaDeploy.json \ --parameters adminPass='<vm password>' dataSource=$DATA_SOURCE
Une fois le déploiement terminé, l’image Bitnami de Grafana est installée sur la machine virtuelle.
Mettre à jour le mot de passe Grafana
Dans le cadre du processus d’installation, le script d’installation Grafana génère un mot de passe temporaire destiné à l’utilisateur administrateur. Ce mot de passe temporaire vous permet de vous connecter. Pour obtenir le mot de passe temporaire, procédez comme suit :
- Connectez-vous au portail Azure.
- Sélectionnez le groupe de ressources dans lequel les ressources ont été déployées.
- Sélectionnez la machine virtuelle sur laquelle Grafana a été installé. Si vous avez utilisé le nom de paramètre par défaut dans le modèle de déploiement, le nom de la machine virtuelle est précédé de sparkmonitoring-vm-grafana.
- Dans la section Support + résolution des problèmes, cliquez sur Diagnostics de démarrage pour ouvrir la page Diagnostics de démarrage.
- Dans la page Diagnostics de démarrage, cliquez sur Journal série.
- Recherchez la chaîne suivante : "Setting Bitnami application password to".
- Copiez le mot de passe dans un emplacement sûr.
Modifiez ensuite le mot de passe de l’administrateur Grafana en procédant comme suit :
- Dans le portail Azure, sélectionnez la machine virtuelle, puis cliquez sur Vue d’ensemble.
- Copiez l’adresse IP publique.
- Ouvrez un navigateur et accédez à l'URL suivante :
http://<IP address>:3000. - Dans l’écran de connexion Grafana, entrez admin pour le nom d’utilisateur et utilisez le mot de passe Grafana des étapes précédentes.
- Une fois connecté, sélectionnez Configuration (l’icône d’engrenage).
- Sélectionnez Administrateur du serveur.
- Sous l’onglet Utilisateurs, sélectionnez le login administrateur.
- Mettez à jour le mot de passe.
Créer une source de données Azure Monitor
Créez un principal de service permettant à Grafana de gérer l’accès à votre espace de travail Log Analytics. Pour plus d’informations, consultez Créer un principal de service Azure avec Azure CLI.
az ad sp create-for-rbac --name http://<service principal name> \ --role "Log Analytics Reader" \ --scopes /subscriptions/mySubscriptionIDNotez les valeurs appId, password et tenant dans la sortie de cette commande :
{ "appId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "displayName": "azure-cli-2019-03-27-00-33-39", "name": "http://<service principal name>", "password": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "tenant": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" }Connectez-vous à Grafana comme décrit précédemment. Sélectionnez Configuration (l’icône d’engrenage), puis Sources de données.
Sous l’onglet Sources de données, cliquez sur Ajouter une source de données.
Sélectionnez Azure Monitor en tant que source de données.
Dans la section Paramètres, entrez un nom pour la source de données dans la zone de texte Nom.
Dans la section Détails d’API Azure Monitor, entrez les informations suivantes :
- ID d’abonnement : ID de votre abonnement Azure.
- ID de locataire : L’ID de locataire précédent.
- ID de client : Valeur « appId » précédente.
- Clé secrète client : Valeur « password » précédente.
Dans la section Détails d’API Azure Log Analytics, cochez la case Mêmes détails que l’API Azure Monitor.
Cliquez sur Enregistrer et tester. Si la Log Analytics source de données est correctement configurée, un message s’affiche pour l’indiquer.
Créer le tableau de bord
Pour créer les tableaux de bord dans Grafana, procédez comme suit :
Accédez au répertoire
/perftools/dashboards/grafanadans votre copie locale du référentiel GitHub.Exécutez le script suivant :
export WORKSPACE=<your Azure Log Analytics workspace ID> export LOGTYPE=SparkListenerEvent_CL sh DashGen.shLa sortie du script correspond à un fichier nommé SparkMonitoringDash.json.
Revenez au tableau de bord Grafana et sélectionnez Créer (l’icône plus).
Sélectionnez Importer.
Cliquez sur Charger un fichier .json.
Sélectionnez le fichier SparkMonitoringDash. JSON créé à l’étape 2.
Dans la section Options, sous ALA, sélectionnez la source de données Azure Monitor créée précédemment.
Cliquez sur Importer.
Visualisations dans les tableaux de bord
Les tableaux de bord Azure Log Analytics et Grafana incluent un ensemble de visualisations de séries chronologiques. Chaque graphique correspond à un tracé de séries chronologiques de données de métriques relatives à un travail Apache Spark, aux étapes du travail et aux tâches qui composent chaque étape.
Les visualisations sont les suivantes :
Latence des travaux
Cette visualisation affiche la latence d’exécution d’un travail, qui correspond à une vue sommaire des performances globales d’un travail. Affiche la durée d’exécution d’un travail du début à la fin. Notez que l’heure de début d’un travail n’est pas la même que celle de son envoi. La latence est représentée sous forme de centiles (10 %, 30 %, 50 %, 90 %) d’exécution d’un travail indexés par ID de cluster et ID d’application.
Latence des étapes
Cette visualisation affiche la latence de chaque étape par cluster, application et étape individuelle. Elle permet d’identifier une étape donnée s’exécutant lentement.
Latence des travaux
Cette visualisation affiche la latence d’exécution des travaux. La latence est représentée sous forme de centiles d’exécution de travaux par cluster, nom d’étape et application.
Somme d’exécution des travaux par hôte
Cette visualisation affiche la somme d’exécution des travaux par hôte s’exécutant sur un cluster. L’affichage de la latence d’exécution des travaux par hôte identifie les hôtes présentant une latence de travaux globale nettement supérieure à celle des autres hôtes. Cela peut indiquer que les travaux ont été distribués de manière inefficace ou inégale aux hôtes.
Métriques des travaux
Cette visualisation présente un ensemble de métriques correspondant à l’exécution d’un travail donné. Ces métriques incluent notamment la taille et la durée d’une lecture aléatoire des données, ainsi que la durée des opérations de sérialisation et de désérialisation. Pour l’ensemble complet des métriques, affichez la requête Log Analytics du panneau. Cette visualisation permet de comprendre les opérations qui composent une tâche et d’identifier la consommation des ressources de chaque opération. Les pics du graphique représentent les opérations coûteuses qui doivent être examinées.
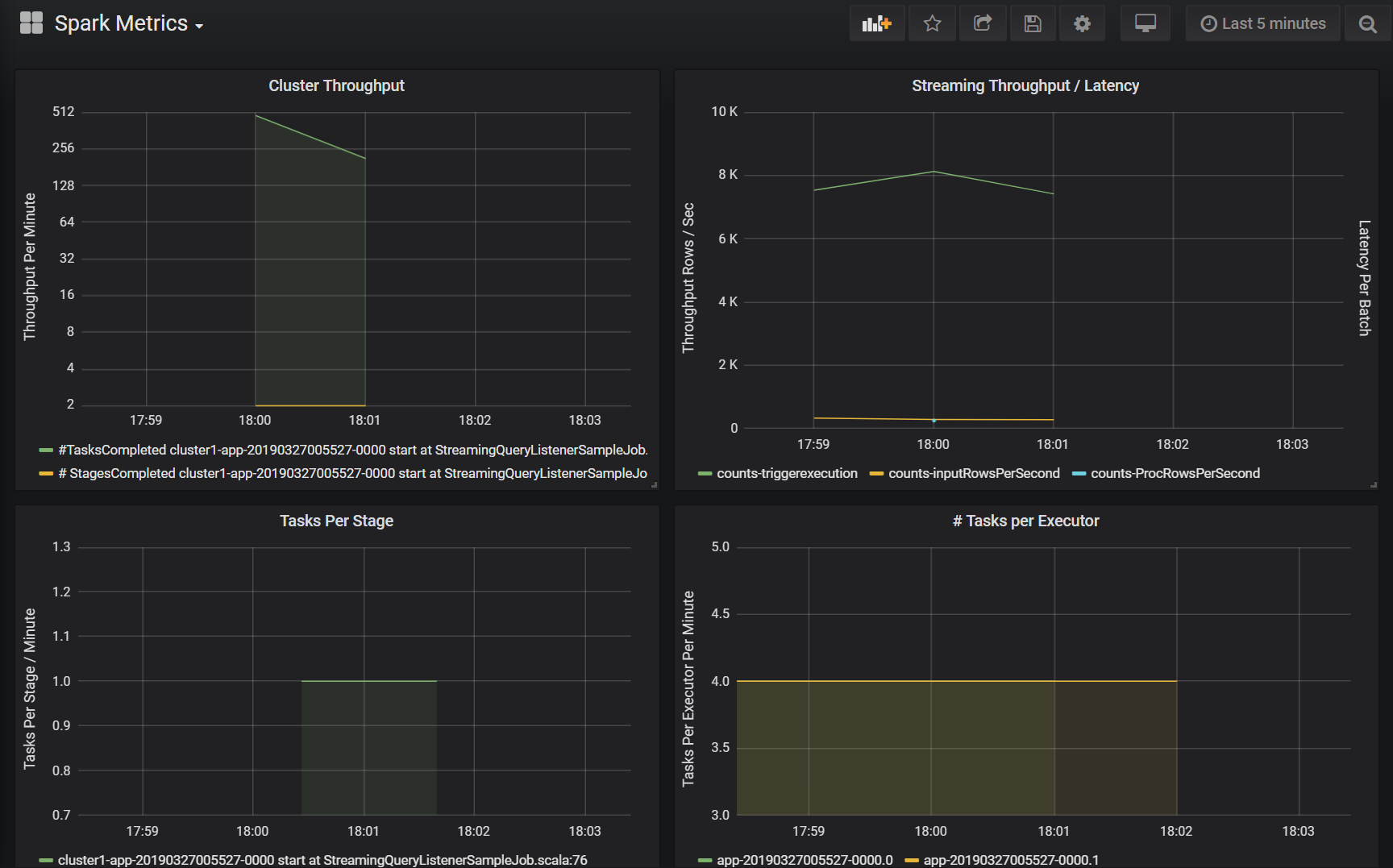
Débit du cluster
Cette visualisation est une vue d’ensemble des éléments de travail indexés par cluster et application pour représenter la quantité de travail effectuée par cluster et application. Elle indique le nombre de travaux, de tâches et d’étapes terminés par cluster, application et étape par incréments d’une minute.
Débit/latence de la diffusion en continu
Cette visualisation est liée aux métriques associées à une requête de diffusion en continu structurée. Le graphique affiche le nombre de lignes d’entrée par seconde et le nombre de lignes traitées par seconde. Les métriques de diffusion en continu sont également représentées par application. Ces métriques sont envoyées lorsque l’événement OnQueryProgress est généré au moment où la requête de diffusion en continu structurée est traitée, et la visualisation représente la latence de la diffusion en continu comme la durée, en millisecondes, nécessaire à l’exécution d’un lot de requêtes.
Consommation de ressources par exécuteur
Voici un ensemble de visualisations du tableau de bord montrant le type particulier de ressource et la manière dont elle est consommée par exécuteur sur chaque cluster. Ces visualisations permettent d’identifier les valeurs hors norme en termes de consommation des ressources par exécuteur. Par exemple, si l’allocation d’un travail pour un exécuteur donné est asymétrique, la consommation des ressources est élevée par rapport à d’autres exécuteurs s’exécutant sur le cluster. Cela peut être identifié par des pics de consommation des ressources pour un exécuteur.
Métriques de temps de calcul de l’exécuteur
Voici un ensemble de visualisations du tableau de bord indiquant le rapport entre l’heure de sérialisation de l’exécuteur, la durée de désérialisation, le temps processeur et l’heure de la machine virtuelle Java, et le temps de calcul global de l’exécuteur. Il démontre visuellement la contribution de chacune de ces quatre métriques au niveau du traitement général de l’exécuteur.
Lecture aléatoire des métriques
Le dernier ensemble de visualisations affiche les métriques de lecture aléatoire des données associées à une requête de diffusion en continu structurée sur tous les exécuteurs. Il s’agit notamment de la lecture aléatoire des octets lus, des octets écrits, de la mémoire et de l’utilisation du disque dans les requêtes où le système de fichiers est utilisé.